From Audio to Photoreal Embodiment: Synthesizing Humans in Conversations
From Audio to Photoreal Embodiment:Synthesizing Humans in Conversations
从二元对话的音频中,我们生成相应的逼真的面部、身体和手势。
概括性:角色是由作者的声音驱动的(而不是模型所训练的演员)。
摘要:
我们提出了一个框架,用于生成根据二元交互的会话动态手势的全身逼真的化身。给定语音音频,我们为个人输出多种可能的手势动作,包括脸、身体和手。我们的方法背后的关键是将矢量量化的样本多样性的好处与通过扩散获得的高频细节相结合,以产生更动态,更具表现力的运动。我们使用高度逼真的虚拟人物来可视化生成的运动,这些虚拟人物可以在手势中表达关键的细微差别(例如嘲笑和傻笑)。为了促进这方面的研究,我们引入了首个允许逼真重建的多视图会话数据集。实验表明,我们的模型生成适当和多样化的手势,优于扩散和VQ-only方法。此外,我们的感知评估强调了真实感(相对于网格)在准确评估会话手势中的细微运动细节方面的重要性。代码和数据集将公开发布。
方法
1-我们捕获了一个新颖的、丰富的二元对话数据集,可以进行逼真的重建。
2.我们的运动模型包括三个部分:面部运动模型、引导姿态预测器和身体运动模型。
3-给定音频和预训练唇回归器的输出,我们训练一个条件扩散模型来输出面部运动。
4-对于身体,我们以音频作为输入,并以1fps的速度自回归输出VQ-ed引导姿态。
5-然后,我们将音频和引导姿势传递到一个扩散模型中,该模型以30 fps的速度填充高频身体运动。
6-生成的面部和身体运动都被传递到我们训练过的头像渲染器中,以生成逼真的头像。
环境安装:需要pytorch3D
【配环境】pytorch3d版本不匹配导致ImportError: libtorch_cuda_cu.so: cannot open shared object file-CSDN博客
效果展示如下
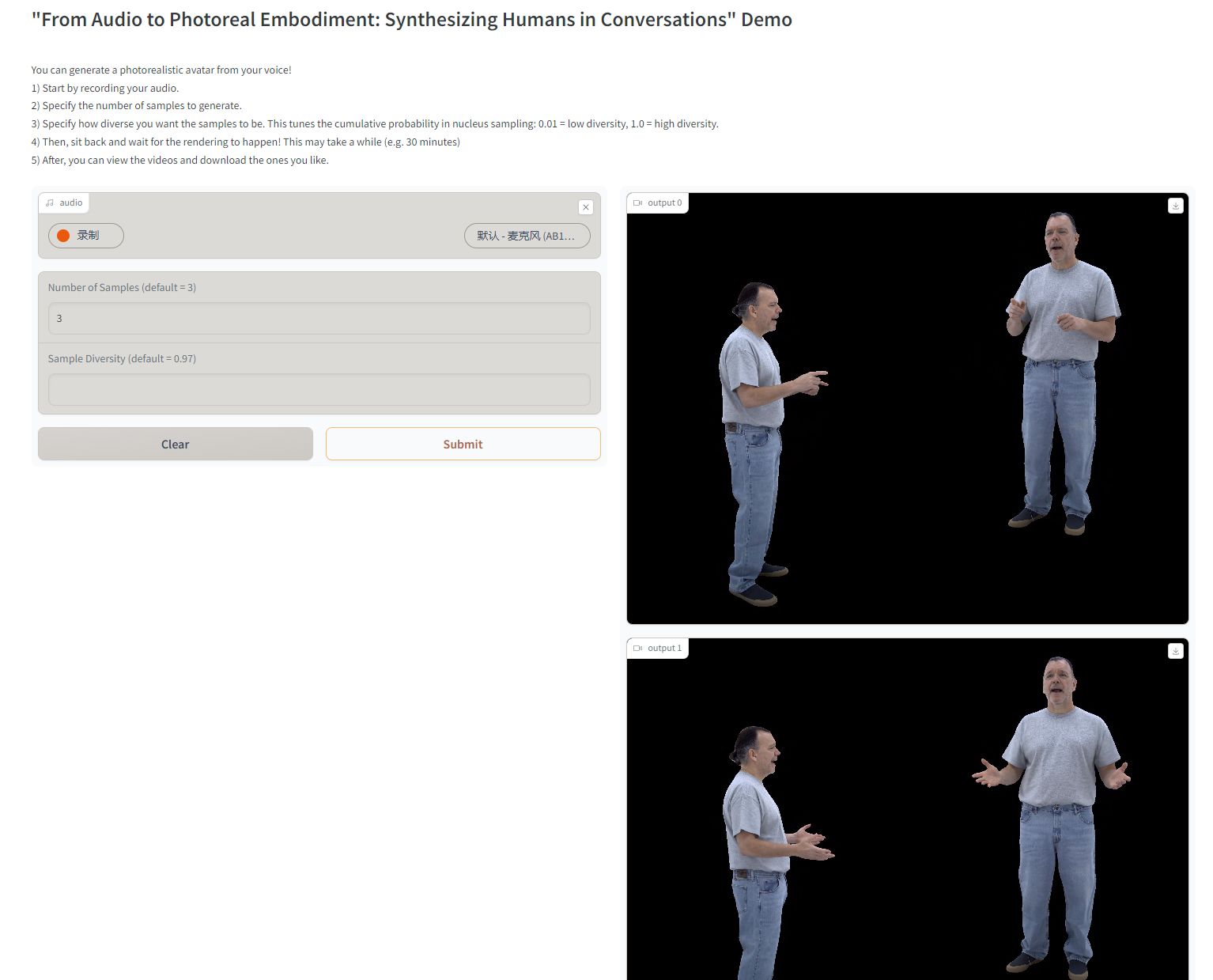
)








)
part1)







)
