RocketMQ高性能背后的核心原理
1.读队列与写队列
在RocketMQ的管理控制台创建Topic时,可以看到要单独设置读队列和写队列。
通常在运行时,都需要设置读队列=写队列。perm字段表示Topic的权限,有三个可选项
2:禁写禁订阅
4: 可订阅
6: 可写可订阅
这其中,写队列会真实的创建对应的存储文件,负责消息写入。而读队列会记录Consumer的Offset,负责消息读取,这其实是一种读写分离的思想。RocketMQ在设置MessageQueue的路由策略时,就可以通过指向不同的队列来实现读写分离

在往写队列里写Message时,会同步写入到一个对应的读队列中
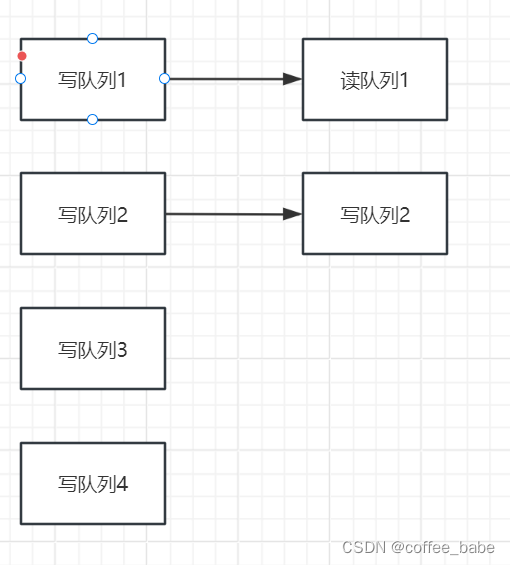
如果写队列大于读队列,就会有一部分写队列无法写入到读队列中,这一部分的消息就无法被读取,就会造成消息丢失 --消息存入了,但是读不出来
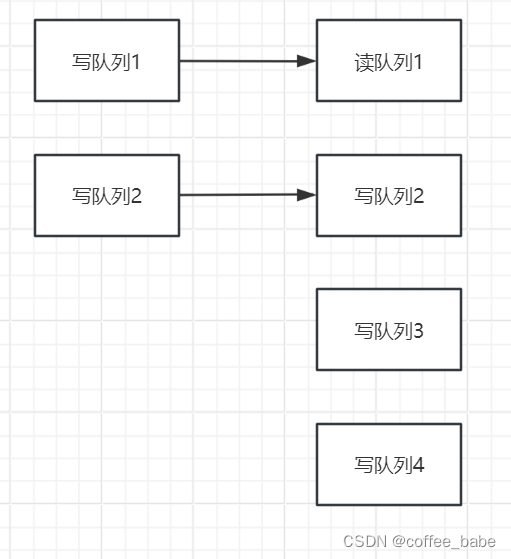
而如果反过来,写队列小于读队列,那就有一部分读队列里时没有消息写入的,如果有一个消费者,被分配的时这些没有消息的读队列,那这些消费者就无法消费消息,造成消费者空转,极大的浪费性能
从这里可以看到,写队列>读队列,会造成消息丢失,写队列<读队列,又会造成消费者空转,所以,在使用时,都是要求=读队列.只有一种情况下可以考虑将读写队列设置为不一致,就是要对Topic的MessageQueue进行缩减的时候。例如原来四个队列,现在要缩减成两个队列。如果立即缩减读写队列,那么被缩减的MessageQueue上没有被消费的消息,就会丢失,这时,可以先缩减写队列,待空出来的读队列上的消息都被消费完了之后,再来缩减读队列,这样就可以比较平稳的实现队列缩减了
2.消息持久化 --重点
RocketMQ消息直接采用磁盘文件保存消息,默认路径在${user_home}/store目录下,这些存储目录
可以在broker.conf中自行指定,存储文件主要分为三个部分
- CommitLog:存储消息的元数据。所有消息都会顺序存入到CommitLog文件当中。CommitLog由多个人文件组成,每个文件固定大小1G,以第一条消息的偏移量为文件名
- ConsumerQueue: 存储消息在CommitLog的索引。一个MessageQueue一个文件,记录当前MessageQueue被哪些消费者组,消费到了哪一条CommitLog.
