💡💡💡本文摘要:介绍了学生课堂行为检测,并使用YOLOv7进行训练模型,以及引入BRA注意力和多种IoU改进来提升检测能力
目录
1.SCB介绍
编辑
2.如何提高YOLOv7课堂行为检测能力
2.1 训练基于YOLOv7模型的课堂行为检测能力
2.2 如何优化提升课堂行为检测能力
2.2.1 Biformer介绍
3.如何获取源码
1.SCB介绍

摘要:利用深度学习方法自动检测学生的课堂行为是分析学生课堂表现和提高教学效果的一种很有前途的方法。然而,缺乏关于学生行为的公开数据集给这一领域的研究人员带来了挑战。为了解决这个问题,我们提出了学生课堂行为数据集(SCB-dataset3),它代表了现实生活中的场景。我们的数据集包括5686张图像,45578个标签,重点关注六种行为:举手、阅读、写作、使用电话、低头和俯身在桌子上。我们使用YOLOv5、YOLOv7和YOLOv8算法对数据集进行评估,平均精度(map)高达80.3%。我们相信我们的数据集可以作为未来学生行为检测研究的坚实基础,并有助于该领域的进步。
在本研究中,我们对之前的工作进行了迭代优化,以进一步扩展scb数据集。最初,我们只关注学生举手的行为,但现在我们已经扩展到六种行为:举手,阅读,写作,使用电话,低头,靠在桌子上。通过这项工作,我们进一步解决了课堂教学场景中学生行为检测的研究空白。我们进行了广泛的数据统计和基准测试,以确保数据集的质量,提供可靠的训练数据。
我们的主要贡献如下:
1. 我们已经将scb数据集更新到第三个版本(SCB-Dataset3),增加了6个行为类别。该数据集共包含5686张图像和45578个注释。它涵盖了从幼儿园到大学的不同场景。
2. 我们对SCBDataset3进行了广泛的基准测试,为今后的研究提供了坚实的基础。
3. 对于SCB-Dataset3中的大学场景数据,我们采用了“帧插值”方法并进行了实验验证。结果表明,该方法显著提高了行为检测的准确率。
4. 我们提出了一种新的度量标准——行为相似指数(BSI),用来衡量网络模型下不同行为之间在形式上的相似性。


学生课堂行为不同数据集如下:
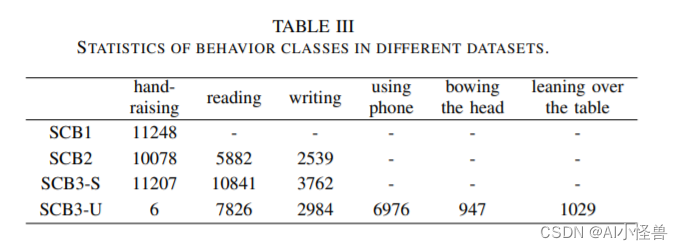 不同YOLO模型性能如下:
不同YOLO模型性能如下:

2.如何提高YOLOv7课堂行为检测能力
2.1 训练基于YOLOv7模型的课堂行为检测能力
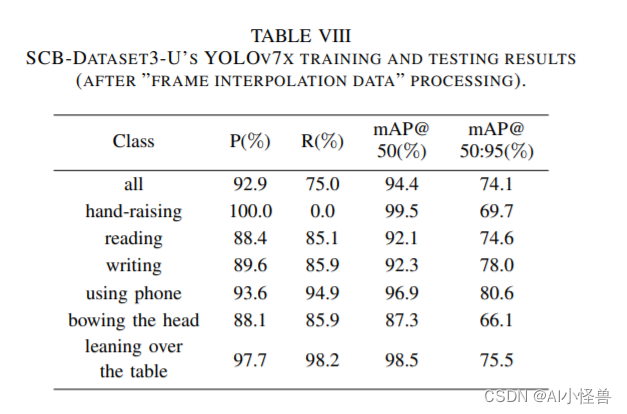
2.2 如何优化提升课堂行为检测能力
通过加入Biformer中的注意力机制和多种IoU优化方法

2.2.1 Biformer介绍

论文:https://arxiv.org/pdf/2303.08810.pdf
背景:注意力机制是Vision Transformer的核心构建模块之一,可以捕捉长程依赖关系。然而,由于需要计算所有空间位置之间的成对令牌交互,这种强大的功能会带来巨大的计算负担和内存开销。为了减轻这个问题,一系列工作尝试通过引入手工制作和内容无关的稀疏性到关注力中来解决这个问题,如限制关注操作在局部窗口、轴向条纹或扩张窗口内。
本文方法:本文提出一种动态稀疏注意力的双层路由方法。对于一个查询,首先在粗略的区域级别上过滤掉不相关的键值对,然后在剩余候选区域(即路由区域)的并集中应用细粒度的令牌对令牌关注力。所提出的双层路由注意力具有简单而有效的实现方式,利用稀疏性来节省计算和内存,只涉及GPU友好的密集矩阵乘法。在此基础上构建了一种新的通用Vision Transformer,称为BiFormer。
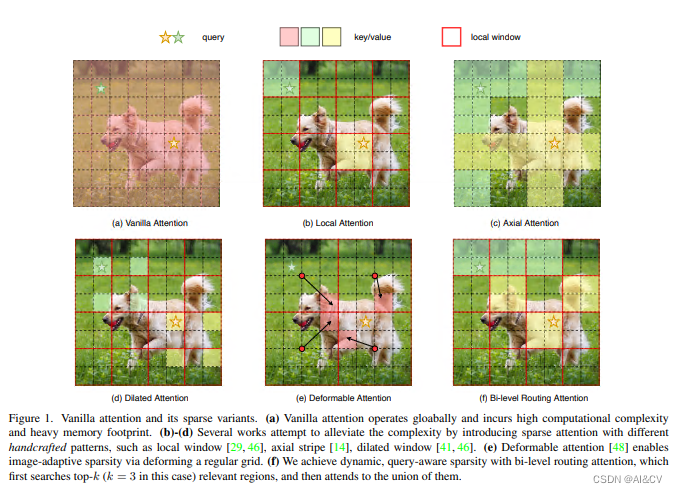
其中图(a)是原始的注意力实现,其直接在全局范围内操作,导致高计算复杂性和大量内存占用;而对于图(b)-(d),这些方法通过引入具有不同手工模式的稀疏注意力来减轻复杂性,例如局部窗口、轴向条纹和扩张窗口等;而图(e)则是基于可变形注意力通过不规则网格来实现图像自适应稀疏性;作者认为以上这些方法大都是通过将 手工制作 和 与内容无关 的稀疏性引入到注意力机制来试图缓解这个问题。因此,本文通过双层路由(bi-level routing)提出了一种新颖的动态稀疏注意力(dynamic sparse attention ),以实现更灵活的计算分配和内容感知,使其具备动态的查询感知稀疏性,如图(f)所示。

