深度强化学习(DRL)
本文是学习笔记,如有侵权,请联系删除。本文在ChatGPT辅助下完成。
参考链接
Deep Reinforcement Learning官方链接:https://github.com/wangshusen/DRL
源代码链接:https://github.com/DeepRLChinese/DeepRL-Chinese
B站视频:【王树森】深度强化学习(DRL)
豆瓣: 深度强化学习
文章目录
- 深度强化学习(DRL)
- 价值学习高级技巧
- 经验回放
- 经验回放的优点
- 经验回放的局限性
- 优先经验回放
- 高估问题及解决方法
- 自举导致偏差的传播
- 最大化导致高估
- 高估的危害
- 使用目标网络
- 双 Q 学习算法
- 总结
- 对决网络 (Dueling Network)
- 最优优势函数
- 对决网络
- 解决不唯一性
- 对决网络的实际实现
- 噪声网络
- 噪声网络的原理
- 噪声 DQN
- 训练流程
- 总结
- 后记
价值学习高级技巧
前面介绍了 DQN, 并且用 Q学习算法训练 DQN。如果用最原始的 Q 学习算法,那么训练出的 DQN 效果会很不理想。想要提升 DQN 的表现,需要用本章的高级技巧。文献中已经有充分实验结果表明这些高级技巧对 DQN 非常有效,而且这些技巧不冲突,可以一起使用。有些技巧并不局限于DQN,而是可以应用于多种价值学习和策略学习方法。
介绍经验回放 (experience replay) 和优先经验回放(prioritized experience replay)。讨论 DQN 的高估问题以及解决方案——目标网络(target network) 和双 Q 学习算法(double Q-learning)。
介绍两种方法改进 DQN 的神经网络结构 (不是对 Q 学习算法的改进):对决网络 (dueling network),它把动作价值 (action value) 分解成状态价值(state value) 与优势 (advantage);噪声网络 (noisy net), 它往神经网络的参数中加入随机噪声,鼓励探索。
经验回放
经验回放(experience replay)是强化学习中一个重要的技巧, 可以大幅提升强化学习的表现。经验回放的意思是把智能体与环境交互的记录 (即经验) 储存到一个数组里,事后反复利用这些经验训练智能体。这个数组被称为经验回放数组 (replay buffer)。
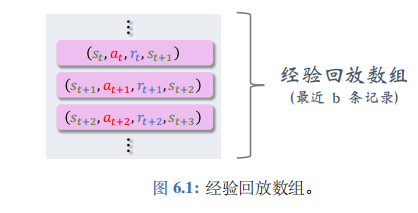
具体来说,把智能体的轨迹划分成 ( s t , a t , r t , s t + 1 ) (s_t,a_t,r_t,s_{t+1}) (st,at,rt,st+1)这样的四元组,存入一个数组。需要人为指定数组的大小 (记作 b b b)。数组中只保留最近 b b b 条数据;当数组存满之后,删除掉最旧的数据。数组的大小 b b b 是个需要调的超参数,会影响训练的结果。通常设置 b b b 为 1 0 5 ∼ 1 0 6 10^5\sim10^6 105∼106。
在实践中,要等回放数组中有足够多的四元组时,才开始做经验回放更新 DQN。根据论文的实验分析,如果将 DQN 用于 Atari 游戏,最好是在收集到 20 万条四元组时才开始做经验回放更新 DQN; 如果是用更好的 Rainbow DQN, 收集到 8 万条四元组时就可以开始更新 DQN。在回放数组中的四元组数量不够的时候,DQN 只与环境交互, 而不去更新 DQN 参数,否则实验效果不好。
经验回放的优点
经验回放的一个好处在于打破序列的相关性。训练 DQN 的时候,每次我们用一个四元组对 DQN 的参数做一次更新。我们希望相邻两次使用的四元组是独立的。然而当智能体收集经验的时候,相邻两个四元组 ( s t , a t , r t , s t + 1 ) (s_t,a_t,r_t,s_{t+1}) (st,at,rt,st+1) 和 ( s t + 1 , a t + 1 , r t + 1 , s t + 2 ) (s_{t+1},a_{t+1},r_{t+1},s_{t+2}) (st+1,at+1,rt+1,st+2) 有很强的相关性。依次使用这些强关联的四元组训练 DQN, 效果往往会很差。经验回放每次从数组里随机抽取一个四元组,用来对 DQN 参数做一次更新。这样随机抽到的四元组都是独立的,消除了相关性。
经验回放的另一个好处是重复利用收集到的经验、而不是用一次就丢弃,这样可以用更少的样本数量达到同样的表现。重复利用经验、不重复利用经验的收敛曲线通常如图 6.2 所示。图的横轴是样本数量,纵轴是平均回报。
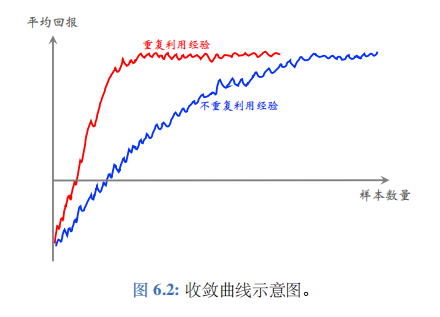
注 在阅读文献的时候请注意“样本数量"(sample complexity) 与“更新次数"两者的区别。样本数量是指智能体从环境中获取的奖励 r r r 的数量。而一次更新的意思是从经验回放数组里取出一个或多个四元组,用它对参数 w w w 做一次更新。通常来说,样本数量更重要, 因为在实际应用中收集经验比较困难。比如,在机器人的应用中, 需要在现实世界做一次实验才能收集到一条经验,花费的时间和金钱远大于做一次计算。相对而言,做更新的次数不是那么重要,更新次数只会影响训练时的计算量而已。
经验回放的局限性
需要注意,并非所有的强化学习方法都允许重复使用过去的经验。经验回放数组里的数据全都是用行为策略 (behavior policy) 控制智能体收集到的。在收集经验同时,我们也在不断地改进策略。策略的变化导致收集经验时用的行为策略是过时的策略,不同于当前我们想要更新的策略——即目标策略(target policy)。也就是说,经验回放数组中的经验通常是过时的行为策略收集的,而我们真正想要学的目标策略不同于过时的行为策略。
有些强化学习方法允许行为策略不同于目标策略。这样的强化学习方法叫做异策略(off-policy)。比如 Q \mathbb{Q} Q 学习、确定策略梯度 (DPG) 都属于异策略。由于它们允许行为策略不同于目标策略,过时的行为策略收集到的经验可以被重复利用。经验回放适用于异策略。
有些强化学习方法要求行为策略与目标策略必须相同。这样的强化学习方法叫做同策略 (on-policy)。比如 SARSA、REINFORCE、A2C 都属于同策略。它们要求经验必须是当前的目标策略收集到的,而不能使用过时的经验。经验回放不适用于同策略。
优先经验回放
优先经验回放 (prioritized experience replay) 是一种特殊的经验回放方法,它比普通的经验回放效果更好:既能让收敛更快,也能让收敛时的平均回报更高。经验回放数组里有 b b b 个四元组,普通经验回放每次均匀抽样得到一个样本——即四元组 ( s j , a j , r j , s j + 1 ) (s_j,a_j,r_j,s_{j+1}) (sj,aj,rj,sj+1). 用它来更新 DQN 的参数。优先经验回放给每个四元组一个权重,然后根据权重做非均匀随机抽样。如果 DQN 对 ( s j , a j ) (s_j,a_j) (sj,aj) 的价值判断不准确,即 Q ( s j , a j ; w ) Q(s_j,a_j;\boldsymbol{w}) Q(sj,aj;w) 离 Q ⋆ ( s j , a j ) Q_\star(s_j,a_j) Q⋆(sj,aj) 较远,则四元组 ( s j , a j , r j , s j + 1 ) (s_j,a_j,r_j,s_{j+1}) (sj,aj,rj,sj+1) 应当有较高的权重。
为什么样本的重要性会有所不同呢?设想你用强化学习训练一辆无人车。经验回放数组中的样本绝大多数都是车辆正常行驶的情形,只有极少数样本是意外情况,比如旁边车辆强行变道、行人横穿马路、警察封路要求绕行。数组中的样本的重要性显然是不同的。绝大多数的样本都是车辆正常行驶,而且正常行驶的情形很容易处理,出错的可能性非常小。意外情况的样本非常少,但是又极其重要,处理不好就会车毁人亡。所以意外情况的样本应当有更高的权重,受到更多关注。这两种样本不应该同等对待。
如何自动判断哪些样本更重要呢?举个例子,自动驾驶中的意外情况数量少、而且难以处理,导致 DQN 的预测 Q ( s j , a j ; w ) Q(s_j,a_j;\boldsymbol{w}) Q(sj,aj;w) 严重偏离真实价值 Q ⋆ ( s j , a j ) Q_\star(s_j,a_j) Q⋆(sj,aj)。因此,要是 ∣ Q ( s j , a j ; w ) − Q ⋆ ( s j , a j ) ∣ \left|Q(s_j,a_j;\boldsymbol{w})-Q_\star(s_j,a_j)\right| ∣Q(sj,aj;w)−Q⋆(sj,aj)∣较大,则应该给样本 ( s j , a j , r j , s j + 1 ) (s_j,a_j,r_j,s_{j+1}) (sj,aj,rj,sj+1) 较高的权重。然而实际上我们不知道 Q ⋆ Q_\star Q⋆,因此无从得知 ∣ Q ( s j , a j ; w ) − Q ⋆ ( s j , a j ) ∣ \left|Q(s_j,a_j;\boldsymbol{w})-Q_\star(s_j,a_j)\right| ∣Q(sj,aj;w)−Q⋆(sj,aj)∣。不妨把它替换成 TD 误差。回忆一下,TD 误差的定义是:
δ j = Δ Q ( s j , a j ; w n o w ) − [ r t + γ ⋅ max a ∈ A Q ( s j + 1 , a ; w n o w ) ] ⏟ 即 TP 目标 . \begin{array}{rcl}\delta_j&\stackrel{\Delta}{=}&Q\big(s_j,a_j;\boldsymbol{w_\mathrm{now}}\big)\:-\underbrace{\left[r_t+\gamma\cdot\max_{a\in\mathcal{A}}Q\big(s_{j+1},a;\boldsymbol{w_\mathrm{now}}\big)\right]}_{\text{即 TP 目标}}.\end{array} δj=ΔQ(sj,aj;wnow)−即 TP 目标 [rt+γ⋅a∈AmaxQ(sj+1,a;wnow)].
