一、背景
在大数据领域,初始阶段业务数据通常被存储于关系型数据库,如MySQL。然而,为满足日常分析和报表等需求,大数据平台采用多种同步方式,以适应这些业务数据的不同存储需求。这些同步存储方式包括离线仓库和实时仓库等,选择取决于业务需求和数据特性。
一项常见需求是,大数据分析平台需要能够检索某张业务表的变更记录,并以每天为单位统计每条数据的变更频率。以下是示例:
- [Mysql] 业务数据 - 用户表全量数据:
| id | name | phone | gender | create_time | update_time |
|---|---|---|---|---|---|
| 1 | jack | 111 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |
| 2 | jason | 222 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |
| 3 | tom | 333 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |
- [Mysql] 2023-06-02 业务数据新增了一名tony用户,且多次更改了tom的手机号,此时表数据如下:
| id | name | phone | gender | create_time | update_time | 备注 |
|---|---|---|---|---|---|---|
| 1 | jack | 111 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 | |
| 2 | jason | 222 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 | |
| 3 | tom | 555 | 男 | 2023-06-01 13:00:00 | 2023-06-02 09:00:00 | (手机号从333->444->555) |
| 4 | tony | 666 | 男 | 2023-06-02 10:00:00 | 2023-06-02 10:00:00 | (新增tony用户) |
加粗为更新/新增数据
- [大数据平台] 2023-06-02日业务人员在大数据分析平台中查看用户表实时变更记录,数据如下:
| id | name | phone | gender | create_time | update_time | op(操作类型) | before(变更前数据) | dt |
|---|---|---|---|---|---|---|---|---|
| 3 | tom | 444 | 男 | 2023-06-01 13:00:00 | 2023-06-02 08:00:00 | u | {3,tom,333,男,…} | 2023-06-02 |
| 3 | tom | 555 | 男 | 2023-06-01 13:00:00 | 2023-06-02 09:00:00 | u | {3,tom,444,男,…} | 2023-06-02 |
| 4 | tony | 666 | 男 | 2023-06-02 10:00:00 | 2023-06-02 10:00:00 | c | null | 2023-06-02 |
op字段为每条数据的操作类型:r/c/u/d
- [大数据平台] 业务人员在大数据分析平台中根据id+姓名维度统计2023-06-02日的变更次数,期望数据如下:
| id | name | count | dt |
|---|---|---|---|
| 3 | tom | 2 | 2023-06-02 |
| 4 | tony | 1 | 2023-06-02 |
根据上述需求,我们可以得出需要构建实时流水表以满足业务数据的实时分析需求。尽管离线数仓中存在流水表,但由于以下原因,离线数仓并不符合此需求:
- 同步延迟问题: 离线数仓的同步方式通常为T+1,而上述需求要求实时查看当天业务数据的变更情况。
- 同步数据源问题: 离线数仓的T+1同步通常是通过 SQL 读取业务表数据,而不是读取 binlog 数据。这导致离线同步只能获取到 Tom 的最后一次更改数据,例如手机号=555,而无法获取所有更改项。
下面将讨论实现方案。
二、实时同步+拉链表实现
2.1、技术选型
鉴于业务数据通常存储在关系型数据库中,我们选择采用Flink-CDC持续读取binlog日志进行实时同步。为了保证实时数据能够高效写入下游并支持用户OLAP查询分析,这里选择了企业中常见的MMP库Doris作为实时数仓的存储层。整体架构如下图所示:
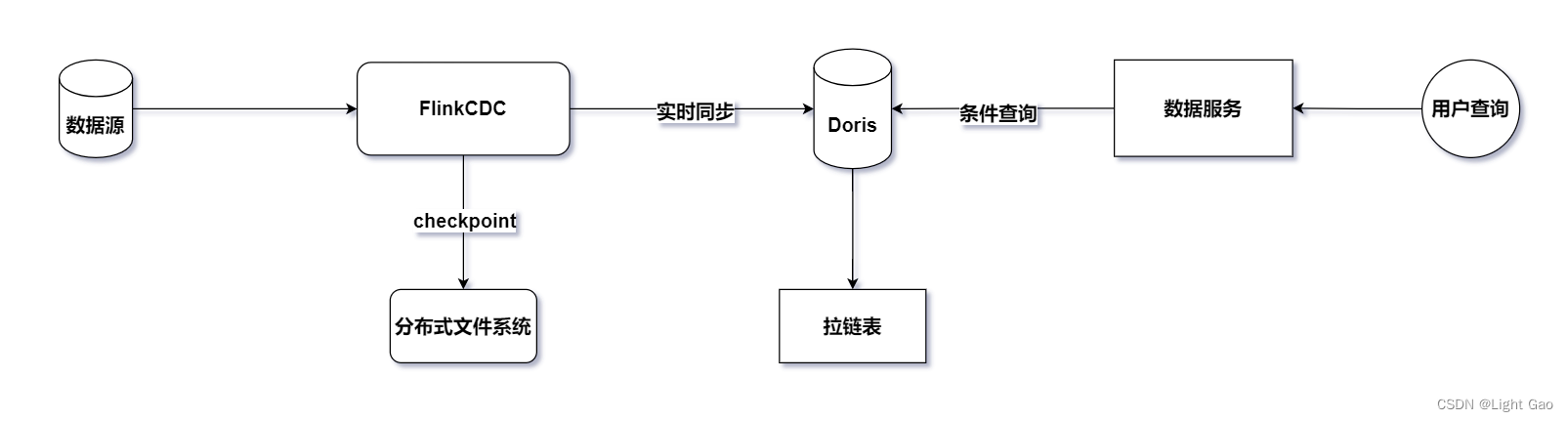
2.2、数据流转过程
Flink 实时同步程序将捕获到的 MySQL 数据变更事件进行实时处理。对于新增(INSERT)、修改(UPDATE)、删除(DELETE)等操作,构建流水表更新语句同步至下游Doris,数据流转过程如下所示:
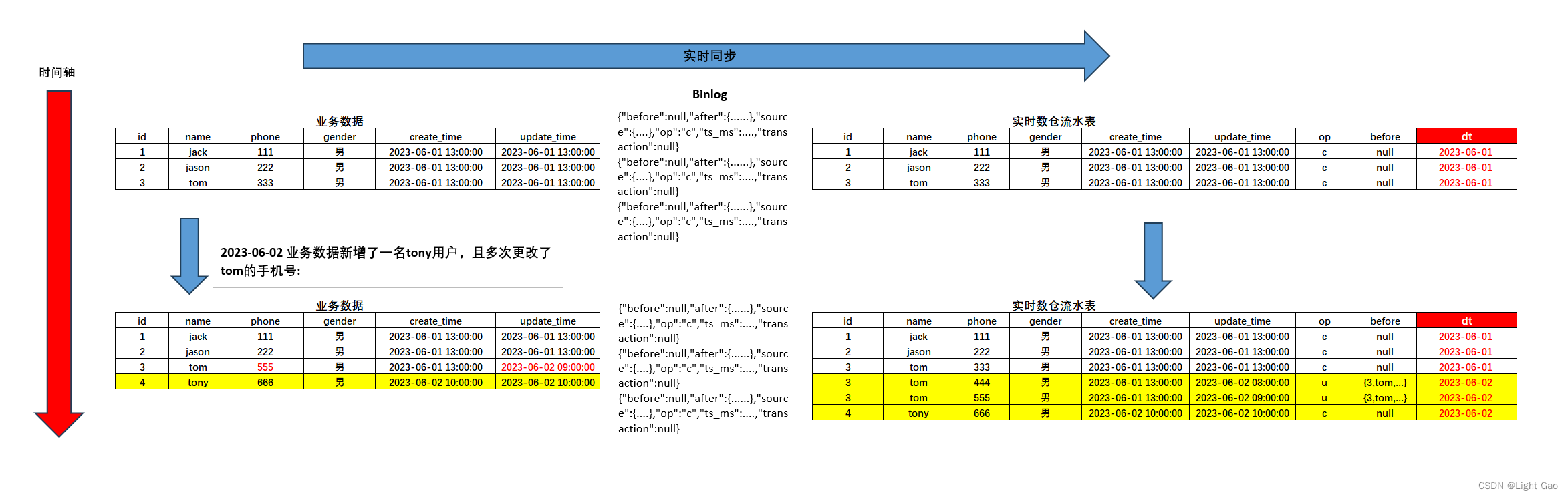
2.3、流水表设计
-
实时流水表是在大数据分析场景中常用的数据结构之一,用于记录业务数据的实时变更情况。该表主要用于跟踪数据的变更历史,捕捉每一次更新、插入或删除的操作,以便实时分析和监控业务数据的动态变化。
