Python网络爬虫分步走之第一步:什么是网络爬虫?
Web Scraping in Python Step by Step – 1st Step, What is Web Crawler?
By Jackson@ML
1. 什么是网络爬虫?
在能够使用Google搜索引擎的场合,你是否尝试过简单搜索:“How does it know where to look? ( 意思是:如何知道去哪里看?),那么很快,Google返回的答案是:web crawlers, 该答案的中文意思是:网络爬虫。
网络爬虫的定义 网络爬虫,也成为搜索引擎机器人或网站蜘蛛,是一种数字机器人,可在互联网上爬取查找及索引搜索引擎的页面。
2. 搜索引擎与网络爬虫
我们通常接触过的搜索引擎,可能有Google, 也可能有Bing,或者Baidu等。
在任意搜索引擎上进行搜索时,该网站可能会根据搜索关键字或者字符串,筛选出数十万亿个页面,以生成与该术语相关的结果列表。
正如我们点击下一个页面,好像有一种永远也到不了底的感觉。
这些搜索引擎究竟如何将所有页面存档?又是如何知道查找它们,并且在几秒钟内生成这些结果的呢?
标准的答案,就是网络爬虫(Web Crawler),也称蜘蛛(Spider)。这些结果都是由自动化运行的程序(常称为“机器人“),来”抓取“或者浏览互联网网络,以便将它们添加到搜素引擎中。
这些成为“机器人“的,会将网站编制索引,以创建最终出现在搜索结果中的页面列表。
网络爬虫还会在这个引擎的数据库中创建和存储这些页面的副本,类似于缓冲区;这样可以使你几乎立刻搜索到结果。这也是搜索引擎经常在其数据库中包含网站缓存版本的原因。
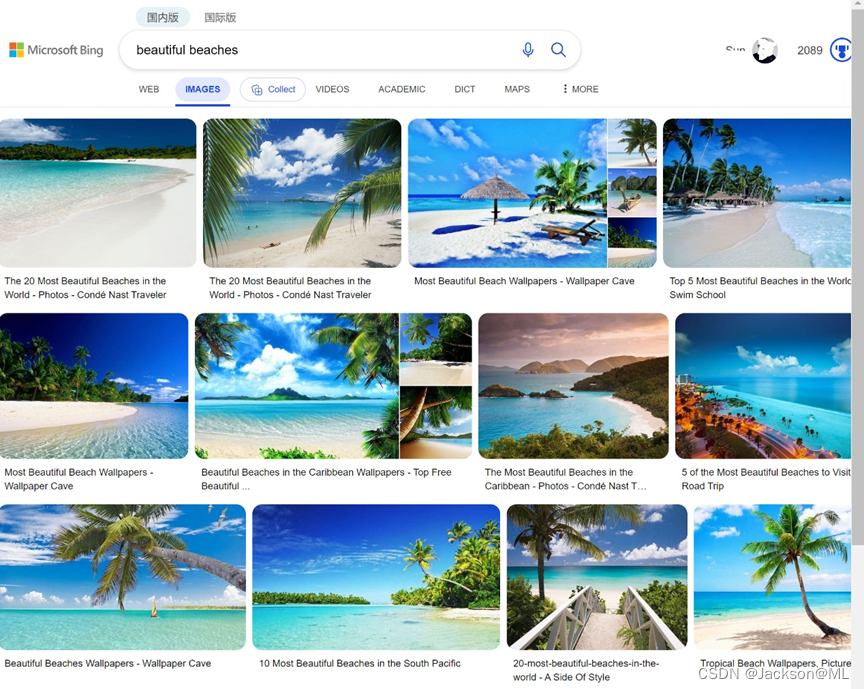
- **示例一:**从Bing搜索引擎搜索关键字 beautiful beaches(美丽海滩)的图片(图片来自于网络),如下图所示:
3. 网络爬虫的工作机理是什么?
