自学Python笔记总结
- 网址
- 数据类型
- 类型
- 查看类型,使用type内置类
- 标识符
- 输出输入语句
- format函数的语法及用法
- 数据类型的转换
- 运算符
- 算数运算符
- 赋值运算符的特殊场景
- 拆包
- 比较运算符
- 逻辑运算符 与 短路
- 位运算符
- 运算符优先级
- 程序流程控制
- 分支语句
- pass 占位
- 循环语句 while 和 for
- 代码运用 打印九九乘法表
- 一行代码快速 打印九九乘法表
- 跳出语句 break continue 使用
- 容器类型的数据
- 字符串
- **加和乘操作**
- 切片操作
- 字符串常见的操作
- 成员测试
- 常用的转义符
- 列表
- 创建列表
- 添加元素
- 替换 修改 元素
- 列表删除和查询元素
- 遍历 冒泡排序
- 排序
- 列表随机 嵌套 与创建
- 拷贝 复制
- 交换两个变量的值
- 元组
- 集合
- 创建集合
- 修改集合
- 使用 运算符
- 去重排序
- 字典
- 创建字典
- 增删改查
- 遍历字典
- 练习
- 转换相关的方法
- 内置函数
- 函数
- 全局变量 局部变量
- 默认参数
- 可变参数
- 可变类型和不可变类型传参
- 递归函数
- lambda() 匿名函数
- 内置函数的使用
- 高级函数 函数嵌套
- 函数练习代码
- 闭包的概念
- 计算时间的代码
- 装饰器
- 模块
- 模块的概念
- 模块的导入方式
- 安装三方模块
- 一、Python修改镜像源
- 二、Python安装三方模块
- 常用的内置模块
- 自定义模块
- 包的使用
- 类与对象【面向对象】
- 定义简单的类(只包含方法)
- 魔法方法
- 面向对象 练习
- 内置属性
- 类属性和对象属性
- 私有属性和方法
- 类方法、静态方法
- 子类重写父类方法
- 单例设计模式
- 继承的基本使用
- 对象相关的内置函数
网址
python官网下载
使用win+R输入CMD,进入控制台后输入python -V,出现对应的python版本就算安装成功。
Pycharm官网下载
请自行找激活教程 …
notepad++ 官网下载
sublime text 官网下载
notepad++和sublime text这两个工具可以更好的查看txt类型的文件
Python、Java、C、C++和JavaScript的在线编译器、可视化调试器和人工智能导师
数据类型
类型
Python里的数据类型:
- 整型(int)
- 浮点型(float)
- 复数(complex)
- 字符串(str)
- 布尔(bool)
- 列表(list)
- 元组(tuple)
- 字典(dict)
- 集合(set)
# 数据类型的概念:
# 在Python里数据都有各自对应的类型:# 数字类型: 整数型int 浮点型 float 复数 complex
print(45) # int整数类型
print(3.1415) # float类型
print((-1) ** 0.5) # complex类型# 字符串类型: 其实就是一段普通的文字
# python里的字符串要求使用一对单引号,或者双引号来包裹
print('今天天气好晴朗,处处好风光呀好风光')
print("56")# 布尔类型:用来表示 真假/对错
# 布尔类型里一共只有两个值,一个是 True,另一个是 False
print(4 > 3) # True
print(1 > 5) # False# 列表类型