- IndexFile: 为了消息查询提供了一种通过key或者时间区间来查询消息的方法,这种通过IndexFile来查找消息的方法不影响发送与消费消息的主流程
另外还有几个辅助的存储文件
- checkpoint:数据存盘检查点。里面主要记录commitlog文件、ConsumeQueue文件
以及IndexFile文件最后一次刷盘的时间戳 - config/*.json:这些文件是将RocketMQ的一些关键配置信息进行存盘保存。例如Topic配置、消费者组配置、消费者组消息偏移量Offset等等一些信息
- abort:这个文件是RocketMQ用来判断程序是否正常关闭的一个标识文件。正常情况下,会在启动时创建,而关闭服务时删除。但是如果遇到一些服务器宕机,或者kill -9这样一些非正常关闭服务的情况,这个abort文件就不会删除,因此RocketMQ就
可以判断上一次服务是非正常关闭的,后续就会做一些数据恢复的操作
整体的消息存储结构
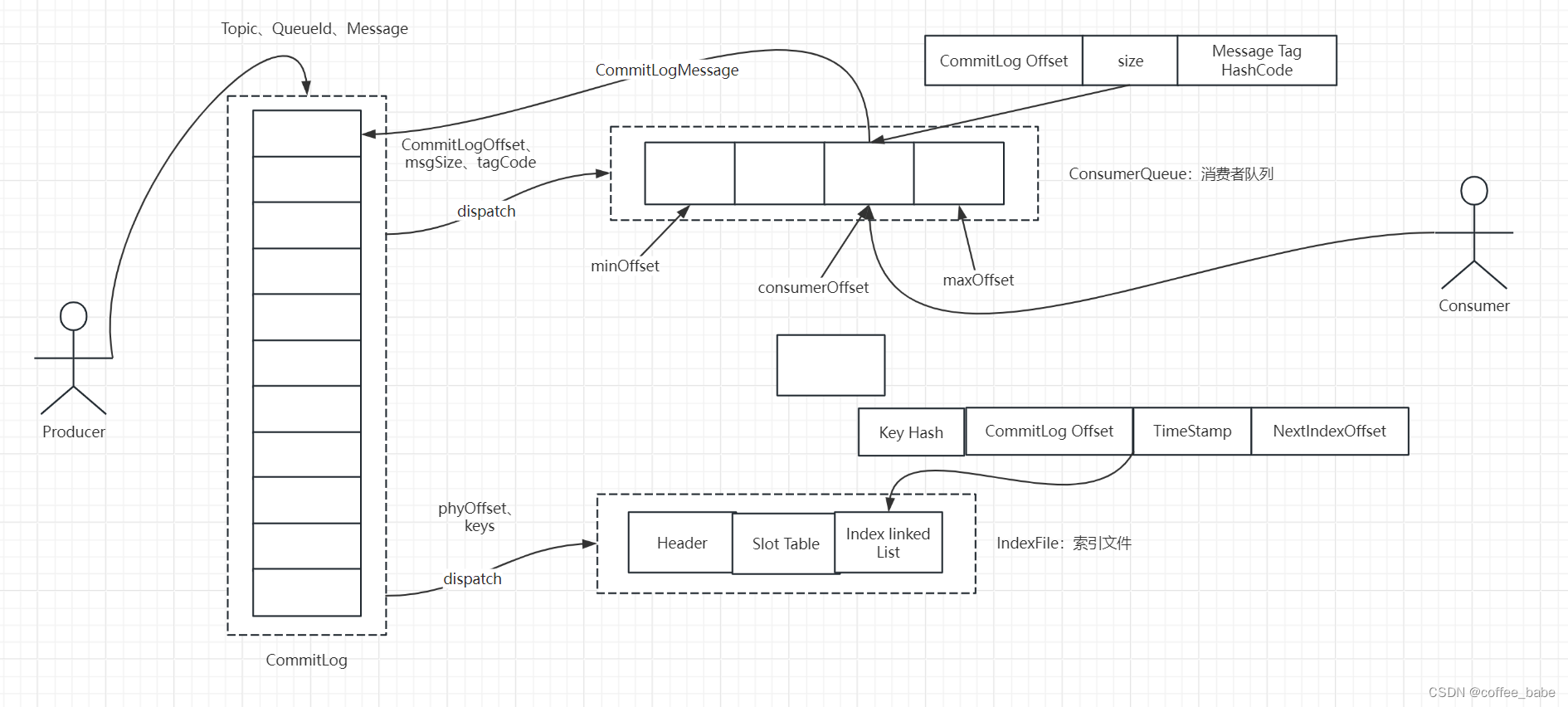
1.CommitLog文件存储所有消息实体。所有生产者发过来的消息,都会无差别的依次
存储到commitLog文件当中。这样的好处是可以减少查找目标文件的时间,让消息以
最快的速度落盘,对比Kafka存文件时,需要寻找消息所属的Partition文件,再完成写入,当Topic比较多时,这样的Partition寻址就会浪费比较多的时间,所以Kafka不太适合多Topic的,场景,而RocketMQ的这种快速落盘的方式在多Topic场景下,优势就比较明显
文件结构:CommitLog的文件大小是固定的,但是其中存储的每个消息单元长度是不固定的,具体格式可以参考org.apache.rokcet.store.CommitLog.正因为消息的记录大小不固定,所以RocketMQ在每次存CommitLog文件时,都会去检查当前CommitLog文件空间是否足够,如果不够的话,就重新创建一个CommitLog文件,文件名为当前消息的偏移量
