文章目录
- 一:简介
- 二:Go标准库compress/gzip包介绍
- Constants
- Variables
- type Header
- type Reader
- 三:代码实践
- 1、压缩与解压工具包
- 2、单元测试
- 3、为何压缩后还要用base64编码
代码地址: https://gitee.com/lymgoforIT/golang-trick/tree/master/41-go-gzip
一:简介
在工作中,我们有时候需要用到Redis来缓存数据,减轻DB的压力,并提升访问性能。但是当要缓存的key数据过大了会带来BigKey问题:30.Go处理Redis BigKey
在介绍BigKey问题的影响和解决办法时,我们其实说过,最好的办法是预防BigKey的出现,而不是出现后去解决。
但有些场景要缓存的一条信息内容可能就是比较大,且无法拆分,这时候怎么办呢?那就压缩后再存入Redis吧。
二:Go标准库compress/gzip包介绍
compress/gzip是Go标准库中的一个压缩工具包,中文文档地址:https://studygolang.com/static/pkgdoc/pkg/compress_gzip.htm
gzip包实现了gzip格式压缩文件的读写,核心内容如下。
-
Constants:常量定义
-
Variables:变量定义
-
type Header:数据头结构
-
type Reader:解压
- func NewReader(r io.Reader) (*Reader, error)
- func (z *Reader) Reset(r io.Reader) error
- func (z *Reader) Read(p []byte) (n int, err error)
- func (z *Reader) Close() error
-
type Writer:压缩
- func NewWriter(w io.Writer) *Writer
- func NewWriterLevel(w io.Writer, level int) (*Writer, error)
- func (z *Writer) Reset(w io.Writer)
- func (z *Writer) Write(p []byte) (int, error)
- func (z *Writer) Flush() error
- func (z *Writer) Close() error
Constants
const (NoCompression = flate.NoCompression // 不压缩BestSpeed = flate.BestSpeed // 最快速度BestCompression = flate.BestCompression // 最佳压缩比DefaultCompression = flate.DefaultCompression // 默认压缩比
)
这些常量都是拷贝自flate包,因此导入"compress/gzip"后,就不必再导入"compress/flate"了。
Variables
var (// 当读取的gzip数据的校验和错误时,会返回ErrChecksumErrChecksum = errors.New("gzip: invalid checksum")// 当读取的gzip数据的头域错误时,会返回ErrHeaderErrHeader = errors.New("gzip: invalid header")
)
type Header
//数据头结构
type Header struct {Comment string // 文件注释Extra []byte // 附加数据ModTime time.Time // 文件修改时间Name string // 文件名OS byte // 操作系统类型
}
gzip文件保存一个头域,提供关于被压缩的文件的一些元数据。该头域作为Writer和Reader类型的一个可导出字段,可以提供给调用者访问。
type Reader
type Reader struct {Header// 内含隐藏或非导出字段
}
Reader类型满足io.Reader接口,可以从gzip格式压缩文件读取并解压数据。
一般情况下,一个gzip文件可以是多个gzip文件的串联,每一个都有自己的头域。从Reader读取数据会返回串联的每个文件的解压数据,但只有第一个文件的头域被记录在Reader的Header字段里。
gzip文件会保存未压缩前数据的长度与校验和。当读取到未压缩数据的结尾时,如果数据的长度或者校验和不正确,Reader会返回ErrCheckSum,如果没有读取完毕后,长度和校验和与压缩前数据的一致,说明解压成功。因此,调用者应该将Read方法返回的数据视为暂定的,直到他们在数据结尾获得了一个io.EOF。
func NewReader
func NewReader(r io.Reader) (*Reader, error)
