论文题目 : : Semi-supervised Small Apple Detection in Orchard Environments
项目链接:https://www.inf.uni-hamburg.de/en/inst/ab/cv/people/wilms/mad.html
摘要(Abstract)
农作物检测是自动估产或水果采摘等精准农业应用不可或缺的一部分。然而,由于缺乏大规模数据集以及图像中农作物的相对尺寸较小,农作物检测(如果园环境中的苹果检测)仍面临挑战。在这项工作中,以半监督的方式重新制定了苹果检测任务,从而应对了这些挑战。为此,提供了大型高分辨率数据集 MAD,其中包括 105 张标注了苹果实例的图像和 4440 张未标注的图像。利用该数据集,还提出了一种基于上下文关注和选择性窗口的新型半监督小苹果检测方法 ,以提高小苹果检测的挑战性,同时限制计算开销。在 MAD 和 MSU 数据集上进行了全面的评估,结果表明 的性能大大优于强大的全监督基线方法,包括几个小物体检测方法,最高可达 14.9%。此外,利用数据集关于苹果特性的详细注释,分析了相对大小或闭塞程度对各种方法结果的影响,量化了当前面临的挑战。
1 引言(Introduction)
收获前产量估算是农业有效规划作物收获、销售、运输和储存的重要组成部分[1,7,34,38]。产量估计通常依赖于劳动密集型的人工在样本位置进行计数[1,7,34,38],以及天气信息和历史数据[1,7,38]。然而,由于果实负荷、土壤、光照等因素的自然差异,这样的估计是不准确的[12,34]。最近,精准农业受到了极大的关注,出现了基于视觉的自动产量估计方法[1,7]、质量控制方法[37]或水果采摘方法[9]。 
开发此类方法的一项重要任务是可靠地检测作物[8]。尽管最近取得了一些进展[1,7,8,34,37],但这项任务仍然具有挑战性。例如,果园中苹果的检测仍然很困难,原因是多种因素造成的复杂环境:(1)苹果分布密集,(2)其他作物或树叶造成的遮挡和阴影,(3)苹果与树木相比体积较小。这些影响也可以从图1中的例子中看到,图1描绘了果园环境中的一棵典型的苹果树。尤其具有挑战性的是小苹果大小,因为物体检测器的性能在小物体上显著下降[4],这是由于cnn固有的下采样和有限的GPU资源阻碍了整个高分辨率图像的处理。此外,有限的数据可用性[3,8]是苹果检测的另一个挑战。
为了解决上述挑战,在一般目标检测中提出了几种方法。为了处理有限的数据量,采用迁移学习(transfer learning)[35]利用在任务中学习到的特征,而标注的工作量更少。此外,还提出了半监督方法,通过一致性[10,36]和伪标签方法[33,41]将无标签的数据纳入目标检测。为了改进具有挑战性的小目标检测,研究人员探索了几个方向[5],包括多尺度特征提取[18,19,32,42],通过学习特定尺度的特征来改善小目标的特征表示,基于注意力的方法[20,44,45]旨在选择网络中的相关区域或特征,而窗口策略(tiling strategies)[25,39,43]则在输入层面上提高目标的相对大小。