2.ConsumeQueue文件主要是加速消费者的消息索引。它的每个文件夹对应RocketMQ中的一个MessageQueue,文件夹下的文件记录了每个MessageQueue中的消息在CommitLog文件当中的偏移量。这样,消费者通过ConsumeQueue文件,就可以快速找到CommitLog文件中感兴趣的消息记录。而消费者在COnsumeQueue文件当中的消费进度,会保存在config/consumerOffset.json文件当中
文件结构:每个COnsumeQueue文件固定由30万个固定大小20Byte的数据块组成,数据块的内容包括:msgPhyOffset(8Byte,消息在文件中的起始位置) + msgSize(4byte,消息在文件中占用的长度)
- msgTagCode(8Byte,消息tag的Hash值)
在ConsumeQueue.java当中有一个常量CQ_STORE_UNIT_SIZE=20,这个常量就表示一个数据块的大小
3.IndexFile文件主要是辅助消息检索。消费者进行消息消费时,通过ConsumeQueue文件就足够完成消息检索了,但是如果要按照MessageId或者Messagekey来检索文件,比如RocketMQ管理控制台的消息轨迹功能,ConsumeQueue文件就不够用了,IndexFile文件就是用来辅助这类消息检索的,它的文件名比较特殊,不是以消息偏移量命名,而是用的时间命名。但是其实,它也是一个固定大小的文件,
文件结构:它的文件结构由indexHeader(固定40byte) + slot(固定500w个,每个固定20Byte)
- index(最多500W*4个,每个固定20Byte)三部分组成
3.过期文件的删除
消息既然要持久化,就必须有对应的删除机制,RocketMQ内置了一套过期文件的删除机制,首先:如何判断过期文件:RocketMQ中CommitLog文件和ConsumeQueue文件都是以偏移量命名的,对于非当前写的文件,如果超过了一定的保留时间,那么这些文件都会被认为是过期文件,随时可以删除。这个保留时间就是在broker.conf中配置的fieReservedTime属性。注意,RocketMQ判断文件是否过期的唯一标准就是非当前写文件的保留时间,而并不关心文件当中的消息是否被消费过。所以,RocketMQ的