如果 TD 误差的绝对值 ∣ δ j ∣ |\delta_j| ∣δj∣ 大,说明 DQN 对 ( s j , a j ) (s_j,a_j) (sj,aj) 的真实价值的评估不准确,那么应该给 ( s j , a j , r j , s j + 1 ) (s_j,a_j,r_j,s_{j+1}) (sj,aj,rj,sj+1) 设置较高的权重。
优先经验回放对数组里的样本做非均匀抽样。四元组 ( s j , a j , r j , s j + 1 ) (s_j,a_j,r_j,s_{j+1}) (sj,aj,rj,sj+1) 的权重是 TD 误差的绝对值 ∣ δ j ∣ |\delta_j| ∣δj∣。有两种方法设置抽样概率。一种抽样概率是:
p j ∝ ∣ δ j ∣ + ϵ . p_j\:\propto\:|\delta_j|+\epsilon. pj∝∣δj∣+ϵ.
此处的 ϵ \epsilon ϵ是个很小的数,防止抽样概率接近零,用于保证所有样本都以非零的概率被抽到。另一种抽样方式先对 ∣ δ j ∣ |\delta_j| ∣δj∣ 做降序排列,然后计算
p j ∝ 1 rank ( j ) . p_j\propto\frac{1}{\operatorname{rank}(j)}. pj∝rank(j)1.
此处的 rank ( j ) \operatorname{rank}(j) rank(j) 是 ∣ δ j ∣ |\delta_j| ∣δj∣的序号。大的 ∣ δ j ∣ |\delta_j| ∣δj∣的序号小,小的 ∣ δ j ∣ |\delta_j| ∣δj∣的序号大。两种方式的原理是一样的, ∣ δ j ∣ |\delta_j| ∣δj∣大的样本被抽样到的概率大。
优先经验回放做非均匀抽样,四元组 ( s j , a j , r j , s j + 1 ) (s_j,a_j,r_j,s_{j+1}) (sj,aj,rj,sj+1) 被抽到的概率是 p j p_j pj。抽样是非均匀的,不同的样本有不同的抽样概率,这样会导致 DQN 的预测有偏差。应该相应调整学习率,抵消掉不同抽样概率造成的偏差。TD 算法用“随机梯度下降”来更新参数:
w n e w ← w n o w − α ⋅ g , w_\mathrm{new}~\leftarrow~w_\mathrm{now}-\alpha\cdot g, wnew ← wnow−α⋅g,
此处的α是学习率, g g g 是损失函数关于 w w w 的梯度。如果用均匀抽样,那么所有样本有相同的学习率 α \alpha α。如果做非均匀抽样的话,应该根据抽样概率来调整学习率 α \alpha α。如果一条样本被抽样的概率大,那么它的学习率就应该比较小。可以这样设置学习率:
α j = α ( b ⋅ p j ) β , \alpha_{j}\:=\:\frac{\alpha}{(b\cdot p_{j})^{\beta}}, αj=(b⋅pj)βα,
此处的 b b b 是经验回放数组中样本的总数, β ∈ ( 0 , 1 ) \beta\in(0,1) β∈(0,1) 是个需要调的超参数(论文里建议一开始让 β \beta β 比较小,最终增长到 1)。
注 均匀抽样是一种特例,即所有抽样概率都相等 : p 1 = ⋯ = p b = 1 b :p_1=\cdots=p_b=\frac1b :p1=⋯=pb=b1。在这种情况下,有 ( b ⋅ p j ) β = 1 (b\cdot p_{j})^{\beta}=1 (b⋅pj)β=1, 因此学习率都相同 : α 1 = ⋯ = α b = α o :\alpha_{1}=\cdots=\alpha_{b}=\alpha_{o} :α1=⋯=αb=αo
注 读者可能会问下面的问题。如果样本 ( s j , a j , r j , s j + 1 ) (s_j,a_j,r_j,s_{j+1}) (sj,aj,rj,sj+1) 很重要,它被抽到的概率 p j p_j pj 很大,可是它的学习率却很小。当 β = 1 \beta=1 β=1 时,如果抽样概率 p j p_j pj 变大 10 倍,则学习率 α j \alpha_j αj 减小 10 倍。抽样概率、学习率两者岂不是抵消了吗,那么优先经验回放有什么意义呢?大抽样概率、小学习率两者其实并没有抵消,因为下面两种方式并不等价:
- 设置学习率为 α \alpha α,使用样本 ( s j , a j , r j , s j + 1 ) (s_j,a_j,r_j,s_{j+1}) (sj,aj,rj,sj+1) 计算一次梯度,更新一次参数 w w w ;
- 设置学习率为 α 10 \frac\alpha{10} 10α, 使用样本 ( s j , a j , r j , s j + 1 ) (s_j,a_j,r_j,s_{j+1}) (sj,aj,rj,sj+1) 计算十次梯度,更新十次参数 w w w。
乍看起来两种方式区别不大,但其实第二种方式是对样本更有效的利用。第二种方式的缺点在于计算量大了十倍,所以第二种方式只被用于重要的样本。
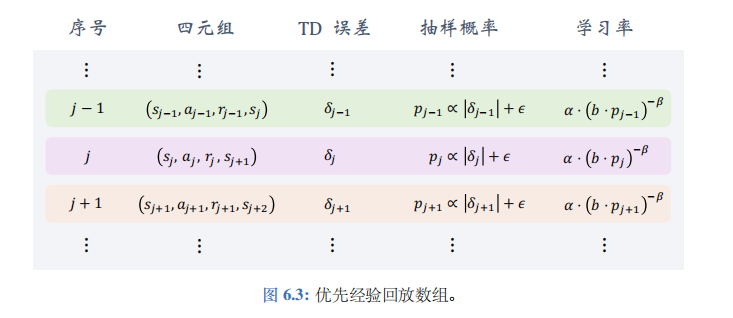
优先经验回放数组如图 6.3 所示。设 b b b 为数组大小,需要手动调整。如果样本 (即四元组) 的数量超过了 b b b,那么要删除最旧的样本。数组里记录了四元组、TD 误差、抽样概率、以及学习率。注意,数组里存的 TD 误差 δ j \delta_j δj 是用很多步之前过时的 DQN 参数计算出来的:
δ j = Q ( s j , a j ; w o l d ) − [ r t + γ ⋅ max a ∈ A Q ( s j + 1 , a ; w o l d ) ] . \delta_{j}\:=\:Q\big(s_{j},a_{j};\:\boldsymbol{w_{\mathrm{old}}}\big)\:-\:\Big[r_{t}+\gamma\cdot\max_{a\in\mathcal{A}}Q\big(s_{j+1},a;\:\boldsymbol{w_{\mathrm{old}}}\big)\Big]. δj=Q(sj,aj;wold)−[rt+γ⋅a∈AmaxQ(sj+1,a;wold)].
做经验回放的时候,每次取出一个四元组,用它计算出新的 TD 误差:
δ j ′ = Q ( s j , a j ; w n o w ) − [ r t + γ ⋅ max a ∈ A Q ( s j + 1 , a ; w n o w ) ] , \delta_{j}^{\prime}\:=\:Q\big(s_{j},a_{j};\:w_{\mathrm{now}}\big)\:-\:\Big[r_{t}+\gamma\cdot\max_{a\in\mathcal{A}}Q\big(s_{j+1},a;\:\boldsymbol{w_{\mathrm{now}}}\big)\Big], δj′=Q(sj,aj;wnow)−[rt+γ⋅a∈AmaxQ(sj+1,a;wnow)],
然后用它更新 DQN 的参数。用这个新的 δ j ′ \delta_j^{\prime} δj′ 取代数组中旧的 δ j \delta_{j} δj。
高估问题及解决方法
Q 学习算法有一个缺陷:用 Q 学习训练出的 DQN 会高估真实的价值,而且高估通常是非均匀的。这个缺陷导致 DQN 的表现很差。高估问题并不是 DQN 模型的缺陷,而是 Q 学习算法的缺陷。 Q \mathbb{Q} Q 学习产生高估的原因有两个:第一,自举导致偏差的传播;第二,最大化导致 TD 目标高估真实价值。为了缓解高估,需要从导致高估的两个原因下手,改进 Q \mathbb{Q} Q学习算法。双 Q \mathbb{Q} Q学习算法是一种有效的改进,可以大幅缓解高估及其危害。
自举导致偏差的传播
在强化学习中,自举意思是“用一个估算去更新同类的估算”,类似于“自己把自己给举起来”。我们在前面的笔记中讨论过 SARSA 算法中的自举。下面回顾训练 DQN 用的 Q学习算法,研究其中存在的自举。算法每次从经验回放数组中抽取一个四元组 ( s j , a j , r j , s j + 1 ) (s_j,a_j,r_j,s_{j+1}) (sj,aj,rj,sj+1)。然后执行以下步骤,对 DQN 的参数做一轮更新:
1.计算TD目标:
y ^ j = r j + γ ⋅ max a j + 1 ∈ A Q ( s j + 1 , a j + 1 ; w n o w ) ⏟ DQN 自己做出的估计 \widehat y_j\:=\:r_j\:+\:\gamma\cdot\underbrace{\max_{a_{j+1}\in\mathcal{A}}Q\big(s_{j+1},a_{j+1};\:\boldsymbol{w_\mathrm{now}}\big)}_{\text{DQN 自己做出的估计}} y j=rj+γ⋅DQN 自己做出的估计 aj+1∈AmaxQ(sj+1,aj+1;wnow)
2.定义损失函数
L ( w ) = 1 2 [ Q ( s j , a j ; w ) − y j ^ ⏟ 让DQN 拟合 y j ^ ] 2 . L(\boldsymbol{w})\:=\:\frac{1}{2}\Big[\:\underbrace{Q(s_{j},a_{j};\boldsymbol{w})\:-\:\widehat{y_{j}}}_{\text{让DQN 拟合}\:\widehat{y_{j}}}\Big]^{2}. L(w)=21[让DQN 拟合yj Q(sj,aj;w)−yj ]2.
3.把 y ^ j \widehat{y}_j y j看做常数,做一次梯度下降更新参数:
w n e w ← w n o w − α ⋅ ∇ w L ( w n o w ) . w_\mathrm{new}\:\leftarrow\:w_\mathrm{now}-\:\alpha\cdot\nabla_{\boldsymbol{w}}L(\boldsymbol{w_\mathrm{now}}). wnew←wnow−α⋅∇wL(wnow).
