
👀日报&周刊合集 | 🎡生产力工具与行业应用大全 | 🧡 点赞关注评论拜托啦!

🉑 GenAI 是美国「2024 年裁员潮」罪魁祸首吗?来看几组数据
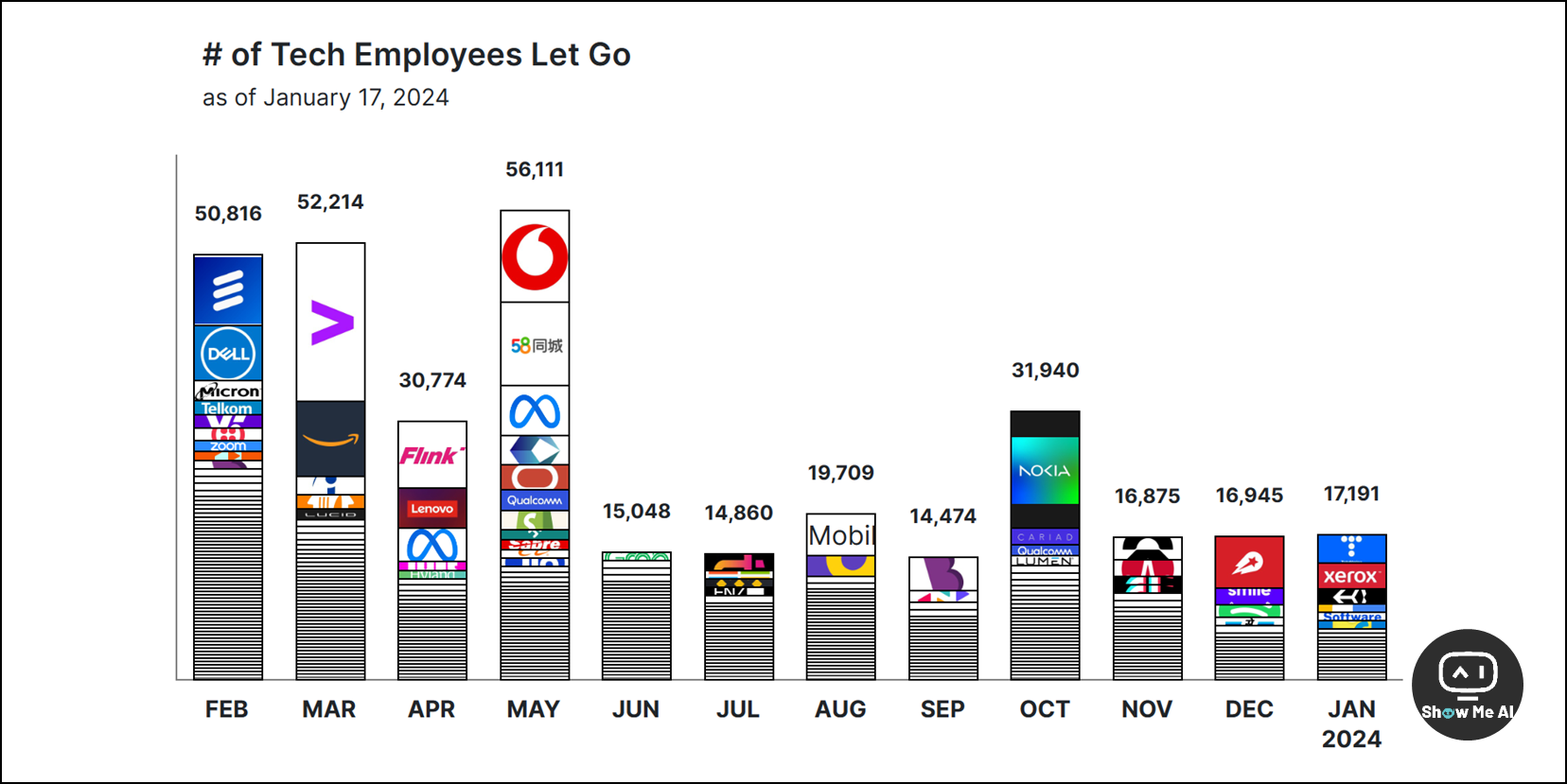
https://www.trueup.io/layoffs
补充一份背景:👆 上方链接是 TrueUp 网站关于科技行业裁员、招聘、股票等信息的汇总页面,其中「The Tech Layoff Tracker」实时密切追踪着全球科技公司的裁员信息,覆盖大型科技公司、科技独角兽和初创公司等
最近美国科技公司出现了新一轮的「裁员潮」。据 TrueUp 汇总,2024年到目前为止,科技公司的裁员信息已经有92条之多,影响人数多达 17,191 (平均每天裁员 1,011) 。2023年这些数据是,科技公司裁员信息共 1,996条,影响人数 428,384 (平均每天裁员 1,174) 。
进入生成式AI浪潮的第二年,科技公司的每轮裁员都跟 AI 相关吗?下拉网页可以看到每条裁员的详细信息,根据统计信息来看,只有6条裁员消息明确说明与AI有关:
2024年1月16日
裁员数百人
谷歌广告部门转向由AI驱动的销售模式
Apple
2024年1月13日
裁员 121 人
苹果在重组中关闭了位于圣地亚哥的121人AI团队
InMobi | 移动广告
2024年1月11日
裁员 125 人 (占公司人数 5%)
InMobi 将重心向AI转移,裁员风险继续增加
Humane | 消费硬件
2024年1月9日
裁员 10 人 (占公司人数 4%)
Humane 在发布 AI Pin 之前进行了一轮裁员
BenchSci | 药物研发
2024年1月8日
裁员 70 人 (占公司人数 17%)
BenchSci 因为生成式AI和经济状况双重因素进行裁员
Duolingo | 语言学习
2024年1月8日
削减 10% 承包商
多邻国转为使用AI翻译和创建内容,少量人工辅助进行审核