消息堆积也是有时间限度的
然后:何时删除过期文件:RocketMQ内部有一个定时任务,对文件进行扫描,并且触发文件删除的操作。用户可以指定文件删除操作的执行时间.在broker.conf中deleteWhen属性指定,默认是凌晨四点
另外,RocketMQ还会检查服务器的磁盘空间是否足够,如果磁盘空间的使用率达到一定的阈值,也会触发过期文件删除,所以RocketMQ官方就特别建议,broker的磁盘空间不要少于4G
4.高效文件写
RocketMQ采用了类似于Kafka的文件存储机制,但是文件存储是一个比较重的操作,
需要有非常多的设计才能保证频繁的文件读写场景下的高性能
零拷贝技术加速文件读写。
零拷贝(zero-copy)是操作系统层面提供的一种加速文件读写的操作机制,非常多的开源软件都在大量使用零拷贝,来提升IO操作的性能。对于Java应用层面,对应着mmap和sendFile两种方式
1.理解CPU拷贝和DMA拷贝

我们知道,操作系统对于内存空间,是分为用户态和内核态的,用户态的应用程序无法直接操作硬件,需要通过内核空间进行操作转换,才能真正操作硬件。这其实是为了保护操作系统的安全,正因为如此,应用程序需要与网卡、磁盘等硬件进行数据交互时,就需要在用户态和内核态之间来回的复制数据,而这些操作,原本都需要由CPU来进行任务的分配、调度等管理步骤的,早先这些IO接口都是由CPU独立负责,所以当发生大规模的数据读写操作时,CPU的占用率会非常高,见上图
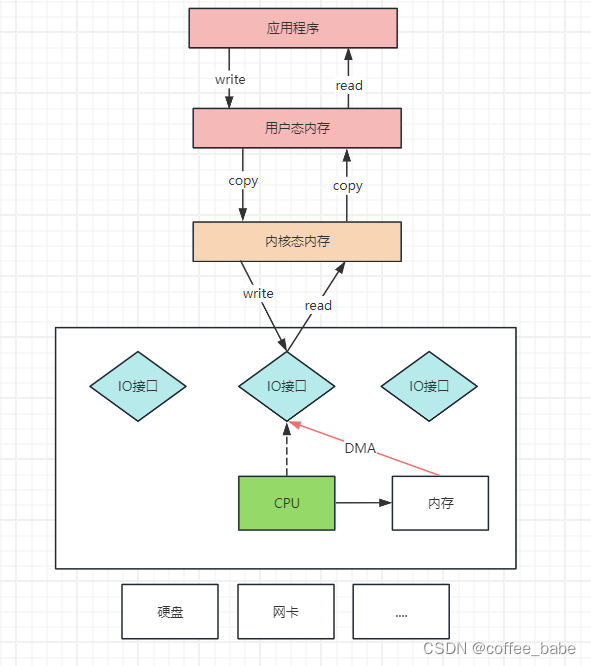
之后,操作系统为了避免完全被各种IO调用给占用,引入了DMA(Direct Memory Access,直接存储器访问),由DMA来负责这些频繁的IO操作,DMA是一套独立的指令集,不会占用CPU的计算资源,这样,CPU就不需要,参与具体的数据复制的工作,只需要管理DMA的权限即可,见上图,DMA拷贝极大地释放了CPU的性能,因此它
的拷贝要快很多,但是,其实DMA拷贝本身,也在不断优化。