第一步中的 TD 目标 y ^ j \hat{y}_j y^j 部分基于 DQN 自己做出的估计。第二步让 DQN 去拟合 y ^ j \hat{y}_j y^j。这就意味着我们用了 DQN 自己做出的估计去更新 DQN 自己,这属于自举。
自举对 DQN 的训练有什么影响呢? Q ( s , a ; w ) Q(s,a;w) Q(s,a;w) 是对价值 Q ⋆ ( s , a ) Q_\star(s,a) Q⋆(s,a) 的近似,最理想的情况下, Q ( s , a ; w ) = Q ⋆ ( s , a ) Q(s,a;\boldsymbol{w})=Q_\star(s,a) Q(s,a;w)=Q⋆(s,a), ∀ s , a \forall s,a ∀s,a。假如碰巧 Q ( s j + 1 , a j + 1 ; w ) Q(s_{j+1},a_{j+1};\boldsymbol{w}) Q(sj+1,aj+1;w)低估(或高估)真实价值 Q ⋆ ( s j + 1 , a j + 1 ) Q_\star(s_{j+1},a_{j+1}) Q⋆(sj+1,aj+1), 则会发生下面的情况:
Q ( s j + 1 , a j + 1 ; w ) 低估(或高估) Q ⋆ ( s j + 1 , a j + 1 ) ⟹ y j ^ 低估(或高估) Q ⋆ ( s j , a j ) ⟹ Q ( s j , a j ; w ) 低估(或高估) Q ⋆ ( s j , a j ) . \begin{array}{cccc}&Q(s_{j+1},a_{j+1};\boldsymbol{w})&\text{低估(或高估)}&Q_{\star}(s_{j+1},a_{j+1})\\\implies&\widehat{y_j}&\text{低估(或高估)}&Q_{\star}(s_j,a_j)\\\implies&Q(s_j,a_j;\boldsymbol{w})&\text{低估(或高估)}&Q_{\star}(s_j,a_j).\end{array} ⟹⟹Q(sj+1,aj+1;w)yj Q(sj,aj;w)低估(或高估)低估(或高估)低估(或高估)Q⋆(sj+1,aj+1)Q⋆(sj,aj)Q⋆(sj,aj).

如果 Q ( s j + 1 , a j + 1 ; w ) Q(s_{j+1},a_{j+1};\boldsymbol{w}) Q(sj+1,aj+1;w) 是对真实价值 Q ⋆ ( s j + 1 , a j + 1 ) Q_\star(s_{j+1},a_{j+1}) Q⋆(sj+1,aj+1) 的低估 (或高估), 就会导致 Q ( s j , a j ; w ) Q(s_j,a_j;\boldsymbol{w}) Q(sj,aj;w) 低估 (或高估) 价值 Q ⋆ ( s j , a j ) Q_\star(s_j,a_j) Q⋆(sj,aj)。也就是说低估 (或高估) 从 ( s j + 1 , a j + 1 ) (s_{j+1},a_{j+1}) (sj+1,aj+1)传播到 ( s j , a j ) (s_j,a_j) (sj,aj), 让更多的价值被低估 (或高估)。
最大化导致高估
首先用数学解释为什么最大化会导致高估。设 x 1 , ⋯ , x d x_1,\cdots,x_d x1,⋯,xd 为任意 d d d 个实数。往 x 1 x_1 x1, ⋯ , x d \cdots,x_d ⋯,xd 中加入任意均值为零的随机噪声,得到 Z 1 , ⋯ , Z d Z_1,\cdots,Z_d Z1,⋯,Zd, 它们是随机变量,随机性来源于随机噪声。很容易证明均值为零的随机噪声不会影响均值:
E [ mean ( Z 1 , ⋯ , Z d ) ] = m e a n ( x 1 , ⋯ , x d ) . \mathbb{E}\Big[\text{mean}\left(Z_1,\cdots,Z_d\right)\Big]\:=\:\mathrm{mean}\left(x_1,\cdots,x_d\right). E[mean(Z1,⋯,Zd)]=mean(x1,⋯,xd).
用稍微复杂一点的证明,可以得到:
E [ max ( Z 1 , ⋯ , Z d ) ] ≥ max ( x 1 , ⋯ , x d ) . \mathbb{E}\Big[\max\left(Z_1,\cdots,Z_d\right)\Big]\:\geq\:\max\left(x_1,\cdots,x_d\right). E[max(Z1,⋯,Zd)]≥max(x1,⋯,xd).
公式中的期望是关于噪声求的。这个不等式意味着先加入均值为零的噪声,然后求最大值,会产生高估。
假设对于所有的动作 a ∈ A a\in\mathcal{A} a∈A 和状态 s ∈ S s\in\mathcal{S} s∈S, DQN 的输出是真实价值 Q ⋆ ( s , a ) Q_{\star}(s,a) Q⋆(s,a) 加上均值为零的随机噪声 ϵ : \epsilon{:} ϵ:
Q ( s , a ; w ) = Q ⋆ ( s , a ) + ϵ . Q\left(s,a;\boldsymbol{w}\right)\:=\:Q_{\star}\big(s,a\big)+\epsilon. Q(s,a;w)=Q⋆(s,a)+ϵ.
显然 Q ( s , a ; w ) Q(s,a;\boldsymbol{w}) Q(s,a;w) 是对真实价值 Q ⋆ ( s , a ) Q_\star(s,a) Q⋆(s,a) 的无偏估计。然而有这个不等式:
E ϵ [ max a ∈ A Q ( s , a ; w ) ] ≥ max a ∈ A Q ⋆ ( s , a ) . \mathbb{E}_\epsilon\Big[\max\limits_{a\in\mathcal{A}}Q(s,a;\boldsymbol{w})\Big]\geq\max\limits_{a\in\mathcal{A}}Q_\star(s,a). Eϵ[a∈AmaxQ(s,a;w)]≥a∈AmaxQ⋆(s,a).
公式说明哪怕 DQN 是对真实价值的无偏估计,但是如果求最大化,DQN 就会高估真实价值。复习一下,TD 目标是这样算出来的:
y ^ j = r j + γ ⋅ max a ∈ A Q ( s j + 1 , a ; w ) ⏟ 高估 max a ∈ A Q ⋆ ( s j + 1 , a ) . \widehat{y}_{j}\:=\:r_{j}\:+\:\gamma\cdot\underbrace{\max_{a\in\mathcal{A}}\:Q\big(s_{j+1},a;\:\boldsymbol{w}\big)}_{\text{高估}\:\max_{a\in\mathcal{A}}Q_{\star}(s_{j+1},a)}\:. y j=rj+γ⋅高估maxa∈AQ⋆(sj+1,a) a∈AmaxQ(sj+1,a;w).
这说明 TD 目标 y ^ j \widehat{y}_j y j 通常是对真实价值 Q ⋆ ( s j , a j ) Q_\star(s_j,a_j) Q⋆(sj,aj) 的高估。TD 算法鼓励 Q ( s j , a j ; w ) Q(s_j,a_j;\boldsymbol{w}) Q(sj,aj;w) 接近TD 目标 y ^ j \widehat{y}_j y j, 这会导致 Q ( s j , a j ; w ) Q(s_j,a_j;w) Q(sj,aj;w) 高估真实价值 Q ⋆ ( s j , a j ) Q_\star(s_j,a_j) Q⋆(sj,aj)。

即使 DQN 是真实价值 Q ⋆ Q_{\star} Q⋆ 的无偏估计,只要 DQN 不恒等于 Q ⋆ Q_{\star} Q⋆, TD 目标就会高估真实价值。TD 目标是高估,而 Q \mathbb{Q} Q学习算法鼓励 DQN 预测接近 TD 目标,因此DQN 会出现高估。
高估的危害
我们为什么要避免高估?高估真的有害吗?如果高估是均匀的,则高估没有危害;如果高估非均匀,就会有危害。举个例子,动作空间是 A = { 左,右,上 } A= \{ 左,右,上\} A={左,右,上}。给定当前状态 s s s, 每个动作有一个真实价值:
Q ⋆ ( s , 左 ) = 200 , Q ⋆ ( s , 右 ) = 100 , Q ⋆ ( s , 上 ) = 230. Q_{\star}(s,\text{左})\:=\:200,\quad Q_{\star}(s,\text{右})\:=\:100,\quad Q_{\star}(s,\text{上})\:=\:230. Q⋆(s,左)=200,Q⋆(s,右)=100,Q⋆(s,上)=230.
智能体应当选择动作“上”,因为“上”的价值最高。假如高估是均匀的,所有的价值都被高估了100:
Q ( s , 左 ; w ) = 300 , Q ( s , t ; w ) = 200 , Q ( s , 上 ; w ) = 330. Q\big(s,左;\:\boldsymbol{w}\big)\:=\:300,\quad Q\big(s,\boldsymbol{t};\:\boldsymbol{w}\big)\:=\:200,\quad Q\big(s,\:\text{上};\:\boldsymbol{w}\big)\:=\:330. Q(s,左;w)=300,Q(s,t;w)=200,Q(s,上;w)=330.
那么动作“上”仍然有最大的价值,智能体会选择“上”。这个例子说明高估本身不是问题, 只要所有动作价值被同等高估。
但实践中,所有的动作价值会被同等高估吗?每当取出一个四元组 ( s , a , r , s ′ ) (s,a,r,s^{\prime}) (s,a,r,s′) 用来更新一次 DQN, 就很有可能加重 DQN 对 Q ⋆ ( s , a ) Q_{\star}(s,a) Q⋆(s,a) 的高估。对于同一个状态 s s s, 三种组合 ( s , 左 ) (s,左) (s,左)、 ( s , 右 ) (s,右) (s,右)、 ( s , 上 ) (s,上) (s,上)出现在经验回放数组中的频率是不同的,所以三种动作被高估的程度是不同的。假如动作价值被高估的程度不同,比如
Q ( s , 左 ; w ) = 280 , Q ( s , 右 ; w ) = 300 , Q ( s , 上 ; w ) = 260 , Q\big(s,\text{左};\boldsymbol{w}\big)\:=\:280,\quad Q\big(s,\text{右};\boldsymbol{w}\big)\:=\:300,\quad Q\big(s,\text{上};\boldsymbol{w}\big)\:=\:260, Q(s,左;w)=280,Q(s,右;w)=300,Q(s,上;w)=260,
那么智能体做出的决策就是向右走,因为“右”的价值貌似最高。但实际上“右”是最差的动作,它的实际价值低于其余两个动作。
综上所述,用 Q \mathbb{Q} Q学习算法训练 DQN 总会导致 DQN 高估真实价值。对于多数的 s ∈ S s\in S s∈S 和 a ∈ A a\in\mathcal{A} a∈A, 有这样的不等式:
Q ( s , a ; w ) > Q ⋆ ( s , a ) . Q(s,a;\boldsymbol{w})\:>\:Q_{\star}(s,a). Q(s,a;w)>Q⋆(s,a).