在本文中,作者通过以半监督的方式重新制定问题来解决果园环境中苹果的挑战性检测。为了解决这个问题,提出了一种新的半监督小苹果检测方法 和一个新的用于半监督学习的大规模苹果检测数据集MAD。MAD由来自苹果园的4545张高分辨率图像组成,105张图像中有14667个手动标注的苹果,其余的图像支持半监督学习。为了以半监督的方式解决苹果检测问题,并改进小苹果的挑战性检测,提出了 。它由三个主要模块组成:(i)用半监督伪标签框架Soft Teacher[41]训练的目标检测器,允许利用数据集中大量无标签的数据,(ii)利用苹果和树冠之间的上下文关系来定位感兴趣区域的TreeAttention模块,以及(iii)从感兴趣区域中裁剪窗口的选择性窗口(selective tiling)模块,使目标检测器能够利用完整图像的分辨率,提高对小苹果的检测性能。在对两个数据集的全面评估中,利用上下文注意和选择性窗口,在小苹果和所有尺寸的苹果上显示了 的强大结果。
综上所述,本文的贡献有三个方面:
•将苹果检测重新制定为一个半监督任务,限制了标注工作量,并发布了一个数据集MAD,其中包含105个有标签的和4,440个无标签的高分辨率图像,其中有14,667个手动标注的苹果,这有助于新的表达方法。
•提出了一种新的苹果检测方法 ,它利用半监督学习、上下文注意力和选择性窗口来解决有限数量的有标签数据和小苹果大小。
•通过在MAD和MSU数据集上对 进行全面评估来验证,将其与强大的全监督小物体检测方法进行比较,并评估三个苹果属性的影响。
2 相关工作(Related Work)
本节简要回顾农作物检测、农作物检测数据集和小目标检测的相关工作。
农作物检测(Crop Detection) 在精准农业中,农作物的检测主要是基于标准目标检测器的变化。例如,文献[14]修改了YOLOv3来检测番茄,而文献[46]采用了SSD。文献[22]利用更快的R-CNN,并增加图像拼接和窗口窗口步骤来处理成排的植物。对于芒果的检测,文献[12]修改了YOLOv2,文献[29]提出了修改后的YOLOv4。
对于苹果检测,文献[3]和文献[6]分别采用了带有标准窗口(standard tiling)和闭塞感知检测模块的Faster R-CNN。转向YOLO,文献[37]提出了带有DenseNet主干的YOLOv3变种,以检测不同生长阶段的苹果。在文献[13]中,YOLOv3的性能通过预处理和后处理步骤得到增强。最近,文献[11]的作者使用非局部特征级注意力增强了YOLOv4,并使用卷积块注意力模块来检测低分辨率图像中的苹果。
相比之下,作者以半监督的方式解决苹果检测问题,并通过引入上下文注意和选择性窗口(selective tiling)来专注于检测小苹果。
**农作物检测数据集(Crop Detection Datasets) ** 农作物检测数据集适用于各种农作物[21]。然而,大多数农作物检测数据集在大小上是有限的。根据文献[8],最大的苹果检测数据集包含1404个有标签的图像[34],在低分辨率图像上有7065个标注实例。文献[3]也适用于苹果检测数据集,包含841张图像和5,765个标注实例。MiniApple数据集[8]包含更多的标注实例,在1001张中等分辨率(1280 × 720)的图像中有41325个标注实例。最近,MSU苹果数据集V2[6]被提出,该数据集包含900张苹果树冠特写图像中的14,518个带注释的苹果。
与这些数据集相比,作者提出的数据集MAD非常适合于包含有标签和无标签图像的半监督苹果检测。此外,该数据集比现有的数据集更大,有4545张高分辨率图像。