-
背景需求需要实时检索某张业务表的历史变更记录,并以每天为单位统计每条数据的变更频率,因此在Doris中设计表结构时采用了Unique数据模型。建表语句如下,其中以id和update_time为unique key从而保证秒级唯一性,同时采用动态分区按天进行划分,建表语句如下:
CREATE TABLE `example_user_stream`
(`id` largeint(40) NOT NULL COMMENT '用户id',`update_time` datetime NULL COMMENT '用户更新时间',`dt` date NULL COMMENT '流水日期',`create_time` datetime NULL COMMENT '用户注册时间',`name` varchar(50) NOT NULL COMMENT '用户昵称',`phone` largeint(40) NULL COMMENT '手机号',`gender` varchar(5) NULL COMMENT '用户性别',`op` varchar(4) NOT NULL COMMENT '每条数据的操作类型:r/c/u/d',`before` STRING NULL COMMENT '变更前数据',`binlog` STRING NULL COMMENT 'binlog全量日志'
) ENGINE=OLAP
UNIQUE KEY(`id`, `update_time`, `dt`)
COMMENT '用户流水表'
PARTITION BY RANGE(dt)()
DISTRIBUTED BY HASH(id) BUCKETS 8
PROPERTIES
("dynamic_partition.enable" = "true","dynamic_partition.time_unit" = "DAY","dynamic_partition.start" = "-90","dynamic_partition.end" = "3","dynamic_partition.prefix" = "p","dynamic_partition.buckets" = "8"
);
该表利用了Doris的动态分区功能,将分区粒度设置为天级,并采取了预先建立3天分区的策略,同时设定了90天的过期时间;更多信息可参考Doris动态分区介绍
2.4、实时同步逻辑
-
首先,由于实时流水表同步使用Flink-cdc读取关系型数据库,flink-cdc提供了四种模式: “initial”,“earliest-offset”,“latest-offset”,“specific-offset” 和 “timestamp”。本文使用的Flink-connector-mysq是2.3版本,这里简单介绍一下这四种模式:
initial(默认):在第一次启动时对受监视的数据库表执行初始快照,并继续读取最新的 binlog。earliest-offset:跳过快照阶段,从可读取的最早 binlog 位点开始读取latest-offset:首次启动时,从不对受监视的数据库表执行快照, 连接器仅从 binlog 的结尾处开始读取,这意味着连接器只能读取在连接器启动之后的数据更改。specific-offset:跳过快照阶段,从指定的 binlog 位点开始读取。位点可通过 binlog 文件名和位置指定,或者在 GTID 在集群上启用时通过 GTID 集合指定。timestamp:跳过快照阶段,从指定的时间戳开始读取 binlog 事件。
-
由于流水表只需知晓更改过程而无需记录全量数据,故采用
timestamp模式从指定的时间戳【今日零点】开始读取 binlog 事件开始读取;这里之所以没有选择earliest-offset模式是因为doris在建表时分区大于或等于今日,而binlog可能保存多天以前的数据而无法存放至doris分区中,故采用timestamp模式. -
此外,由于实时流水表同步需要对 binlog 数据进行解析及判断更新操作类型,因此,Flink CDC SQL 方式的表建立不再满足我们的要求。为了更好地实现这一功能,我们需要采用 API 方式来构建解决方案,代码如下:
import org.apache.flink.api.common.eventtime.WatermarkStrategy; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import com.ververica.cdc.debezium.JsonDebeziumDeserializationSchema; import com.ververica.cdc.connectors.mysql.source.MySqlSource;public class MySqlSourceExample {public static void main(String[] args) throws Exception {MySqlSource<String> mySqlSource = MySqlSource.<String>builder().hostname("yourHostname").port(yourPort).databaseList("yourDatabaseName") // 设置捕获的数据库, 如果需要同步整个数据库,请将 tableList 设置为 ".