高估本身不是问题,真正的麻烦在于DQN 的高估往往是非均匀的。如果 DQN 有非均匀的高估,那么用 DQN 做出的决策是不可靠的。我们已经分析过导致高估的原因:
-
TD 算法属于“自举”,即用 DQN 的估计值去更新 DQN 自己。自举会导致偏差的传播。如果 Q ( s j + 1 , a j + 1 ; w ) Q(s_{j+1},a_{j+1};\boldsymbol{w}) Q(sj+1,aj+1;w) 是对 Q ⋆ ( s j + 1 , a j + 1 ) Q_\star(s_{j+1},a_{j+1}) Q⋆(sj+1,aj+1) 的高估,那么高估会传播到 ( s j , a j ) j (s_j,a_j)_j (sj,aj)j 让 Q ( s j , a j ; w ) Q(s_j,a_j;\boldsymbol{w}) Q(sj,aj;w) 高估 Q ⋆ ( s j , a j ) Q_\star(s_j,a_j) Q⋆(sj,aj)。自举导致 DQN 的高估从一个二元组 ( s , a ) (s,a) (s,a) 传播到更多的二元组。
-
TD 目标 y ^ \hat{y} y^ 中包含一项最大化,这会导致 TD 目标高估真实价值 Q ⋆ Q_{\star} Q⋆。Q 学习算法鼓励 DQN 的预测接近 TD 目标,因此 DQN 会高估 Q ⋆ Q_{\star} Q⋆。
找到了产生高估的原因,就可以想办法解决问题。想要避免 DQN 的高估,要么切断自举,要么避免最大化造成高估。注意,高估并不是 DQN 自身的属性,高估纯粹是算法造成的。想要避免高估,就要用更好的算法替代原始的 Q 学习算法。
使用目标网络
上文已经讨论过,切断“自举”可以避免偏差的传播,从而缓解 DQN 的高估。回顾一下,Q 学习算法这样计算 TD 目标:
y ^ j = r j + γ ⋅ max a ∈ A Q ( s j + 1 , a ; w ) ⏟ DQN做出的估计 . \widehat{y}_{j}\:=\:r_{j}\:+\:\underbrace{\gamma\cdot\max_{a\in\mathcal{A}}Q(s_{j+1},a;\:\boldsymbol{w})}_{\text{DQN做出的估计}}\:. y j=rj+DQN做出的估计 γ⋅a∈AmaxQ(sj+1,a;w).
然后做梯度下降更新 w w w,使得 Q ( s j , a j ; w ) Q(s_j,a_j;\boldsymbol{w}) Q(sj,aj;w)更接近 y ^ j \widehat{y}_j y j。想要切断自举,可以用另一个神经网络计算 TD 目标,而不是用 DQN 自己计算 TD 目标。另一个神经网络被称作目标网络 (target network) 。把目标网络记作:
Q ( s , a ; w − ) . Q(s,a;\boldsymbol{w}^{-}). Q(s,a;w−).
它的神经网络结构与 DQN 完全相同,但是参数 w − w^- w− 不同于 w w w。
使用目标网络的话,Q 学习算法用下面的方式实现。每次随机从经验回放数组中取一个四元组,记作 ( s j , a j , r j , s j + 1 ) (s_j,a_j,r_j,s_{j+1}) (sj,aj,rj,sj+1)。设 DQN 和目标网络当前的参数分别为 w n o w w_\mathrm{now} wnow 和 w n o w ˉ \bar{w_\mathrm{now}} wnowˉ,
执行下面的步骤对参数做一次更新:
1.对 DQN 做正向传播,得到:
q ^ j = Q ( s j , a j ; w n o w ) . \widehat q_{j}\:=\:Q\big(s_{j},a_{j};\:\boldsymbol{w_{\mathrm{now}}}\big). q j=Q(sj,aj;wnow).
2.对目标网络做正向传播,得到
q ^ j + 1 − = max a ∈ A Q ( s j + 1 , a ; w n o w − ) . \widehat q_{j+1}^{-}\:=\:\max_{a\in\mathcal{A}}Q\big(s_{j+1},a;\:\boldsymbol{w_{\mathrm{now}}^{-}}\big). q j+1−=a∈AmaxQ(sj+1,a;wnow−).
3.计算 TD 目标和 TD 误差:
y ^ j − = r j + γ ⋅ q ^ j + 1 − 和 δ j = q ^ j − y ^ j − . \widehat y_{j}^{-}\:=\:r_{j}+\gamma\cdot\widehat q_{j+1}^{-}\quad\text{和}\quad\delta_{j}\:=\:\widehat q_{j}-\widehat y_{j}^{-}. y j−=rj+γ⋅q j+1−和δj=q j−y j−.
4.对 DQN 做反向传播,得到梯度 ∇ w Q ( s j , a j ; w n o w ) \nabla_wQ(s_j,a_j;\boldsymbol{w}_\mathrm{now}) ∇wQ(sj,aj;wnow)。
5.做梯度下降更新 DQN 的参数:
w n e w ← w n o w − α ⋅ δ j ⋅ ∇ w Q ( s j , a j ; w n o w ) . \boldsymbol{w_\mathrm{new}}\:\leftarrow\:\boldsymbol{w_\mathrm{now}}\:-\:\alpha\:\cdot\:\delta_{j}\:\cdot\:\nabla_{\boldsymbol{w}}\:Q\big(s_{j},a_{j};\:\boldsymbol{w_\mathrm{now}}\big). wnew←wnow−α⋅δj⋅∇wQ(sj,aj;wnow).
6.设 τ ∈ ( 0 , 1 ) \tau\in(0,1) τ∈(0,1) 是需要手动调的超参数。做加权平均更新目标网络的参数:
w n e w ˉ ← τ ⋅ w n e w + ( 1 − τ ) ⋅ w n o w − . \bar{w_\mathrm{new}}\:\leftarrow\:\tau\cdot\boldsymbol{w_\mathrm{new}}\:+\:\left(1-\tau\right)\cdot\boldsymbol{w_\mathrm{now}^-}. wnewˉ←τ⋅wnew+(1−τ)⋅wnow−.

如图 6.4 (左) 所示,原始的 Q学习算法用 DQN 计算 y ^ \widehat{y} y ,然后拿 y ^ \hat{y} y^ 更新 DQN 自己, 造成自举。如图 6.4(右)所示,可以改用目标网络计算 y ^ \widehat{y} y ,这样就避免了用 DQN 的估计更新 DQN 自己,降低自举造成的危害。然而这种方法不能完全避免自举,原因是目标网络的参数仍然与 DQN 相关。
双 Q 学习算法
造成 DQN 高估的原因不是 DQN 模型本身的缺陷,而是 Q 学习算法有不足之处:第一,自举造成偏差的传播;第二,最大化造成 TD 目标的高估。在 Q 学习算法中使用目标网络,可以缓解自举造成的偏差,但是无助于缓解最大化造成的高估。本小节介绍双 Q \mathbb{Q} Q 学习 (double Q learning) 算法,它在目标网络的基础上做改进,缓解最大化造成的高估。
注 本小节介绍的双 Q 学习算法在文献中被称作 double DQN, 缩写 DDQN。本书不采用DDQN这名字,因为这个名字比较误导。双 Q 学习 (即所谓的 DDQN) 只是一种 TD 算法而已,它可以把 DQN 训练得更好。双 Q 学习并没有用区别于 DQN 的模型。本节中的模型只有一个,就是 DQN。我们讨论的只是训练 DQN 的三种 TD 算法:原始的 Q 学习、 用目标网络的 Q 学习、双 Q 学习。
为了解释原始的 Q 学习、用目标网络的 Q 学习、以及双 Q 学习三者的区别,我们再回顾一下Q 学习算法中的 TD 目标:
y ^ j = r j + γ ⋅ max a ∈ A Q ( s j + 1 , a ; w ) . \widehat y_j\:=\:r_j\:+\:\gamma\cdot\max_{a\in\mathcal{A}}Q\left(s_{j+1},a;\:\boldsymbol{w}\right). y j=rj+γ⋅a∈AmaxQ(sj+1,a;w).
不妨把最大化拆成两步:
1.选择——即基于状态 s j + 1 s_{j+1} sj+1,选出一个动作使得 DQN 的输出最大化:
a ⋆ = argmax a ∈ A Q ( s j + 1 , a ; w ) . a^{\star}\:=\:\underset{a\in\mathcal{A}}{\operatorname*{argmax}}\:Q\left(s_{j+1},a;\:\boldsymbol{w}\right). a⋆=a∈AargmaxQ(sj+1,a;w).
2.求值——即计算 ( s j + 1 , a ⋆ ) (s_{j+1},a^\star) (sj+1,a⋆) 的价值,从而算出 TD 目标:
y ^ j = r j + Q ( s j + 1 , a ⋆ ; w ) . \widehat{y}_{j}\:=\:r_{j}+Q(s_{j+1},a^{\star};\:\boldsymbol{w}). y j=rj+Q(sj+1,a⋆;w).
以上是原始的 Q 学习算法,选择和求值都用 DQN。上一小节改进了 Q 学习,选择和求值都用目标网络:
选择: a − = a r g m a x a ∈ A Q ( s j + 1 , a ; w − ) , 求值: y ~ j = r j + Q ( s j + 1 , a − ; w − ) . \begin{array}{rcl}{\text{选择:}}&{{a^{-}\:=\:\mathrm{argmax}}_{a\in\mathcal{A}}\:Q\big(s_{j+1},a;\:\boldsymbol{w^{-}}\big),}\\{\text{求值:}}&{{\widetilde{y}_{j}\:=\:r_{j}+Q\big(s_{j+1},\boldsymbol{a}^{-};\:\boldsymbol{w}^{-}\big).}}\end{array} 选择:求值:a−=argmaxa∈AQ(sj+1,a;w−),y j=rj+Q(sj+1,a−;w−).
本小节介绍双 Q 学习,第一步的选择用 DQN, 第二步的求值用目标网络:
选择: a ⋆ = a r g m a x a ∈ A Q ( s j + 1 , a ; w ) , 求值: y ~ j = r j + Q ( s j + 1 , a ⋆ ; w − ) . \begin{array}{rcl}{\text{选择:}}&{{a^{\star}\:=\:\mathrm{argmax}}_{a\in\mathcal{A}}\:Q\big(s_{j+1},a;\:\boldsymbol{w}\big),}\\{\text{求值:}}&{{\widetilde{y}_{j}\:=\:r_{j}+Q\big(s_{j+1},\boldsymbol{a}^{\star};\:\boldsymbol{w}^{-}\big).}}\end{array} 选择:求值:a⋆=argmaxa∈AQ(sj+1,a;w),y j=rj+Q(sj+1,a⋆;w−).