小目标检测(Small Object Detection) 小目标检测问题已经用不同的策略解决。参见文献[5]进行广泛的调查。一种主流的策略是使用多尺度或特定尺度的特征来改善小目标的表示。虽然文献[18]以自下而上和自上而下的方式学习特定尺度的特征,文献[19]重新组合这些特征以改进多尺度表示。文献[31]和文献[32]改进了目标检测器的训练策略,通过降低尺度内噪声,从特征金字塔转向图像金字塔。文献[23]通过由粗到细检测提高了该方法的效率。为提高特定尺度特征的表达能力,文献[17]调整不同尺度目标的感受野。最近,文献[42]采用了一种基于由粗到细查询的检测机制对连续更高分辨率的特征图进行检测。
除了改进特征表示外,一些工作还利用窗口(tiling)[25,39,43]或超分辨率[2,16,24]来提高特征的空间分辨率。另一种工作是利用注意力机制来突出小目标的特征或位置[20,44,45]。作者的苹果检测方法 与多尺度和窗口方法最为相关。然而,它被明确设计为在半监督框架中解决苹果的检测问题,例如,利用领域知识来学习上下文注意力。
3 数据采集与数据集(Data Acquisition & Dataset)
为了方便苹果检测任务的新半监督方法的制定,作者提出了修道院苹果数据集(Monastery Apple Dataset ,MAD)。这些数据是与德国Bad Oldesloe的一家修道院合作获得的。使用分辨率为4k (3840 × 2160)的DJI-Mini 3 Pro无人机采集了修道院苹果园16棵树的视频数据。数据收集是在2022年9月的一个月里,在不同的照明条件下进行的,以确保多样性。
为了生成训练、验证和测试分区,首先将6(训练)、2(验证)和4(测试)树的视频分配给各自的分区。从视频中,手动选择图像进行标注,以最大限度地提高数据的多样性。训练、验证和测试分成66、12和27帧,分别有10,089、1,288和3,290个带标注的实例,如表1所示。苹果是用边界框手工标注的。来自数据集的具有真实值的样本图像如图2所示。此外,自动为每个标注过的苹果分配了三个属性,分别代表相对大小、遮挡程度和光照条件,使得能够评估这些条件对方法的影响。训练分区中的4,440个无标签图像由未标注的6个训练树的帧和剩余4个未分配给其他分区的视频/树的帧组成。
4 方法(Method)
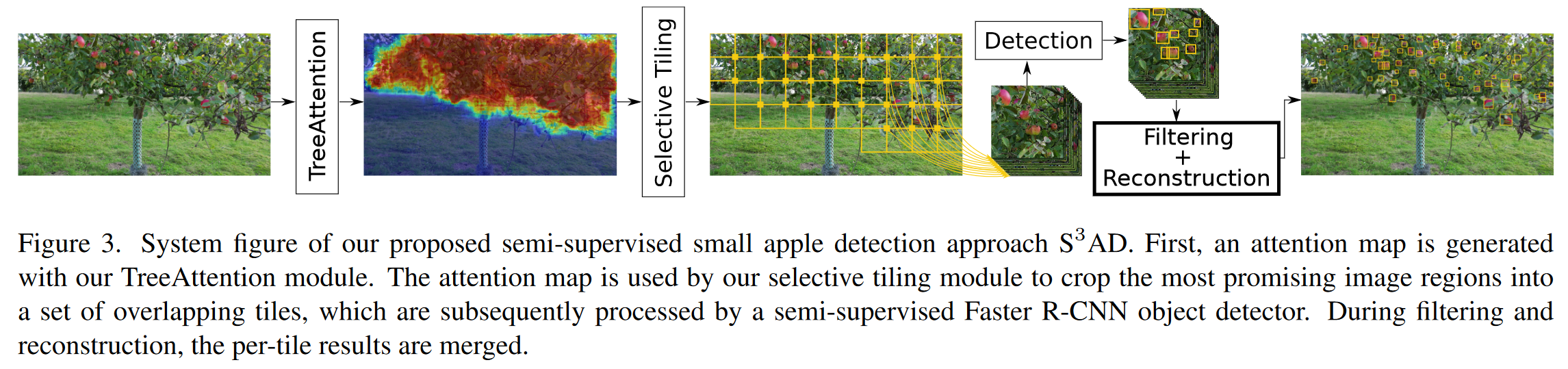
本节将介绍新颖的半监督小苹果检测方法 ,该方法专门用于解决相对苹果尺寸较小和标注数据量有限的难题。 包括四个步骤,如图 3 所示。给定输入图像后,新 TreeAttention 模块(见第 4.1 节)会利用上下文信息突出显示最有希望进行苹果检测的图像区域。这些区域随后会被选择性窗口模块提取出来(见第 4.2 节的说明),并裁剪成一组重叠的窗口图。对高分辨率图像进行窗口是有优势的,因为这样可以增大苹果的相对尺寸,并使目标检测器在处理图像时无需进行初始下采样。接下来,在软教师Soft Teacher框架(见第 4.3 节)[41]中训练一个带有 FPN 主干网络[18]的半监督 Fast R-CNN 目标检测器[27]。FPN 主干网络提高了对小苹果的检测能力,而软教师框架中的半监督训练则利用了未标注的数据。最后,在滤波和重构步骤中合并每个窗口的结果,详见第 4.4 节。
4.1 树注意力(Tree Attention)