*"..tableList("yourDatabaseName.yourTableName") // 设置捕获的表.username("yourUsername").password("yourPassword").startupOptions(StartupOptions.timestamp(1685548800000L)) // 从2023-06-01零点处读取binlog.deserializer(new JsonDebeziumDeserializationSchema()) // 将 SourceRecord 转换为 JSON 字符串.build();StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 设置 3s 的 checkpoint 间隔env.enableCheckpointing(3000);env.fromSource(mySqlSource, WatermarkStrategy.noWatermarks(), "MySQL Source")// 设置 source 节点的并行度为 4.setParallelism(4).print().setParallelism(1); // 设置 sink 节点并行度为 1 env.execute("Print MySQL Snapshot + Binlog");} }代码摘自mysql-cdc-connector官网示例
-
这里我们以2023-06-02日的[Mysql]业务数据为例,新增了一名tony用户,且多次更改了tom的手机号,此时表数据如下:
| id | name | phone | gender | create_time | update_time | 备注 |
|---|---|---|---|---|---|---|
| 1 | jack | 111 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 | |
| 2 | jason | 222 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 | |
| 3 | tom | 555 | 男 | 2023-06-01 13:00:00 | 2023-06-02 09:00:00 | (手机号从333->444->555) |
| 4 | tony | 666 | 男 | 2023-06-02 10:00:00 | 2023-06-02 10:00:00 | (新增tony用户) |
加粗为更新/新增数据
- 此时Flink应用获取到的数据如下:
# 新增tony变更数据如下
{"before": null,"after": {"id": 4,"name": "tony","phone": "666","gender": "男","create_time": "2023-06-02T02:00:00Z","update_time": "2023-06-02T02:00:00Z"},"source": {# 元数据信息忽略},"op": "c", # 操作类型"ts_ms": 1706768344113,"transaction": null
}
# tom手机号333->444变更数据如下
{"before": {"id": 3,"name": "tom","phone": "333","gender": "男","create_time": "2023-06-01T05:00:00Z","update_time": "2023-06-01T05:00:00Z"},"after": {"id": 3,"name": "tom","phone": "444","gender": "男","create_time": "2023-06-01T05:00:00Z","update_time": "2023-06-01T23:00:00Z"},"source": {# 元数据信息忽略},"op": "u", # 操作类型"ts_ms": 1706768454904,"transaction": null
}
# tom手机号444->555变更数据如下
{"before": {"id": 3,"name": "tom","phone": "444","gender": "男","create_time": "2023-06-01T05:00:00Z","update_time": "2023-06-01T23:00:00Z"},"after": {"id": 3,"name": "tom","phone": "555","gender": "男","create_time": "2023-06-01T05:00:00Z","update_time": "2023-06-02T00:00:00Z"},"source": {# 元数据信息忽略},"op": "u", # 操作类型"ts_ms": 1706768521452,"transaction": null
}
-
我们使用 Flink CDC MySQL 同步数据时可以获取到binlog数据中的
op字段。op字段是用来记录每条数据的操作类型的标志。具体的操作类型如下:op=d代表删除操作op=u代表更新操作op=c代表新增操作op=r代表全量读取,而不是来自 binlog 的增量读取
-
当 Flink 同步程序接收到