为什么双 Q 学习可以缓解最大化造成的高估呢?不难证明出这个不等式:
Q ( s j + 1 , a ⋆ ; w − ) ⏟ 双 Q 学习 ≤ max a ∈ A Q ( s j + 1 , a ; w − ) ⏟ 用目标网络的 Q 学习 . \underbrace{Q(s_{j+1},\color{red}{a^{\star}};\boldsymbol{w^{-}})}_{\text{双 Q 学习}}\:\leq\:\underbrace{\max_{a\in\mathcal{A}}Q(s_{j+1},\color{red}{a};\boldsymbol{w^{-}})}_{\text{用目标网络的 Q 学习}}\:. 双 Q 学习 Q(sj+1,a⋆;w−)≤用目标网络的 Q 学习 a∈AmaxQ(sj+1,a;w−).
因此,
y ~ t ⏟ 双Q学习 ≤ y t ^ ⏟ 用目标网络的 Q 学习 . \underbrace{\widetilde{y}_{t}}_\text{双Q学习}{ \leq }\underbrace{\widehat{y_{t}}}_{\text{用目标网络的 Q 学习}} . 双Q学习 y t≤用目标网络的 Q 学习 yt .
这个公式说明双 Q 学习得到的 TD 目标更小。也就是说,与用目标网络的 Q 学习相比, 双 Q学习缓解了高估。
双 Q 学习算法的流程如下。每次随机从经验回放数组中取出一个四元组,记作 ( s j s_j sj, a j , r j , s j + 1 ) a_j,r_j,s_{j+1}) aj,rj,sj+1)。设 DQN 和目标网络当前的参数分别为 w n o w w_\mathrm{now} wnow 和 w n o w − w_\mathrm{now}^- wnow−, 执行下面的步骤对参数做一次更新:
1.对 DQN 做正向传播,得到:
q ^ j = Q ( s j , a j ; w n o w ) . \widehat q_{j}\:=\:Q\big(s_{j},a_{j};\:\boldsymbol{w_{\mathrm{now}}}\big). q j=Q(sj,aj;wnow).
2.选择:
a ⋆ = argmax a ∈ A Q ( s j + 1 , a ; w n o w ) . a^{\star}\:=\:\underset{a\in\mathcal{A}}{\operatorname*{argmax}}Q\left(s_{j+1},a;\:\boldsymbol{w_{\mathrm{now}}}\right). a⋆=a∈AargmaxQ(sj+1,a;wnow).
3.求值:
q ^ j + 1 = Q ( s j + 1 , a ⋆ ; w n o w ˉ ) . \widehat q_{j+1}\:=\:Q\big(s_{j+1},a^{\star};\:\bar{\boldsymbol{w_{now}}}\big). q j+1=Q(sj+1,a⋆;wnowˉ).
4.计算 TD 目标和 TD 误差:
y ~ j = r j + γ ⋅ q ^ j + 1 和 δ j = q ^ j − y ~ j . \widetilde{y}_{j}\:=\:r_{j}+\gamma\cdot\widehat{q}_{j+1}\quad\text{和}\quad\delta_{j}\:=\:\widehat{q}_{j}-\widetilde{y}_{j}. y j=rj+γ⋅q j+1和δj=q j−y j.
5.对 DQN 做反向传播,得到梯度 ∇ w Q ( s j , a j ; w n o w ) \nabla_wQ(s_j,a_j;w_\mathrm{now}) ∇wQ(sj,aj;wnow)。
6.做梯度下降更新 DQN 的参数:
w n e w ← w n o w − α ⋅ δ j ⋅ ∇ w Q ( s j , a j ; w n o w ) . w_{\mathrm{new}}\:\leftarrow\:w_{\mathrm{now}}-\:\alpha\cdot\delta_{j}\cdot\nabla_{\boldsymbol{w}}Q\big(s_{j},a_{j};\:\boldsymbol{w_{\mathrm{now}}}\big). wnew←wnow−α⋅δj⋅∇wQ(sj,aj;wnow).
7.设 τ ∈ ( 0 , 1 ) \tau\in(0,1) τ∈(0,1) 是需要手动调整的超参数。做加权平均更新目标网络的参数:
w n e w ˉ ← τ ⋅ w n e w + ( 1 − τ ) ⋅ w n o w − . \bar{w_\mathrm{new}}\:\leftarrow\:\tau\cdot w_\mathrm{new}\:+\:\left(1-\tau\right)\cdot\boldsymbol{w_\mathrm{now}^-}. wnewˉ←τ⋅wnew+(1−τ)⋅wnow−.
总结
本节研究了 DQN 的高估问题以及解决方案。DQN 的高估不是 DQN 模型造成的,不是 DQN 的本质属性。高估只是因为原始 Q 学习算法不好。Q 学习算法产生高估的原因有两个:第一,自举导致偏差从一个 ( s , a ) (s,a) (s,a) 二元组传播到更多的二元组;第二,最大化造成 TD 目标高估真实价值。
想要解决高估问题,就要从自举、最大化这两方面下手。本节介绍了两种缓解高估的算法:使用目标网络、双Q 学习。Q 学习算法与目标网络的结合可以缓解自举造成的偏差。双 Q \mathbb{Q} Q学习基于目标网络的想法,进一步将 TD 目标的计算分解成选择和求值两步, 缓解了最大化造成的高估。图 6.5 总结了本节研究的三种算法。

注 如果使用原始 Q 学习算法,自举和最大化都会造成严重高估。在实践中,应当尽量使用双 Q 学习,它是三种算法中最好的。
注 如果使用 SARSA 算法 (比如在 actor-critic 中), 自举的问题依然存在,但是不存在最大化造成高估这一问题。对于 SARSA, 只需要解决自举问题,所以应当将目标网络应用到 SARSA 。
对决网络 (Dueling Network)
本节介绍对决网络 (dueling network), 它是对 DQN 的神经网络结构的改进。它的基本想法是将最优动作价值 Q ⋆ Q_{\star} Q⋆ 分解成最优状态价值 V ⋆ V_{\star} V⋆ 加最优优势 D ⋆ D_{\star} D⋆。对决网络的训练与 DQN 完全相同,可以用 Q 学习算法或者双 Q 学习算法 。
最优优势函数
在介绍对决网络 (dueling network)之前,先复习一些基础知识。动作价值函数 Q π ( s , a ) Q_\pi(s,a) Qπ(s,a) 是回报的期望:
Q π ( s , a ) = E [ U t ∣ S t = s , A t = a ] . Q_{\pi}(s,a)\:=\:\mathbb{E}\Big[U_{t}\Big|\:S_{t}=s,A_{t}=a\Big]. Qπ(s,a)=E[Ut St=s,At=a].
最优动作价值 Q ⋆ Q_{\star} Q⋆的定义是:
Q ⋆ ( s , a ) = max π Q π ( s , a ) , ∀ s ∈ S , a ∈ A . Q_{\star}(s,a)\:=\:\max_{\pi}\:Q_{\pi}(s,a),\quad\forall\:s\in\mathcal{S},\:a\in\mathcal{A}. Q⋆(s,a)=πmaxQπ(s,a),∀s∈S,a∈A.
状态价值函数 V π ( s ) V_{\pi}(s) Vπ(s) 是 Q π ( s , a ) Q_{\pi}(s,a) Qπ(s,a) 关于 a a a 的期望:
V π ( s ) = E A ∼ π [ Q π ( s , A ) ] . V_{\pi}(s)\:=\:\mathbb{E}_{A\sim\pi}\Big[Q_{\pi}(s,A)\Big]. Vπ(s)=EA∼π[Qπ(s,A)].
最优状态价值函数 V ⋆ V_{\star} V⋆的定义是:
V ⋆ ( s ) = max π V π ( s ) , ∀ s ∈ S . V_{\star}\big(s\big)\:=\:\operatorname*{max}_{\pi}\:V_{\pi}\big(s\big),\quad\forall\:s\in\mathcal{S}. V⋆(s)=πmaxVπ(s),∀s∈S.
最优优势函数 (optimal advantage function) 的定义是:
D ⋆ ( s , a ) ≜ Q ⋆ ( s , a ) − V ⋆ ( s ) . \boxed{D_{\star}(s,a)\:\triangleq\:Q_{\star}(s,a)\:-\:V_{\star}(s).} D⋆(s,a)≜Q⋆(s,a)−V⋆(s).
通过数学推导,可以证明下面的定理:

Q ⋆ ( s , a ) = V ⋆ ( s ) + D ⋆ ( s , a ) − max a ∈ A D ⋆ ( s , a ) ⏟ 恒等于零 ∀ s ∈ S , a ∈ A . Q_{\star}(s,a)=V_{\star}(s)+D_{\star}(s,a)-\underbrace{\max_{a\in\mathcal{A}}D_{\star}(s,a)}_{\text{恒等于零}}\quad\forall s\in\mathcal{S},a\in\mathcal{A}. Q⋆(s,a)=V⋆(s)+D⋆(s,a)−恒等于零 a∈AmaxD⋆(s,a)∀s∈S,a∈A.