在苹果检测中,试图检测树冠上的苹果。因此,在给定图像的情况下, 只需搜索树冠的区域,从而大大减少了搜索空间。一般来说,这被称为上下文信息,常用于小目标检测[4]。因此,提出 TreeAttention 作为 中的上下文注意力模块,将处理重点放在输入图像中最突出的树冠上。将在第 4.2 节中使用这种注意力来引导 的选择性窗口。
TreeAttention 模块基于简单的残差 U-Net 架构 [28],包括编码器和解码器中各有一个残差块的三个阶段。TreeAttention 模块的最终结果是一个注意力图,其值介于 1(高注意力)和 0(低注意力)之间,表示苹果的大致位置。由于这一步不需要精确定位,因此为了提高计算效率,将 TreeAttention 应用于较低分辨率的输入图像。在训练 TreeAttention 时,使用二元交叉熵损失和从相应数据集的边界框标注中获得的真实值。由于 TreeAttention 的目标是突出树冠,因此在图像中所有苹果的标注周围计算出 α = 100 的alpha shape作为真实值。alpha shape是凸壳的一般化,可在边界框周围形成紧密贴合的壳。

如图 4(a) 所示是一个mask示例,用于TreeAttention的训练, 相应的边界框如图 4(b) 所示。
4.2 选择性窗口(Selective Tiling)
为了提高高分辨率图像中小苹果的检测率, 采用了窗口法 [15, 30, 40],通过提取窗口图来增大小苹果的相对大小,以便进行检测。随后, 中的目标检测器会以全分辨率处理每个窗口片。因此,目标检测器可以利用窗口片中的所有可用信息,而且小苹果受 CNN 下采样的影响较小。由于标准窗口会大大增加运行时间,因此利用 TreeAttention 模块(见第 4.1 节)生成的注意力图来选择由 检测器处理的窗口。
从注意力图中提取相关窗口片时,首先使用 τ = 0.3 的阈值对注意力图进行二值化处理,并将其向上采样到原始图像大小。然后,在二值化的注意力图上移动一个 800 × 800 的滑动窗口,窗口间距为 400 像素。对于每个窗口,确定注意力值大于 τ 的像素数量,如果该数量大于 20%,则选择窗口片在 中进行进一步处理。窗口片之间的重叠可确保每个苹果至少完全包含在一个窗口中。与处理所有窗口片相比,这种方法大大减少了已处理窗口片的数量和 的推理时间,同时不会降低检测性能(见第 5.3 节)。
4.3 半监督检测(Semi-supervised Detection)
可与任意物目标检测器一起使用。由于以前农作物检测的成功应用[3, 8, 22],作者选择了以特征金字塔网络(Feature Pyramid Network,FPN)[18]为骨干的 Faster R-CNN [27]。Faster R-CNN 是一种两阶段目标检测器,首先生成不分类的目标候选框,然后对候选框进行分类和完善。在 中,分类是二元的(苹果与背景)。FPN 主干已被证明能改善 Faster R-CNN 对小目标的检测结果[18],这与苹果检测任务相吻合。如上所述,将检测器应用到每个选定的窗口区域,以提高对小苹果的检测。然后,如第 4.4 节所述,合并每个窗口片的结果。
为了利用提出的数据集 MAD 中的大量未标注数据,在半监督软教师框架 [41] 中训练 的Faster R-CNN检测器。软教师利用两个模型进行半监督训练:一个教师模型和一个学生模型。教师模型学习从无标签的数据中生成边框,而学生模型则使用有标签的数据和无标签的数据的组合进行训练,其中教师模型提供的边框作为伪真实值。在这项工作中,使用 Faster R-CNN 作为学生模型。在整个训练过程中,教师模型使用学生模型的指数移动平均值进行更新。由于教师会生成成千上万的候选框,因此采用了非最大抑制来消除冗余。此外,只有超过给定置信度的候选框才被视为伪真实值,以减少误报的数量。将伪标注的置信度阈值定为 0.9。