op=c表示新增 Tony 的数据时,首先解析 binlog 日志,提取其中的op、before和after数据。接着,从after中截取update_time的日期值,并将这些信息拼装成 Doris 的INSERT语句,通过该语句将数据插入到 Doris 中。这一过程完成后,即成功记录了这条流水数据,sql语句如下:
INSERT INTO example_user_stream (id, update_time, dt, create_time, name, phone, gender, op, `before`, `binlog`)
VALUES
(4, '2023-06-02 10:00:00', '2023-06-02', '2023-06-02 10:00:00', 'tony', 555, '男', 'c', null, '{"before":null,"after":{"id":4,"name":"tony","phone":"666","gender":"男","create_time":"2023-06-02T02:00:00Z","update_time":"2023-06-02T02:00:00Z"},"source":{"version":"1.6.4.Final","connector":"mysql","name":"mysql_binlog_source","ts_ms":1706768344000,"snapshot":"false","db":"yushu_dds","sequence":null,"table":"user","server_id":2307031958,"gtid":"71221bfd-56e8-11ee-8275-fa163e4ecceb:33719321","file":"3509-binlog.000191","pos":643757739,"row":0,"thread":null,"query":null},"op":"c","ts_ms":1706768344113,"transaction":null}');
- 当 Flink 同步程序接收到
op=u修改tom手机号的数据时,和上述步骤一样提取binlog日志,需要注意的是此时要将before数据写入到doris数据中,sql语句如下:
# tom手机号333->444:
INSERT INTO example_user_stream (id, update_time, dt, create_time, name, phone, gender, op, `before`,`binlog`)
VALUES
(3, '2023-06-02 08:00:00', '2023-06-02', '2023-06-02 13:00:00', 'tom', 444, '男', 'u', '{"id":3,"name":"tom","phone":"333","gender":"男","create_time":"2023-06-01T05:00:00Z","update_time":"2023-06-01T05:00:00Z"}', '{"before":{"id":3,"name":"tom","phone":"333","gender":"男","create_time":"2023-06-01T05:00:00Z","update_time":"2023-06-01T05:00:00Z"},"after":{"id":3,"name":"tom","phone":"444","gender":"男","create_time":"2023-06-01T05:00:00Z","update_time":"2023-06-01T23:00:00Z"},"source":{"version":"1.6.4.Final","connector":"mysql","name":"mysql_binlog_source","ts_ms":1706768454000,"snapshot":"false","db":"yushu_dds","sequence":null,"table":"user","server_id":2307031958,"gtid":"71221bfd-56e8-11ee-8275-fa163e4ecceb:33719761","file":"3509-binlog.000191","pos":692873739,"row":0,"thread":null,"query":null},"op":"u","ts_ms":1706768454904,"transaction":null}');# tom手机号444->555:
INSERT INTO example_user_stream (id, update_time, dt, create_time, name, phone, gender, op, `before`,`binlog`)
VALUES