上面提到搜索引擎。接下来的内容,将扩展一下。
1) 可抓取的网站
搜索引擎通过在页面上的链接来互相传递抓取或访问网站,这是通常的做法。但是,如果您有一个新网站,而没有将您的页面连接到其他页面的链接,您可以通过在 Google Search Console 上提交您的 URL 来要求搜索引擎执行网站抓取。
您可以进一步详细了解相关技术,包括如何检查您的网站是否可抓取和编入索引。
爬虫爬取了数据,就像在新的土地上充当了一次探险家一样。
它们总是在页面上搜寻可发现的链接,并在了解其功能之后,将其记在网站地图上。然而,爬虫只能够筛选网站上的公共页面,哪些无法抓取的私人页面,会被贴上“暗网“(Dark Web)的标签。
网络爬虫在网页上时会收集有关网页的信息,例如文案拷贝(copy)和元标记(meta tags)。然后,爬虫将页面存储在索引中,因此 Google 的算法可以对它们包含的单词进行排序,以便稍后为用户获取和排名。
2) 网络爬虫的例子
说到这里,也许你会问:网络爬虫有哪些例子呢?
通常,流行的搜索引擎都有一个网络爬虫,而大型搜索引擎则有多个爬虫,各带有特定的关注点。
例如,Google 拥有其主要抓取工具 - Googlebot,包括移动和桌面抓取。但 Google 还有额外的几个机器人,例如 Googlebot 图片、Googlebot 视频、Googlebot 新闻和 AdsBot。
以下是您可能遇到的其他一些网络爬虫:
适用于 DuckDuckGo 的 DuckDuckBot
Yandex Bot for Yandex