4.4 过滤与重构 (Filtering & Reconstruction)
对图像中每个选定的窗口片应用半监督 Fast R-CNN 检测器后, 通过过滤和合并每个窗口片的检测结果,并应用图像级过滤步骤来重构整个图像的结果。首先, 会过滤每个窗口的结果,以去除检测到的沿窗口片边界部分可见但在另一个窗口片中完全可见的苹果。这种部分苹果检测可能会导致误报,而且在根据 IoU 阈值合并每个窗口片结果后很难去除误报,因为部分苹果的检测与整个苹果的检测自然不会有很高的重叠度。为了解决这个问题, 在重建完整图像级结果之前,会移除每个窗口周围 100 像素宽边界上的检测结果。请注意,不会去除图像边缘的检测结果。在每个窗口滤波步骤之后, 会合并单个检测结果,然后应用 IoU 阈值为 0.5 的非最大抑制。
4.5 训练(Training)
中的半监督 Fast R-CNN 检测器是在软教师框架下训练的,并使用半监督 MS COCO 权重进行初始化。在对 MAD 进行训练时,使用了从所有标注的训练图像和使用 TreeAttention 挑选出的 41,415 张未标注图像中挑选出的窗口片(有关 TreeAttention 的挑选和训练详情,请参阅补充资料)。请注意,在训练实际检测器之前,TreeAttention 是作为一个单独的方法进行训练的。在训练过程中,图像窗口片的大小会在 600 到 1600 之间随机调整,并以 10 个为一组进行分组。在软教师框架中,使用 0.2 的数据采样率。因此,每批数据中的每个标注窗口片都会随机选取四张未标注的图像。该模型的学习目标是最小化由监督损失项和加权非监督损失项组成的联合损失(更多信息,请参阅 [41]),并使用 SGD 训练 100k 步,初始学习率、动量和权重衰减分别为 0.001、0.9 和 0.0001。此外,学习率在 60k 和 80k 步时除以 10,数据采样率在最后 5,500 步时逐渐降为 0。为确保高质量的伪标注,使用教师伪真实的前景阈值设置为 0.9。
5 评估(Evaluation)
为了验证 的优势,在引入的数据集 MAD 上进行了评估。如第 3 节所述,MAD 数据集涵盖了复杂的果园环境,其中苹果的相对大小较小,且只有有限数量的标注训练图像。此外,还通过在 MSU 数据集[6]上进行训练和测试,评估了提出的方法与其他苹果检测数据集的通用性。本章中的所有结果都是在相应的测试数据集上得出的。
在 MAD 数据集上,将 与专门用于检测小目标的五种强大的全监督基准进行了比较:带有 FPN 主干[18]的 Faster R-CNN [27](常用于农作物检测方法[3, 8, 22])、PANet [19]、SNIPER [32]、AutoFocus [23],以及基于transformer的目标检测器 Deformable DETR [47]。由于缺乏公开的实现方法,因此无法与其他农作物检测方法进行直接比较。在训练完全监督基准时,只使用了 MAD 的 66 幅标注训练图像,其中包含 10,089 个标注苹果。在 MSU数据集上,与 的基础方法 Faster RCNN+FPN 进行了比较。由于缺乏可用的实现,无法与 MSU 作者提出的 O2RNet [6] 进行比较。