(3, '2023-06-02 09:00:00', '2023-06-02', '2023-06-02 13:00:00', 'tom', 555, '男', 'u', '{"id":3,"name":"tom","phone":"444","gender":"男","create_time":"2023-06-01T05:00:00Z","update_time":"2023-06-01T23:00:00Z"}', '{"before":{"id":3,"name":"tom","phone":"444","gender":"男","create_time":"2023-06-01T05:00:00Z","update_time":"2023-06-01T23:00:00Z"},"after":{"id":3,"name":"tom","phone":"555","gender":"男","create_time":"2023-06-01T05:00:00Z","update_time":"2023-06-02T00:00:00Z"},"source":{"version":"1.6.4.Final","connector":"mysql","name":"mysql_binlog_source","ts_ms":1706768521000,"snapshot":"false","db":"yushu_dds","sequence":null,"table":"user","server_id":2307031958,"gtid":"71221bfd-56e8-11ee-8275-fa163e4ecceb:33720328","file":"3509-binlog.000191","pos":806151026,"row":0,"thread":null,"query":null},"op":"u","ts_ms":1706768521452,"transaction":null}');
- [大数据平台] 2023-06-02日业务人员在大数据分析平台中查看用户表实时变更记录,sql查询及结果如下:
SELECT * FROM example_user_stream PARTITION p20230602;
| id | update_time | dt | create_time | name | phone | gender | op | before | binlog(部分省略) |
|---|---|---|---|---|---|---|---|---|---|
| 4 | 2023-06-02 10:00:00 | 2023-06-02 | 2023-06-02 10:00:00 | tony | 555 | 男 | c | NULL | {“before”:null,“after”:{…}…} |
| 3 | 2023-06-02 08:00:00 | 2023-06-02 | 2023-06-02 13:00:00 | tom | 444 | 男 | u | {“id”:3,“name”:“tom”,“phone”:“333”,“gender”:“男”,“create_time”:“2023-06-01T05:00:00Z”,“update_time”:“2023-06-01T05:00:00Z”} | {“before”:null,“after”:{…}…} |
| 3 | 2023-06-02 09:00:00 | 2023-06-02 | 2023-06-02 13:00:00 | tom | 555 | 男 | u | {“id”:3,“name”:“tom”,“phone”:“444”,“gender”:“男”,“create_time”:“2023-06-01T05:00:00Z”,“update_time”:“2023-06-01T23:00:00Z”} | {“before”:null,“after”:{…}…} |
- [大数据平台] 业务人员在大数据分析平台中根据id+姓名维度统计2023-06-02日的变更次数,sql查询及结果如下:
SELECT id,name,count(*) as 'count',dt FROM example_user_stream PARTITION p20240201 group by dt,id,name;
| id | name | count | dt |
|---|---|---|---|
| 3 | tom | 2 | 2023-06-02 |
| 4 | tony | 1 | 2023-06-02 |
至此流水表的实时同步逻辑结束,删除操作与前述的修改操作类似,实现方式基本一致。
三、总结
FlinkCDC与流水表的结合:
- 实时同步: FlinkCDC通过实时捕获数据库变更,结合Flink的处理能力,将变更逻辑应用到流水表中,实现实时同步。
- 数据一致性: 结合Flink的状态管理,可以确保对数据变更的精确追踪和一致性处理,避免数据丢失或不一致。
- 删除操作: FlinkCDC同样适用于删除操作,将删除事件同步到流水表,确保流水表记录了所有的数据变更历史。
- 动态分区支持: FlinkCDC与动态分区的流水表结合,可以更灵活地管理和查询历史数据,使得数据的存储和查询更为高效。
总体而言,FlinkCDC与流水表的结合为实时数据同步提供了可靠的解决方案,既能满足实时性要求,又能保证数据变更历史的完整性和一致性。
四、相关资料
- Doris 数据模型
- MySQL CDC Connector
- Flink实时数仓同步:拉链表实战详解
- 深入数仓离线数据同步:问题分析与优化措施

:资源可用性与性别比例Problem A: Resource Availability and Sex Ratios)
)



学习笔记 03 - 1.3 背包、队列和栈)
-掌握Fiddler中Fiddler Script用法,你会有多牛逼-下篇)
)



)





)