names = ['廉颇', '小乔', '妲己', '孙尚香', '甄姬', '安琪拉']
# 字典类型
person = {'name': '貂蝉', 'age': 18, 'addr': '三国', '身高': '166cm'}
# 元组类型
nums = (1, 8, 9, 2, 3, 0)
# 集合类型
x = {9, 'hello', 'hi', 'good', True}print(True)
查看类型,使用type内置类
a = 34
b = 'hello'
c = True
d = ['廉颇', '小乔', '妲己', '孙尚香', '甄姬', '安琪拉']# 使用type内置类可以查看一个变量对应的数据类型
print(type(a)) # <class 'int'> 整数型
print(type(b)) # <class 'str'> 字符串类型
print(type(c)) # <class 'bool'> 布尔类型
print(type(d)) # <class 'list'> 列表类型print(type(3.14)) # <class 'float'> 浮点类型# 在Python里,变量是没有数据类型的,我们所说变量的数据类型,其实是变量对应的值的数据类型
e = 23
print(type(e)) # <class 'int'>
f = "hello"
print(type(f)) # <class 'str'>
标识符
标识符:变量,模块名,函数名,类名
标识符的命名规则与规范:
规则:
- 由数字、字母和_组成,不能以数字开头
- 严格区分大小写(计算机编程里,一共有52个英语字母)
- 不能使用关键字
关键字:在Python语言里,有特殊含义的单词,例如 if/for/else/while/try等等… …
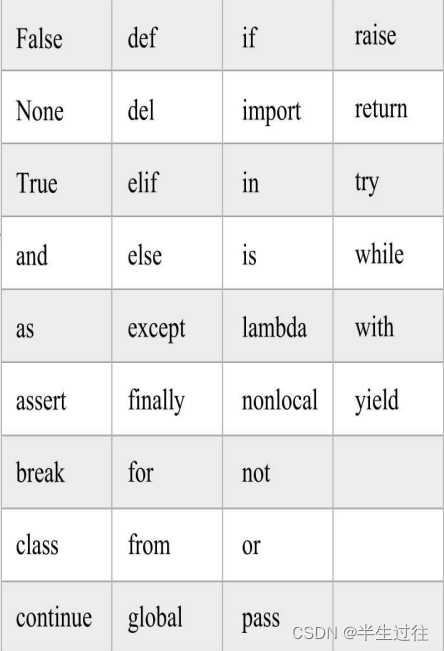
关键字:
False None True and as assert break class continue def del elif else except finally for from global if import in is lambda nonlocal not or pass raise return try while with yield
规范: 建议遵守,遵守规范会显得专业,并且代码易读- 顾名思义
- 遵守一定的命名规范
- 小驼峰命名法:第一个单词的首字母小写,以后每个单词的首字母都大写 userNameAndPassword
- 大驼峰命名法: 每个单词的首字母都大写 PersonModel
- 使用下划线连接: user_name_and_password
在Python里的变量、函数和模块名使用下划线连接; Python里的类名使用大驼峰命名法
输出输入语句
Python里使用 print内置函数 来输出内容
print(value, …, sep=’ ‘, end=’\n’, file=sys.stdout, flush=False)
sep 参数用来表示输出时,每个值之间使用哪种字符作为分隔。默认使用空格作为分隔符 end
当执行完一个print语句以后,接下来要输出的字符。默认 \n 表示换行
python里使用 input 内置函数接收用户的输入 input() ==> 括号里写提示信息 定义一个变量可以保存用户输入的内容
password = input(“请输入内容”)
