目录
一、背景
二、设计
三、具体实现
Filebeat配置
K8S SideCar yaml
Logstash配置
一、背景
将容器中服务的trace日志和应用日志收集到KAFKA,需要注意的是 trace 日志和app 日志需要存放在同一个KAFKA两个不同的topic中。分别为APP_TOPIC和TRACE_TOPIC
二、设计
流程图如下:
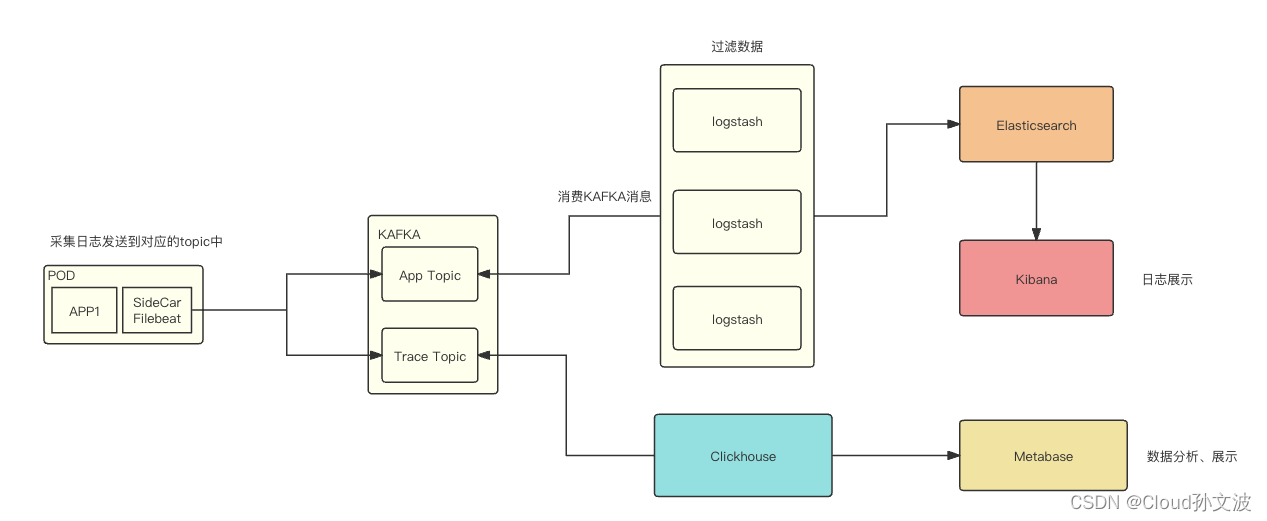
说明:
APP_TOPIC:主要存放服务的应用日志
TRACE_TOPIC:存放程序输出的trace日志,用于排查某一个请求的链路
文字说明:
filebeat 采集容器中的日志(这里需要定义一些规范,我们定义的容器日志路径如下),filebeat会采集两个不同目录下的日志,然后输出到对应的topic中,之后对kafka 的topic进行消费、存储。最终展示出来
/home/service/
└── logs├── app│ └── pass│ ├── 10.246.84.58-paas-biz-784c68f79f-cxczf.log│ ├── 1.log│ ├── 2.log│ ├── 3.log│ ├── 4.log│ └── 5.log└── trace├── 1.log├── 2.log├── 3.log├── 4.log├── 5.log└── trace.log4 directories, 13 files三、具体实现
上干货~
Filebeat配置
配置说明:
其中我将filebeat的一些配置设置成了变量,在接下来的k8s yaml文件中需要定义变量和设置变量的value。
需要特别说明的是我这里是使用了 tags: ["trace-log"]结合when.contains来匹配,实现将对应intput中的日志输出到对应kafka的topic中
filebeat.inputs:
- type: logenabled: truepaths:- /home/service/logs/trace/*.logfields_under_root: truefields:topic: "${TRACE_TOPIC}"json.keys_under_root: truejson.add_error_key: truejson.message_key: messagescan_frequency: 10smax_bytes: 10485760harvester_buffer_size: 1638400ignore_older: 24hclose_inactive: 1htags: ["trace-log"]processors:- decode_json_fields:fields: ["message"]process_array: falsemax_depth: 1target: ""overwrite_keys: true- type: logenabled: truepaths:- /home/service/logs/app/*/*.logfields:topic: "${APP_TOPIC}"scan_frequency: 10smax_bytes: 10485760harvester_buffer_size: 1638400close_inactive: 1htags: ["app-log"]output.kafka:enabled: truecodec.json:pretty: true # 是否格式化json数据,默认falsecompression: gziphosts: "${KAFKA_HOST}"topics:- topic: "${TRACE_TOPIC}"bulk_max_duration: 2sbulk_max_size: 2048required_acks: 1max_message_bytes: 10485760when.contains:tags: "trace-log"- topic: "${APP_TOPIC}"bulk_flush_frequency: 0bulk_max_size: 2048compression: gzipcompression_level: 4group_id: "k8s_filebeat"grouping_enabled: truemax_message_bytes: 10485760partition.round_robin:reachable_only: truerequired_acks: 1workers: 2when.contains:tags: "app-log"K8S SideCar yaml
配置说明:
该yaml中定一个两个容器,容器1为nginx(示例)容器2为filebeat容器。定义了一个名称为logs的emptryDir类型的卷,将logs卷同时挂载在了容器1和容器2的/home/service/logs目录
接下来又在filebeat容器中自定义了三个环境变量,这样我们就可以通过修改yaml的方式很灵活的来配置filebeat
TRACE_TOPIC: Trace日志的topic
APP_TOPIC:App日志的topic
KAFKA_HOST:KAFKA地址
apiVersion: apps/v1
kind: Deployment
metadata:labels:app: nginxname: nginxnamespace: default
spec:replicas: 2selector:matchLabels:app: nginxtemplate:metadata:labels:app: nginxspec:imagePullSecrets:- name: uhub-registrycontainers:- image: uhub.service.ucloud.cn/sre-paas/nginx:v1imagePullPolicy: IfNotPresentname: nginxports:- name: nginxcontainerPort: 80- mountPath: /home/service/logsname: logsterminationMessagePath: /dev/termination-logterminationMessagePolicy: FilevolumeMounts:- mountPath: /home/service/logsname: logs- env:- name: TRACE_TOPICvalue: pro_platform_monitor_log- name: APP_TOPICvalue: platform_logs- name: KAFKA_HOSTvalue: '["xxx.xxx.xxx.xxx:9092","xx.xxx.xxx.xxx:9092","xx.xxx.xxx.xxx:9092"]'- name: MY_POD_NAMEvalueFrom:fieldRef:apiVersion: v1fieldPath: metadata.nameimage: xxx.xxx.xxx.cn/sre-paas/filebeat-v2:8.11.2imagePullPolicy: Alwaysname: filebeatresources:limits:cpu: 150mmemory: 200Mirequests:cpu: 50mmemory: 100MisecurityContext:privileged: truerunAsUser: 0terminationMessagePath: /dev/termination-logterminationMessagePolicy: FilevolumeMounts:- mountPath: /home/service/logsname: logsdnsPolicy: ClusterFirstimagePullSecrets:- name: xxx-registryrestartPolicy: AlwaysschedulerName: default-schedulersecurityContext: {}terminationGracePeriodSeconds: 30volumes:- emptyDir: {}name: logs Logstash配置
input {kafka {type => "platform_logs"bootstrap_servers => "xxx.xxx.xxx.xxx:9092,xxx.xxx.xxx.xxx:9092,xxx.xxx.xxx.xxx:9092"topics => ["platform_logs"]group_id => 'platform_logs'client_id => 'open-platform-logstash-logs'}kafka {type => "platform_pre_log"bootstrap_servers => "xxx.xxx.xxx.xxx:9092,xxx.xxx.xxx.xxx:9092,xxx.xxx.xxx.xxx:9092"topics => ["pre_platform_logs"]group_id => 'pre_platform_logs'client_id => 'open-platform-logstash-pre'}kafka {type => "platform_nginx_log"bootstrap_servers => "xxx.xxx.xxx.xxx:9092,xxx.xxx.xxx.xxx:9092,xxx.xxx.xxx.xxx:9092"topics => ["platform_nginx_log"]group_id => 'platform_nginx_log'client_id => 'open-platform-logstash-nginx'}
}
filter {if [type] == "platform_pre_log" {grok {match => { "message" => "\[%{IP}-(?<service>[a-zA-Z-]+)-%{DATA}\]" }}}if [type] == "platform_logs" {grok {match => { "message" => "\[%{IP}-(?<service>[a-zA-Z-]+)-%{DATA}\]" }}}
}
output {if [type] == "platform_logs" {elasticsearch {id => "platform_logs"hosts => ["http://xxx.xxx.xxx.xxx:9200","http://xxx.xxx.xxx.xxx:9200","http://xxx.xxx.xxx.xxx:9200"]index => "log-xxx-prod-%{service}-%{+yyyy.MM.dd}"user => "logstash_transformer"password => "xxxxxxx"template_name => "log-xxx-prod"manage_template => "true"template_overwrite => "true"}}if [type] == "platform_pre_log" {elasticsearch {id => "platform_pre_logs"hosts => ["http://xxx.xxx.xxx.xxx:9200","http://xxx.xxx.xxx.xxx:9200","http://xxx.xxx.xxx.xxx:9200"]index => "log-xxx-pre-%{service}-%{+yyyy.MM.dd}"user => "logstash_transformer"password => "xxxxxxx"template_name => "log-xxx-pre"manage_template => "true"template_overwrite => "true"}}if [type] == "platform_nginx_log" {elasticsearch {id => "platform_nginx_log"hosts => ["http://xxx.xxx.xxx.xxx:9200","http://xxx.xxx.xxx.xxx:9200","http://xxx.xxx.xxx.xxx:9200"]index => "log-platform-nginx-%{+yyyy.MM.dd}"user => "logstash_transformer"password => "xxxxxxx"template_name => "log-platform-nginx"manage_template => "true"template_overwrite => "true"}}
}如果有帮助到你麻烦给个赞或者收藏一下~,有问题可以随时私聊我或者在评论区评论,我看到会第一时间回复




)






)