https://www.imf.org/en/Blogs/Articles/2024/01/14/ai-will-transform-the-global-economy-lets-make-sure-it-benefits-humanity
AI会让今年的就业形势雪上加霜吗? 👆 上图左,1月14日,国际货币基金组织 IMF 在发布的一项研究成果显示,AI对发达国家、新兴市场、低收入国家的工作岗位影响度分别为 60%、40%、25%;也就是说,在发达经济体中,约有 60% 的工作岗位会受到AI的影响。
好消息是,这其中有一半的工作可能受益于AI来提升生产效率;坏消息是,另一半可能会裁员甚至直接消失 😭
👆 上图右,普华永道在本周达沃斯经济论坛的一项 CEO 调研显示,预计受生成式AI影响,今年公司的员工人数将减少 5% 以上,其中媒体/娱乐、银行、保险、物流等行业首当其中 (高清图见社群)。
👀 中国的大模型人才在哪里?这份研究报告给出了答案

研究背景和数据来源:在国家知识产权局和全球科学引文数据库中,以北京、上海、深圳、杭州这四座大模型落地项目与机构最集聚的城市为样本,搜集并清洗出了近三年来与大模型相关的3.68万篇高水准学术论文和3万余项专利成果
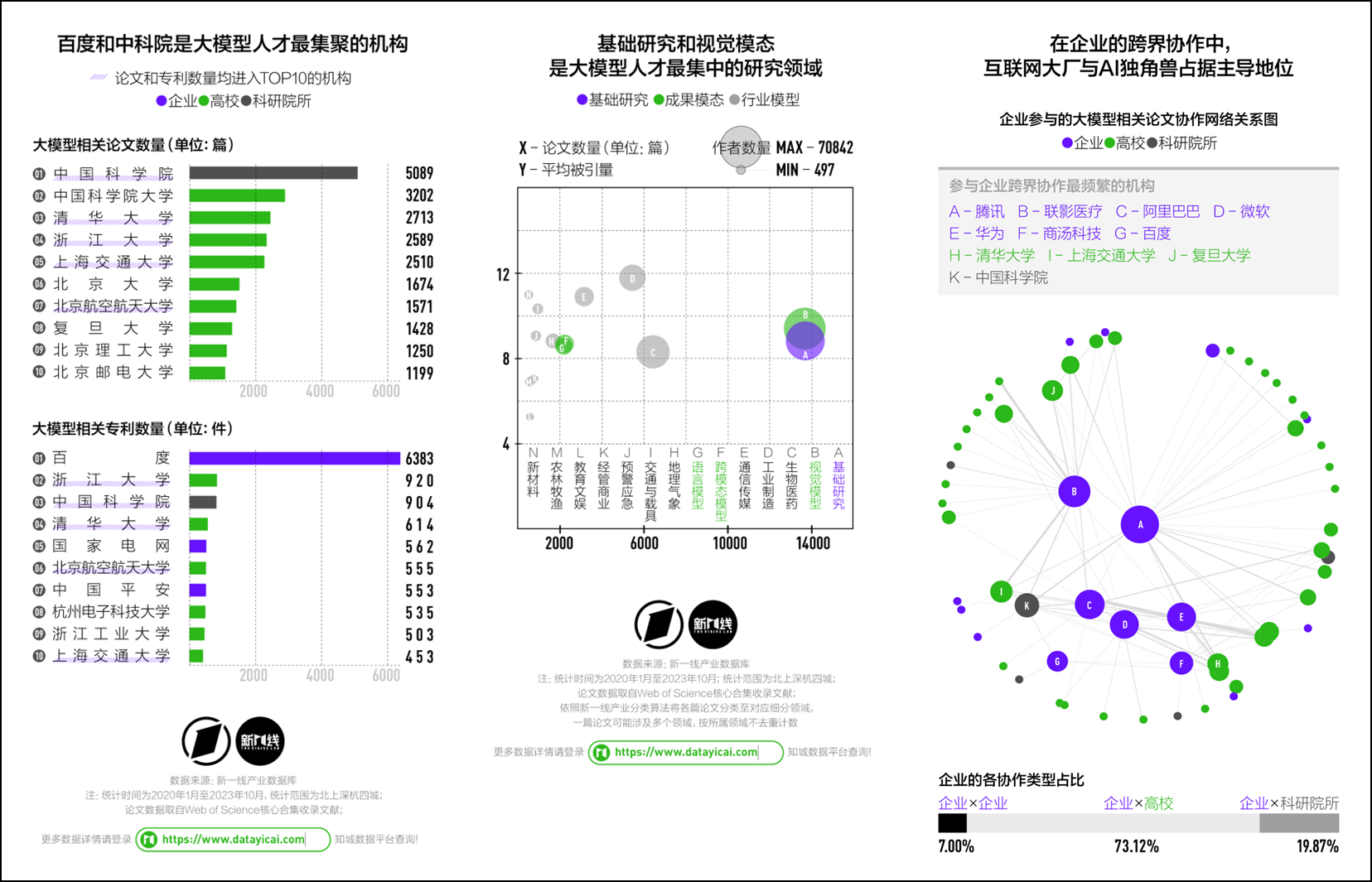
以机构为单位,中国科学院、中国科学院大学和清华大学分别是大模型相关论文数量最多的三家机构
在专利领域,百度以6000余项专利的绝对领先优势超越了所有高校与科研院所排在第一位;国家电网、中国平安等大型企业也凭借自身的行业地位积极布局创新业务
尽管行业应用遍地开花,大模型的基础研究以及聚焦视觉、语言和跨模态模型训练的成果模态研究等通用型技术框架研发,实际上仍是高层次大模型人才密度最高的科研产出领域
大模型创业热潮的推动,出现了许多来自高校、科研院所背景的明星学者:除了腾讯、阿里、华为、百度等互联网企业,联影医疗、商汤科技等人工智能领域的头部企业都已经与各类高校建立了紧密的科研协作关系

在高校、科研院所、企业三方共同协作完成的研究关键词中,深度学习依然是三方协同攻关频率最高的领域;此外,在微观研究主题上,遥感、机器人、气象学、蛋白质等各个垂直领域的算法获得了更多的关注
从产出成果的应用领域来看,京沪深杭目前集聚的大模型人才类型已表现出了各自的特色,这与各城市拥有的高校与科研资源禀赋往往密切相关
京沪深杭这四座城市的论文跨国协作,目前已辐射到全球126个国家和地区,与美国、英国、澳大利亚和新加坡这四个国家的协作最为紧密 ⋙ 查看详情