print(password)
format函数的语法及用法
语法:‘{}’.format()
用法:用于格式化字符串。可以接受无限个参数,可以指定顺序。返回结果为字符串
# 不设置位置,按默认顺序(从左到右)输出。print('学习{}中的{}函数'.format('python','format')) # '学习python中的format函数'#指定顺序
print('学习{1}中的{0}函数'.format('format','python')) #'学习python中的format函数'# 设置参数
list1 = ['hello','say','world','s']
print('LiMing {0[1]}{0[3]} {0[0]} to {0[2]}'.format(list1)) # 'LiMing says hello to world'list2 = ['hello','say']
list3 = ['world','s']
print('LiMing {0[1]}{1[1]} {0[0]} to {1[0]}'.format(list2,list3)) # 'LiMing says hello to world'# {变量名}
z = '大家好,我是{name},我今年{age}岁了,我来自{addr}'.format(age=18, name='jack', addr='襄阳')
print(z) # 大家好,我是jack,我今年18岁了,我来自襄阳# 混合使用 {数字} {变量}
a = '大家好,我是{name},我今年{1}岁了,我来自{0}'.format('泰国', 23, name='tony')
print(a) # 大家好,我是tony,我今年23岁了,我来自泰国# {}什么都不写 {数字} 不能混合使用d = ['zhangsan', 18, '上海', 180]
# b = '大家好,我是{},我今年{}岁了,我来自{},身高{}cm'.format(d[0], d[1], d[2], d[3])
b = '大家好,我是{},我今年{}岁了,我来自{},身高{}cm'.format(*d)
print(b) # 大家好,我是zhangsan,我今年18岁了,我来自上海,身高180cminfo = {'name': 'chris', 'age': 23, 'addr': '北京', 'height': 190}
c = '大家好,我是{name},我来自{addr},身高{height}cm,我今年{age}岁了'.format(**info)
print(c) # 大家好,我是chris,我来自北京,身高190cm,我今年23岁了#同时使用元组和字典传参
name=["卡卡罗特","界王拳"]
names={"nickname":"孙君","skill":"元气弹"}
print("我是{0},我的绝招是{skill}".format(*name,**names)) # 我是卡卡罗特,我的绝招是元气弹
print("我是{nickname},我的绝招是{1}".format(*name,**names)) # 我是孙君,我的绝招是界王拳#同时使用位置参数,元组,关键字参数,字典传参。
#注意位置参数要在关键数参数前面
a=["卡卡罗特"]
dic={"name":"超级赛亚人"}
print("我是{0},我也是{0},因为我是正义的战士,所以我变成了{name}".format("卡卡罗特",*a,**dic)) # 我是卡卡罗特,我也是卡卡罗特,因为我是正义的战士,所以我变成了超级赛亚人数字格式化
