一,场景概述:
在高并发的环境下,比如淘宝,京东不定时的促销活动,大量的用户访问会导致数据库的性能下降,进而有可能数据库宕机从而不能产生正常的服务,一般一个系统最大的性能瓶颈,就是数据库的io操作,如果发生大量的io那么他的问题也会随之而来。从数据库入手也是调优性价比最高的切入点。因此需要对我们的程序进行优化.一般采取两种方案:
①从数据库自身出发:优化sql,通过分析sql給sql建立索引,优化查询效率
②尽量避免直接查询数据库:使用缓存来实现
此文主要以缓存来解决高并发的效率问题来阐述,工欲善其事必先利其器,我们从原理和实战两方面入手来完成优化
二,原理
1.缓存的基本使用流程

如图所示:用户发起请求到达服务器,处理业务的同时,如果涉及到持久层,会经历以下几个步骤:
①首先到达缓存查询,查看缓存是否存在
②如果存在,则直接返回
③如果不存在,则前往数据库查询
④将DB查询到的结果返回给客户端,同时将查询到的结果放入缓存一份
⑤再次查询,直接从缓存里面即可拿到对应的数据.
但是在高并发的情况下,大量的请求过来又会导致一系列问题的产生,因此针对不同的问题,我们又有不同的解决方案,详情如下:
2.缓存产生的问题以及解决方案
在高并发条件下,无数的请求并发会产生以下问题:
①缓存雪崩
②缓存穿透
③缓存击穿
............
2.1缓存雪崩

我们可以简单的理解为:由于原有缓存失效,新缓存未到期间(例如:我们设置缓存时采用了相同的过期时间,在同一时刻出现大面积的缓存过期),所有原本应该访问缓存的请求都去查询数据库了,而对数据库CPU和内存造成巨大压力,严重的会造成数据库宕机。从而形成一系列连锁反应,造成整个系统崩溃。
解决方案:
①加锁
②对于缓存的key随机的设置过期时间,保证让缓存不在同一时间失效
③采用队列方式保证来保证不会有大量的线程对数据库一次性进行读写,从而避免失效时大量的并发请求落到底层存储系统上
2.2缓存击穿

如图所示:缓存穿透指的是对于某个热点key,在高峰期大量的并发请求过来的时候,该热点key正好过期,导致所有的请求一瞬间打在了DB上,从而导致DB宕机或性能下降.
解决方案:
①加锁
②队列
2.3缓存穿透
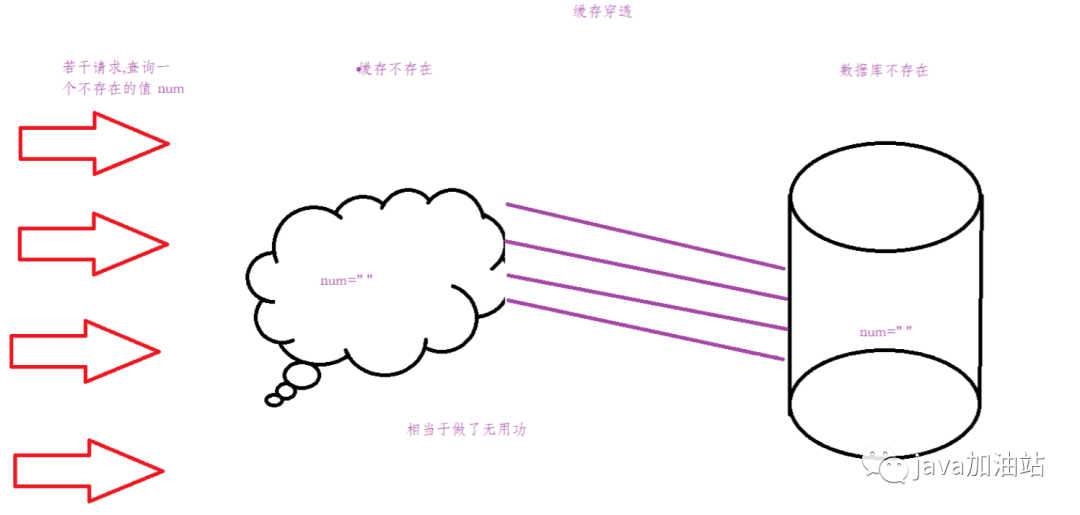
如图所示:缓存穿透指的是,查询一个不存在的key,缓存为空,同时数据库也为空,相当于做了无用功,意义不大,如果被别人利用,大量的请求null,将会对数据库的性能产生巨大的影响
解决办法:
①缓存空值,并给空值key设置小于5分的过期时间
②采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。
2.4缓存预热
缓存预热这个应该是一个比较常见的概念,相信很多小伙伴都应该可以很容易的理解,缓存预热就是系统上线后,将相关的缓存数据直接加载到缓存系统。这样就可以避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题!用户直接查询事先被预热的缓存数据!