👀 2023年最受欢迎的 GenAI 工具排行榜,一图览尽 300+ 常用工具

https://view.genial.ly/658ce60a6f93b40014d35b2d/interactive-content-ai-tools-ranking-for-2024
GenAI 是生成式人工智能 (Generative AI) 的英文简写,国内更常使用的词是 AIGC (AI Generated Content,人工智能生成内容)
这是一份GenAI 最受欢迎 & 最常使用的工具清单,根据网站访问数据排名,收录整理了 300+ AI工具。而且!访问 👆 上方网站,将鼠标悬停在工具 Logo 上方,就会出现对应工具的详细介绍哦!!日报整理了这份清单的工具分类信息,看看有你感兴趣的领域没 ( ̄︶ ̄*))
Dev tools / 开发工具
Chat with document / 文档聊天
Workflow / 工作流
Summarize / 总结
Prompts / 提示
Video Generation / 视频生成
Social Media / 社交媒体
SEO / 搜索引擎优化
Voice / 语音
Presentations / 演示文稿
News / 新闻
Logo / 标志
Legal Assistant / 法律助手
Image Edit / 图像编辑
Analytics / 分析
Image Generation / 图像生成
Design / 设计
Customer Support / 客户支持
Others / 其他
Chat / 聊天
Podcasting / 播客
Model Generation / 模型生成
Productivity / 生产力
Video Editing & + / 视频编辑及其他
ChatBot / 聊天机器人
Text To Speech / 文本转语音
Website building / 网站构建
Sales & Marketing / 销售与市场
Meeting Notes / 会议记录
Speech / 语音
Text to Video / 文本转视频
Email Tools / 电子邮件工具
API / 应用程序编程接口
Chrome extension / Chrome 扩展
Writing / 写作
Search / 搜索
Copywriting / 广告文案
Research & Science / 研究与科学
Photo Editing / 照片编辑
Coding / 编程
Audio Editing / 音频编辑

🉑 大模型恋爱神器!自由定制16种 MBTI 人格,深度聊天停不下来

补充一份背景:MBTI 是一种心理测量工具,通过四个维度将人的性格划分为 16 种基本类型;了解自己的 MBTI 分类一定程度上有助于探索自己的性格和偏好
MBTI 最近两年突然爆火并逐渐成为新一代社交符号,现在常说的 i 人 (内向型) 和 e 人(外向型) 就是出自这个体系;感兴趣可以搜题库自测一下