对决网络
与 DQN 一样,对决网络 (dueling network) 也是对最优动作价值函数 Q ⋆ Q_{\star} Q⋆ 的近似。对决网络与 DQN 的区别在于神经网络结构不同。直观上,对决网络可以了解到哪些状态有价值或者没价值,而无需了解每个动作对每个状态的影响。实践中,对决网络具有更好的效果。由于对决网络与 DQN 都是对 Q ⋆ Q_{\star} Q⋆ 的近似,可以用完全相同的算法训练两种神经网络。
对决网络由两个神经网络组成。一个神经网络记作 D ( s , a ; w D ) D(s,a;w^D) D(s,a;wD), 它是对最优优势函数 D ⋆ ( s , a ) D_\star(s,a) D⋆(s,a) 的近似。另一个神经网络记作 V ( s ; w V ) V(s;w^V) V(s;wV),它是对最优状态价值函数 V ⋆ ( s ) V_{\star}(s) V⋆(s) 的近似。把定理 6.1 中的 D ⋆ D_{\star} D⋆ 和 V ⋆ V_{\star} V⋆ 替换成相应的神经网络,那么最优动作价值函数 Q ⋆ Q_{\star} Q⋆ 就被近似成下面的神经网络:
Q ( s , a ; w ) ≜ V ( s ; w V ) + D ( s , a ; w D ) − max a ∈ A D ( s , a ; w D ) . ( 6.1 ) Q\big(s,a;\boldsymbol{w}\big)\triangleq V\big(s;\boldsymbol{w}^{V}\big)+D\big(s,a;\boldsymbol{w}^{D}\big)-\max_{a\in\mathcal{A}}D\big(s,a;\boldsymbol{w}^{D}\big).\quad{(6.1)} Q(s,a;w)≜V(s;wV)+D(s,a;wD)−a∈AmaxD(s,a;wD).(6.1)
公式左边的 Q ( s , a ; w ) Q(s,a;\boldsymbol{w}) Q(s,a;w) 就是对决网络,它是对最优动作价值函数 Q ⋆ Q_{\star} Q⋆ 的近似。它的参数记作 w ≜ ( w V ; w D ) w\triangleq(w^V;w^D) w≜(wV;wD)。
对决网络的结构如图 6.6 所示。
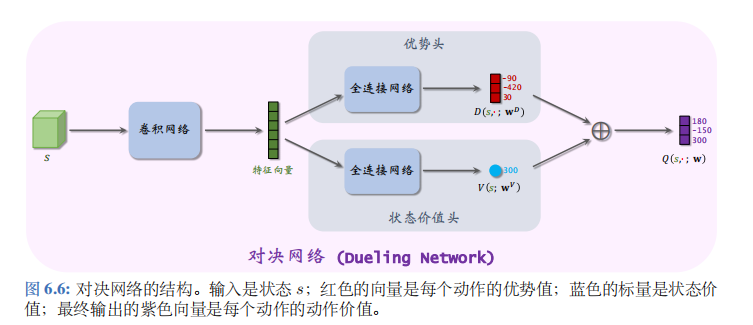
可以让两个神经网络 D ( s , a ; w D ) D(s,a;w^D) D(s,a;wD) 与 V ( s ; w V ) V(s;w^V) V(s;wV) 共享部分卷积层;这些卷积层把输入的状态 s s s 映射成特征向量,特征向量是“优势头”与“状态价值头”的输入。优势头输出一个向量,向量的维度是动作空间的大小 ∣ A ∣ |A| ∣A∣, 向量每个元素对应一个动作。举个例子,动作空间是$A= { 左,右,上 左,右,上 左,右,上} $。优势头的输出是三个值:
D ( s , 左 ; w D ) = − 90 , D ( s , 右 ; w D ) = − 420 , D ( s , 上 ; w D ) = 30. D\big(s,\textit{左};\boldsymbol{w}^D\big)\:=\:-90,\quad D\big(s,\textit{右};\boldsymbol{w}^D\big)\:=\:-420,\quad D\big(s,\:\text{上};\boldsymbol{w}^D\big)\:=\:30. D(s,左;wD)=−90,D(s,右;wD)=−420,D(s,上;wD)=30.
状态价值头输出的是一个实数,比如
V ( s ; w V ) = 300. V(s;\:\boldsymbol{w}^{V})\:=\:300. V(s;wV)=300.
首先计算
max a D ( s , a ; w D ) = max { − 90 , − 420 , 30 } = 30. \operatorname*{max}_{a}D\big(s,a;\boldsymbol{w}^{D}\big)\:=\:\operatorname*{max}\big\{\:-90,\:-420,\:30\big\}\:=\:30. amaxD(s,a;wD)=max{−90,−420,30}=30.
然后用公式 (6.1) 计算出:
Q ( s , 左 ; w ) = 180 , Q ( s , 右 ; w ) = − 150 , Q ( s , 上 ; w ) = 300. Q\big(s,\textit{左};\boldsymbol{w}\big)\:=\:180,\quad Q\big(s,\textit{右};\boldsymbol{w}\big)\:=\:-150,\quad Q\big(s,\:\text{上};\boldsymbol{w}\big)\:=\:300. Q(s,左;w)=180,Q(s,右;w)=−150,Q(s,上;w)=300.
这样就得到了对决网络的最终输出。
解决不唯一性
读者可能会有下面的疑问。对决网络是由定理 6.1 推导出的,而定理中最右的一项恒等于零:
max a ∈ A D ⋆ ( s , a ) = 0 , ∀ s ∈ S . \max_{a\in\mathcal{A}}\:D_{\star}\big(s,a\big)\:=\:0,\quad\forall\:s\in\mathcal{S}. a∈AmaxD⋆(s,a)=0,∀s∈S.
也就是说,可以把最优动作价值写成两种等价形式:
Q ⋆ ( s , a ) = V ⋆ ( s ) + D ⋆ ( s , a ) (第一种形式) = V ⋆ ( s ) + D ⋆ ( s , a ) − max a ∈ A D ⋆ ( s , a ) . (第二种形式) \begin{matrix}Q_\star(s,a)&=&V_\star(s)+D_\star(s,a)&\text{(第一种形式)}\\&=&V_\star(s)+D_\star(s,a)-\max_{a\in\mathcal{A}}D_\star(s,a).&\text{(第二种形式)}\end{matrix} Q⋆(s,a)==V⋆(s)+D⋆(s,a)V⋆(s)+D⋆(s,a)−maxa∈AD⋆(s,a).(第一种形式)(第二种形式)
之前我们根据第二种形式实现对决网络。我们可否根据第一种形式,把对决网络按照下面的方式实现呢:
Q ( s , a ; w ) = V ( s ; w V ) + D ( s , a ; w D ) ? Q\big(s,a;\:\boldsymbol{w}\big)\:=\:V\big(s;\:\boldsymbol{w}^{V}\big)+D\big(s,a;\:\boldsymbol{w}^{D}\big)\:? Q(s,a;w)=V(s;wV)+D(s,a;wD)?
答案是不可以这样实现对决网络,因为这样会导致不唯一性。假如这样实现对决网络,那么 V V V 和 D D D 可以随意上下波动,比如一个增大 100, 另一个减小 100:
V ( s ; w ~ V ) ≜ V ( s ; w V ) + 100 , D ( s , a ; w ~ D ) ≜ D ( s , a ; w D ) − 100. \begin{array}{rcl}V(s;\:\tilde{\boldsymbol{w}}^V)&\triangleq&V(s;\:\boldsymbol{w}^V)+100,\\\\D\big(s,a;\:\tilde{\boldsymbol{w}}^D\big)&\triangleq&D\big(s,a;\:\boldsymbol{w}^D\big)-100.\end{array} V(s;w~V)D(s,a;w~D)≜≜V(s;wV)+100,D(s,a;wD)−100.
这样的上下波动不影响最终的输出:
V ( s ; w V ) + D ( s , a ; w D ) = V ( s ; w ~ V ) + D ( s , a ; w ~ D ) . V\big(s;\:\boldsymbol{w}^{V}\big)+D\big(s,a;\:\boldsymbol{w}^{D}\big)\:=\:V\big(s;\:\tilde{\boldsymbol{w}}^{V}\big)+D\big(s,a;\:\tilde{\boldsymbol{w}}^{D}\big). V(s;wV)+D(s,a;wD)=V(s;w~V)+D(s,a;w~D).
这就意味着 V V V和 D D D的参数可以很随意地变化,却不会影响输出的 Q。我们不希望这种情况出现,因为这会导致训练的过程中参数不稳定。
因此很有必要在对决网络中加入 max a ∈ A D ( s , a ; w D ) \max_{a\in\mathcal{A}}D(s,a;\boldsymbol{w}^D) maxa∈AD(s,a;wD) 这一项。它使得 V V V 和 D D D 不能随意上下波动。假如让 V V V变大 100,让 D D D 变小 100, 则对决网络的输出会增大 100,而非不变:
V ( s ; w ~ V ) + D ( s , a ; w ~ D ) − max a D ( s , a ; w ~ D ) V\big(s;\:\tilde{\boldsymbol{w}}^V\big)\:+\:D\big(s,a;\:\tilde{\boldsymbol{w}}^D\big)\:-\:\max_aD\big(s,a;\:\tilde{\boldsymbol{w}}^D\big) V(s;w~V)+D(s,a;w~D)−amaxD(s,a;w~D)
= V ( s ; w V ) + D ( s , a ; w D ) − max a D ( s , a ; w D ) + 100. =V(s;\:\boldsymbol{w}^{V})\:+\:D\big(s,a;\:\boldsymbol{w}^{D}\big)\:-\:\operatorname*{max}_{a}D\big(s,a;\:\boldsymbol{w}^{D}\big)\:+\:100. =V(s;wV)+D(s,a;wD)−amaxD(s,a;wD)+100.
以上讨论说明了为什么 max a ∈ A D ( s , a ; w D ) \max_{a\in\mathcal{A}}D(s,a;w^D) maxa∈AD(s,a;wD)这一项不能省略。
对决网络的实际实现
按照定理 6.1, 对决网络应该定义成:
Q ( s , a ; w ) ≜ V ( s ; w V ) + D ( s , a ; w D ) − max a ∈ A D ( s , a ; w D ) . Q\big(s,a;\:\boldsymbol{w}\big)\:\triangleq\:V\big(s;\:\boldsymbol{w}^{V}\big)\:+\:D\big(s,a;\:\boldsymbol{w}^{D}\big)\:-\:\operatorname*{max}_{a\in\mathcal{A}}D\big(s,a;\:\boldsymbol{w}^{D}\big). Q(s,a;w)≜V(s;wV)+D(s,a;wD)−a∈AmaxD(s,a;wD).
最右边的 max 项的目的是解决不唯一性。实际实现的时候,用 mean 代替 max \max max 会有更好的效果。所以实际 上会这样定义对决网络:
Q ( s , a ; w ) ≜ V ( s ; w V ) + D ( s , a ; w D ) − m e a n a ∈ A D ( s , a ; w D ) . \color{red}{\boxed{Q(s,a;\boldsymbol{w})\triangleq V(s;\boldsymbol{w}^{V})+D(s,a;\boldsymbol{w}^{D})-mean_{a\in\mathcal{A}}D(s,a;\boldsymbol{w}^{D}).}} Q(s,a;w)≜V(s;wV)+D(s,a;wD)−meana∈AD(s,a;wD).