解决办法:
①直接写个缓存刷新页面,上线时手工操作下;
②数据量不大,可以在项目启动的时候自动进行加载;
③定时刷新缓存;
2.5缓存更新
除了缓存服务器自带的缓存失效策略之外(Redis默认的有6种策略可供选择),我们还可以根据具体的业务需求进行自定义的缓存淘汰,常见的策略有两种:
①定时去清理过期的缓存;
②当有用户请求过来时,再判断这个请求所用到的缓存是否过期,过期的话就去底层系统得到新数据并更新缓存。
两者各有优劣,第一种的缺点是维护大量缓存的key是比较麻烦的,第二种的缺点就是每次用户请求过来都要判断缓存失效,逻辑相对比较复杂!具体用哪种方案,可以根据自己的应用场景来权衡。
2.6、缓存降级
当访问量剧增、服务出现问题(如响应时间慢或不响应)或非核心服务影响到核心流程的性能时,仍然需要保证服务还是可用的,即使是有损服务。系统可以根据一些关键数据进行自动降级,也可以配置开关实现人工降级。降级的最终目的是保证核心服务可用,即使是有损的。而且有些服务是无法降级的(如加入购物车、结算)。
总结:针对于上面提到的问题不同的场景有不同的解决方案,一般情况下,我们选择加锁的方式来完成对缓存产生问题的优化,锁的选择有多种:
①本地锁(不能解决集群下产生的问题)
②分布式锁(redis,zookeper,数据库锁)
以下将采用加锁的方式分别阐述解决缓存带来的问题
三,准备工作
3.1创建springboot工程,导入redis的依赖
springboot版本选择2.3.6.RELEASE
<!-- redis --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></dependency><!-- spring2.X集成redis所需common-pool2--><dependency><groupId>org.apache.commons</groupId><artifactId>commons-pool2</artifactId><version>2.6.0</version></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency>
3.2添加配置文件并创建启动类(略)
redis:host: 192.168.17.166port: 6379database: 0timeout: 1800000password:lettuce:pool:max-active: 20 #最大连接数max-wait: -1 #最大阻塞等待时间(负数表示没限制)max-idle: 5 #最大空闲min-idle: 0 #最小空闲
3.3配置类
@Configuration
@EnableCaching
public class RedisConfig {@Beanpublic RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {RedisTemplate<Object, Object> redisTemplate = new RedisTemplate<>();redisTemplate.setConnectionFactory(redisConnectionFactory);Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);ObjectMapper objectMapper = new ObjectMapper();objectMapper.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);objectMapper.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);jackson2JsonRedisSerializer.setObjectMapper(objectMapper);// 序列号key valueredisTemplate.setKeySerializer(new StringRedisSerializer());redisTemplate.setValueSerializer(jackson2JsonRedisSerializer);redisTemplate.setHashKeySerializer(new StringRedisSerializer());redisTemplate.setHashValueSerializer(jackson2JsonRedisSerializer);redisTemplate.afterPropertiesSet();return redisTemplate;}}四,实战模拟
4.1不加锁带来的问题
num的值为0,提前在redis客户端里面存储
创建controller和service
启动测试:

单独的测试,每次发请求都没有问题,但是如果面对大量的请求呢,又会发生什么问题呢?
使用ab工具进行压测
在linux里面安装yum -y install httpd-tools
测试5000个请求,每次请求100个会是什么情况呢?
预想值:5000

实际值:148
为什么呢?
