流程:
1.指定url(获取网页的内容)
爬虫会向指定的URL发送HTTP请求,获取网页的HTML代码,然后解析HTML代码,提取出需要的信息,如文本、图片、链接等。爬虫请求URL的过程中,还可以设置请求头、请求参数、请求方法等,以便获取更精确的数据。通过爬虫请求URL,可以快速、自动地获取大量的数据,为后续的数据分析和处理提供基础。
2.发起请求(request)(向目标网站发送请求,获取网站上的数据)
通过发送请求,爬虫可以模拟浏览器的行为,访问网站上的各种资源,例如网页、图片、视频、音频等等。爬虫可以通过请求获取网站上的数据,然后对数据进行解析和处理,从而实现数据的抓取和提取。请求可以包含各种参数,例如请求的URL、请求的方法、请求的头部信息、请求的数据等等,这些参数可以根据需要进行设置,以便获取目标数据。
3.获取响应数据(页面源码)
4.存储数据
一、导入相关库(requests库)
安装:
pip install requests
导入:(requests:python的网络请求模块)
import requests返回值:
response.status_code : 状态码
response.url: 请求url
response.headers: 头部信息
response.cookies: cookie信息
response.text: 字符串形式网页源码
response.content: 字节流形式网页源码
二、相关的参数(url,headers)
带参数的请求:
- 百度搜索设置了反爬机制,如果判断请求方是爬虫而不是浏览器,则不返回结果
- 百度如何判断是爬虫还是浏览器在请求?
通过User-Agent(请求者身份标识)
获取:进入想要爬取的网站中点击F12
点击network,按下Ctr+r或者F5刷新,拉到页面的最上方叫research的文件,打开headers,
这里我们只需要到两个简单的参数,本次案例只是做一个简单的爬虫教程,其他参数暂时不考虑
| 参数 | 作用 |
| Request URL | 发送请求的网站地址,也就是图片所在的网址 |
| user-agent | 用来模拟浏览器对网站进行访问,避免被网站监测出非法访问 |


做参数代码的准备
url = "https://pic.netbian.com/uploads/allimg/210317/001935-16159115757f04.jpg"
headers = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36"
}
三、向网站发出请求
response = requests.get(url=url,headers=headers)
print(response.text) # 打印请求成功的网页源码,和在网页右键查看源代码的内容一样的出现的网络源码可能会乱码
解决乱码:
- 修改response的encoding为utf-8,然后再进行写入
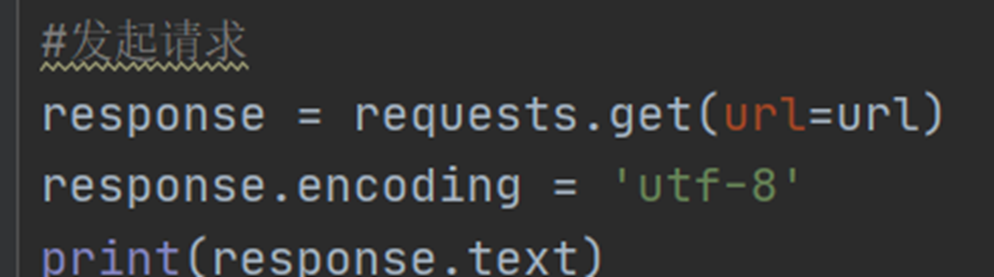