保留小数点
#保留两位小数点 print( '{:.2f}'.format(314.541) ) # 314.54#保留一位小数点并携带正负符号 print( '{:+.1f}'.format(1.2684) ) # +1.3print('{:+.1f}'.format(-45.62556)) # -45.6#不保留小数点 print('{:.0f}'.format(-45.62556)) # -46#说明:加上‘+’可以将数字的符号正确输出百分比格式
#保留两位小数点的百分比 print('{:.2%}'.format(0.54036) ) # 54.04%#不保留小数点的百分比 print( '{:.0%}'.format(0.54036)) # 54%转进制
#b二进制,>右对齐,长度为20 print('{:>20b}'.format(23)) # ' 10111'#d十进制,<左对齐,长度为15 print( '{:<15d}'.format(892)) # '892 '#x十六进制,^居中对齐,长度为10 print( '{:^10x}'.format(16894)) # ' 41fe ' #o八进制,^居中对齐,长度为10 print('{:^10o}'.format(1394)) # ' 2562 '
数据类型的转换
类型转换 将一个类型的数据转换为其他类型的数据
- int ==> str
- str ==> int
- bool ==> int
- int ==> float
# 数字0,空字符串 ''/"",空列表[],空元组(),空字典{},空集合set(),空数据None会被转换成为False
s = set() # 空集合
print(bool(s))
运算符
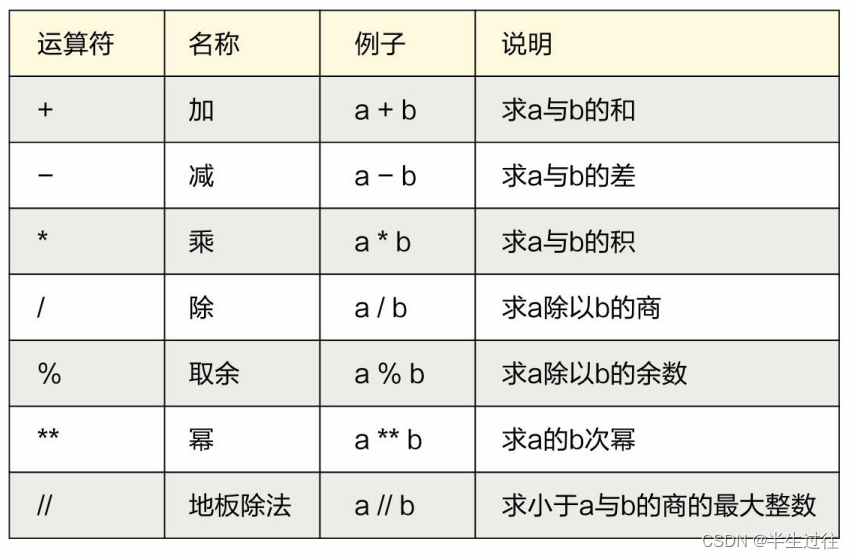
算数运算符
- 加 +
- 减 -
- 乘 *
- 除 /
- 幂运算 **
- 整除 //
- 取余(取模)运算 %
# true 可以当作1 false 可以当作0
print(1 + true) # 2
print(1 + false) # 1
print(1 + 1) # 2
print(4 - 2) # 2
print(3 * 2) # 6# 在Python3里,两个整数相除,得到的结果会是一个浮点数
print(6 / 2) # 3.0
print(9 / 2) # 4.5print(3 ** 3) # 27
print(81 ** (1 / 2)) # 9.0print(10 / 3) # 3.333333333333333
print(10 // 3) # 3 整除
print(-5 // 2) # -2.5 ==> -3 争取,向下取整print(10 % 3) # 1 取余,只取余数部分# 字符串里有限度的支持加法和乘法运算符# 加法运算符:只能用于两个字符串类型的数据,用来拼接两个字符串
print('hello' + 'world') # 将多个字符串拼接为一个字符串
# 乘法运算符:可以用于数字和字符串之间,用来将一个字符串重复多次
print('hello' * 2) # hellohello# -a 对于a 是取反
a = 1
print(-a) # -1
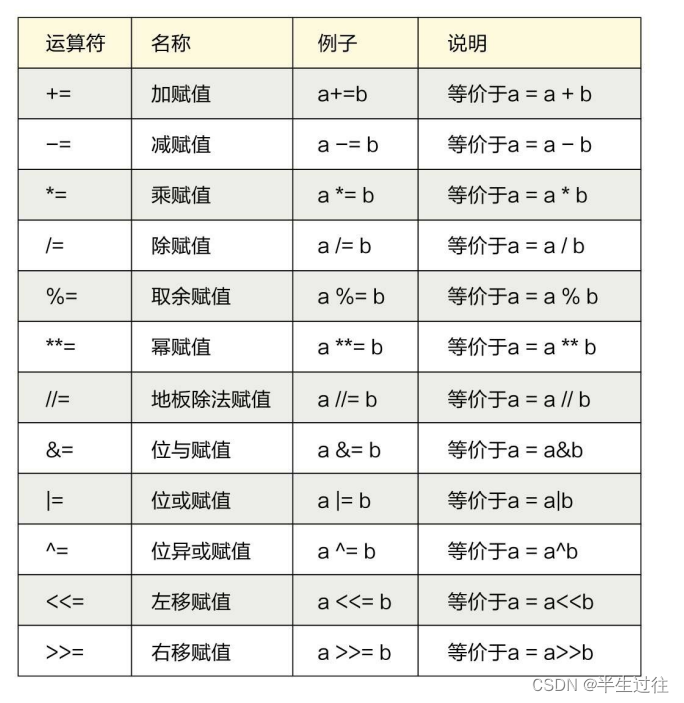
赋值运算符的特殊场景