YOLOv7-BRA结构图
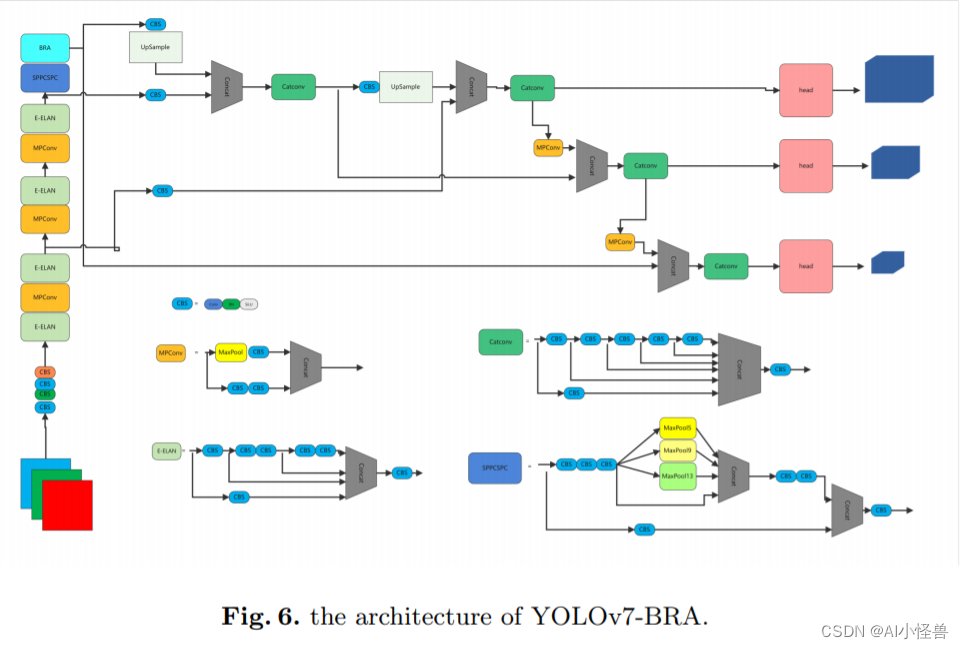
YOLOv7-BRA结果分析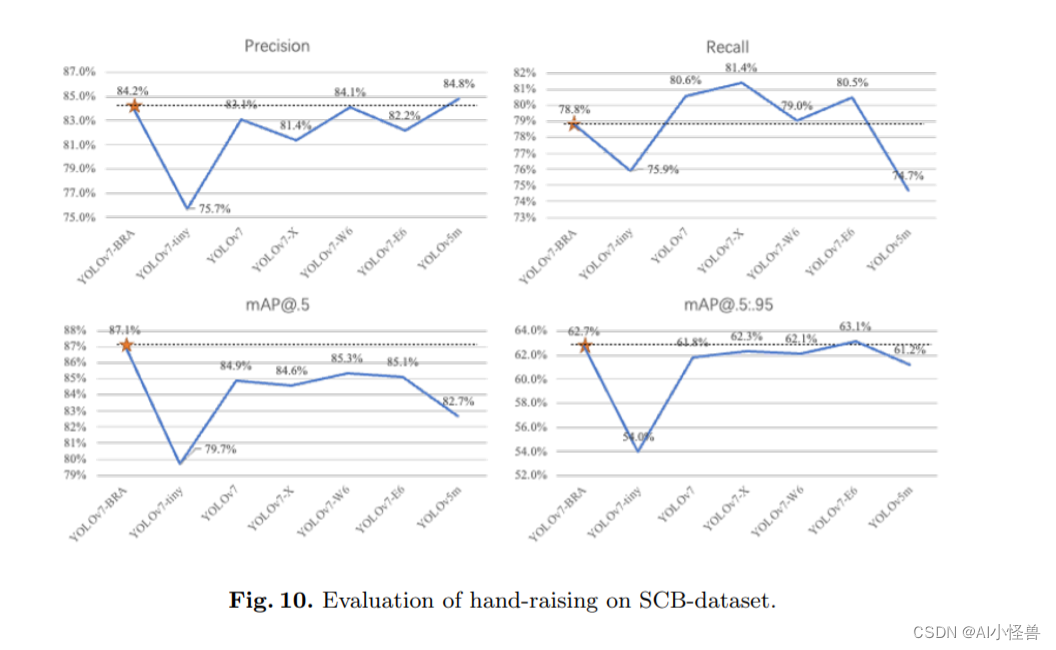
3.如何获取源码
关注后私信提供获取方式

应用,FOR循环,解决存储表内存溢出的问题)


)

)
)
)



主从复制)