原因是多个线程抢占同一资源,会有不同的线程在同一时刻抢占到同一个值,来回的切换修改,导致了,数据不一致的问题
如何解决:上锁,加入synchronized关键字,再次进行测试
4.2本地锁
synchonized又叫同步锁,它通过持有同步监视器对象来判断是否自动上锁还是解锁.
①实例方法:同步监视器是this
②静态方法:同步监视器是类.class
③同步代码块:同步监视器是括号里面的内容
@Overridepublic synchronized void testRedisRefresh() {//查询缓存是否存在(预先客户端设置num的值为0)String value = redisTemplate.opsForValue().get("num");//校验if(StringUtils.isEmpty(value)){//不存在(查询数据库,并且将数据存入redis)return;}//存在将num转换为intint num = Integer.parseInt(value);//存入缓存redisTemplate.opsForValue().set("num",String.valueOf(++num));}

可以看到,此时的结果正确,这是因为我们使用了synchronized给方法上了同步锁,那么我的方法每次只处理一个线程的请求,其余方法只能在外面等着,当我的一个线程处理完,自动释放锁之后,其他方法才会依次进入,这样就可以保证原子性.
但是,为了减少服务器的性能,会将服务器搭建集群,那么本地锁还能够适用吗,我们拭目以待.
搭建同样的8206,8216,8226三个微服务,使用gatway网关统一访问测试:

可以看到数据再次出现了不一致,导致出现这种情况的原因在于我们的三个微服务有三把锁,三把锁同时工作,
每个线程占到的锁不一样,因此会导致数据不一致的情况.
本地锁只能锁住同一工程内的资源,在分布式系统里面都存在局限性。
解决这个问题的办法在于给集群的程序设置一把锁,此时需要分布式锁。
4.3分布式锁
4.3.1分布式锁的解决方案
随着业务发展的需要,原单体单机部署的系统被演化成分布式集群系统后,由于分布式系统多线程、多进程并且分布在不同机器上,这将使原单机部署情况下的并发控制锁策略失效,单纯的Java API并不能提供分布式锁的能力。为了解决这个问题就需要一种跨JVM的互斥机制来控制共享资源的访问,这就是分布式锁要解决的问题!
分布式锁主流的实现方案:
-
基于数据库实现分布式锁
-
基于缓存(Redis等)
-
基于Zookeeper
每一种分布式锁解决方案都有各自的优缺点:
-
性能:redis最高
-
可靠性:zookeeper最高
这里,我们基于redis实现分布式锁。
4.3.2redis实现分布式锁
在redis中可以通过setnx来对一个key上锁,通过删除这个key来解锁,因此基于redis的这个特性我们可以将它做成全局分布式锁
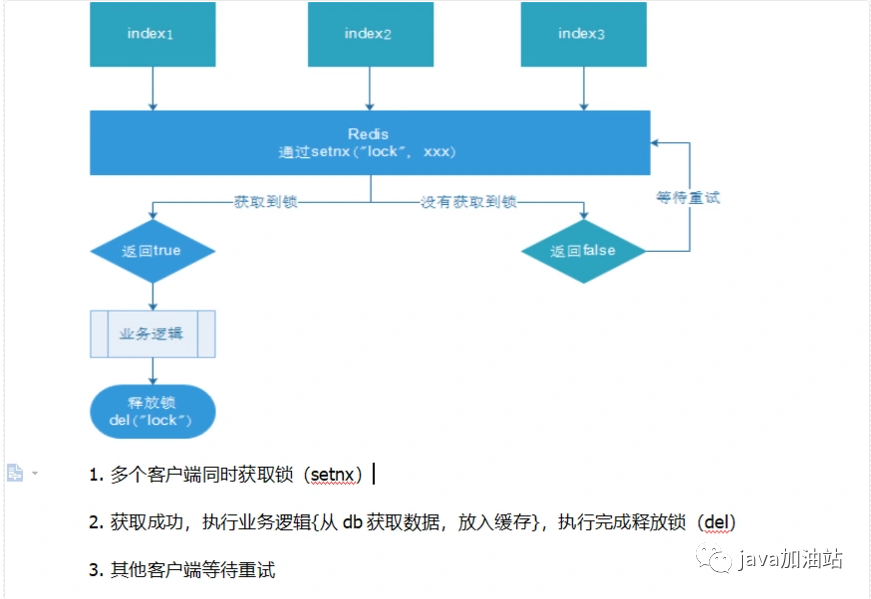
(1)版本一
修改service代码如下所示
@Overridepublic void testRedisRefresh() {//锁定keyBoolean absent = redisTemplate.opsForValue().setIfAbsent("lock", "111");if (absent){//处理业务//查询缓存是否存在(预先客户端设置num的值为0)String value = redisTemplate.opsForValue().get("num");//校验if(StringUtils.isEmpty(value)){//不存在(查询数据库,并且将数据存入redis)return;}//存在将num转换为intint num = Integer.parseInt(value);//存入缓存redisTemplate.opsForValue().set("num",String.valueOf(++num));}else{//未拿到锁等待try {Thread.sleep(100);} catch (InterruptedException e) {e.printStackTrace();}//自旋this.testRedisRefresh();}}
再次启动三个微服务测试
通过测试发现结果为5000,与预想的结果值一样
再次分析:

(2)版本二,优化
基于2.6.1版本之后的特性我们在使用java执行setnx的时候可以给key设置一个过期时间
