DETR的损失函数包括几个部分,如果只看论文或者代码,比较难理解,最好是可以打断点调试,对照着论文看。但是现在DETR模型都已经被集成进各种框架中,很难进入内部打断掉调试。与此同时,数据的label的前处理也比较麻烦。本文中提供的代码做好了数据标签的预处理,可以在中间打断点调试,观察每部分损失函数究竟是如何计算的。
首先,从hugging face的transformers库中拿出detr segmentation的model,并准备数据,数据是coco dataset数据集的panoptic,根据coco的json文件和mask图片,制作label:
from transformers import DetrConfig, DetrForSegmentationmodel = DetrForSegmentation.from_pretrained("facebook/detr-resnet-50-panoptic")
state_dict = model.state_dict()
# Remove class weights
del state_dict["detr.class_labels_classifier.weight"]
del state_dict["detr.class_labels_classifier.bias"]
# define new model with custom class classifier
config = DetrConfig.from_pretrained("facebook/detr-resnet-50-panoptic", num_labels=250)
model.load_state_dict(state_dict, strict=False)
model.to("cuda")# print(model.config)import torch
import json
from pathlib import Path
from PIL import Image
from transformers import DetrFeatureExtractor
import numpy as np
import matplotlib.pyplot as pltclass CocoPanoptic(torch.utils.data.Dataset):def __init__(self, img_folder, ann_folder, ann_file, feature_extractor):with open(ann_file, 'r') as f:self.coco = json.load(f)# sort 'images' field so that they are aligned with 'annotations'# i.e., in alphabetical orderself.coco['images'] = sorted(self.coco['images'], key=lambda x: x['id'])# sanity checkif "annotations" in self.coco:for img, ann in zip(self.coco['images'], self.coco['annotations']):assert img['file_name'][:-4] == ann['file_name'][:-4]self.img_folder = img_folderself.ann_folder = Path(ann_folder)self.ann_file = ann_fileself.feature_extractor = feature_extractordef __getitem__(self, idx):ann_info = self.coco['annotations'][idx] if "annotations" in self.coco else self.coco['images'][idx]img_path = Path(self.img_folder) / ann_info['file_name'].replace('.png', '.jpg')img = Image.open(img_path).convert('RGB')width = 400height = 600img = img.resize((width, height))# preprocess image and target (converting target to DETR format, resizing + normalization of both image and target)encoding = self.feature_extractor(images=img, annotations=ann_info, masks_path=self.ann_folder, return_tensors="pt")pixel_values = encoding["pixel_values"].squeeze() # remove batch dimensiontarget = encoding["labels"][0] # remove batch dimensionreturn pixel_values, targetdef __len__(self):return len(self.coco['images'])# we reduce the size and max_size to be able to fit the batches in GPU memory
feature_extractor = DetrFeatureExtractor.from_pretrained("facebook/detr-resnet-50-panoptic", size=500, max_size=600)dataset = CocoPanoptic(img_folder='/home/robotics/Downloads/coco2017/val2017',ann_folder='/home/robotics/Downloads/coco2017/Mask/panoptic mask/panoptic_val2017', # mask folder pathann_file='/home/robotics/Downloads/coco2017/annotations/panoptic_val2017.json',feature_extractor=feature_extractor)# let's split it up into very tiny training and validation sets using random indices
np.random.seed(42)
indices = np.random.randint(low=0, high=len(dataset), size=50)
train_dataset = torch.utils.data.Subset(dataset, indices[:40])
val_dataset = torch.utils.data.Subset(dataset, indices[40:])pixel_values, target = train_dataset[2]
print(pixel_values.shape)
print(target.keys())
# label_masks = target["masks"]
# boxes = target["boxes"]
# labels = target["class_labels"]from torch.utils.data import DataLoaderdef collate_fn(batch):pixel_values = [item[0] for item in batch]encoded_input = feature_extractor.pad(pixel_values, return_tensors="pt")labels = [item[1] for item in batch]batch = {}batch['pixel_values'] = encoded_input['pixel_values']batch['pixel_mask'] = encoded_input['pixel_mask']batch['labels'] = labelsreturn batchtrain_dataloader = DataLoader(train_dataset, collate_fn=collate_fn, batch_size=2, shuffle=True)
val_dataloader = DataLoader(val_dataset, collate_fn=collate_fn, batch_size=1)# for idx, batch in enumerate(train_dataloader):