百度蜘蛛(用于百度搜索)
Yahoo! Slurp (用于 Yahoo!搜索)
Bing 还有一个名为 Bingbot 的标准 Web 爬虫和更具体的机器人,如 MSNBot-Media 和 BingPreview。它的主要爬虫过去曾是MSNBot,后来在标准爬虫方面退居二线,现在只涵盖次要的网站爬虫任务。
4. 搜索引擎优化
SEO,即 Search Engine Optimization (搜索引擎优化)。SEO从业者不断优化网站架构、网页和内容,用于改进你的网站以便在搜索引擎(例如Google)中获得更好的排名 - SEO 是一套旨在改善自然搜索结果中多种类型内容的外观、定位和实用性的做法。这些内容可以包括网页、视频媒体、图像、本地商家信息和其他资产。由于自然搜索是人们发现和访问在线内容的首选方法,因此利用 SEO 最佳实践对于确保您发布的数字内容能够被公众找到和选择,从而增加您网站的自然流量,这对于网站推广来说至关重要。
这就要求网页对网络爬虫来说是可访问和可读的。抓取是搜索引擎锁定您的页面的第一种方式,但定期抓取可以帮助它们显示您所做的更改并随时了解您的内容新鲜度。
5. 为什么SEO很重要?
SEO(搜索引擎优化)很重要的一个重要原因,是因为它可以帮助在线发布者出现在搜索引擎显示的结果中。像 Google 和 Bing 这样的搜索引擎都有自己的方法来显示和格式化用户在搜索框中输入查询时显示的内容,如下所示:
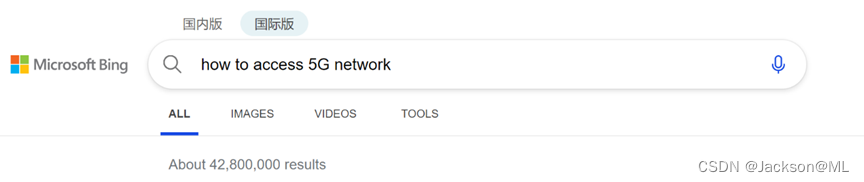