- 通过发送请求成功response,通过(apparent_encoding)获取该网页的编码格式,并对response解码
response.encoding=response.apparent_encoding
区别:
- 第一行代码 `response.encoding=response.apparent_encoding` 是使用 `response` 对象的 `apparent_encoding` 属性来自动检测编码,并将编码设置为检测到的编码。`apparent_encoding` 属性是根据 HTTP 头部、HTML 的 meta 标签等信息来猜测编码的,但并不一定准确。
- 第二行代码 `response.encoding='utf-8'` 是手动将编码设置为 UTF-8。这种方式适用于已知响应的编码方式,或者在使用第一种方式检测编码失败时手动指定编码。
- 第一种方式更加智能,但可能不够准确;第二种方式更加精确,但需要手动指定编码。
四、匹配(re库,正则表达式)
正则表达式:简单点说就是由用户制定一个规则,然后代码根据我们指定的所规则去指定内容里匹配出正确的内容
通过正则表达式把一个个图片的链接和名字给匹配出来,存放到一个列表中
import re
"""
. 表示除空格外任意字符(除\n外)
* 表示匹配字符零次或多次
? 表示匹配字符零次或一次
.*? 非贪婪匹配
"""
# src后面存放的是链接,alt后面是图片的名字
# 直接(.*?)也是可以可以直接获取到链接,但是会匹配到其他不是我们想要的图片
# 我们可以在前面图片信息看到链接都是/u····开头的,所以我们就设定限定条件(/u.*?)
#这样就能匹配到我们想要的
parr = re.compile('src="(/u.*?)".alt="(.*?)"')
image = re.findall(parr,response.text)
for content in image:print(content)解析html文件:
•导入lxml模块中的html功能
•使用html.fromstring函数将网页文本解析成html内容
这里举爬取豆瓣电影排行榜并解析其电影图片和电影名的例子来更好地学习爬虫的相关步骤
网址:https://movie.douban.com/chart

要解析html文件,先安装lxml模块
命令:
pip install lxml- 导入lxml模块中的html功能
- 使用html.fromstring函数将网页文本解析成html内容
- esponse是爬虫获取的结果,也可以读本地存好的html文件
- 观察html文件,找到想收集的数据在什么样的标签里
- 例如要获取电影名字,通过观察,所有的电影名字都在<a class = "nbg">标签里



- 使用xpath函数定位到电影名字所在的标签(注意路径以//开头,指定class名称前要加@符号)
- 使用 /@属性名 获取标签内的某个属性值
- 注意:得到的结果必定是列表,即使只有一个元素

打印列表结果

然后用相同的方式,对电影的评分和图片进行爬取
#导入网络请求库
import requests,lxml,os
from lxml import html #用于解析html文件
url="https://movie.douban.com/chart"
headers={"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"
}
response=requests.get(url=url,headers=headers)
response.encoding='utf-8'
content=html.fromstring(response.text) #将HTTP响应的文本内容转换为HTML文档对象,以便进行后续的HTML解析和处理
text=str(content)
f=open("douban.html",'w',encoding='utf-8') #打开html文件,以写入模式‘w’打开,指定编码格式为utf-8
f.write(response.text) #将爬取到的内容写入文件中
f.close()
import os
names=content.xpath('//a[@class="nbg"]/@title') #运用xpath函数解析html文件找到电影的名字存储到一个列表里面
print(names)
scores=content.xpath('//span[@class="rating_nums"]/text()')
print(scores)
pictures=content.xpath('//a[@class="nbg"]/img/@src') #这里存储的是图片的网址,并组成了一个列表
if not os.path.exists('pictures'): #创建一个文件夹os.mkdir('pictures')
for i in pictures: #便利每一张图片列表的元素resp=requests.get(url=i,headers=headers) #依次向每张图片发送get请求,获取响应信息name=i.split('/').pop() #以‘/’来分割,取图片网址的提取出最后一个斜杠后面的部分来作为名字with open('pictures/'+name,"wb")as f: #将图片名变为namef.write(resp.content) #将图片存入该目录
![PyTorch][chapter 12][李宏毅深度学习][Semi-supervised Linear Methods-1]](https://img-blog.csdnimg.cn/direct/c0f2d39aaac24825a7d136038020cc03.png)
![[Bug] [OpenAI] [TypeError: fetch failed] { cause: [Error: AggregateError] }](https://img-blog.csdnimg.cn/direct/c296b838dd2f433686f4228951741e07.png)