# pixel_values = batch["pixel_values"].to("cuda")
# pixel_mask = batch["pixel_mask"].to("cuda")
# labels = [{k: v.to("cuda") for k, v in t.items()} for t in batch["labels"]]
#
# outputs = model(pixel_values=pixel_values, pixel_mask=pixel_mask, labels=labels)
#
# loss = outputs.loss
# loss_dict = outputs.loss_dict
#
# print("done")
然后再创建一个py文件,写入下面的代码,就可以打断点观察loss的计算了:
import torch.nn as nn
from collections import OrderedDict
import importlib.util
import torch
from torch import Tensor
from scipy.optimize import linear_sum_assignment
from typing import Dict, List, Optional, Tuple# docstyle-ignore
SCIPY_IMPORT_ERROR = """
{0} requires the scipy library but it was not found in your environment. You can install it with pip:
`pip install scipy`
"""
def is_scipy_available():return importlib.util.find_spec("scipy") is not NoneBACKENDS_MAPPING = OrderedDict([("scipy", (is_scipy_available, SCIPY_IMPORT_ERROR)),]
)def requires_backends(obj, backends):if not isinstance(backends, (list, tuple)):backends = [backends]name = obj.__name__ if hasattr(obj, "__name__") else obj.__class__.__name__checks = (BACKENDS_MAPPING[backend] for backend in backends)failed = [msg.format(name) for available, msg in checks if not available()]if failed:raise ImportError("".join(failed))def _upcast(t: Tensor) -> Tensor:# Protects from numerical overflows in multiplications by upcasting to the equivalent higher typeif t.is_floating_point():return t if t.dtype in (torch.float32, torch.float64) else t.float()else:return t if t.dtype in (torch.int32, torch.int64) else t.int()def box_area(boxes: Tensor) -> Tensor:"""Computes the area of a set of bounding boxes, which are specified by its (x1, y1, x2, y2) coordinates.Args:boxes (`torch.FloatTensor` of shape `(number_of_boxes, 4)`):Boxes for which the area will be computed. They are expected to be in (x1, y1, x2, y2) format with `0 <= x1< x2` and `0 <= y1 < y2`.Returns:`torch.FloatTensor`: a tensor containing the area for each box."""boxes = _upcast(boxes)return (boxes[:, 2] - boxes[:, 0]) * (boxes[:, 3] - boxes[:, 1])def box_iou(boxes1, boxes2):area1 = box_area(boxes1)area2 = box_area(boxes2)left_top = torch.max(boxes1[:, None, :2], boxes2[:, :2]) # [N,M,2]right_bottom = torch.min(boxes1[:, None, 2:], boxes2[:, 2:]) # [N,M,2]width_height = (right_bottom - left_top).clamp(min=0) # [N,M,2]inter = width_height[:, :, 0] * width_height[:, :, 1] # [N,M]union = area1[:, None] + area2 - interiou = inter / unionreturn iou, uniondef generalized_box_iou(boxes1, boxes2):"""Generalized IoU from https://giou.stanford.edu/. The boxes should be in [x0, y0, x1, y1] (corner) format.Returns:`torch.FloatTensor`: a [N, M] pairwise matrix, where N = len(boxes1) and M = len(boxes2)"""# degenerate boxes gives inf / nan results# so do an early checkassert (boxes1[:, 2:] >= boxes1[:, :2]).all()assert (boxes2[:, 2:] >= boxes2[:, :2]).all()iou, union = box_iou(boxes1, boxes2)lt = torch.min(boxes1[:, None, :2], boxes2[:, :2])rb = torch.max(boxes1[:, None, 2:], boxes2[:, 2:])wh = (rb - lt).clamp(min=0) # [N,M,2]area = wh[:, :, 0] * wh[:, :, 1]return iou - (area - union) / areadef center_to_corners_format(x):"""Converts a PyTorch tensor of bounding boxes of center format (center_x, center_y, width, height) to corners format(x_0, y_0, x_1, y_1)."""x_c, y_c, w, h = x.unbind(-1)b = [(x_c - 0.5 * w), (y_c - 0.5 * h), (x_c + 0.5 * w), (y_c + 0.5 * h)]return torch.stack(b, dim=-1)class DetrHungarianMatcher(nn.Module):"""This class computes an assignment between the targets and the predictions of the network.For efficiency reasons, the targets don't include the no_object. Because of this, in general, there are morepredictions than targets. In this case, we do a 1-to-1 matching of the best predictions, while the others areun-matched (and thus treated as non-objects).Args:class_cost:The relative weight of the classification error in the matching cost.bbox_cost:The relative weight of the L1 error of the bounding box coordinates in the matching cost.giou_cost:The relative weight of the giou loss of the bounding box in the matching cost."""def __init__(self, class_cost: float = 1, bbox_cost: float = 1, giou_cost: float = 1):super().