引入DMA拷贝之后,在读写请求的过程重,CPU不再需要参与具体的工作,DMA可以独立完成数据在系统内部的复制。但是,数据复制过程中,造成总线冲突,最终还是会影响数据读写性能。为了避免DMA总线冲突对性能的影响,后来又引入了Channel通道的方式,Channel是一个完全独立的处理器,专门负责IO操作,既然是处理器,Channel就有自己的IO指令,与CPU无关,它也更适合大型的IO操作,性能更高,这也解释了,为什么Java应用层与零拷贝相关的操作都是通过Channel的字类实现的,
这其实是借鉴了操作系统中的概念,而所谓的零拷贝技术,其实并不是不拷贝,而是要尽量减少CPU拷贝
2.mmap文件映射机制
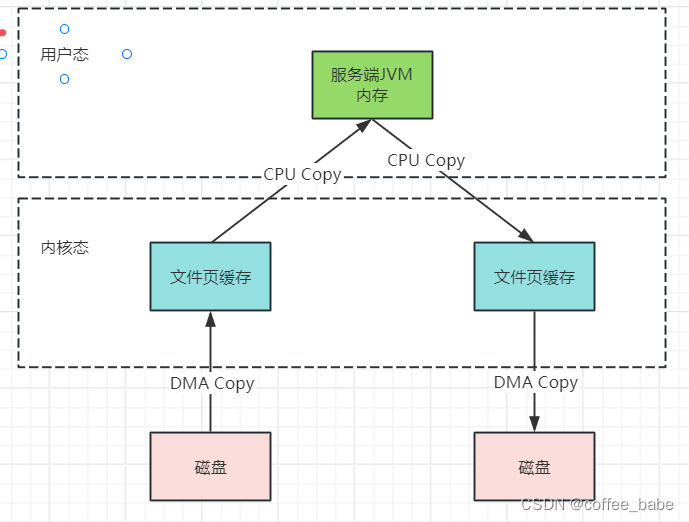
以一次文件的读写操作为例,应用程序对磁盘文件的读与写,都需要经过内核态与用户态之间的状态切换,每次状态切换的过程中,就需要有大量的数据复制,见上图,在这个过程中,总共需要进行四次数据拷贝,而磁盘与内核态之间的数据拷贝在操作系统层面已经由CPU拷贝优化成了DMA拷贝。而内核态与用户态之间的拷贝依然是CPU拷贝,所以,在这个场景下,零拷贝技术优化的重点,就是内核态与用户态之间的
这两次拷贝
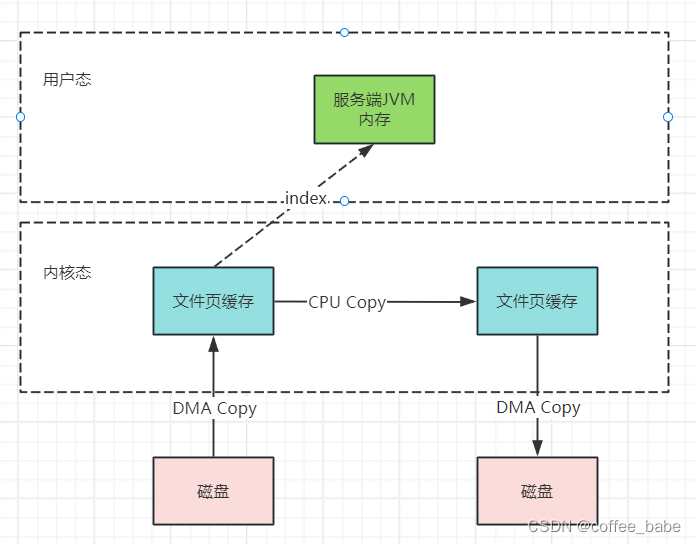
而mmap文件映射的方式,就是在用户态不再保存文件的内容,而只保存文件的映射,包括文件的内存起始地址,文件大小等。真实的数据,也不需要在用户态留存,可以直接通过操作映射,在内核态完成数据复制,见上图,这个拷贝过程都是在操作系统的系统调用层面完成的,在Java应用层,其实是无法直接观测到的,但是我们可以去JDK源码当中进行间接验证。在JDK的NIO包中,java.nio.HeapByteBuffer映射的就是JVM的一块堆内内存,在HeapByteBuffer中,会由一个byte数组来缓存数据内容,所有的读写操作也是先操作这个byte数组,这其实就是没有使用零拷贝的普通文件读写机制
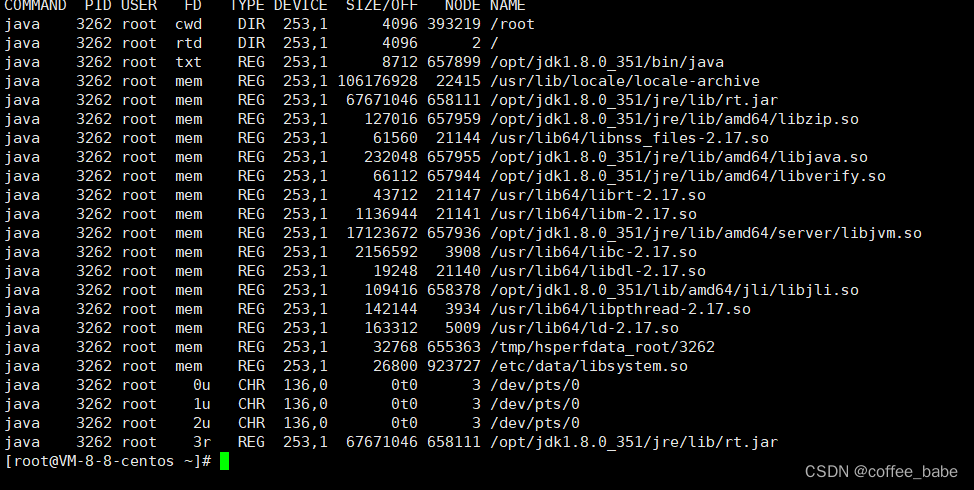