为了与 MAD 的半监督设置相匹配,在训练 和 Faster R-CNN+FPN 时只对 10%的训练图像进行标注,从而得到 93 张标注训练图像。值得注意的是,在 MAD 中,只有 1.5% 的训练图像有标注。为了评估苹果检测结果的质量,使用了常用的基于 100 次检测的平均召回率(AR)和平均精度(AP)指标。平均召回率评估的是发现苹果的数量和精确定位的程度,而平均精确率还考虑了误报率。这两个指标通常用于评估目标检测 [26, 27] 和农作物检测方法 [8, 12, 34, 40]。作为定量结果的补充,还提供了定性结果。
5.1 MAD数据集结果(Results on MAD)
5.1.1 总体量化结果(Overall Quantitative Results)
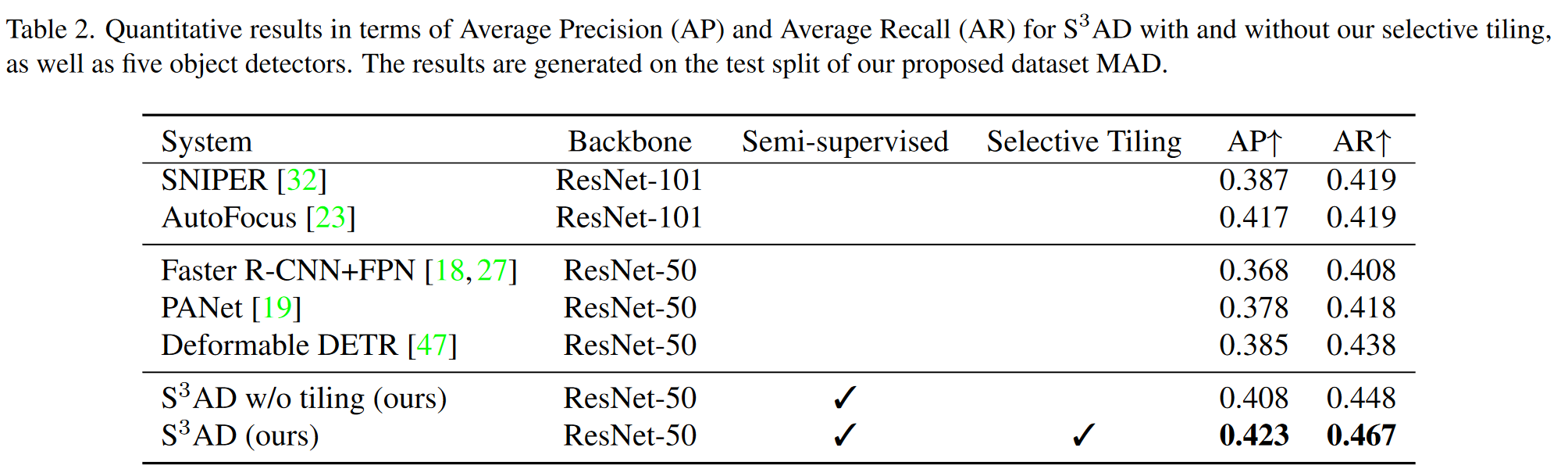
表 2 列出了使用和不使用选择性窗口的 以及五种完全监督基准的定量结果。从结果中可以明显看出, 的性能优于所有基线。与 的基础方法 Faster R-CNN+FPN 相比,通过使用无标签数据,AP 提高了 10.9%,而通过额外引入选择性窗口,AP 甚至提高了 14.9%。与其他专用的小目标检测方法 PANet 和 SNIPER 相比, 的 AP 提高了 11.9%。 甚至比基于transformer的 Deformable DETR 方法高出 9.9%。只有 AutoFocus 能够与 竞争。就 AP 而言,它只提高了 1.4%,但就 AR 而言,却提高了 11.5%,这凸显了 强大的召回能力。此外,AutoFocus 是用 ResNet-101 骨干网络训练的,而 是用较小的 ResNet-50 骨干网络训练的。最后,比较 有无窗口表明,选择性窗口对结果产生了积极影响,提高了 3.7%。总之,结果表明,在半监督训练中使用无标签数据具有很强的积极作用,而且选择性窗口也很有益处。
5.1.2 基于属性的定量结果(Property-based Quantitative Results)
在讨论了总体定量结果之后,将研究之前讨论过的基于 ResNet-50 主干网络的检测方法的行为: 的基础方法 Faster R-CNN+FPN、PANet 和 Deformable DETR。根据 MAD 中标注的三种苹果属性(相对大小、遮挡程度和光照条件)来检查其行为。图 5 给出了基于 AR 的、针对每种属性的不同水平的结果,其中每个数据点代表了特定属性规模上 2% 的标注苹果。通过选择 AR来显示在不对重复进行惩罚的情况下,能找到多少个具有相应属性的苹果。 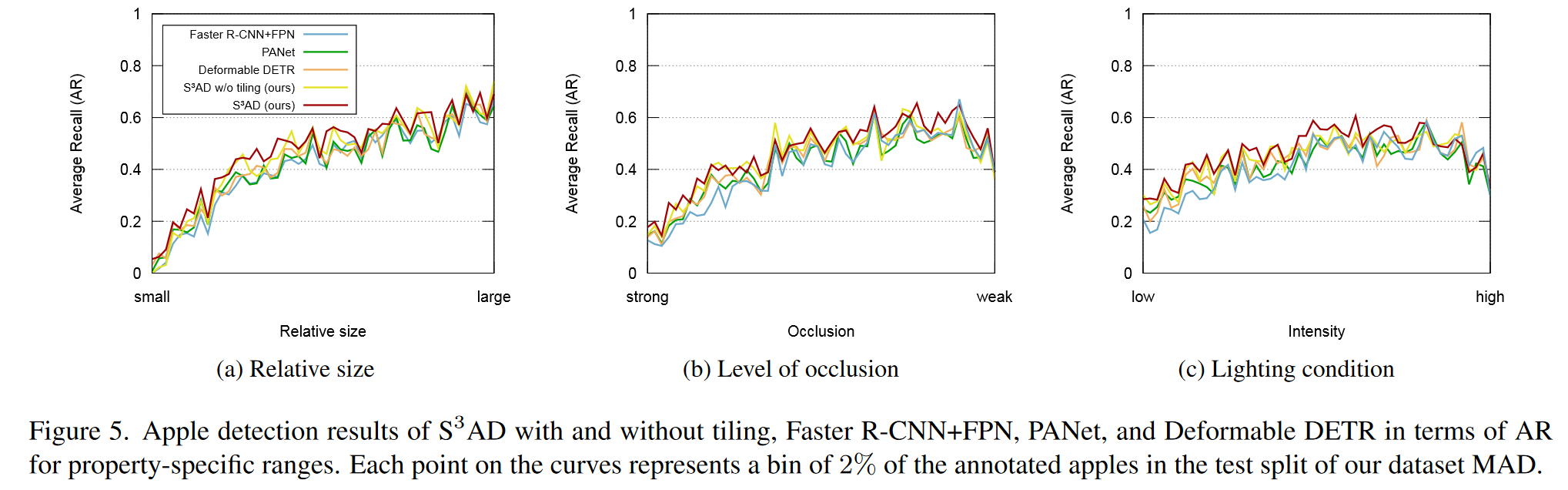
根据目标的相对大小对结果进行分析,可以清楚地看到 几乎始终优于所有其他方法。特别是在小目标上(图 5a 左侧部分), 比其他方法有更大的改进。为了更详细地分析这种改进,对前三分之一数据点/分区(小目标)和后三分之一数据点/分区(大目标)的平均改进进行了量化。在小目标上,使用窗口技术的 比不使用窗口技术的 高出 15%,而在大目标上仅提高了 1.7%。同样,与 Faster R-CNN+FPN 相比,在小目标上的改进幅度为 35.3%,而在大目标上的改进幅度仅为 7.4%。尽管有所改进,但所有方法的结果都随着相对目标大小的减小而下降。