__init__()requires_backends(self, ["scipy"])self.class_cost = class_costself.bbox_cost = bbox_costself.giou_cost = giou_costif class_cost == 0 or bbox_cost == 0 or giou_cost == 0:raise ValueError("All costs of the Matcher can't be 0")@torch.no_grad()def forward(self, outputs, targets):"""Args:outputs (`dict`):A dictionary that contains at least these entries:* "logits": Tensor of dim [batch_size, num_queries, num_classes] with the classification logits* "pred_boxes": Tensor of dim [batch_size, num_queries, 4] with the predicted box coordinates.targets (`List[dict]`):A list of targets (len(targets) = batch_size), where each target is a dict containing:* "class_labels": Tensor of dim [num_target_boxes] (where num_target_boxes is the number ofground-truthobjects in the target) containing the class labels* "boxes": Tensor of dim [num_target_boxes, 4] containing the target box coordinates.Returns:`List[Tuple]`: A list of size `batch_size`, containing tuples of (index_i, index_j) where:- index_i is the indices of the selected predictions (in order)- index_j is the indices of the corresponding selected targets (in order)For each batch element, it holds: len(index_i) = len(index_j) = min(num_queries, num_target_boxes)"""batch_size, num_queries = outputs["logits"].shape[:2]# We flatten to compute the cost matrices in a batchout_prob = outputs["logits"].flatten(0, 1).softmax(-1) # [batch_size * num_queries, num_classes]out_bbox = outputs["pred_boxes"].flatten(0, 1) # [batch_size * num_queries, 4]# Also concat the target labels and boxestgt_ids = torch.cat([v["class_labels"] for v in targets])tgt_bbox = torch.cat([v["boxes"] for v in targets])# Compute the classification cost. Contrary to the loss, we don't use the NLL,# but approximate it in 1 - proba[target class].# The 1 is a constant that doesn't change the matching, it can be ommitted.class_cost = -out_prob[:, tgt_ids]# Compute the L1 cost between boxesbbox_cost = torch.cdist(out_bbox, tgt_bbox, p=1)# Compute the giou cost between boxesgiou_cost = -generalized_box_iou(center_to_corners_format(out_bbox), center_to_corners_format(tgt_bbox))# Final cost matrixcost_matrix = self.bbox_cost * bbox_cost + self.class_cost * class_cost + self.giou_cost * giou_costcost_matrix = cost_matrix.view(batch_size, num_queries, -1).cpu()sizes = [len(v["boxes"]) for v in targets]indices = [linear_sum_assignment(c[i]) for i, c in enumerate(cost_matrix.split(sizes, -1))]return [(torch.as_tensor(i, dtype=torch.int64), torch.as_tensor(j, dtype=torch.int64)) for i, j in indices]def _max_by_axis(the_list):# type: (List[List[int]]) -> List[int]maxes = the_list[0]for sublist in the_list[1:]:for index, item in enumerate(sublist):maxes[index] = max(maxes[index], item)return maxesclass NestedTensor(object):def __init__(self, tensors, mask: Optional[Tensor]):self.tensors = tensorsself.mask = maskdef to(self, device):cast_tensor = self.tensors.to(device)mask = self.maskif mask is not None:cast_mask = mask.to(device)else:cast_mask = Nonereturn NestedTensor(cast_tensor, cast_mask)def decompose(self):return self.tensors, self.maskdef __repr__(self):return str(self.tensors)def nested_tensor_from_tensor_list(tensor_list: List[Tensor]):if tensor_list[0].ndim == 3:max_size = _max_by_axis([list(img.shape) for img in tensor_list])batch_shape = [len(tensor_list)] + max_sizeb, c, h, w = batch_shapedtype = tensor_list[0].dtypedevice = tensor_list[0].devicetensor = torch.zeros(batch_shape, dtype=dtype, device=device)mask = torch.ones((b, h, w), dtype=torch.bool, device=device)for img, pad_img, m in zip(tensor_list, tensor, mask):pad_img[: img.shape[0], : img.shape[1], : img.shape[2]].copy_(img)m[: img.shape[1], : img.shape[2]] = Falseelse:raise ValueError("Only 3-dimensional tensors are supported")return NestedTensor(tensor, mask)def sigmoid_focal_loss(inputs, targets, num_boxes, alpha: float = 0.25, gamma: float = 2):"""Loss used in RetinaNet for dense detection: https://arxiv.org/abs/1708.02002.Args:inputs: A float tensor of arbitrary shape.The predictions for each example.targets: A float tensor with the same shape as inputs. Stores the binaryclassification label for each element in inputs (0 for the negative class and 1 for the positiveclass).alpha: (optional) Weighting factor in range (0,1) to balancepositive vs negative examples. Default = -1 (no weighting).gamma: Exponent of the modulating factor (1 - p_t) tobalance easy vs hard examples.Returns:Loss tensor"""prob = inputs.sigmoid()ce_loss = nn.functional.binary_cross_entropy_with_logits(inputs, targets, reduction="none")p_t = prob * targets + (1 - prob) * (1 - targets)loss = ce_loss * ((1 - p_t) ** gamma)if alpha >= 0:alpha_t = alpha * targets + (1 - alpha) * (1 - targets)loss = alpha_t * lossreturn loss.mean(1).sum() / num_boxesdef dice_loss(inputs, targets, num_boxes):"""Compute the DICE loss, similar to generalized IOU for masksArgs:inputs: A float tensor of arbitrary shape.The predictions for each example.targets: A float tensor with the same shape as inputs. Stores the binaryclassification label for each element in inputs (0 for the negative class and 1 for the positiveclass)."""inputs = inputs.sigmoid()inputs = inputs.flatten(1)numerator = 2 * (inputs * targets).sum(1)denominator = inputs.sum(-1) + targets.sum(-1)loss = 1 - (numerator + 1) / (denominator + 1)return loss.sum() / num_boxesclass DetrLoss(nn.Module):"""This class computes the losses for DetrForObjectDetection/DetrForSegmentation. The process happens in two steps: 1)we compute hungarian assignment between ground truth boxes and the outputs of the model 2) we supervise each pairof matched ground-truth / prediction (supervise class and box).A note on the `num_classes` argument (copied from original repo in detr.py): "the naming of the `num_classes`parameter of the criterion is somewhat misleading. It indeed corresponds to `max_obj_id` + 1, where `max_obj_id` isthe maximum id for a class in your dataset. For example, COCO has a `max_obj_id` of 90, so we pass `num_classes` tobe 91. As another example, for a dataset that has a single class with `id` 1, you should pass `num_classes` to be 2(`max_obj_id` + 1). For more details on this, check the following discussionhttps://github.com/facebookresearch/detr/issues/108#issuecomment-650269223"Args:matcher (`DetrHungarianMatcher`):Module able to compute a matching between targets and proposals.num_classes (`int`):Number of object categories, omitting the special no-object category.eos_coef (`float`):Relative classification weight applied to the no-object category.losses (`List[str]`):List of all the losses to be applied. See `get_loss` for a list of all available losses."""def __init__(self, matcher, num_classes, eos_coef, losses):super().