@Overridepublic void testRedisRefresh() {//锁定keyBoolean absent = redisTemplate.opsForValue().setIfAbsent("lock", "111",3L,TimeUnit.SECONDS);if (absent){//处理业务//查询缓存是否存在(预先客户端设置num的值为0)String value = redisTemplate.opsForValue().get("num");//校验if(StringUtils.isEmpty(value)){//不存在(查询数据库,并且将数据存入redis)return;}//存在将num转换为intint num = Integer.parseInt(value);//存入缓存redisTemplate.opsForValue().set("num",String.valueOf(++num));//释放锁redisTemplate.delete("lock");}else{//未拿到锁等待try {Thread.sleep(100);//自旋this.testRedisRefresh();} catch (InterruptedException e) {e.printStackTrace();}}}
测试发现依然没问题,再次分析
问题:可能会释放其他服务器的锁。
场景:如果业务逻辑的执行时间是7s。执行流程如下
-
index1业务逻辑没执行完,3秒后锁被自动释放。
-
index2获取到锁,执行业务逻辑,3秒后锁被自动释放。
-
index3获取到锁,执行业务逻辑
-
index1业务逻辑执行完成,开始调用del释放锁,这时释放的是index3的锁, 导致index3的业务只执行1s就被别人释放。
最终等于没锁的情况。
解决:setnx获取锁时,设置一个指定的唯一值(例如:uuid);释放前获取这个值,判断是否自己的锁
(3)版本三优化(uuid防止误删)
@Overridepublic void testRedisRefresh() {//设置唯一表示,防止误删除String uuid = UUID.randomUUID().toString().replace("-", "");//锁定keyBoolean absent = redisTemplate.opsForValue().setIfAbsent("lock", uuid,3L,TimeUnit.SECONDS);if (absent){//处理业务//查询缓存是否存在(预先客户端设置num的值为0)String value = redisTemplate.opsForValue().get("num");//校验if(StringUtils.isEmpty(value)){//不存在(查询数据库,并且将数据存入redis)return;}//存在将num转换为intint num = Integer.parseInt(value);//存入缓存redisTemplate.opsForValue().set("num",String.valueOf(++num));//判断是否是自己的锁,防误删if (uuid.equals(redisTemplate.opsForValue().get("lock"))){//释放锁redisTemplate.delete("lock");}}else{//未拿到锁等待try {Thread.sleep(100);//自旋this.testRedisRefresh();} catch (InterruptedException e) {e.printStackTrace();}}}
由于删除操作不具有原子性因此需要再次优化
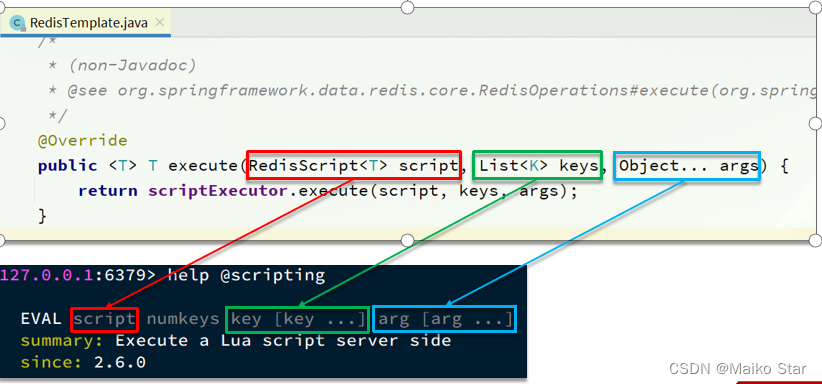
(4)终极版本(使用lua脚本)
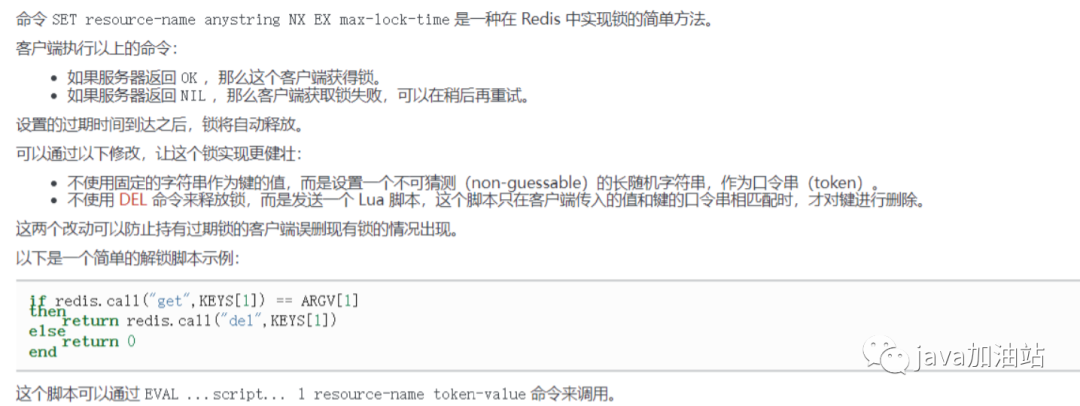
代码实现:
@Overridepublic void testRedisRefresh() {//①上锁//设置唯一表示,防止误删除String uuid = UUID.randomUUID().toString().replace("-", "");//锁定keyBoolean absent = redisTemplate.opsForValue().setIfAbsent("lock", uuid,3L,TimeUnit.SECONDS);//②业务if (absent){//处理业务//查询缓存是否存在(预先客户端设置num的值为0)String value = redisTemplate.opsForValue().get("num");//校验if(StringUtils.isEmpty(value)){//不存在(查询数据库,并且将数据存入redis)return;}//存在将num转换为intint