Wavelet-Guided Acceleration of Text Inversion in Diffusion-Based Image Editing
公众号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)
目录
0. 摘要
2. 初步分析
2.1. 空文本优化分析
2.2. 频率分析
3. 方法
3.1 模型架构
3.2. 损失函数
4. 实验
0. 摘要
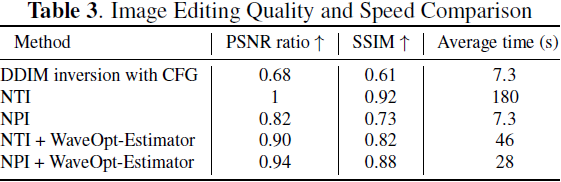
在图像编辑领域,空文本反演 (Null-text Inversion,NTI) 能够在 DDIM 采样过程中优化空嵌入,实现细粒度编辑同时保留原始图像的结构。然而,NTI 过程耗时较长,每张图像超过两分钟。为解决这个问题,我们引入了一种创新方法,该方法在加速图像编辑过程的同时保持了 NTI 的原则。我们提出了 WaveOpt-Estimator,它基于频率特征确定文本优化的端点。通过利用小波变换分析来识别图像的频率特征,我们可以在 DDIM 采样过程的特定时间步限制文本优化。通过采用负提示反演 (Negative-Prompt Inversion,NPI) 的概念,表示原始图像的目标提示作为优化的初始文本值。这种方法在保持与 NTI 可比的性能的同时,相对于 NTI 方法将平均编辑时间减少了 80% 以上。我们的方法为基于扩散模型的高效、高质量的图像编辑提供了一种有前景的途径。
2. 初步分析
2.1. 空文本优化分析
在本节中,我们研究了不是在所有时间步上都进行 Null-Text Inversion (NTI) ,而是仅在特定的时间步上进行时对性能的影响。为了铺平我们分析的基础,我们首先介绍了与基本 DDIM 反演过程和空文本优化相关的一些术语。让 x_ori 代表原始图像。我们用 T 表示 DDIM 反演和采样的总时间步数。

在进行图像编辑时,原始图像 x_ori 经过编码器 E 转变为潜在变量 z_0(1),并与表示原始图像的源提示 p_src 一起用于 DDIM 反演过程,生成带噪声的潜在变量 z_T(2)。然后,UNet 接收 z_T、源提示 p_src、编辑提示 p_edit 以及预优化的空文本嵌入值 {ϕ_t}^T_(t=1) 进行去噪,生成一个修改后的潜在变量 ˆz_0,该变量保留了原始图像的特征并融入了由 p_edit 指定的修改(3)。修改后的 ˆz_0 然后经过解码器 D 生成图像,将原始结构与预期的编辑结合在一起(4)。
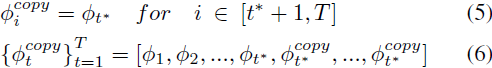
我们引入了概念 {ϕ^copy_t}^T_(t=1)(6),这是通过在特定时间步 t* 之前应用 NTI 并随后复制最后一个空文本 ϕ_(t*) 扩展剩余时间步数达到 T 而获得的一系列空文本嵌入向量(5)。

将潜在变量 ˆz*_0(7)通过解码器 D,得到的重构图像被标记为 x^(t*)_recon(8)。在这里,用于生成 x^(t*)_recon 的潜在变量 ˆz*_0 是通过使用 {ϕ^copy_t}^T_(t=1) 进行 DDIM 采样得到的,其中 NPI 仅包含到特定的时间步 t*。在实践中,我们将 T 设置为 50,并对 t* 进行实验,范围从 0 到 T,以步长为 5 递增。在不同 t* 下获得的 x^(t*)_recon 集合被标记为 X_recon(9),可在图 1 中观察到。为了评估重构的 x^(t*)_recon 与原始图像 x_ori 之间的相似性,使用 PSNR 指标,结果显示在图 2 中。发现随着时间步的推移,每个图像的 PSNR 值收敛方式不同,并且在某个时间步之后,PSNR 的增益变得较小。


例如,在图 2 中,自行车图像在第 25 个时间步达到了 24.9 的 PSNR 值,占其在第 50 个时间步的 PSNR 值(25.65)的 97.4%。另一方面,咖啡图像在第 35 个时间步达到了 33.7 的 PSNR 值,占其在第 50 个时间步的 PSNR 值(34.36)的 97.1%。在这种情况下,特定时间步 t* 的 PSNR 与第 50 个时间步 T 的 PSNR 之比被定义为 PSNR 比率。
经验上观察到,当 PSNR 比率超过 0.9 时,原始图像与重构图像之间的差异可以忽略不计。我们将时间步 t* 定义为 PSNR 比率首次超过 0.9 的端点。本研究假设端点由独特的图像特征决定,从而成为下一节进一步研究的动机。
2.2. 频率分析
为了探索基于图像固有特性的 PSNR 比率收敛速度,我们使用离散小波变换(Discrete
Wavelet Transform,DWT)。DWT 将图像 x 分解为频率子带 x_LL、x_LH、x_HL、x_HH,使用一组低通和高通滤波器。为了更精确地分析高频组分,我们计算了 x_LH、x_HL 和 x_HH 子带的平均值,得到 x_SUM。此外,我们使用自适应直方图均衡化增强 x_SUM,以突显高频细节。我们将重点放在 x_LL、x_SUM 子带上进行分析,并计算它们的能量,即信号的平方(10-11)。