NewReader返回一个从r读取并解压数据的Reader。其实现会缓冲输入流的数据,并可能从r中读取比需要的更多的数据(如长度和校验和)。调用者有责任在读取完毕后调用返回值的Close方法。
注意入参是io.Reader,返回值是*gzip.Reader,但*gzip.Reader(Struct)也是实现了io.Reader接口的
func (*Reader) Reset
func (z *Reader) Reset(r io.Reader) error
Reset将z重置,丢弃当前的读取状态,并将下层读取目标设为r。效果上等价于将z设为使用r重新调用NewReader返回的Reader。这让我们可以重用z而不是再申请一个新的。(因此效率更高)
func (*Reader) Read
func (z *Reader) Read(p []byte) (n int, err error)
func (*Reader) Close
func (z *Reader) Close() error
调用Close会关闭z,但不会关闭下层io.Reader接口。
type Writer
type Writer struct {Header// 内含隐藏或非导出字段
}
Writer满足io.WriteCloser接口。它会将提供给它的数据压缩后写入下层io.Writer接口。
func NewWriter
func NewWriter(w io.Writer) *Writer
NewWriter创建并返回一个Writer。写入返回值gzip.Writer的数据都会在压缩后写入入参指定的w中。调用者有责任在结束写入后调用返回值gzip.Writer的Close方法。因为写入的数据可能保存在缓冲中没有刷新入下层。
如要设定Writer.Header字段,调用者必须在第一次调用Write方法或者Close方法之前设置。Header字段的Comment和Name字段是go的utf-8字符串,但下层格式要求为NUL中止的ISO 8859-1 (Latin-1)序列。如果这两个字段的字符串包含NUL或非Latin-1字符,将导致Write方法返回错误。
func NewWriterLevel
func NewWriterLevel(w io.Writer, level int) (*Writer, error)
NewWriterLevel类似NewWriter但指定了压缩水平而不是采用默认的DefaultCompression。
参数level可以是DefaultCompression、NoCompression或BestSpeed与BestCompression之间的任何整数。如果level合法,返回的错误值为nil。
func (*Writer) Reset
func (z *Writer) Reset(dst io.Writer)
Reset将z重置,丢弃当前的写入状态,并将下层输出目标设为dst。效果上等价于将w设为使用dst和w的压缩水平重新调用NewWriterLevel返回的*Writer。这让我们可以重用z而不是再申请一个新的。(因此效率更高)
func (*Writer) Write
func (z *Writer) Write(p []byte) (int, error)
Write将p压缩后写入下层io.Writer接口。压缩后的数据不一定会立刻刷新,除非Writer被关闭或者显式的刷新,即调用Close方法或者Flush方法。
func (*Writer) Flush
func (z *Writer) Flush() error
Flush将缓冲中的压缩数据刷新到下层io.Writer接口中。
本方法主要用在传输压缩数据的网络连接中,以保证远端的接收者可以获得足够的数据来重构数据报。Flush会阻塞直到所有缓冲中的数据都写入下层io.Writer接口后才返回。如果下层的io.Writetr接口返回一个错误,Flush也会返回该错误。在zlib包的术语中,Flush方法等价于Z_SYNC_FLUSH。
func (*Writer) Close
func (z *Writer) Close() error
调用Close会关闭z,但不会关闭下层io.Writer接口。
三:代码实践
1、压缩与解压工具包
package utilimport ("bytes""compress/gzip""context""encoding/base64""fmt"
)// GzipEncode 采用gzip算法压缩字符串,输出base64编码的字符串