而NIO把包中的另一个实现类java.nio.DirectByteBuffer则映射的是一块堆外内存。在DirectByteBuffer中,并没有一个数据结构来保存数内容,只保存了一个内存地址。所有对数据的读写操作,都通过unsafe魔法类直接交由内核完成,这其实就是mmap的读写机制。mmap文件映射机制,其实并不射你,我们启动任何一个Java程序时,其实都大量用到了mmap文件映射。例如,我们可以在Linux机器上,运行一下,通过java指令运行起来后,使用JPS查看运行的进程ID,再使用lsof -p {PID}的方式查看文件的映射情况
import java.util.Scanner;public class BlockDemo {public static void main(String[] args) {Scanner scanner = new Scanner(System.in);final String s= scanner.nextLine();System.out.println(s);}
}
这里能看到的mem类型的FD其实就是文件映射,最后这种mmap的映射机制由于还是需要用户态保存文件的映射信息,数据复制的过程也需要用户态的参与,这其中的变数还是非常多的,所以,mmap机制适合操作小文件,如果文件太大,映射信息也会过大,容易造成很多问题。通常mmap机制建议的映射文件大小不要超过2G.RocketMQ做大的CommitLog文件保持再1G固定大小,也是为了方便文件映射
3.sendFile机制是怎么运行的
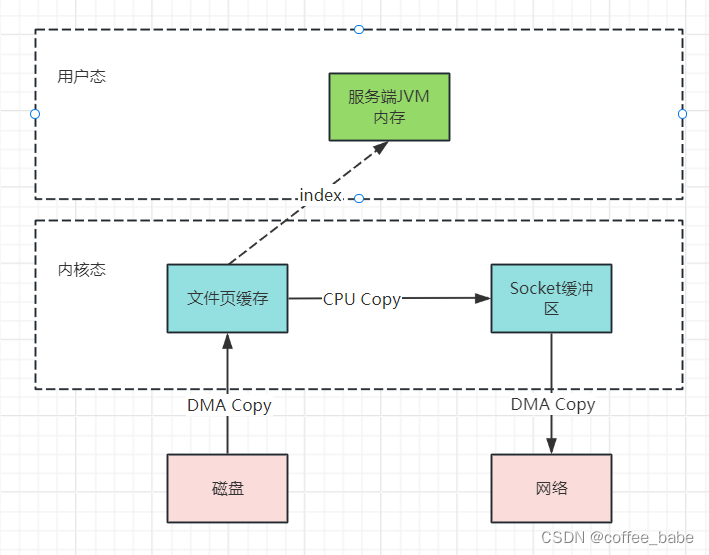
sendFile主要是通过java.nio.channels.FileChannel的transferTo方法完成的
sourcereadChannel.transferTo(0,sourceFile.length(), targetWriteChannel);
还记得Kafka当中是如何使用零拷贝的吗?就是将文件从磁盘复制到网卡时,就
大量地使用了零拷贝,见上图,早期地sendfile实现机制其实还是依靠CPU进行