在其他两个标注属性(遮挡程度和光照条件)上,各方法的表现类似。虽然 几乎始终优于其他方法,但所有方法在处理暗苹果、亮苹果和强遮蔽苹果时都同样表现不佳。从弱遮挡苹果(图 5b 中的右三分之一)到强遮挡苹果(图 5b 中的左三分之一), 的结果下降了 42.3%,而 PANet 和 Deformable DETR 的差异分别为 45.4% 和 46.7%。同样,从光线充足的苹果(图 5c 中的中间三分之一)到光线较暗的苹果(图 5c 中的左三分之一), 的性能下降了 24.4%,而 PANet 的性能下降了 26.5%。
总之,这一详细评估凸显了在 中提出的选择性窗口对小苹果检测的积极影响,而且与其他方法相比, 在小苹果方面的性能普遍提高。此外,从这三个特性中,可以得出并量化苹果检测方法所面临的挑战条件:小苹果、强遮挡苹果、暗苹果或亮苹果。
5.1.3 定性结果

除了定量结果,还在图 6 和图 7 中给出了定性结果。图 6 中的结果表明,与 Faster R-CNN+FPN 和 AutoFocus 相比, 能够改进对小苹果的检测。例如,在图 6 的上部示例中, 检测到了左上角的小苹果,而 Faster R-CNN+FPN 则没有检测到。此外,与 Faster R-CNN+FPN 和 AutoFocus 相比, 能更好地检测到几个被部分遮挡的非常小的苹果(见箭头)。这也证实了第 5.1.2 节中的结论,即在小苹果上 的强劲表现,在完全遮挡程度中, 的效果普遍更好。图 6 中的下部示例也支持上述结论。不过,在这个示例中,还可以清楚地看到,即使是 ,仍然会漏检一些小苹果,这主要是由于遮挡(中央红色箭头)或光照条件不足(右下角箭头)造成的。在第 5.1.2 节中,这三种特性也被认为是苹果检测所面临的主要挑战。

图 7 显示了 在有选择性窗口和没有选择性窗口情况下的结果,重点是选择性窗口的影响。正如定量结果所预料的那样,如果没有红色箭头表示的选择性窗口,就会漏掉几个小苹果。在下图的上半部分和右半部分可以看到多个这样的例子。例如,下部示例右下方用箭头标记的四个小苹果,在没有选择性窗口的情况下都被漏掉了。在这两个示例中,都有几个小苹果由于强烈遮挡而被错过。正如上例右上方的结果和图 5b 中的定量结果所示,应用选择性窗口后,这种情况也略有改善。不过,尽管进行了选择性窗口,仍有几个被强烈遮挡的苹果被遗漏。
总之,定性结果显示了 的强大性能,以及采用选择性窗口方法对小苹果检测的大幅改进,在一定程度上也适用于强遮挡苹果的检测。
5.2 MSU数据集结果(Results on MSU)
表 3 列出了 及其基础方法 Faster R-CNN+FPN 在 MSU 数据集中的结果。总体而言,结果趋势与 MAD数据集相似, 优于 Faster R-CNN+FPN。不过,与 MAD数据集相比,MSU数据集的方法之间的差距要大得多。在 MAD数据集 上,从 Faster R-CNN+FPN 到 的 AP仅提升了 14.9%,而在MSU数据集上则高达 50.5%。为了更详细地研究这一效果,还比较了没有窗口的 ,以区分选择性窗口和半监督训练的影响。在 AP 方面,不使用窗口的 已经比 Faster RCNN+FPN 高出 44.2%,这表明在没有大量标注图像的情况下,半监督学习具有强大的影响力。不过,提出的选择性窗口在 MSU 数据集上也很有效,当加入 后,又提高了 4.4%,这与在 MAD数据集上的结果相似。将带有选择性窗口的 与在 MSU 数据集全部标注训练数据集(842 张标注图像)上训练的 Faster R-CNN+FPN 版本进行比较后发现,尽管只使用了约 11% 的标注数据, 的结果却达到了完全监督的 Faster R-CNN 结果的 90%(0.518 vs. 0.579)。这再次彰显了 中提出的半监督训练的优势。总之,MSU数据集上的结果表明, 能够很好地泛化到其他苹果检测数据集,同时再次显示了半监督训练的优势。