# 等号连接的变量可以传递赋值
a = b = c = d = 'hello'
print(a, b, c, d) # hello hello hello hello
拆包
m, n = 3, 5 # 拆包
print(m, n) # 3 5
x = 'hello', 'good', 'yes'
print(x) # ('hello', 'good', 'yes')# 拆包时,变量的个数和值的个数不一致,会报错
# y, z = 1, 2, 3, 4, 5
# print(y, z)
# o, p, q = 4, 2
# print(o, p, q)
# Traceback (most recent call last):
# File "........py", line 14, in <module>
# y, z = 1, 2, 3, 4, 5
# ^^^^
# ValueError: too many values to unpack (expected 2)*表示可变长度
o, p, *q = 1, 2, 3, 4, 5, 6
print(o, p, q) # 1 2 [3, 4, 5, 6]
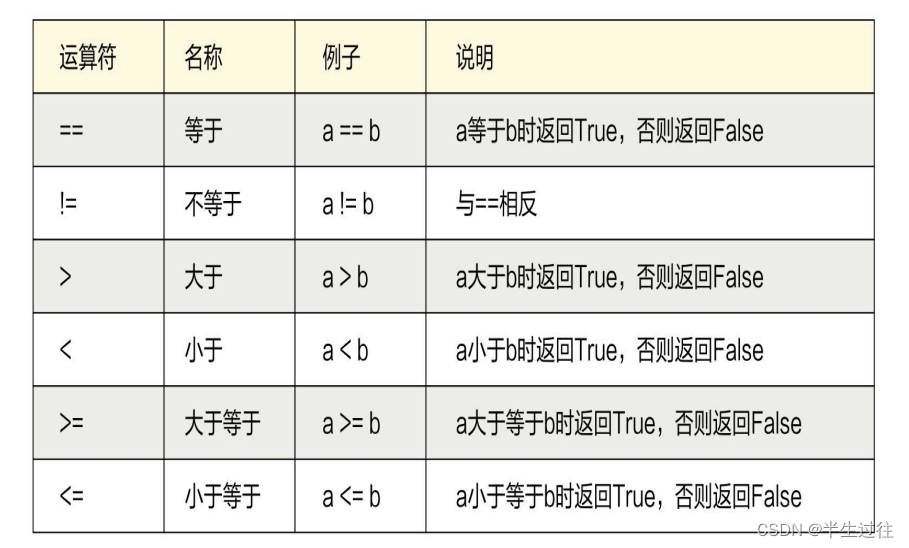
比较运算符
- 大于 >
- 小于 <
- 大于等于 >=
- 小于等于 <=
- 不等于 !=
<> - 等等与 ==
浮点数 和 整数 也可以比较
print(1.0 == 1) # True
print(1.0 != 1) # False
print(2 > 1) # True
print(2 < 4) # True
print(4 >= 3) # True
print(4 <= 9) # True
print(5 != 6) # True
print('hello' == 'hello') # True# 比较运算符在字符串里的使用
# 字符串之间使用比较运算符,会根据各个字符的编码值逐一进行比较
# ASCII码表
print('a' > 'b') # False 97 > 98
print('abc' > 'b') # False 97 > 98# 数字和字符串之间,做 == 运算的结果是False,做 != 结果是True,不支持其他的比较运算
# print('a' > 90)
print('a' == 90) # False
print('a' != 97) # True
逻辑运算符 与 短路
- 逻辑与 and
- 逻辑或 or
- 逻辑非 not
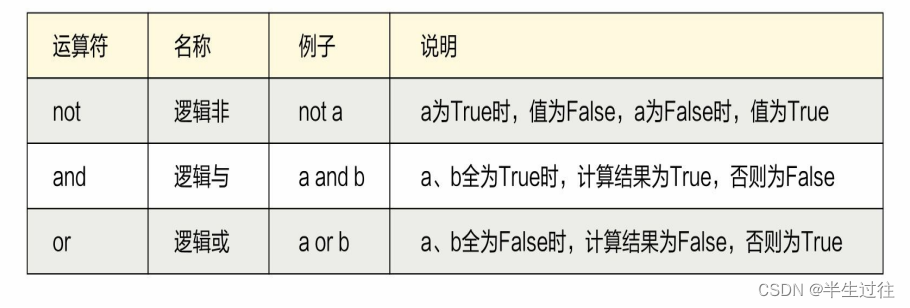
#逻辑与规则:只要有一个运算数是False,结果就是False;只有所有的运算数都是True,结果才是True
print(2 > 1 and 5 > 3 and 10 > 2) # True
print(3 > 2 and 5 < 4 and 6 > 1) # False# 逻辑或规则:只要有一个运算数是True,结果就是True;只有所有的运算数都是False,结果才是False
print(3 > 9 or 4 < 7 or 10 < 3) # True
print(3 > 5 or 4 < 2 or 8 < 7) # False# 逻辑非运算:True ==> False False ==> True
print(not (5 > 2)) # False逻辑与运算的短路问题