对决网络与 DQN 都是对最优动作价值函数 Q ⋆ Q_{\star} Q⋆ 的近似,所以对决网络的训练和决策与 DQN 完全一样。比如可以这样训练对决网络:
- 用 ϵ \epsilon ϵ-greedy 算法控制智能体,收集经验,把 ( s j , a j , r j , s j + 1 ) (s_j,a_j,r_j,s_{j+1}) (sj,aj,rj,sj+1) 这样的四元组存入经验回放数组。
- 从数组里随机抽取四元组,用双 Q 学习算法更新对决网络参数 w = ( w D , w V ) \boldsymbol{w}=(\boldsymbol{w}^D,\boldsymbol{w}^V) w=(wD,wV)。
完成训练之后,基于当前状态 s t s_t st,让对决网络给所有动作打分,然后选择分数最高的动作:
a t = a r g m a x a ∈ A Q ( s t , a ; w ) . a_{t}\:=\:\mathop{\mathrm{argmax}}_{a\in\mathcal{A}}\:Q\big(s_{t},a;\:\boldsymbol{w}\big). at=argmaxa∈AQ(st,a;w).
简而言之,怎么样训练 DQN,就怎么样训练对决网络;怎么样用 DQN 做控制,就怎么样用对决网络做控制。如果一个技巧能改进 DQN 的训练,这个技巧也能改进对决网络。同样的道理,因为 Q 学习算法导致 DQN 出现高估,所以 Q 学习算法也会导致对决网络出现高估。
噪声网络
本节介绍噪声网络(noisy net),这是一种非常简单的方法,可以显著提高 DQN 的表现。噪声网络的应用不局限于 DQN, 它可以用于几乎所有的深度强化学习方法。
噪声网络的原理
把神经网络中的参数 w w w 替换成 μ + σ ∘ ξ \mu+\sigma\circ\xi μ+σ∘ξ。此处的 μ 、 σ 、 ξ \mu、\sigma、\xi μ、σ、ξ 的形状与 w w w 完全相同。 μ \mu μ、 σ \sigma σ 分别表示均值和标准差,它们是神经网络的参数,需要从经验中学习。 ξ \xi ξ 是随机噪声,它的每个元素独立从标准正态分布 N ( 0 , 1 ) \mathcal{N}(0,1) N(0,1) 中随机抽取。符号“ ∘ \circ ∘”表示逐项乘积。
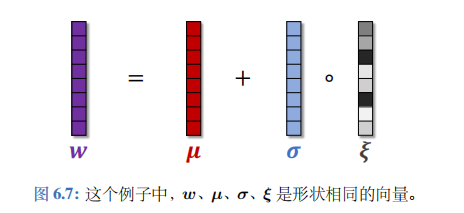
如果 w w w 是向量,那么有
w i = μ i + σ i ⋅ ξ i . w_{i}\:=\:\mu_{i}\:+\:\sigma_{i}\cdot\xi_{i}. wi=μi+σi⋅ξi.
如果 w w w 是矩阵,那么有
w i j = μ i j + σ i j ⋅ ξ i j . w_{ij}\:=\:\mu_{ij}\:+\:\sigma_{ij}\cdot\xi_{ij}. wij=μij+σij⋅ξij.
噪声网络的意思是参数 w w w 的每个元素 w i w_i wi 从均值为 μ i \mu_i μi、标准差为 σ i \sigma_i σi 的正态分布中抽取。
举个例子,某一个全连接层记作:
z = R e L U ( W x + b ) . z\:=\:\mathrm{ReLU}\:(\boldsymbol{Wx}+\boldsymbol{b})\:. z=ReLU(Wx+b).
公式中的向量 x x x 是输入,矩阵 W W W 和向量 b b b 是参数,ReLU 是激活函数, z z z 是这一层的输出。噪声网络把这个全连接层替换成:
z = R e L U ( ( W μ + W σ ∘ W ξ ) x + ( b μ + b σ ∘ b ξ ) ) . z\:=\:\mathrm{ReLU}\left(\left(W^{\mu}+W^{\sigma}\circ W^{\xi}\right)x\:+\:\left(b^{\mu}+b^{\sigma}\circ b^{\xi}\right)\right). z=ReLU((Wμ+Wσ∘Wξ)x+(bμ+bσ∘bξ)).
公式中的 W μ W^\mathrm{\mu} Wμ、 W σ W^\mathrm{\sigma} Wσ、 b μ b^\mathrm{\mu} bμ、 b σ b^\mathrm{\sigma} bσ是参数,需要从经验中学习。矩阵 W ξ W^\mathrm{\xi} Wξ 和向量 b ξ b^\mathrm{\xi} bξ 的每个元素都是独立从 N ( 0 , 1 ) \mathcal{N}(0,1) N(0,1) 中随机抽取的,表示噪声。
训练噪声网络的方法与训练标准的神经网络完全相同,都是做反向传播计算梯度,然后用梯度更新神经参数。把损失函数记作 L L L。已知梯度 ∂ L ∂ z \frac{\partial L}{\partial z} ∂z∂L,可以用链式法则算出损失关于参数的梯度:
∂ L ∂ W μ = ∂ z ∂ W μ ⋅ ∂ L ∂ z , ∂ L ∂ b μ = ∂ z ∂ b μ ⋅ ∂ L ∂ z , ∂ L ∂ W σ = ∂ z ∂ W σ ⋅ ∂ L ∂ z , ∂ L ∂ b σ = ∂ z ∂ b σ ⋅ ∂ L ∂ z . \begin{array}{rcl}\displaystyle\frac{\partial L}{\partial W^{\mu}}=\frac{\partial z}{\partial W^{\mu}}\cdot\frac{\partial L}{\partial z},&\displaystyle\frac{\partial L}{\partial b^{\mu}}=\frac{\partial z}{\partial b^{\mu}}\cdot\frac{\partial L}{\partial z},\\\displaystyle\frac{\partial L}{\partial W^{\sigma}}=\frac{\partial z}{\partial W^{\sigma}}\cdot\frac{\partial L}{\partial z},&\displaystyle\frac{\partial L}{\partial b^{\sigma}}=\frac{\partial z}{\partial b^{\sigma}}\cdot\frac{\partial L}{\partial z}.\end{array} ∂Wμ∂L=∂Wμ∂z⋅∂z∂L,∂Wσ∂L=∂Wσ∂z⋅∂z∂L,∂bμ∂L=∂bμ∂z⋅∂z∂L,∂bσ∂L=∂bσ∂z⋅∂z∂L.
然后可以做梯度下降更新参数 W μ W^\mu Wμ、 W σ W^\sigma Wσ、 b μ b^\mu bμ、 b σ b^\sigma bσ。
噪声 DQN
噪声网络可以用于 DQN。标准的 DQN 记作 Q ( s , a ; w ) Q(s,a;\boldsymbol{w}) Q(s,a;w), 其中的 w w w 表示参数。把 w w w 替换成 μ + σ ∘ ξ \mu+\sigma\circ\xi μ+σ∘ξ, 得到噪声 DQN, 记作:
Q ~ ( s , a , ξ ; μ , σ ) ≜ Q ( s , a ; μ + σ ∘ ξ ) . \tilde{Q}(s,a,\boldsymbol{\xi};\boldsymbol{\mu},\boldsymbol{\sigma})\:\triangleq\:Q(s,\boldsymbol{a};\boldsymbol{\mu}+\boldsymbol{\sigma}\circ\boldsymbol{\xi}). Q~(s,a,ξ;μ,σ)≜Q(s,a;μ+σ∘ξ).
其中的 μ \mu μ和 σ \sigma σ是参数,一开始随机初始化,然后从经验中学习;而 ξ \xi ξ则是随机生成,每个元素都从 N ( 0 , 1 ) \mathcal{N}(0,1) N(0,1) 中抽取。噪声 DQN 的参数数量比标准 DQN 多一倍。
收集经验:
DQN 属于异策略 (off-policy)。我们用任意的行为策略 (behavior policy) 控制智能体,收集经验,事后做经验回放更新参数。在之前章节中,我们用 ϵ \epsilon ϵ-greedy 作为行为策略:
a t = { argmax a ∈ A Q ( s t , a ; w ) , 以概率 ( 1 − ϵ ) ; 均匀抽取 A 中的一个动作 , 以概率 ϵ . \left.a_t\:=\:\left\{\begin{array}{ll}\operatorname{argmax}_{a\in\mathcal{A}}Q(s_t,a;\boldsymbol{w}),&\text{以概率}\:(1-\epsilon);\\\text{均匀抽取}\:\mathcal{A}\:\text{中的一个动作},&\text{以概率}\:\epsilon.\end{array}\right.\right. at={argmaxa∈AQ(st,a;w),均匀抽取A中的一个动作,以概率(1−ϵ);以概率ϵ.
ϵ \epsilon ϵ-greedy 策略带有一定的随机性,可以让智能体尝试更多动作,探索更多状态。
噪声 DQN 本身就带有随机性,可以鼓励探索,起到与 ϵ \epsilon ϵ-greedy 策略相同的作用。我们直接用
a t = a r g m a x a ∈ A Q ~ ( s , a , ξ ; μ , σ ) a_t\:=\:\underset{a\in\mathcal{A}}{\mathrm{argmax}}\:\tilde{Q}(s,a,\xi;\:\mu,\sigma) at=a∈AargmaxQ~(s,a,ξ;μ,σ)
作为行为策略,效果比 ϵ \epsilon ϵ-greedy 更好。每做一个决策,要重新随机生成一个 ξ \xi ξ。
Q \mathbb{Q} Q学习算法:
训练的时候,每一轮从经验回放数组中随机抽样出一个四元组,记作 ( s j , a j , r j , s j + 1 ) (s_j,a_j,r_j,s_{j+1}) (sj,aj,rj,sj+1)。从标准正态分布中做抽样,得到 ξ ′ \xi^{\prime} ξ′的每一个元素。计算 TD 目标:
y ^ j = r j + γ ⋅ max a ∈ A Q ~ ( s j + 1 , a , ξ ′ ; μ , σ ) . \widehat y_j\:=\:r_j\:+\:\gamma\:\cdot\:\max_{a\in\mathcal{A}}\widetilde Q(s_{j+1},a,\xi^{\prime};\:\mu,\sigma). y j=rj+γ⋅a∈AmaxQ (sj+1,a,ξ′;μ,σ).
把损失函数记作:
L ( μ , σ ) = 1 2 [ Q ~ ( s j , a j , ξ ; μ , σ ) − y ^ j ] 2 , L(\boldsymbol{\mu},\boldsymbol{\sigma})\:=\:\frac{1}{2}\Big[\tilde{Q}(s_{j},a_{j},\boldsymbol{\xi};\boldsymbol{\mu},\boldsymbol{\sigma})\:-\:\widehat{y}_{j}\Big]^{2}, L(μ,σ)=21[Q~(sj,aj,ξ;μ,σ)−y j]2,
其中的 ξ \xi ξ也是随机生成的噪声,但是它与 ξ ′ \xi^{\prime} ξ′不同。然后做梯度下降更新参数:
μ ← μ − α μ ⋅ ∇ μ L ( μ , σ ) , σ ← σ − α σ ⋅ ∇ σ L ( μ , σ ) . \mu\:\leftarrow\:\mu-\alpha_{\mu}\cdot\nabla_{\mu}L(\mu,\sigma),\quad\sigma\:\leftarrow\:\sigma-\alpha_{\sigma}\cdot\nabla_{\sigma}L(\mu,\sigma). μ←μ−αμ⋅∇μL(μ,σ),σ←σ−ασ⋅∇σL(μ,σ).