func GzipEncode(ctx context.Context, input string) (string, error) {if len(input) == 0 {return input, nil}var b bytes.Buffer // 实现了io.Writergz := gzip.NewWriter(&b)defer func() {if err := gz.Close(); err != nil {fmt.Println(fmt.Sprintf("gz.Close() err:%v", err))}}()if _, err := gz.Write([]byte(input)); err != nil {fmt.Println(fmt.Sprintf("[GzipEncode] gz write err:%v", err))return "", err}// 将gzip.Writer缓冲中的数据刷到底层io.Writer中if err := gz.Flush(); err != nil {fmt.Println(fmt.Sprintf("[GzipEncode] gz flush err:%v", err))return "", err}// 在读取数据之前必须close,否则读取的数据会有问题,在这里作用同Flush一样// 即将压缩后的数据立即写入底层io.Writer中,在这里是b(bytes.Buffer)if err := gz.Close(); err != nil {fmt.Println(fmt.Sprintf("[GzipEncode] gz close err:%v", err))return "", err}newStr := base64.StdEncoding.EncodeToString(b.Bytes())return newStr, nil
}// GzipDecode 采用gzip算法解压字符串
func GzipDecode(ctx context.Context, input string) (string, error) {newInput, err := base64.StdEncoding.DecodeString(input)if err != nil {fmt.Println(fmt.Sprintf("[GzipDecode] base decode err:%v", err))return "", err}bReader := bytes.NewReader(newInput)gReader, err := gzip.NewReader(bReader)if err != nil {fmt.Println(fmt.Sprintf("[GzipDecode] new reader err,%v", err))return "", err}if err = gReader.Close(); err != nil {fmt.Println(fmt.Sprintf("[GzipDecode] reader close err:%v", err))return "", err}buf := new(bytes.Buffer)if _, err = buf.ReadFrom(gReader); err != nil {fmt.Println(fmt.Sprintf("[GzipDecode] read from greader err:%v", err))return "", err}return buf.String(), err
}
2、单元测试
package utilimport ("context""fmt""testing"
)func TestGzipEncode(t *testing.T) {encode, err := GzipEncode(context.Background(), "hello world")if err != nil {fmt.Println(fmt.Sprintf("GzipEncode err:%v", err))return}fmt.Println(fmt.Sprintf("res:%v", encode))
}func TestGzipDecode(t *testing.T) {decode, err := GzipDecode(context.Background(), "H4sIAAAAAAAA/8pIzcnJVyjPL8pJAQAAAP//AQAA//+FEUoNCwAAAA==")if err != nil {fmt.Println(fmt.Sprintf("GzipEncode err:%v", err))return}fmt.Println(fmt.Sprintf("res:%v", decode))
}当执行TestGzipEncode后,我们可以看到输出为
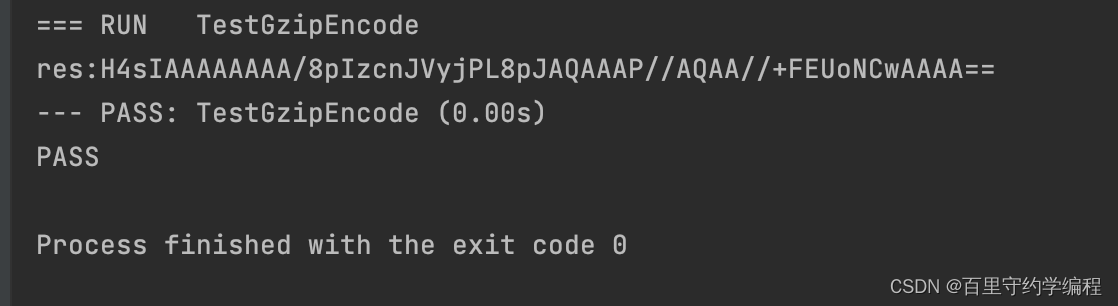
当执行TestGzipDecode后,可以看到输出为

测试结果符合预期。
此时可能会有一个疑问,一个hello world压缩并用base64编码后,字符串长度更长了,这不是与压缩的初衷背道而驰了嘛?是的,这里只是为了演示,所以用了个hello world,实际场景下,既然选择了压缩,那肯定是已知要压缩的内容是比较大的。
比如我们稍微将字符串变长一些,看看效果就知道压缩对于减少内存占用确实是有用的

3、为何压缩后还要用base64编码
我们可以将util中的源代码去掉base64编码后,单元测试一下看看原始gzip压缩后,字符串会是什么形式呢?