# 逻辑与运算,只有所有的运算数都是True,结果才为True
# 只要有一个运算数是False,结果就是False
4 > 3 and print('hello world') # hello world
4 < 3 and print('你好世界') # 逻辑与运算的短路问题 不打印# 逻辑或运算,只有所有的运算数都是False,结果才是False
# 只要有一个运算数是True,结果就是True
4 > 3 or print('哈哈哈') # 逻辑或运算的短路问题 不打印
4 < 3 or print('嘿嘿嘿') # 嘿嘿嘿# 逻辑运算的结果,不一定是布尔值
# 逻辑与运算做取值时,取第一个为False的值;如果所有的运算数都是True,取最后一个值
print(3 and 5 and 0 and 'hello') # 0
print('good' and 'yes' and 'ok' and 100) # 100# 逻辑或运算做取值时,取第一个为True的值;如果所有的运算数都是False,取最后一个值
print(0 or [] or 'lisi' or 5 or 'ok') # lisi
print(0 or [] or {} or ()) # ()
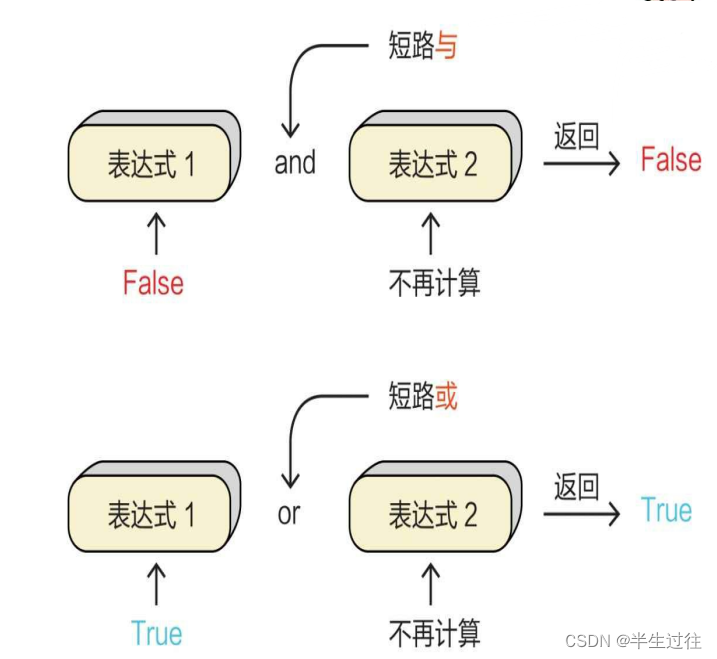
逻辑运算符规则:
- 逻辑与运算:
1.只要有一个运算数是False,结果就是False;只有所有的运算数都是True,结果才是True
2.短路:只要遇到了False,就停止,不再继续执行了 取值:取第一个为False,如果所有的运算数都是True,取最后一个运算数
- 逻辑或运算:
1.只要有一个运算数是True,结果就是True;只有所有的运算数都是False,结果才是False
2.短路:只要遇到了True,就停止,不再继续执行了 取值:取第一个为True的值,如果所有的运算数都是False,取最后一个运算数
位运算符
按位与& 按位或| 按位异或^ 按位左移<< 按位右移>> 按位取反~
按位取反运算归纳总结了一个公式:
~a = (a +1) ×-1
如果a为十进制数178,则~a为十进制数-179;如果a为十进制数-20,则~a为十进制数19
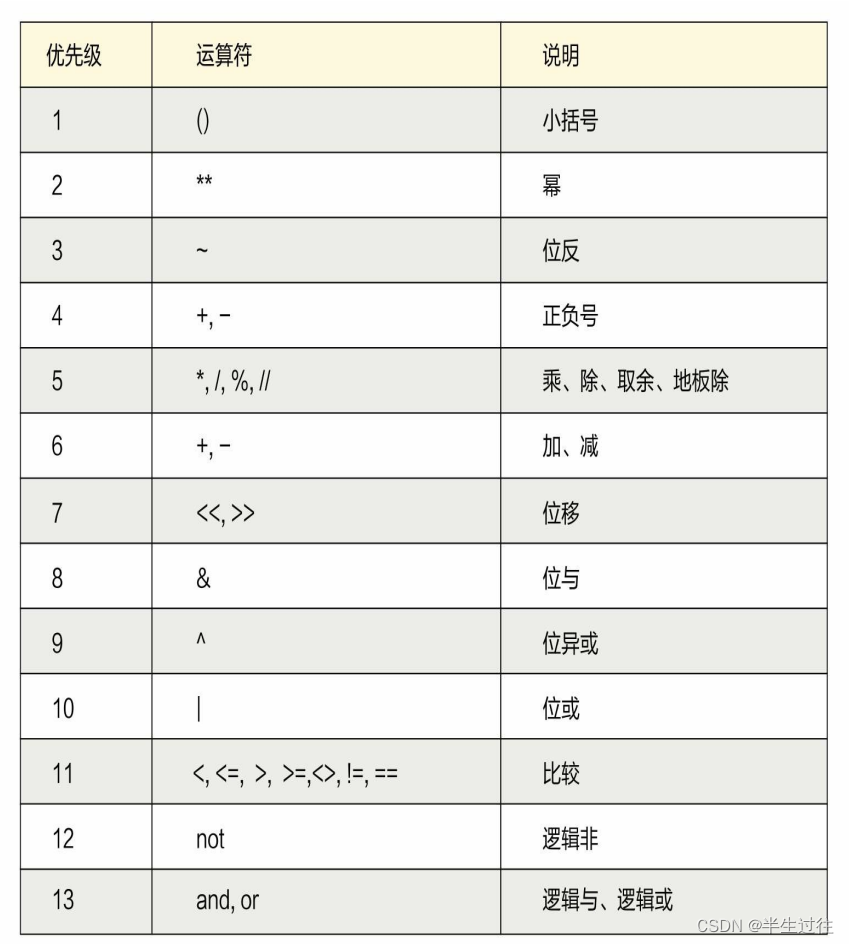
运算符优先级
在位运算优先级中,优先级从高到低大体是:
算术运算符→位运算符→关系运算符→逻辑运算符→赋值运算符。
程序流程控制
分支语句
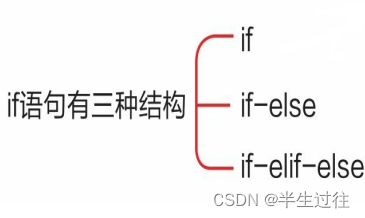
if 语法:
if 判断条件:条件成立时,执行的代码if…else 语法:
if 判断条件:条件成立时执行的代码else:条件不成立时执行的代码if…elif…else 语法:
if 判断条件:条件成立时执行的代码elif:条件成立时执行的代码else:条件都不成立时执行的代码三元运算 语法:
条件成立 if 判断条件 else条件不成立时
if 语法:

if…else语法:

if…elif…else语法:

pass 占位
pass 关键字在Python里没有意义,只是单纯的用来占位,保证语句的完整性 可用在任何语法中
pass 语法:
if 条件判断:pass
循环语句 while 和 for
while 循环 语法: 【注:else 可以省略不写】
while 判断条件::条件成立时执行的代码else:条件不成立时执行的代码for… in … 语法::
【注:
else 可以省略不写
in 的后面必须要是一个可迭代对象!!!