这些结果在图 3 和表 1 中呈现,其中 t* 表示端点。
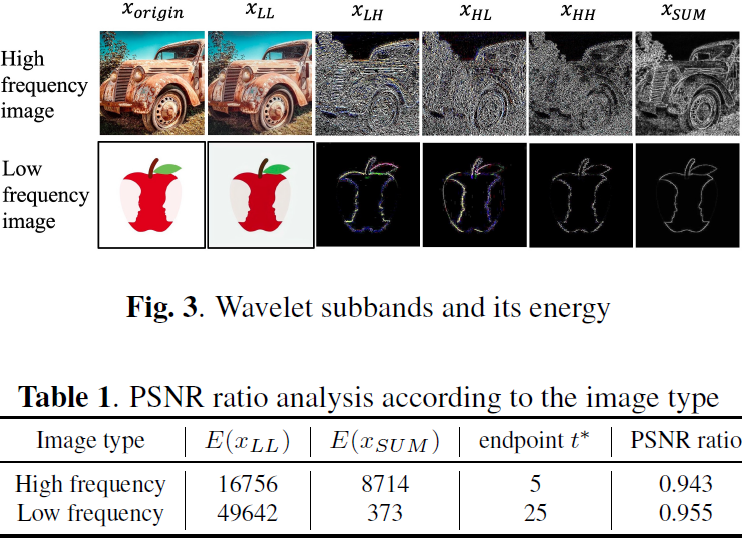
实验结果显示,具有显著高频成分的图像往往在 x_LL 中表现出较低的能量,在 x_SUM 中表现出较高的能量。相反,富含低频成分的图像在 x_LL 中表现出较高的能量,在 x_SUM 中表现出较低的能量。值得注意的是,我们发现在 x_LL 中能量较低且在 x_SUM 中能量较高的图像往往在 DDIM 采样的较低时间步骤下达到端点 t*。这一观察表明,UNet 的 DDIM 采样需要更多时间来形成低频元素,而形成高频元素相对较快,从而影响图像重建的速度。这一发现表明图像的频率组分影响了在 DDIM 采样期间的收敛速度以及文本优化所需的时间。
3. 方法
在第 2 节中提出的分析中,观察到图像固有频率组分与端点 t* 之间存在依赖关系。受到这些发现的启发,我们提出了 WaveOpt-Estimator,这是一个基于图像频率特征估计端点 t* 的模型。利用预测的端点 t*,生成 {ϕ^copy_t}^T_(t=1),与在 NTI 中在所有时间步上执行优化相比,显著减少了优化所需的时间。此外,我们不再使用空文本作为初始值,而是利用 NPI 的优势将初始文本值设置为描述原始图像的目标提示。

3.1 模型架构
WaveOpt-Estimator 包括用于处理原始图像和小波子带的编码器,以及交叉注意力和自注意力模块。通过离散小波变换(DWT),x_ori 被分解成 x_LL、x_SUM 子带。随后,通过图像编码器 E_I(13)对 x_ori 进行编码,通过小波编码器 E_WL 和 E_WS(14)分别对 x_LL 和 x_SUM 进行编码。ResNet-50 用于图像和小波编码器。这些编码特征被串联起来形成统一的视觉特征 f_visual(15)。

为了训练视觉特征和 DDIM 潜在变量之间的多模态关系,采用了交叉注意力。在交叉注意力模块中,视觉特征 f_visual 充当查询(Query),而在 DDIM 反演过程中存储的 z_t 同时充当键(Key)和值(Value)。对于给定的输入图像 x_ori,z_t 在 t = 0 到 t = t* 共存在 t* 次。在视觉特征和 z_t 之间进行交叉注意力(CA)后,得到的 Q* 作为后续自注意力的输入。经过两次自注意力后,输出张量经过一个全连接层进行回归。回归值表示从当前时间步 t 到终点 t* 的持续时间,即应该限制优化的时间。

3.2. 损失函数
WaveOpt-Estimator 的设计目标是使用原始图像 x_ori、其频率组分 x_LL 和 x_SUM 以及 DDIM 潜在变量 z_t 来预测端点 t*。为实现这一目标,在预测的端点 t*_pred 和实际端点 t*_gt 之间应用 L2 损失(16)。此外,基于 PSNR 的铰链损失在 x_ori 和从 z_t 派生的图像之间使用(17)。我们定义 PSNR_t 为 x_ori 和从 z_t 重建的图像之间的 PSNR,而 PSNR*_t 为从端点 z_t 重建的图像的 PSNR。该损失捕捉了特定时间步 t 和端点 t* 之间 PSNR 的差异。通过对这两个损失项应用权重因子 α1 和 α2 进行实验(18),并将两个因子都设定为 0.5。
4. 实验












)



:从零开始部署书生·浦语2-20B大模型,使用fastchat和webui部署测试,autodl申请2张显卡,占用显存40G可以运行)
(数据驱动测试))