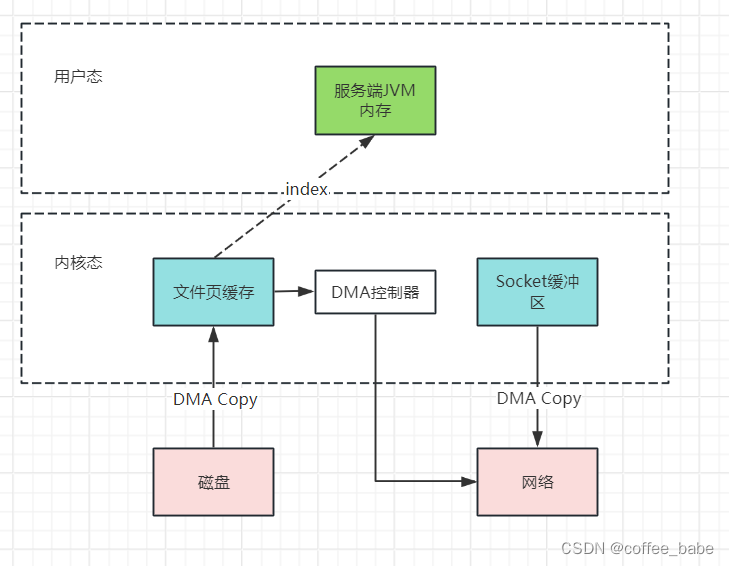
页缓存与Socket缓冲区之间的数据拷贝,但是,在后期的不断改进过程中,sendFile
优化了实现机制,在拷贝过程中,并不直接拷贝文件的内容,而只是拷贝一个带有
文件位置和长度等信息的文件描述符FD,这样就大大减少了需要传递的数据。而真实
的数据内容,会交由DMA控制器,从也缓存中打包异步发送到socket中
Linux操作系统的man手册可以帮助看到一部分答案,使用man systemcall sendfile
就能看到Linux操作系统对于sendfile这个系统调用的手册,在2.6.33以前的Linux内核中,out_fd只能是一个socket,但是现在的版本已经没有了这个限制,它可以是任何文件。最后,sendFile机制在内核态直接完成了数据的复制,不需要用户态的参与,所以这种机制的传输效率是非常稳定的,sendFile机制非常适合大数据的复制转移

顺序写加速文件写入磁盘。
通常应用程序往磁盘写文件时,由于磁盘空间不是连续的,会有很多碎片,所以在写一个文件时,也就无法把一个文件卸载一块连续的磁盘空间中,而需要在磁盘多个扇区之间进行大量的随机写,这个过程中有大量的寻址操作,会严重影响写数据的性能,而顺序写机制是在磁盘中提前申请一块连续的磁盘空间,每次写数据时,就可以避免这些寻址操作,直接在之前写入的地址后面接着写就行。Kafka官方详细分析过顺序写的性能提升问题,Kafka官方曾说明,顺序写的性能基本能够达到内存级别,
而如果配备固态硬盘,顺序写的性能甚至有可能超过写内存,而RocketMQ很大程度上借鉴了Kafka的这思想
刷盘机制保证消息不丢失。
在操作系统层面,当应用程序写入一个文件时,文件内容并不会直接写入到硬件当中,而是会先写入到操作系统中的一个缓存PageCache中。PageCache缓存以4K大小为单位,缓存文件的具体内容。这些写入到PageCache中的文件,在应用程序看来,是已经完全落盘保存好了的,可以正常修改、复制等等。但是,本质上PageCache依然是内存形态,所以一断电就会丢失,因此,需要将内存状态的数据写入到磁盘当中,这样数据才能真正完成持久化,断电也不会丢失这个过程就称为刷盘

