为什么需要训练集、验证集(简单交叉验证集)和测试集?
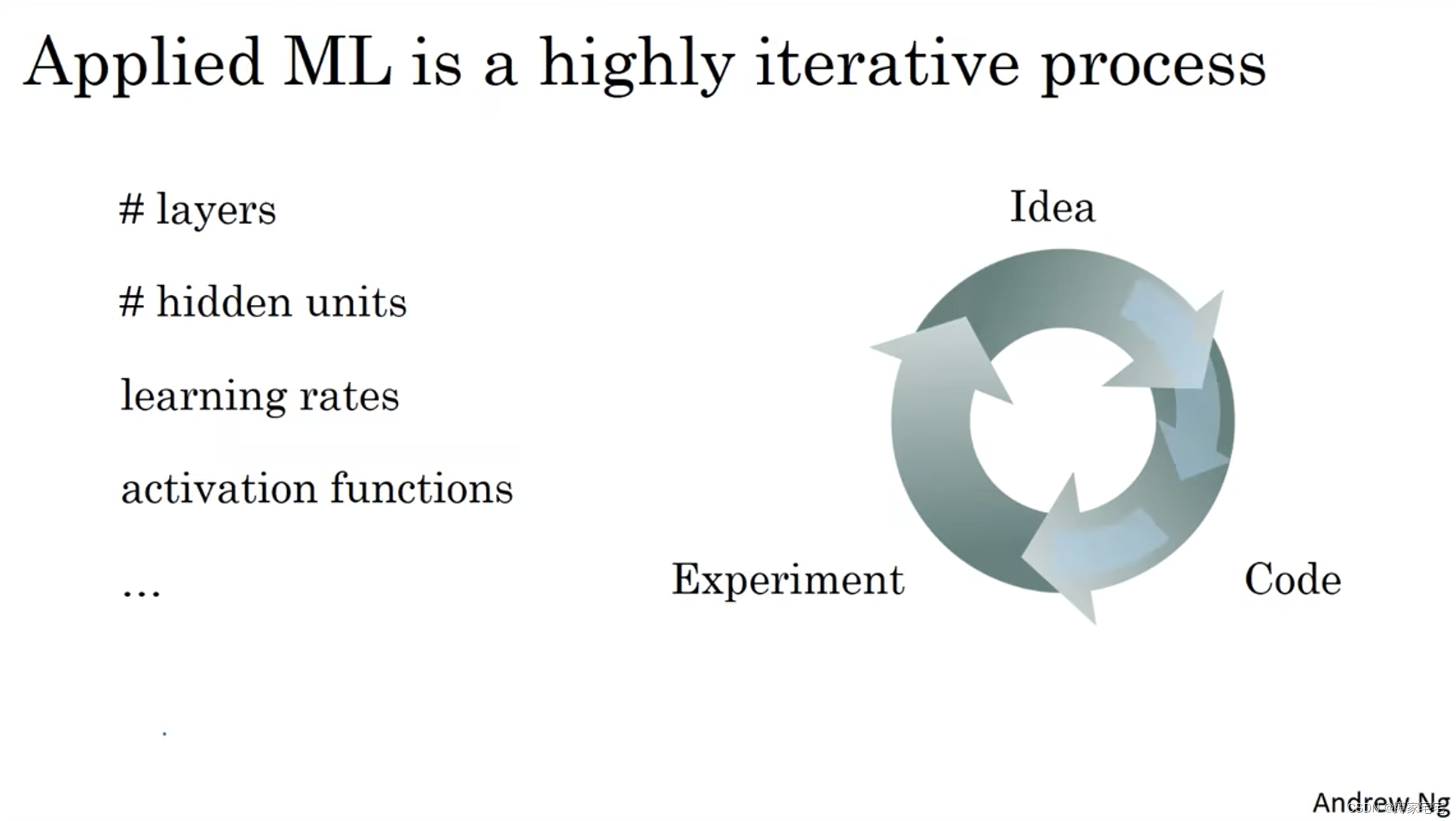 为了创建高效的神经网络,需要不断进行训练(迭代)
为了创建高效的神经网络,需要不断进行训练(迭代)
一个神经网络的产生
从最开始的想法idea开始,然后付诸于代码code,根据结果验证反过来对一开始的想法idea进行修正,而这就完成了一次训练(迭代)
循环速率(迭代速率)
train/dev/test sets会加速神经网络的集成
数据的配置

一般将数据分为三个部分(train/dev/test sets)
在训练集和验证集之后得到匹配的神经网络,然后利用测试集来对当前神经网络进行评估
分配的演变
小数据时代:
70% train sets 30% test sets
60% train sets 20% dev sets 20% test sets
大数据时代:
绝大部分为train sets,极小部分为dev sets和test sets
对于百万量级的数据,可以分为98% train sets 1% dev sets 1% test sets
对于超百万量级的数据,可以分为99.5% train sets 0.25% dev sets 0.25% test sets
原因:
由于大数据量的存在,dev sets只需要对不同的算法进行验证与取舍即可,故得出几种合适的算法来优化性能即可,而test sets只需要对神经网络进行无偏评估即可,所以数据量不需要很大
补充:
一条法则:
dev和test sets最好来自同一分布(same distribution),这样可以加快速率与优化性能
test sets不是必须的
如果不需要进行无偏评估,那么只用保证train/dev sets(训练验证集)即可
)





库读取csv文件并取出某个单元格的内容的学习过程)








![【学习笔记】[AGC043F] Jewelry Box](http://pic.xiahunao.cn/【学习笔记】[AGC043F] Jewelry Box)



 Ba-Permissions)