5.3 选择性窗口方法分析(Analysis of Selective Tiling Approach)
在介绍了方法的主要结果后,进一步分析了选择性窗口方法,如图 5a 所示,这种方法提高了小苹果的检测率。
5.3.1 TreeAttention效果(Quality of TreeAttention)
首先,展示了学习的 TreeAttention 的结果,它旨在利用上下文信息选择前景树冠的所有相关窗口。总体而言,TreeAttention 能召回 99.71% 的标注苹果,而只处理了 62.47% 的所有窗口片。图 8 将 TreeAttention 的结果编码为热图,从图 8 的定性结果中也可以清楚地看到强大的召回率和良好的精确度。虽然两个树冠都被完全覆盖(红色覆盖),但大部分背景都被修剪掉了(蓝色覆盖)。因此,TreeAttention 是一种高质量的预处理机制,可以有效地集中处理,同时保持较强的整体检测性能。 
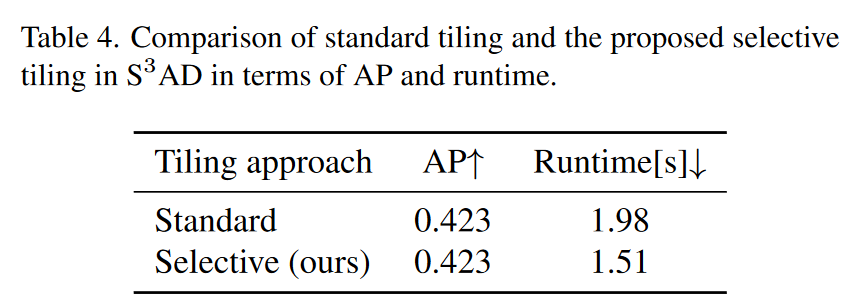
5.3.2 窗口方法的比较(Comparison of Tiling Approaches )
鉴于 TreeAttention 生成了高质量的注意力图,可以如前所述,大幅减少处理的窗口片数量。现在,将选择性窗口与提取所有考虑过的窗口的标准窗口化进行比较。表展示了提出方法在AP和运行时间方面的对比结果。虽然两种窗口策略的苹果检测结果在 AP 方面几乎保持不变,但选择性窗口方法的运行时间减少了 24.2%。因此,选择性窗口结合了标准窗口的优点,提高了对小目标的检测(见第 5.1.2 节),而运行时间仅有适度增加。
6 总结(Conclusion)
在本文中,作者将果园环境中的苹果检测问题重新表述为半监督检测任务,以便在缺乏大规模标注训练数据的情况下提高检测结果。为此,收集了一个新的苹果检测数据集 MAD,该数据集由 4,545 张高分辨率图像和 14,667 个带标注的苹果组成,其中包括大量用于半监督训练的无标签数据。利用 MAD 的优势,提出了 ,这是一种新型的半监督苹果检测方法,它基于上下文注意力、高效的选择性窗口方法和在软教师框架下训练的Faster R-CNN 检测器。窗口方法利用输入图像的全分辨率提高了小苹果的检测挑战,而 则利用上下文注意力来选择性地处理窗口,并限制窗口引起的额外运行时间。
在以复杂果园环境为特征的新数据集上进行了全面的评估,结果表明,与强大的基线相比, 的性能有了大幅提高(最高达 14.9%)。在 MSU 数据集上的进一步结果证实了这些改进。通过更详细地分析 的结果,发现特别是在小目标上,基于上下文信息的选择性窗口方法提高了性能,同时限制了额外的运行时间,并保持了较强的苹果检测性能。总之,本文提出了一种新的苹果检测任务重构方法和一种新颖、高质量的半监督苹果检测方法,解决了新的半监督苹果检测任务。
本文由 mdnice 多平台发布
)


)

)





)







)