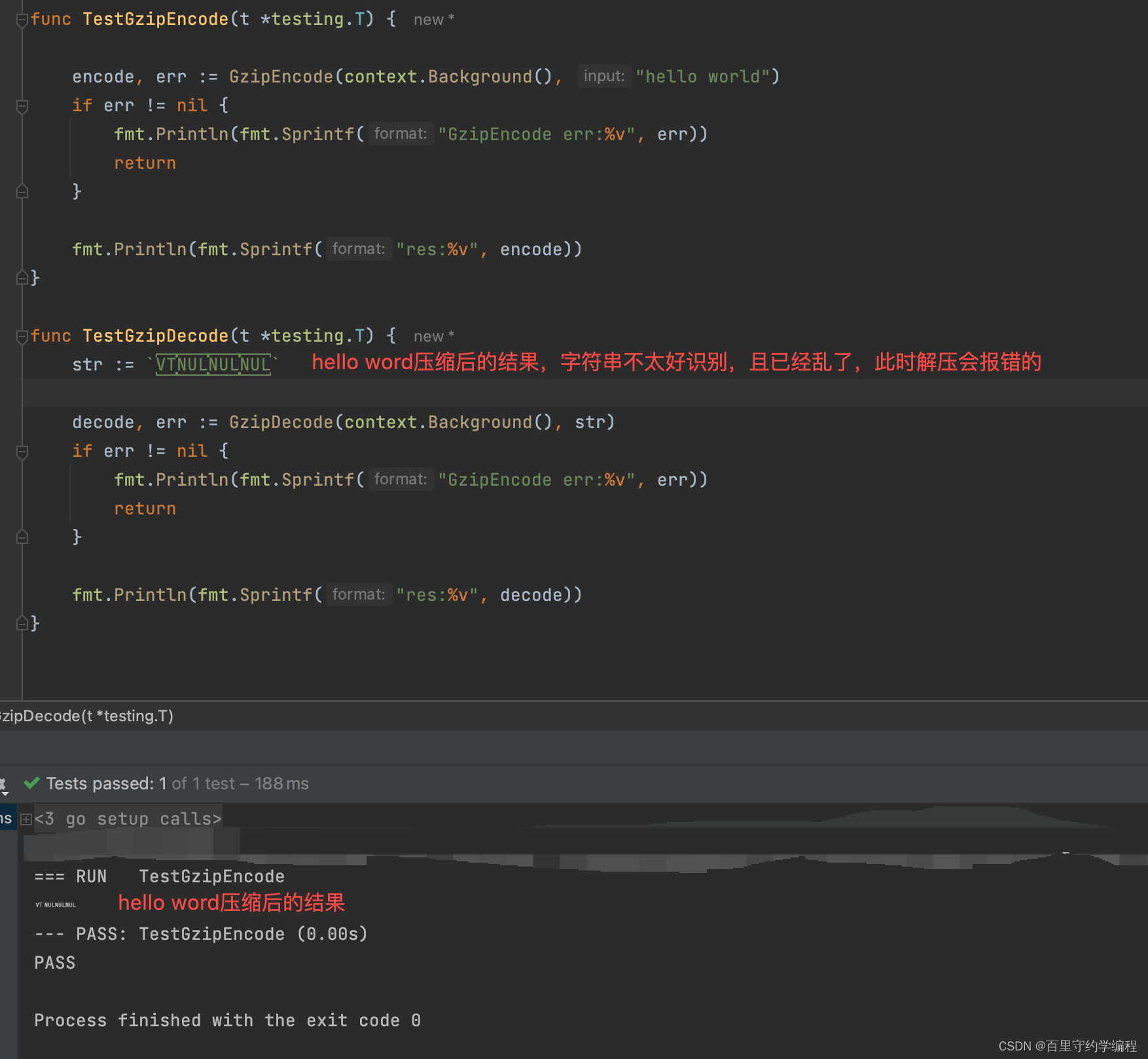
可以看到压缩后字符串确实很小了,但是美观,且复制后对其解压会报错GzipEncode err:unexpected EOF,所以还是把base64编码用上吧!!
)

)
)






![[学习笔记]刘知远团队大模型技术与交叉应用L3-Transformer_and_PLMs](http://pic.xiahunao.cn/[学习笔记]刘知远团队大模型技术与交叉应用L3-Transformer_and_PLMs)