num = Integer.parseInt(value);//存入缓存redisTemplate.opsForValue().set("num",String.valueOf(++num));//③解锁//lua脚本String script="if redis.call(\"get\",KEYS[1]) == ARGV[1]\n" +"then\n" +" return redis.call(\"del\",KEYS[1])\n" +"else\n" +" return 0\n" +"end";//创建对象DefaultRedisScript<Long> redisScript = new DefaultRedisScript<>();redisScript.setScriptText(script);redisScript.setResultType(Long.class);//执行删除redisTemplate.execute(redisScript,Arrays.asList("lock",uuid));//④自旋}else{//未拿到锁等待try {Thread.sleep(100);//自旋this.testRedisRefresh();} catch (InterruptedException e) {e.printStackTrace();}}
4.3.3redision实现分布式锁
(1)概述:Redisson是一个在Redis的基础上实现的Java驻内存数据网格(In-Memory Data Grid)。它不仅提供了一系列的分布式的Java常用对象,还提供了许多分布式服务。其中包括(BitSet, Set, Multimap, SortedSet, Map, List, Queue, BlockingQueue, Deque, BlockingDeque, Semaphore, Lock, AtomicLong, CountDownLatch, Publish / Subscribe, Bloom filter, Remote service, Spring cache, Executor service, Live Object service, Scheduler service) Redisson提供了使用Redis的最简单和最便捷的方法。Redisson的宗旨是促进使用者对Redis的关注分离(Separation of Concern),从而让使用者能够将精力更集中地放在处理业务逻辑上。

(2)基本使用
导入依赖
1.导入依赖 service-util
<!-- redisson --><dependency><groupId>org.redisson</groupId><artifactId>redisson</artifactId><version>3.15.3</version></dependency>
配置redission,加载redis连接数据
@Data@Configuration@ConfigurationProperties("spring.redis")public class RedissonConfig {private String host;private String password;private String port;private int timeout = 3000;private static String ADDRESS_PREFIX = "redis://";/*** 自动装配*/@BeanRedissonClient redissonSingle() {Config config = new Config();if(StringUtils.isEmpty(host)){throw new RuntimeException("host is empty");}SingleServerConfig serverConfig = config.useSingleServer().setAddress(ADDRESS_PREFIX + this.host + ":" + port).setTimeout(this.timeout);if(!StringUtils.isEmpty(this.password)) {serverConfig.setPassword(this.password);}return Redisson.create(config);}}
(3)实现