为了响应上图中这样的查询,弄清楚 how to access 5G network (如何接入(访问)5G网络),像Bing这样的搜索引擎可以返回各种各样的结果,有以下几类典型的结果:
1) 有机结果(Organic Results)
Google最熟悉的结果就是传统的自然结果,Bing也趋于表达这样的结果。它们根据特定算法按特定顺序排名的网站页面链接组成。
搜索引擎算法是搜索引擎用来确定可能结果与用户查询的相关性的一组公式。曾几何时,谷歌通常为每个查询返回一个包含 10 个自然结果的页面,但现在这个数字可能会有很大差异,结果的数量会根据搜索者使用的是台式电脑、手机还是其他设备而有所不同。
传统的自然搜索结果如下所示,每个条目都有标题、描述、来源链接以及其他功能,如日期和其他链接。
现在,我们来看一下Bing就刚才的字符串搜索的结果:
-
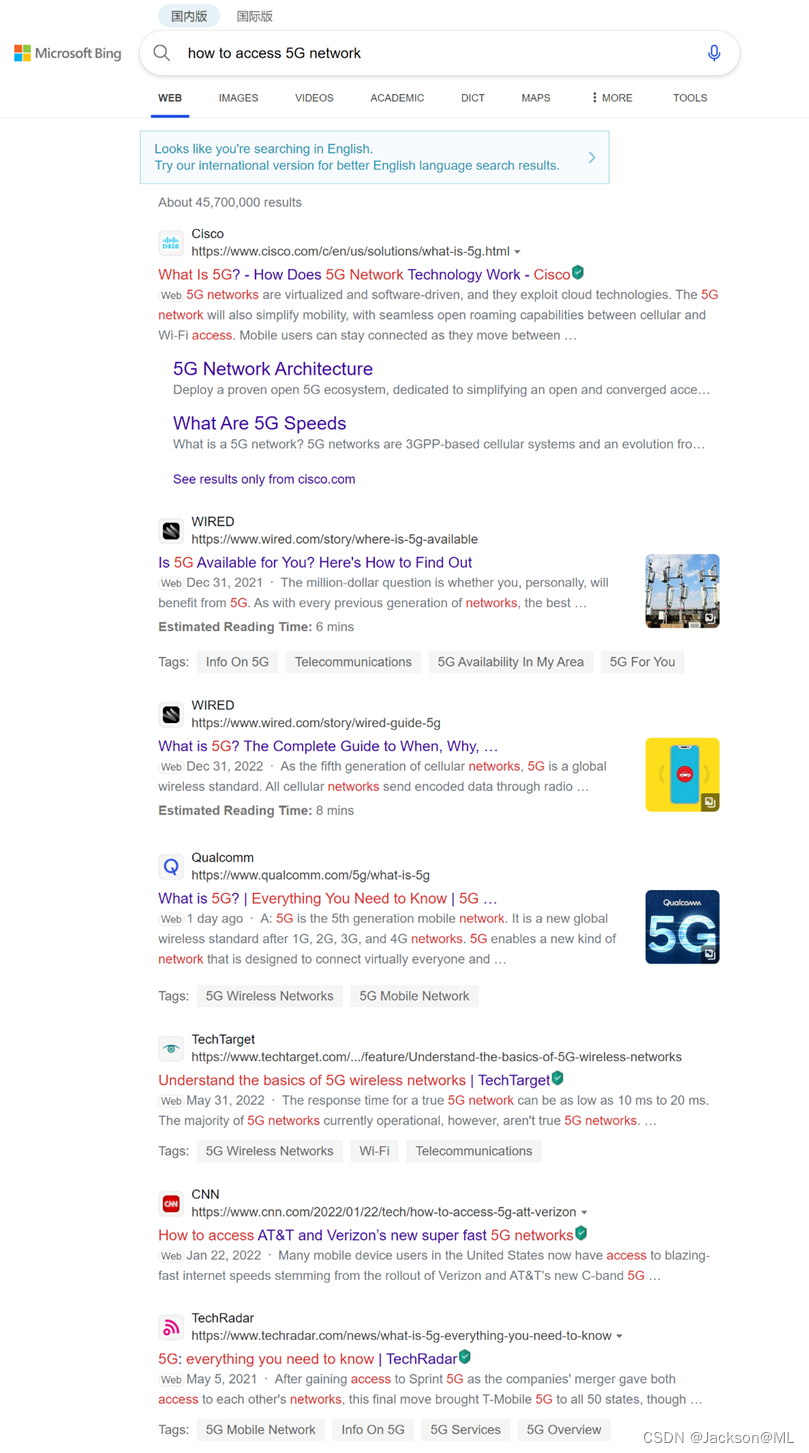
国内版搜索结果如下:
-
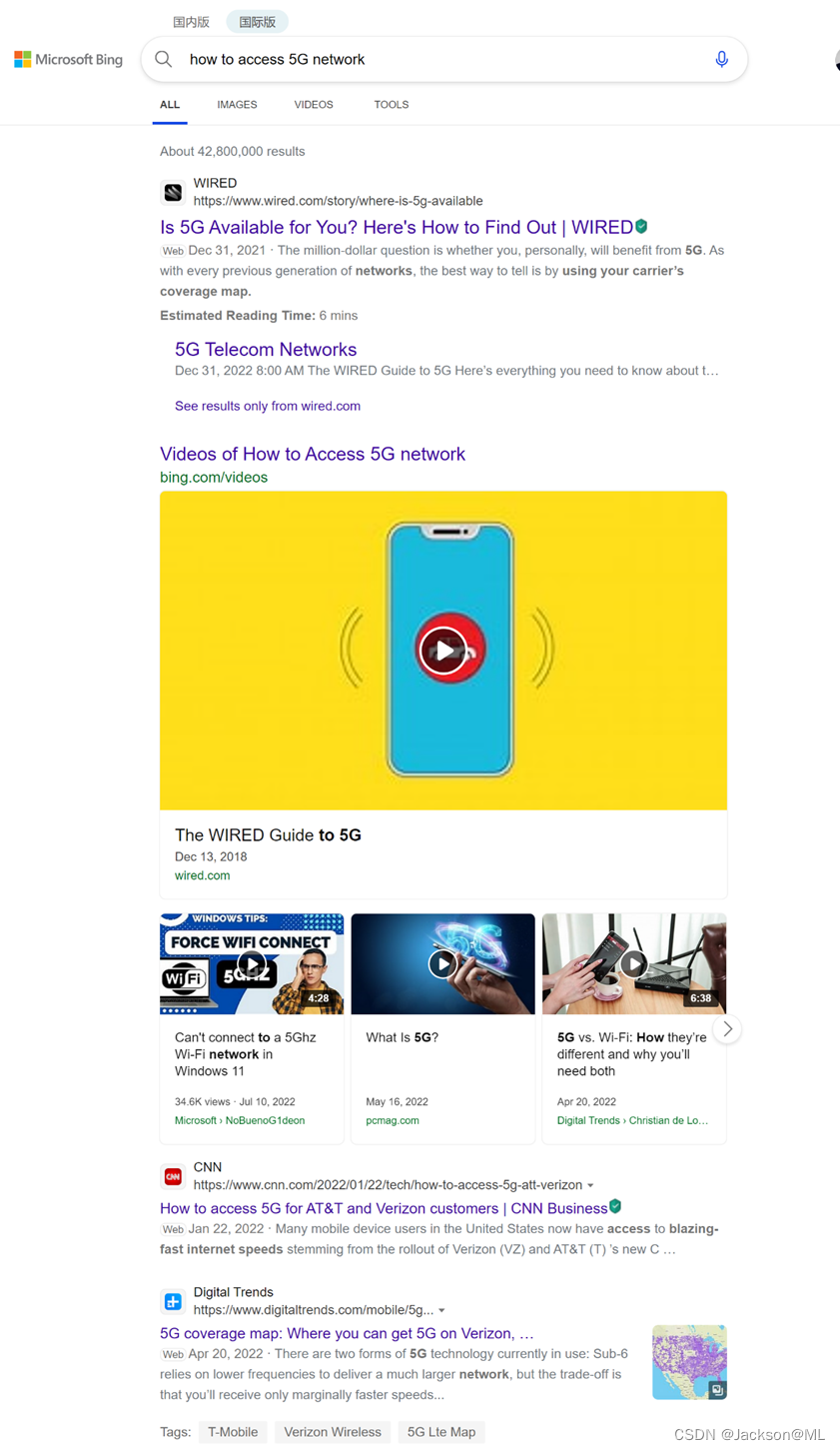
国际版搜索结果如下:
2) SERP功能
Search Engine Results Pages(即搜索引擎结果页面,简称SERP)。 除了传统的自然结果之外,搜索引擎还可以显示各种其他显示,这些显示可以归类为“SERP 功能”的总称。Google SERP的功能有很多种,包括但不限于以下这些:
本地包结果
Google 商家资料
知识面板
附加链接
精选片段
图片包和图片轮播
视频包
People Also Ask 功能
相关搜索