公式中的 α μ \alpha_\mathrm{\mu} αμ 和 α σ \alpha_\mathrm{\sigma} ασ 是学习率。这样做梯度下降更新参数,可以让损失函数减小,让噪声DQN 的预测更接近 TD 目标。
做决策 :
做完训练之后,可以用噪声 DQN 做决策。做决策的时候不再需要噪声,因此可以把参数 σ \sigma σ设置成全零,只保留参数 μ \mu μ。这样一来,噪声 DQN 就变成标准的 DQN:
Q ~ ( s , a , ξ ′ ; μ , 0 ) ⏟ 噪声 DQN = Q ( s , a ; μ ) ⏟ 标准 DQN . \underbrace{\widetilde{Q}(s,a,\boldsymbol{\xi'};\boldsymbol{\mu},\boldsymbol{0})}_{\text{噪声 DQN}}=\underbrace{Q(s,a;\boldsymbol{\mu})}_{\text{标准 DQN}}. 噪声 DQN Q (s,a,ξ′;μ,0)=标准 DQN Q(s,a;μ).
在训练的时候往 DQN 的参数中加入噪声,不仅有利于探索,还能增强鲁棒性。鲁棒性的意思是即使参数被扰动,DQN 也能对动作价值 Q ⋆ Q_{\star} Q⋆ 做出可靠的估计。为什么噪声可以让DQN 有更强的鲁棒性呢?
假设在训练的过程中不加入噪声。把学出的参数记作 μ \mu μ。当参数严格等于 μ \mu μ 的时候DQN 可以对最优动作价值做出较为准确的估计。但是对 μ \mu μ 做较小的扰动,就可能会让DQN 的输出偏离很远。所谓“失之毫厘,谬以千里”。
噪声 DQN 训练的过程中,参数带有噪声: w = μ + σ ∘ ξ w=\mu+\sigma\circ\xi w=μ+σ∘ξ。训练迫使 DQN 在参数带噪声的情况下最小化 TD 误差,也就是迫使 DQN 容忍对参数的扰动。训练出的 DQN 具有鲁棒性:参数不严格等于 μ \mu μ 也没关系,只要参数在 μ \mu μ 的邻域内,DQN 做出的预测都应该比较合理。用噪声 DQN, 不会出现“失之毫厘,谬以千里”。
训练流程
实际编程实现 DQN 的时候,应该将本章的四种技巧——优先经验回放、双 Q \mathbb{Q} Q学习、 对决网络、噪声 DQN——全部用到。应该用对决网络的神经网络结构,而不是简单的DQN 结构。往对决网络中的参数 w w w 中加入噪声,得到噪声 DQN, 记作 Q ~ ( s , a , ξ ; μ , σ ) \tilde{Q}(s,a,\xi;\mu,\sigma) Q~(s,a,ξ;μ,σ)。训练要用双 Q \mathbb{Q} Q 学习、优先经验回放,而不是原始的 Q 学习。双 Q 学习需要目标网络 Q ~ ( s , a , ξ ; μ − , σ − ) \tilde{Q}(s,a,\xi;\mu^-,\sigma^-) Q~(s,a,ξ;μ−,σ−) 计算 TD 目标。它跟噪声 DQN 的结构相同,但是参数不同。
初始化的时候,随机初始化 μ 、 σ \mu、\sigma μ、σ,并且把它们赋值给目标网络参数: μ − ← μ . σ − ← σ \mu^-\leftarrow\mu.\sigma^-\leftarrow\sigma μ−←μ.σ−←σ。
然后重复下面的步骤更新参数。把当前的参数记作 μ n o w \mu_\mathrm{now} μnow、 σ n o w \sigma_\mathrm{now} σnow、 μ n o w − \mu_\mathrm{now}^\mathrm{-} μnow− σ n o w − \sigma_\mathrm{now}^\mathrm{-} σnow−。
- 用优先经验回放,从数组中抽取一个四元组,记作 ( s j , a j , r j , s j + 1 ) (s_j,a_j,r_j,s_{j+1}) (sj,aj,rj,sj+1)。
- 用标准正态分布生成 ξ \xi ξ。对噪声 DQN 做正向传播,得到:
q ^ j = Q ~ ( s j , a j , ξ ; μ n o w , σ n o w ) . \widehat q_{j}\:=\:\widetilde Q(s_{j},a_{j},\xi;\:\mu_{\mathrm{now}},\sigma_{\mathrm{now}}). q j=Q (sj,aj,ξ;μnow,σnow).
- 用噪声 DQN 选出最优动作:
a ~ j + 1 = argmax a ∈ A Q ~ ( s j + 1 , a , ξ ; μ n o w , σ n o w ) . \tilde{a}_{j+1}\:=\:\operatorname*{argmax}_{a\in A}\:\tilde{Q}\big(s_{j+1},a,\:\xi;\:\mu_{\mathrm{now}},\sigma_{\mathrm{now}}\big). a~j+1=a∈AargmaxQ~(sj+1,a,ξ;μnow,σnow).
- 用标准正态分布生成 ξ ′ \xi^{\prime} ξ′。用目标网络计算价值:
q ^ j + 1 − = Q ~ ( s j + 1 , a ~ j + 1 , ξ ′ ; μ n o w − , σ n o w − ) . \widehat q_{j+1}^{-}\:=\:\widetilde Q\big(s_{j+1},\tilde{a}_{j+1},\:\xi^{\prime};\:\mu_{\mathrm{now}}^{-},\sigma_{\mathrm{now}}^{-}\big). q j+1−=Q (sj+1,a~j+1,ξ′;μnow−,σnow−).
- 计算 TD 目标和 TD 误差:
y ^ j − = r j + γ ⋅ q ^ j + 1 − 和 δ j = q ^ j − y ^ j − . \widehat{y}_{j}^{-}\:=\:r_{j}+\gamma\cdot\widehat{q}_{j+1}^{-}\quad\text{和}\quad\delta_{j}\:=\:\widehat{q}_{j}-\widehat{y}_{j}^{-}. y j−=rj+γ⋅q j+1−和δj=q j−y j−.
- 设 α μ \alpha_\mathrm{\mu} αμ 和 α σ \alpha_\mathrm{\sigma} ασ为学习率。做梯度下降更新噪声 DQN 的参数:
μ n e w ← μ n o w − α μ ⋅ δ j ⋅ ∇ μ Q ~ ( s j , a j , ξ ; μ n o w , σ n o w ) , σ n e w ← σ n o w − α σ ⋅ δ j ⋅ ∇ σ Q ~ ( s j , a j , ξ ; μ n o w , σ n o w ) . \begin{array}{rcl}\mu_\mathrm{new}&\leftarrow&\mu_\mathrm{now}-\alpha_{\mu}\cdot\delta_j\cdot\nabla_{\mu}\widetilde{Q}\big(s_j,a_j,\xi;\:\mu_\mathrm{now},\sigma_\mathrm{now}\big),\\\\\sigma_\mathrm{new}&\leftarrow&\sigma_\mathrm{now}-\alpha_\sigma\cdot\delta_j\cdot\nabla_{\sigma}\widetilde{Q}\big(s_j,a_j,\:\xi;\:\mu_\mathrm{now},\sigma_\mathrm{now}\big).\end{array} μnewσnew←←μnow−αμ⋅δj⋅∇μQ (sj,aj,ξ;μnow,σnow),σnow−ασ⋅δj⋅∇σQ (sj,aj,ξ;μnow,σnow).
- 设 τ ∈ ( 0 , 1 ) \tau\in(0,1) τ∈(0,1) 是需要手动调整的超参数。做加权平均更新目标网络的参数:
μ n e w − ← τ ⋅ μ n e w + ( 1 − τ ) ⋅ μ n o w − , σ n e w − ← τ ⋅ σ n e w + ( 1 − τ ) ⋅ σ n o w − . \begin{array}{rcl}\mu_\mathrm{new}^-&\leftarrow&\tau\cdot\mu_\mathrm{new}\:+\:\left(1-\tau\right)\cdot\mu_\mathrm{now}^-,\\\\\sigma_\mathrm{new}^-&\leftarrow&\tau\cdot\sigma_\mathrm{new}\:+\:\left(1-\tau\right)\cdot\sigma_\mathrm{now}^-.\end{array} μnew−σnew−←←τ⋅μnew+(1−τ)⋅μnow−,τ⋅σnew+(1−τ)⋅σnow−.
总结
-
经验回放可以用于异策略算法。经验回放有两个好处:打破相邻两条经验的相关性、 重复利用收集的经验。
-
优先经验回放是对经验回放的一种改进。在做经验回放的时候,从经验回放数组中做加权随机抽样,TD 误差的绝对值大的经验被赋予较大的抽样概率、较小的学习率。
-
Q 学习算法会造成 DQN 高估真实的价值。高估的原因有两个:第一,最大化造成TD 目标高估真实价值;第二,自举导致高估传播。高估并不是由 DQN 本身的缺陷造成的,而是由于 Q \mathbb{Q} Q学习算法不够好。双 Q \mathbb{Q} Q学习是对 Q 学习算法的改进,可以有效缓解高估。
-
对决网络与 DQN 一样,都是对最优动作价值函数 Q ⋆ Q_\mathrm{\star} Q⋆ 的近似;两者的唯一区别在于神经网络结构。对决网络由两部分组成 : D ( s , a ; w D ) :D(s,a;w^D) :D(s,a;wD) 是对最优优势函数的近似, V ( s ; w V ) V(s;\boldsymbol{w}^V) V(s;wV) 是对最优状态价值函数的近似。对决网络的训练与 DQN 完全相同。
-
噪声网络是一种特殊的神经网络结构,神经网络中的参数带有随机噪声。噪声网络可以用于DQN 等多种深度强化学习模型。噪声网络中的噪声可以鼓励探索,让智能体尝试不同的动作,这有利于学到更好的策略。
后记
截至2024年1月29日13点41分,学习完价值学习的高级技巧。











)