https://www.modelscope.cn/studios/FarReelAILab/Machine_Mindset/summary
FarReel AI Lab (前身是 ChatLaw 项目) 和北大深研院合作研发,赋予了开源模型性格。访问 👆 上方链接,就可以和带有 MBTI 性格的大模型进行深度对话了!上方左图就是于 ENFP 模型对话的详细步骤~ 根据我与这类朋友的沟通体验来说,这几轮对话还挺有感觉的!!
呐!节日送礼摸底、聊天反复练习、生气原因分析、道歉策略尝试…… 大模型真的能帮我们谈恋爱了 ♥♥♥
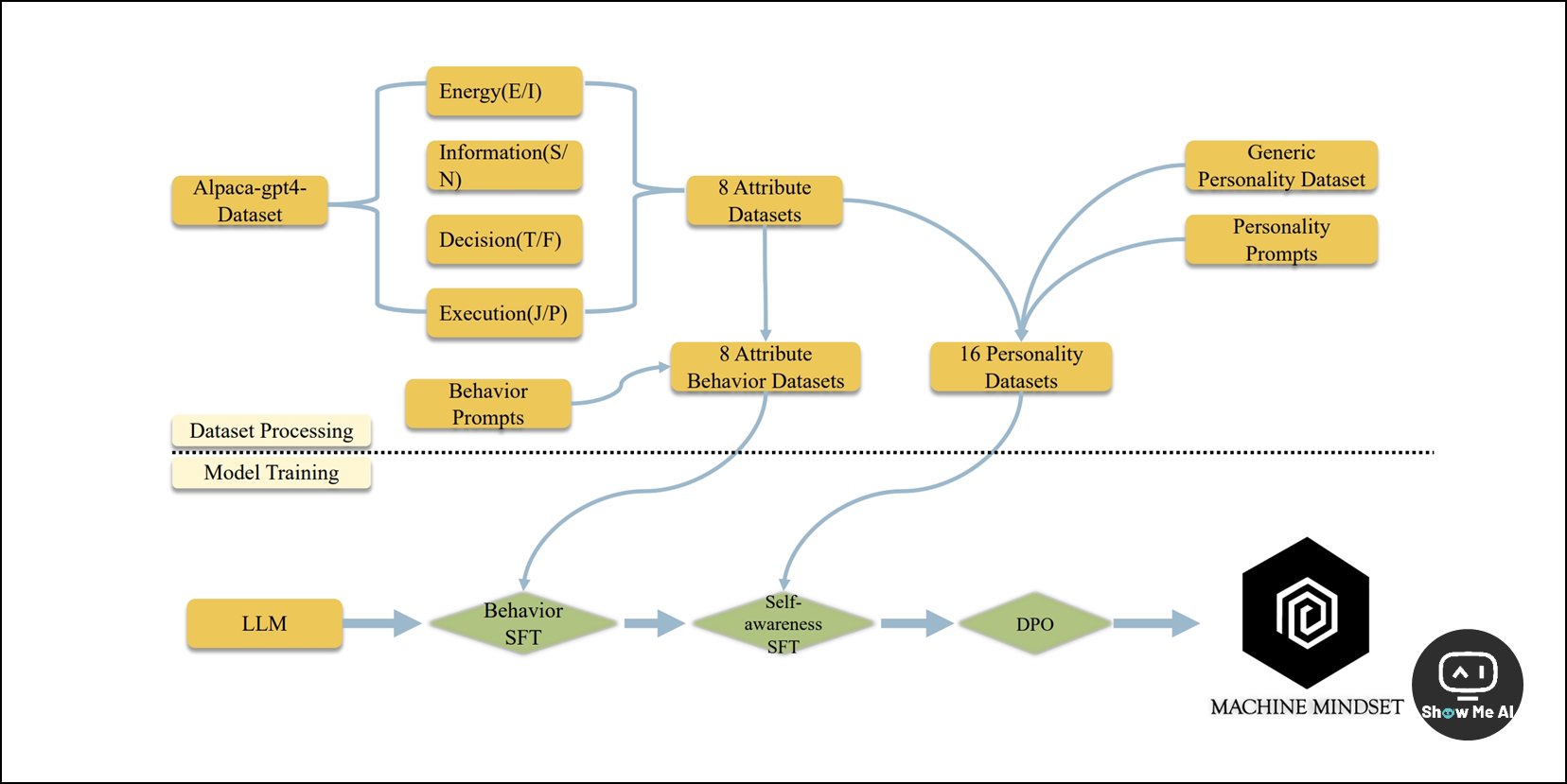
https://github.com/PKU-YuanGroup/Machine-Mindset
团队在 GitHub 发布了论文链接,并且开放下载所有的训练数据集 👏👏👏
团队自主构建了十万条大规模 MBTI 数据,然后通过多阶段预训练、微调、DPO训练方法为它注入性格。通过一个两阶段的有监督训练微调过程,最后可以得到对应人格的大模型。
👆 上图以训练一个 INFP 大模型为例,在第一阶段的有监督微调中,利用行为数据集中 I、N、F、P 四个数据集;在第二阶段的有监督微调中,再使用一个额外的自我意识数据集。