@Overridepublic void testRedisRefresh() {//上锁String skuId="31";String lockKey="lock:"+skuId;//获取锁RLock lock = redissonClient.getLock(lockKey);lock.lock();//处理业务//查询缓存是否存在(预先客户端设置num的值为0)String value = redisTemplate.opsForValue().get("num");//校验if(StringUtils.isEmpty(value)){//不存在(查询数据库,并且将数据存入redis)return;}//存在将num转换为intint num = Integer.parseInt(value);// //存入缓存redisTemplate.opsForValue().set("num",String.valueOf(++num));//解锁lock.unlock();}
五,总结
经过分析发现分布式锁的实现在一定程度上还是会存在一系列的问题,通过这些问题的解决可以在很大程度的避免数据不一致的情况,关于分布式锁的实现可以抽取为模板,有业务场景需要的时候二次修改复用即可.
5.1redis实现分布式锁四部曲
①上锁
②判断true处理业务
③解锁(lua脚本)
④自旋
@Overridepublic void testRedisRefresh() {//①上锁//设置唯一表示,防止误删除String uuid = UUID.randomUUID().toString().replace("-", "");//锁定keyBoolean absent = redisTemplate.opsForValue().setIfAbsent("lock", uuid,3L,TimeUnit.SECONDS);//②业务if (absent){//处理业务//查询缓存是否存在(预先客户端设置num的值为0)String value = redisTemplate.opsForValue().get("num");//校验if(StringUtils.isEmpty(value)){//不存在(查询数据库,并且将数据存入redis)return;}//存在将num转换为intint num = Integer.parseInt(value);//存入缓存redisTemplate.opsForValue().set("num",String.valueOf(++num));//③解锁//lua脚本String script="if redis.call(\"get\",KEYS[1]) == ARGV[1]\n" +"then\n" +" return redis.call(\"del\",KEYS[1])\n" +"else\n" +" return 0\n" +"end";//创建对象DefaultRedisScript<Long> redisScript = new DefaultRedisScript<>();redisScript.setScriptText(script);redisScript.setResultType(Long.class);//执行删除redisTemplate.execute(redisScript,Arrays.asList("lock",uuid));//④自旋}else{//未拿到锁等待try {Thread.sleep(100);//自旋this.testRedisRefresh();} catch (InterruptedException e) {e.printStackTrace();}}
5.redission实现分布式锁三部曲
①上锁
②业务逻辑
③解锁
@Overridepublic void testRedisRefresh() {//上锁String skuId="31";String lockKey="lock:"+skuId;//获取锁RLock lock = redissonClient.getLock(lockKey);lock.lock();//处理业务//查询缓存是否存在(预先客户端设置num的值为0)String value = redisTemplate.opsForValue().get("num");//校验if(StringUtils.isEmpty(value)){//不存在(查询数据库,并且将数据存入redis)return;}//存在将num转换为intint num = Integer.parseInt(value);// //存入缓存redisTemplate.opsForValue().set("num",String.valueOf(++num));//解锁lock.unlock();}