加上额外的 SERP 功能,用于新闻结果、酒店和旅行结果、购物、常见问题解答、工作列表等。
Local Pack Results (本地打包结果) 会显示某些查询的本地企业列表,或者快捷支付的电子商务网站及报价等,这在Google分类列表尤为明显。
但是,在Bing搜索里,只做笼统地做国内、国际分类。
例如:当搜索buy mobile phones online时,国际版列表如下图所示:
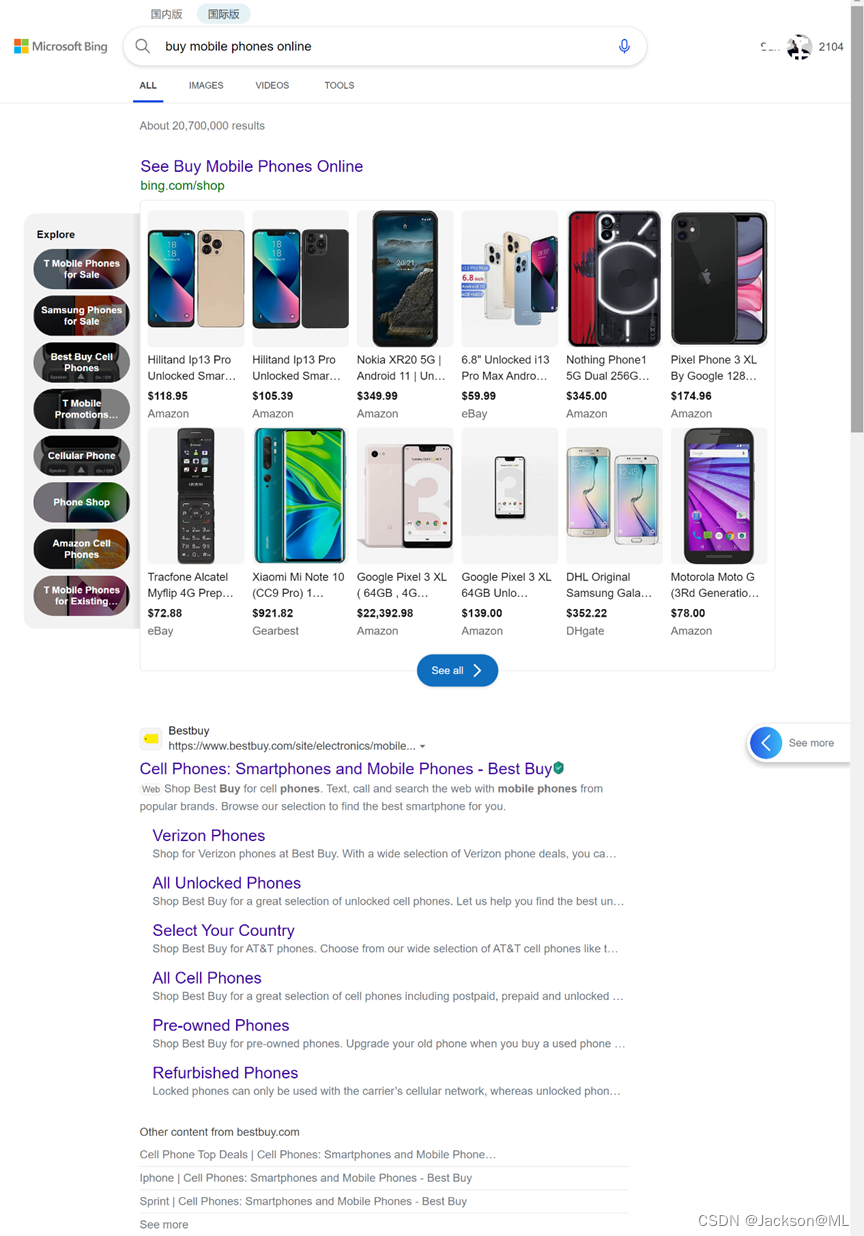
关于搜索引擎的更多详细内容,不在本文的论述范围。今后有机会单独详述。
6. 网络爬虫的基本步骤
认识了网络爬虫之后,可以看出,网络爬虫是一个从Web站点资源爬取所需数据的过程,它包含的基本步骤有以下几步:
1) 识别目标网站。 爬虫的第一步,是识别目标Web站点资源的网址;
2) 请求获取HTML网页。 此时会使用Python函数库发送HTTP请求,来取回HTTP响应的HTML网站页面;
3) 分析HTML网页。 使用可视化工具在HTML网页定位所需数据,并且分析如何搜索和查找出此标签来获取数据;
4) 解析HTML网页。 使用Python函数库解析(Parse)响应文件的HTML网页,可以创建成树状结构的标签对象集合;
5) 从解析网页提取所需数据。 可以通过搜索或访问的方式,获取所需数据,在整理成指定格式后,存储为CSV格式文件,或者JSON格式文件。
参考文献:
- https://moz.com/learn/
- https://octoparse.com


















)