PageCache是源源不断产生的,而Linux操作系统显然不可能时时刻刻往硬盘写文件,
所以,操作系统只会在某些特定的时刻将PageCache写入到磁盘。例如当我们正常关机时,就会完成PageCache刷盘,另外,在Linux中,对于有数据修改的PageCache,会标记为Dirty(脏页)状态。当DirtyPage的比例达到一定的阈值时,就会触发一次刷盘操作,例如在Linux操作系统当中,可以通过/proc/meminfo文件查看到PageCache的状态
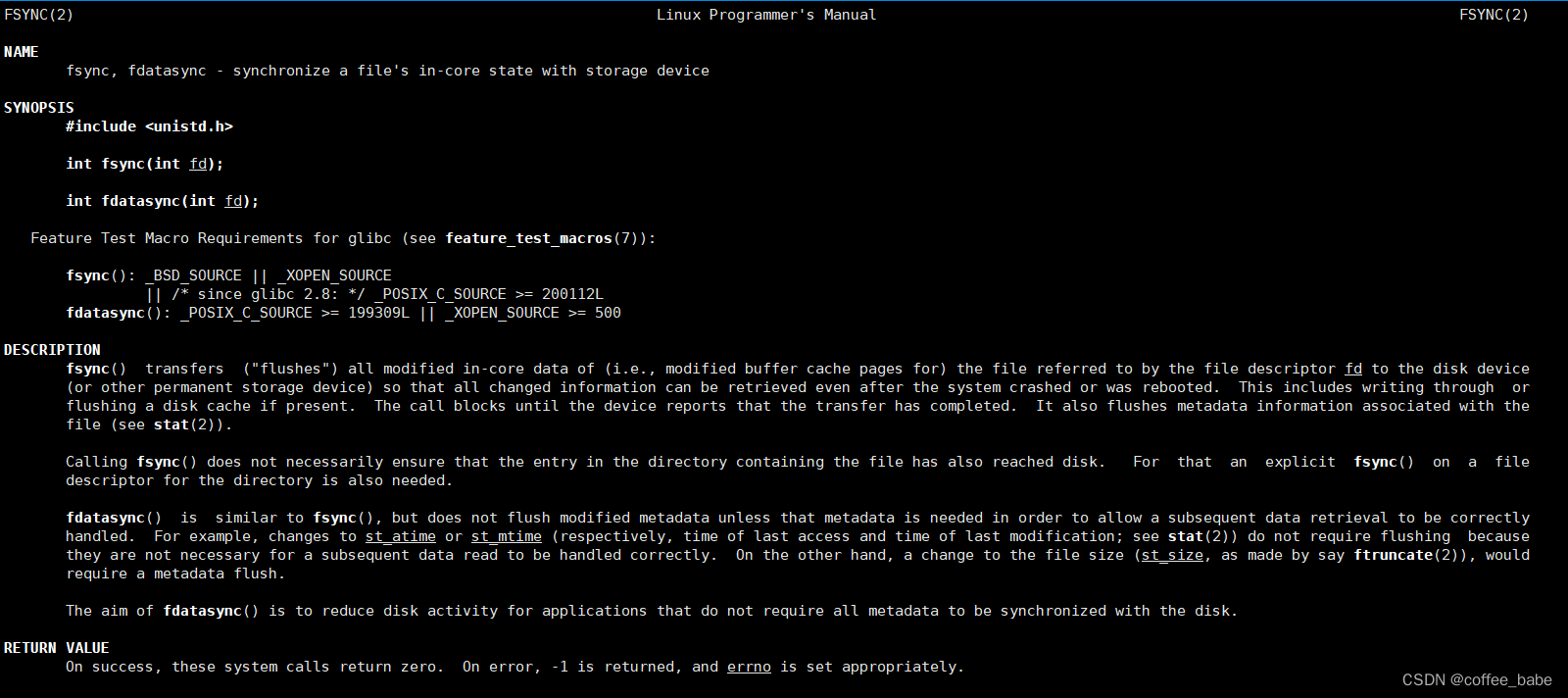
但是,只要操作系统的刷盘操作不是时时刻刻执行的,那么对于用户态的应用程序来说,那就避免不了非正常宕机时的数据丢失问题,因此,操作系统也提供了一个系统调用,应用程序可以自行调用这个系统调用,完成PageCache的强制刷盘。在Linux中时fsync(),也可以用man systemcall fsync()进行查看

RocketMQ对于何时进行刷盘,也设计了两种刷盘机制,同步刷盘和异步刷盘
同步刷盘。
在返回写成功状态时,消息已经被写入磁盘。具体流程是,消息写入内存的PageCache后,立刻通知刷盘线程刷盘,然后等待刷盘完成,刷盘线程执行完后唤醒等待的线程,返回消息写成功的状态
异步刷盘。
在返回写成功状态时,消息可能只是被写入了内存的PageCache,写操作的返回快,吞吐量大,当内存里的消息量积累到一定程度时,统一触发写磁盘动作,快速写入
配置方式:刷盘方式是通过Broker配置文件里的flushDiskType参数设置的,这个参数被配置成SYNC_FLUSH、ASYNC_FLUSH中的一个,同步刷盘机制会更频繁地调用fsync,所以吞吐量相比异步刷盘会降低,但是数据地安全性会得到提高



)
算法:从理论到实战全解析)
项目方舟框架(ArkUI)之Swiper容器组件)


)






)



FSM Gateway 的会话保持功能)