__init__()self.matcher = matcherself.num_classes = num_classesself.eos_coef = eos_coefself.losses = lossesempty_weight = torch.ones(self.num_classes + 1)empty_weight[-1] = self.eos_coefself.register_buffer("empty_weight", empty_weight)# removed logging parameter, which was part of the original implementationdef loss_labels(self, outputs, targets, indices, num_boxes):"""Classification loss (NLL) targets dicts must contain the key "class_labels" containing a tensor of dim[nb_target_boxes]"""if "logits" not in outputs:raise KeyError("No logits were found in the outputs")src_logits = outputs["logits"]idx = self._get_src_permutation_idx(indices)target_classes_o = torch.cat([t["class_labels"][J] for t, (_, J) in zip(targets, indices)])target_classes = torch.full(src_logits.shape[:2], self.num_classes, dtype=torch.int64, device=src_logits.device)target_classes[idx] = target_classes_oloss_ce = nn.functional.cross_entropy(src_logits.transpose(1, 2), target_classes, self.empty_weight)losses = {"loss_ce": loss_ce}return losses@torch.no_grad()def loss_cardinality(self, outputs, targets, indices, num_boxes):"""Compute the cardinality error, i.e. the absolute error in the number of predicted non-empty boxes.This is not really a loss, it is intended for logging purposes only. It doesn't propagate gradients."""logits = outputs["logits"]device = logits.devicetgt_lengths = torch.as_tensor([len(v["class_labels"]) for v in targets], device=device)# Count the number of predictions that are NOT "no-object" (which is the last class)card_pred = (logits.argmax(-1) != logits.shape[-1] - 1).sum(1)card_err = nn.functional.l1_loss(card_pred.float(), tgt_lengths.float())losses = {"cardinality_error": card_err}return lossesdef loss_boxes(self, outputs, targets, indices, num_boxes):"""Compute the losses related to the bounding boxes, the L1 regression loss and the GIoU loss.Targets dicts must contain the key "boxes" containing a tensor of dim [nb_target_boxes, 4]. The target boxesare expected in format (center_x, center_y, w, h), normalized by the image size."""if "pred_boxes" not in outputs:raise KeyError("No predicted boxes found in outputs")idx = self._get_src_permutation_idx(indices)src_boxes = outputs["pred_boxes"][idx]target_boxes = torch.cat([t["boxes"][i] for t, (_, i) in zip(targets, indices)], dim=0)loss_bbox = nn.functional.l1_loss(src_boxes, target_boxes, reduction="none")losses = {}losses["loss_bbox"] = loss_bbox.sum() / num_boxesloss_giou = 1 - torch.diag(generalized_box_iou(center_to_corners_format(src_boxes), center_to_corners_format(target_boxes)))losses["loss_giou"] = loss_giou.sum() / num_boxesreturn lossesdef loss_masks(self, outputs, targets, indices, num_boxes):"""Compute the losses related to the masks: the focal loss and the dice loss.Targets dicts must contain the key "masks" containing a tensor of dim [nb_target_boxes, h, w]."""if "pred_masks" not in outputs:raise KeyError("No predicted masks found in outputs")src_idx = self._get_src_permutation_idx(indices)tgt_idx = self._get_tgt_permutation_idx(indices)src_masks = outputs["pred_masks"]src_masks = src_masks[src_idx]masks = [t["masks"] for t in targets]# TODO use valid to mask invalid areas due to padding in losstarget_masks, valid = nested_tensor_from_tensor_list(masks).decompose()target_masks = target_masks.to(src_masks)target_masks = target_masks[tgt_idx]# upsample predictions to the target sizesrc_masks = nn.functional.interpolate(src_masks[:, None], size=target_masks.shape[-2:], mode="bilinear", align_corners=False)src_masks = src_masks[:, 0].flatten(1)target_masks = target_masks.flatten(1)target_masks = target_masks.view(src_masks.shape)losses = {"loss_mask": sigmoid_focal_loss(src_masks, target_masks, num_boxes),"loss_dice": dice_loss(src_masks, target_masks, num_boxes),}return lossesdef _get_src_permutation_idx(self, indices):# permute predictions following indicesbatch_idx = torch.cat([torch.full_like(src, i) for i, (src, _) in enumerate(indices)])src_idx = torch.cat([src for (src, _) in indices])return batch_idx, src_idxdef _get_tgt_permutation_idx(self, indices):# permute targets following indicesbatch_idx = torch.cat([torch.full_like(tgt, i) for