目前接触的可迭代对象: 字符串、列表、字典、元组、集合、range
range 内置类用来生成指定区间的整数序列(列表)
】for 变量 in可迭代对象:条件成立时执行的代码else:条件不成立时执行的代码
while 语法:

for… in … 语法语法:

代码运用 打印九九乘法表
j = 0
while j < 9:j += 1 # j = 3;i = 0 # i=0;while i < j:i += 1 # i=2;print(i, '*', j, '=', (i * j), sep="", end="\t")print()
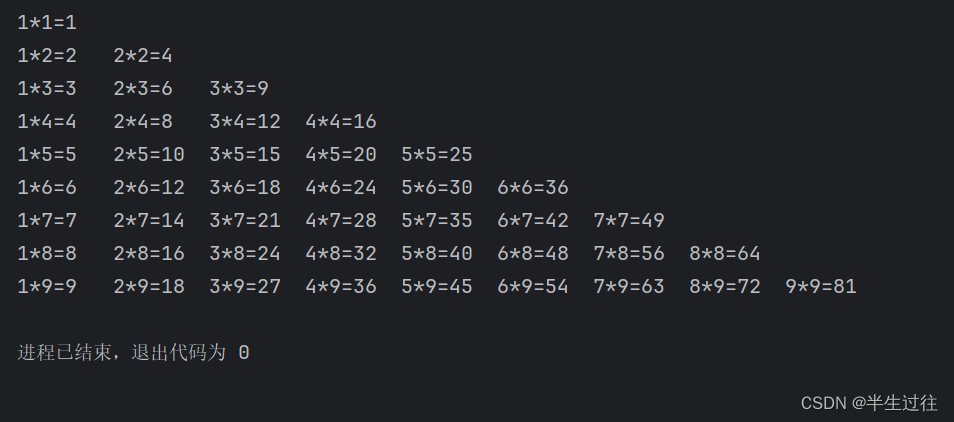
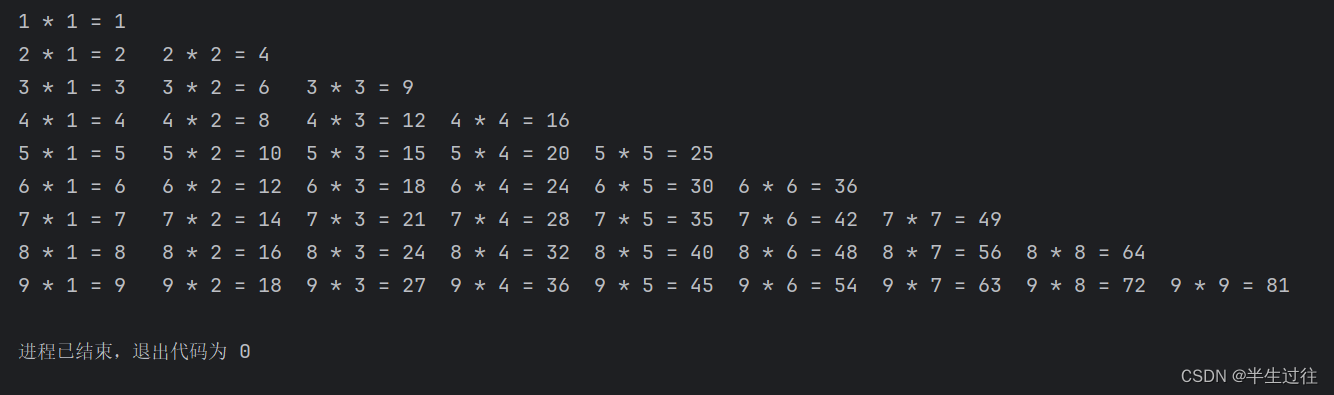
for i in range(1, 10):for e in range(1, i + 1):print(i, '*', e, "=", int(i) * int(e), end="\t")print()
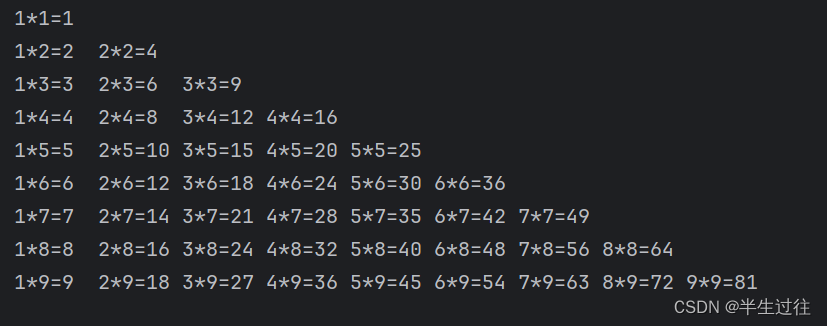
一行代码快速 打印九九乘法表
print('\n'.join([' '.join(['%s*%s=%-2s' % (y, x, x*y) for y in range(1, x+1)]) for x in range(1, 10)]))
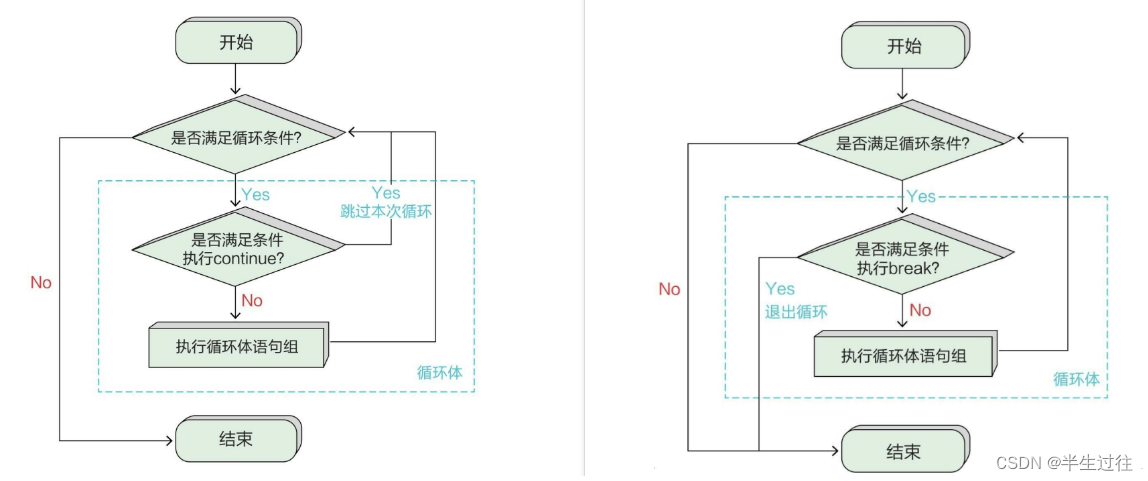
跳出语句 break continue 使用
跳转语句能够改变程序的执行顺序,包括break、continue和return。
break和continue用于循环体中,而return用于函数中。
