1. 背景
本qiang~这段时间调研了LLM上下文扩展的问题,并且实打实的运行了几个开源的项目,所谓实践与理论相结合嘛!
此文是本qiang~针对上下文扩展问题的总结,包括解决方案的整理概括,文中参考了多篇有意义的文章,他山之石可以攻玉。
大语言模型的扩展有诸多意义,如进行更长的会话、总结更长的文档等。
2. 上下文扩展方案
2.1 位置插值
位置插值(Position Interpolation)是Meta研究人员在去年发布的论文《EXTENDING CONTEXT WINDOW OF LARGE LANGUAGE MODELS VIA POSITION INTERPOLATION》提出的方案,基线模型为LLAMA,LLAMA采用的位置编码是苏神提出的ROPE(如果苏神的文章理论不清楚,推荐拜读下FireFly作者的《图解RoPE旋转位置编码及其特性》,连接在文末),但ROPE的外推性效果不佳,位置插值则做了进一步的改进优化。
位置插值的原理图如下:
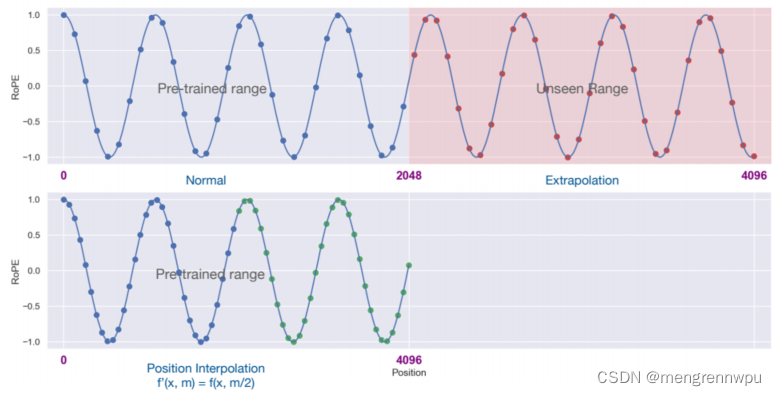
原理其实很简单,通过线性降低输入位置索引以匹配原始上下文窗口大小,然后通过少量微调工作,然后将LLaMA 7B和65B模型初始的2048扩展到32768,效率和效果均有保障。
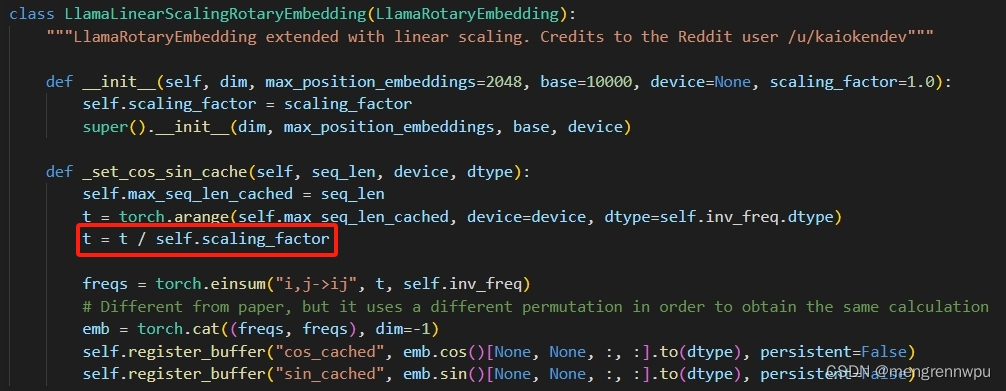
位置插值的代码可以参考transformers中LlamaLinearScalingRotaryEmbedding方法,该防范继承了ROPE的基础类LlamaRotaryEmbedding,改动之处仅在于图中标红之处。
2.2 LongLoRA
LongLoRA是港中文大学和MIT联合发出的论文《LONGLORA:EFFICIENT FINE-TUNING OF LONGCONTEXT LARGE LANGUAGE MODELS》提出的方法,本论文的主要改进之处在于:
1. 基于位置插值方法,在上下文扩展任务中引入LoRA方法,降低对硬件资源的专需。
2. 提出了shift short attention,将attention的直接计算改进为分组计算,且保障相邻组间信息共享。
3. 将norm层及embed层也加入到微调训练中,该部分的参数占比相对较少。
LoRA大家应该很熟悉,下面将重点介绍shift short attention。原理图如下:
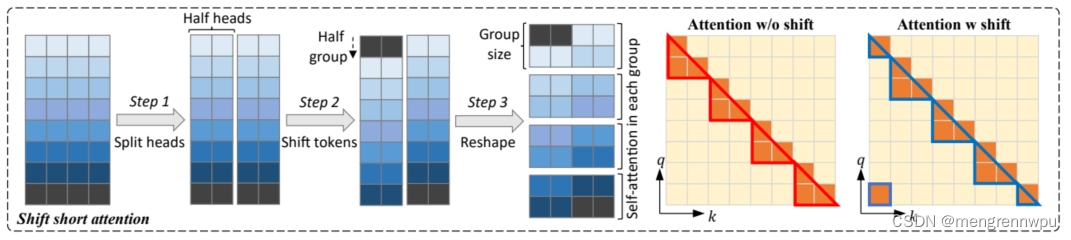
(1) 首先将head维度的特征拆分为2块
(2) 然后将其中一组的特征被移动,移动大小为group size的一半
(3) 将tokens拆分成组,且reshape为batch维,然后attention计算
(4) 最后将计算后的结果进行还原。
shift short attention的伪代码如下,具体代码可以参考LongLoRA的github仓库:

2.3 LongQLoRA
LongQLoRA的论文是《LONGQLORA: EFFICIENT AND EFFECTIVE METHOD TO EXTEND CONTEXT LENGTH OF LARGE LANGUAGE MODELS》,主要的思想就是在LongLoRA的基础上引入了量化操作,进一步降低了显卡需求。(Ps: 其实LongLoRA项目本身也集成了量化微调)
LongQLoRA仅在一张32G的V100上,可以将LLaMA2的7B和13B从4096扩展到8192甚至12K,仅需要1000步微调即可。
LongQLoRA本身也是基于transformers架构,因此引入量化配置仅需要些许改动即可,具体如下:

3. 总结
一句话足矣~
本文主要展示了LLM长文本扩展的方法,包括位置插值、LongLoRA、LongQLoRA等论文的简单概述。
此外,所有的论文最好能够结合源码进行开展,目前本qiang~就在践行这一条路线,欢迎大家一块交流。
4. 参考
(1) ROPE原理: https://spaces.ac.cn/archives/8265
(2) 图解ROPE: https://mp.weixin.qq.com/s/-1xVXjoM0imXMC7DKqo-Gw
(3) 位置插值论文: https://arxiv.org/pdf/2306.15595v2.pdf
(4) LongLoRA论文: https://arxiv.org/pdf/2309.12307v2.pdf
(5) LongLoRA代码:https://github.com/dvlab-research/longlora
(6) LongQLoRA论文:https://arxiv.org/pdf/2311.04879v2.pdf
(7) LongQLoRA代码:https://github.com/yangjianxin1/longqlora

)








(面试重点))
)




在NLP-NER任务中的应用)