i, (_, tgt) in enumerate(indices)])tgt_idx = torch.cat([tgt for (_, tgt) in indices])return batch_idx, tgt_idxdef get_loss(self, loss, outputs, targets, indices, num_boxes):loss_map = {"labels": self.loss_labels,"cardinality": self.loss_cardinality,"boxes": self.loss_boxes,"masks": self.loss_masks,}if loss not in loss_map:raise ValueError(f"Loss {loss} not supported")return loss_map[loss](outputs, targets, indices, num_boxes)def forward(self, outputs, targets):"""This performs the loss computation.Args:outputs (`dict`, *optional*):Dictionary of tensors, see the output specification of the model for the format.targets (`List[dict]`, *optional*):List of dicts, such that len(targets) == batch_size. The expected keys in each dict depends on thelosses applied, see each loss' doc."""outputs_without_aux = {k: v for k, v in outputs.items() if k != "auxiliary_outputs"}# Retrieve the matching between the outputs of the last layer and the targetsindices = self.matcher(outputs_without_aux, targets)# Compute the average number of target boxes accross all nodes, for normalization purposesnum_boxes = sum(len(t["class_labels"]) for t in targets)num_boxes = torch.as_tensor([num_boxes], dtype=torch.float, device=next(iter(outputs.values())).device)# (Niels): comment out function below, distributed training to be added# if is_dist_avail_and_initialized():# torch.distributed.all_reduce(num_boxes)# (Niels) in original implementation, num_boxes is divided by get_world_size()num_boxes = torch.clamp(num_boxes, min=1).item()# Compute all the requested losseslosses = {}for loss in self.losses:losses.update(self.get_loss(loss, outputs, targets, indices, num_boxes))# In case of auxiliary losses, we repeat this process with the output of each intermediate layer.if "auxiliary_outputs" in outputs:for i, auxiliary_outputs in enumerate(outputs["auxiliary_outputs"]):indices = self.matcher(auxiliary_outputs, targets)for loss in self.losses:if loss == "masks":# Intermediate masks losses are too costly to compute, we ignore them.continuel_dict = self.get_loss(loss, auxiliary_outputs, targets, indices, num_boxes)l_dict = {k + f"_{i}": v for k, v in l_dict.items()}losses.update(l_dict)return lossesclass_cost = 1
bbox_cost = 5
giou_cost = 2
matcher = DetrHungarianMatcher(class_cost=class_cost, bbox_cost=bbox_cost, giou_cost=giou_cost)losses = ["labels", "boxes", "cardinality", "masks"]
num_labels = 250
eos_coefficient = 0.1
criterion = DetrLoss(matcher=matcher,num_classes=num_labels,eos_coef=eos_coefficient,losses=losses,
)
criterion.to("cuda")
# Third: compute the losses, based on outputs and labelsfrom model_from_huggingface import *for idx, batch in enumerate(train_dataloader):pixel_values = batch["pixel_values"].to("cuda")pixel_mask = batch["pixel_mask"].to("cuda")labels = [{k: v.to("cuda") for k, v in t.items()} for t in batch["labels"]]outputs = model(pixel_values=pixel_values, pixel_mask=pixel_mask, labels=labels)outputs_loss = {}outputs_loss["logits"] = outputs.logitsoutputs_loss["pred_boxes"] = outputs.pred_boxesoutputs_loss["pred_masks"] = outputs.pred_masksloss_dict = criterion(outputs_loss, labels)# Fourth: compute total loss, as a weighted sum of the various lossesbbox_loss_coefficient = 5giou_loss_coefficient = 2mask_loss_coefficient = 1dice_loss_coefficient = 1weight_dict = {"loss_ce": 1, "loss_bbox": bbox_loss_coefficient}weight_dict["loss_giou"] = giou_loss_coefficientweight_dict["loss_mask"] = mask_loss_coefficientweight_dict["loss_dice"] = dice_loss_coefficientloss = sum(loss_dict[k] * weight_dict[k] for k in loss_dict.keys() if k in weight_dict)print(loss)
下面解释一下运行其中的变量
indices是query和target进行匈牙利匹配后的结果

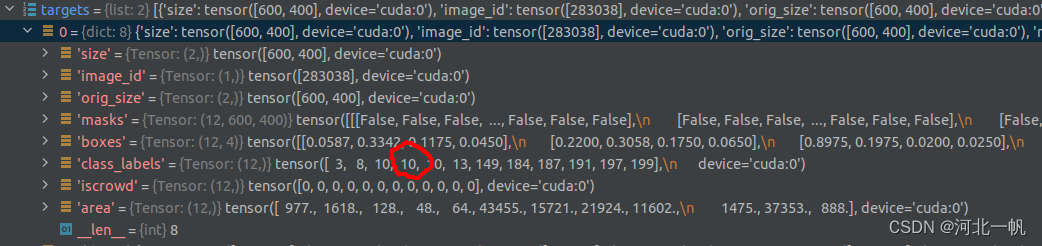
也就是说,第5个query去匹配class_labels中的10


)










)





_内联样式的获取和修改、获取元素当前显示的样式)