🉑 00后AI创业者:很遗憾!2023年我们没能成为风口上的猪

补充一份背景:一个AI初创团队2023年毅然转型AI赛道,做失败了所有项目,现金流出现问题,团队也由最初的60多人缩减至现在的4人。而他们是4位在读的大四本科生
这是一份来自 00 后AI创业团队的真诚总结。在过去10个月的时间里,他们尝试了大量的 AIGC 项目,可以说是琳琅满目:
第一阶段 | 用信息差或认知差做项目
图像和视频赛道:AI写真、AI换装,打造AI女友
新媒体赛道:运营AI短视频、公众号、AI社群、小红书、B站、知识星球
第二阶段 | 做套壳项目
- 搭建 ChatGPT 套壳小程序、AI工具集合库、Gpts集合网站
第三阶段 | To b 场景业务探索
- 为知识博主开发数字人分身应用,和B端医美企业合作生成人像海报,建立医生知识库…
第四阶段:打造AI原生应用
- 正在尝试中……
他们在文章里详细介绍了各个阶段的业务思考、业务发展情况、市场反馈、停止的原因,并且详细总结了经验。写得朴实且真诚~
AI创业新手和老手都可以看看,新手可以尝试把每条总结「读厚」,老手们可以找找难觅的纯真 ⋙ 有空就阅读原文呀
年轻真好 (づ ̄ 3 ̄)づ 祝福他们
👀 敢问路在何方?!2024年 AI 工具发展趋势预测
https://generativeai.pub/top-ai-tool-trends-for-2024-1ee0afeb5935
补充一份背景:昨天日报 提到 Sam Altman 近期出席 Y Combinator W24 启动会,反复提及 GPT-5 的能力飞跃及其对现有公司和产品的巨大冲击
GPT-5 相较于于 GPT-4 可能会有一个指数级的飞跃,尽管 GPT-4 已经领先近两年且至今无人超越
大多数 GPT-4 当前的限制都将在 GPT-5 中得到修复,这一巨大进步会给现有大大小小的公司带来了诸多挑战 → AGI将覆盖一大批创业者
建议使用最先进的模型 (State of the Art, SOTA) ,而不是花费太多时间进行微调和优化 → 徒劳无功
那……产品开发者将如何提早布局应对呢?AI工具选择那条发展路径最有可能得以存活乃至爆发呢?这篇文章作者提出的 2024年AI工具的8类发展趋势,或许可以加入思考和讨论:
服务速度提升:随着计算能力的提升和算法的优化,AI服务将实现更快的响应速度,这将催生更多创新应用
视频生成技术的普及:视频创作工具如Pika、RunWayML和Leonardo等的兴起,将使视频制作变得更加便捷,但用户仍需掌握如何编写有效的提示来获得最佳效果
个性化服务深化:AI通过分析用户数据提供定制化服务,随着大数据和用户行为分析技术的进步,未来将出现更加个性化的服务体验
智能聊天机器人的革新:开源语言模型 (LLMs) 的兴起,如Hugging Face的开放LLM排行榜,将推动智能文本服务的创新,并可能与能够表达真实情感的声音结合
动画虚拟影响者的兴起:继2023年虚拟影响者如Aitana的成功之后,预计2024年将出现更多带有声音的全动画影响者,未来可能发展为能够识别情感的个性化影响者
智能机器人工具的发展:智能聊天机器人与机器人技术的结合将带来可编程的智能机器人,随着LLMs的普及、计算能力的增强和3D算法的掌握,机器人技术将更加普及
多AI集成工具:2024年的工具将集成多个AI,以更有效地满足用户需求,同时管理算法复杂性将成为重点
输出质量的持续提升:AI工具的输出质量将持续改进,如Midjourney的版本迭代所示,AI技术将随着时间不断进化

🉑 优质科普视频!20分钟讲清楚自然语言处理的「古往」和「今来」
https://www.bilibili.com/video/BV1yi4y1B7Jt/
补充一份背景:自然语言处理 (Natural Language Processing,NLP) 是人工智能的一个分支,主要任务是使计算机理解、生成和处理人类语言
自然语言处理是一门涉及广泛的复杂技术,其发展历程上出现过众多值得称赞的想法。这个视频选取了每个时期最具代表性的方法,将自然语言的百年发展演进主千串成一条逻辑清晰的线条。
00:00 - 05:27 晦暗中的摸索
预定论认为上帝已经决定了每个人的救赎或放逐,个人无法改变;并衍生了对这一定理的众多补充
帕维尔利克拉索夫用大数定理证明了自由意志的存在
马尔可夫选择研究文学作品中元音和辅音的规律,客观上为随机过程的研究开创了道路,但因为枯燥等原因停止了研究
05:27 - 09:28 香农的研究以及 n-gram 模型在自然语言处理中的应用
香农在信息论中描述了自然语言中的马尔可夫随机过程,包括n-gram模型
语言学家认为,自然语言的研究需要一套非常完备的系统,而这是一项浩大而繁杂的工程
09:28 - 14:09 统计学和神经网络出现了
自然语言处理的本质是语义,而非符号规则本身
统计学方法在算力和数据上的客观障碍逐渐被克服,成为自然语言处理的主流方法
神经网络技术从上个世纪40年代开始发展,逐渐成为自然语言处理的研究方向
14:09 - 18:52 词向量、Word2Vec、注意力机制
模型使用充足的语料数据经过充分的训练后,可以预测下一个词的概率分布
训练过程中,词向量会被更新,使得相似的词变得更近、疏远的词变得更远
18:52 - 23:40 Transformer 模型在自然语言处理中的应用
使用注意力机制在上下文处理中十分有效
研究者们尝试不同的网络结构 (循环神经网络、Transformer等) 来加强向量对语义的表达能力
GPT 模型的原理与古老的 n-gram 模型类似,但显示出了令人惊讶的语义理解能力
🉑 绝佳新手教程:公式+代码+讲解,一文带你彻底搞懂 Transformer

http://aicoco.net/s/80
补充一份背景:上方视频提到了对于大模型发展至关重要的 Transformer。Transformer 的工作原理到底是什么?有没有一篇文章可以简单且清晰地讲明白 Transformer?
这篇文章对新手非常友好,用一个案例贯穿全文,来讲解 Transformer 的工作原理,并且配了大量的图解、代码段和公式推导过程。看懂本文,你就可以搞清楚上图中的每一个细节啦!!
而且,为了降低理解和演示难度,比如与 Transformer 论文「Attention is all you need」的数据相比,文章在维度和参数量方面做了一定程度的简化处理:
嵌入维度:512 (文章示例是4)
编码器数量:6 (文章示例是6)
解码器数量:6 (文章示例是6)
前馈维度:2048 (文章示例是8)
注意力头数量:8 (文章示例是2)
注意力维度:64 (文章示例是3)

🔔 Encoder (编码器)
Tokenization (分词):将输入文本分割成标记 (tokens) ,并为每个标记分配一个唯一的ID
Embedding the text (文本嵌入):将标记ID转换为具有语义含义的固定大小向量 (嵌入)
Positional encoding (位置编码):为嵌入向量添加位置信息,以便模型能够理解单词在句子中的位置
Add positional encoding and embedding (添加位置编码和嵌入):将位置编码向量与嵌入向量相加,为编码器的输入做好准备
Self-attention (自注意力):定义了用于多头自注意力的权重矩阵 → 计算查询 (Q) 、键 (K) 和值 (V) 矩阵 → 计算注意力分数并应用softmax函数 → 将注意力分数与值矩阵相乘以获得加权的值
Feed-forward layer (前馈层):包含两个线性变换和一个ReLU激活函数,用于进一步处理自注意力层的输出
Residual and Layer Normalization (残差和层归一化):使用残差连接和层归一化来稳定训练过程,防止梯度消失或爆炸
🔔 Decoder (解码器)
Embedding the text (文本嵌入):与编码器类似,将输入标记转换为嵌入向量
Positional encoding (位置编码):为解码器的嵌入向量添加位置编码
Add positional encoding and embedding (添加位置编码和嵌入):将位置编码向量与嵌入向量相加
Self-attention (自注意力):在解码器中执行自注意力,但与编码器的自注意力不同,这里使用了掩码来防止未来信息的泄漏
Residual connection and layer normalization (残差连接和层归一化):与编码器类似,使用残差连接和层归一化来稳定解码器的输出
Encoder-decoder attention (编码器-解码器注意力):在解码器中引入编码器-解码器注意力,允许解码器关注输入序列的相关部分
Residual connection and layer normalization (残差连接和层归一化):再次使用残差连接和层归一化来稳定输出
Feed-forward layer (前馈层):与编码器类似,包含两个线性变换和一个ReLU激活函数
Encapsulating everything: The Random Decoder (封装一切:随机解码器):将解码器的各个部分组合在一起,形成一个完整的解码器块
🔔 Generating the output sequence (生成输出序列)
Linear layer (线性层):在解码器的输出上应用线性层,以生成下一个标记的预测
Softmax (softmax):对线性层的输出应用softmax函数,以获得下一个标记的概率分布
The Random Encoder-Decoder Transformer (随机编码器-解码器Transformer):将编码器和解码器结合起来,形成一个完整的Transformer模型,用于生成输出序列
感谢贡献一手资讯、资料与使用体验的 ShowMeAI 社区同学们!

◉ 点击 👀日报&周刊合集,订阅话题 #ShowMeAI日报,一览AI领域发展前沿,抓住最新发展机会!
◉ 点击 🎡生产力工具与行业应用大全,一起在信息浪潮里扑腾起来吧!




)



部分)





和拦截器(HandlerInterceptor))




)