break:用来结束整个循环,强行退出循环体,不再执行循环体中剩余的语句。
continue:用来结束本轮循环,开启下一轮循环,直到循环完成
容器类型的数据
Python内置的数据类型如序列(列表、元组等)、集合和字典等可以容纳多项数据,我们称它们为容器类型的数据
序列包括列表(list)、字符串(str)、元组(tuple)和字节序列(bytes)等
序列中的元素都是有序的,每一个元素都带有序号,这个序号叫作索引。索引有正值索引和负值索引之分。
字符串
如果要使用字符串表示一篇文章,其中包含了换行、缩进等排版字符,则可以使用长字符串表示。对于长字符串,要使用三个单引号(‘’')或三个双引号(""")括起来。
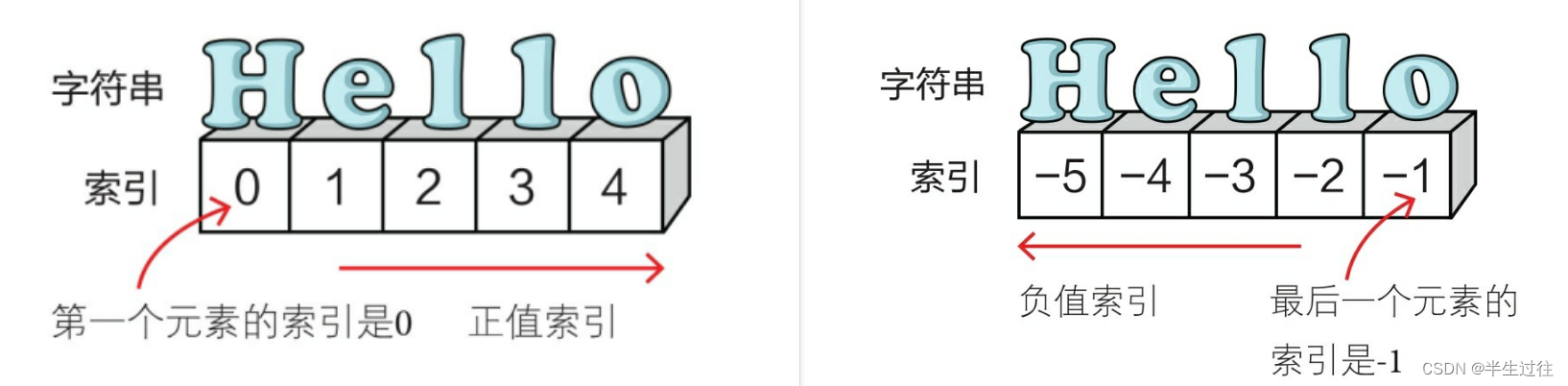
# 在计算机里,下标都是从 0 开始的。-1最后一个
# 字符串是不可变的数据类型
# 对于字符串的任何操作,都不会改变原有的字符串!!!
word = 'Hello' # 字符串:一个一个的字符串在一起
# 可以通过下标来获取或者修改指定位置的数据
print(word[4]) # o
print(word[-1]) # oprint(word[30])
# .若索引超过范围,则会发生IndexError错误
# Traceback (most recent call last):
# File "....py", line 9, in <module>
# print(word[30])
# ~~~~^^^^
# IndexError: string index out of range加和乘操作
加(+)和乘()运算符也可以用于序列中的元素操作。加(+)运算符可以将两个序列连接起来,乘()运算符可以将两个序列重复多次
a = "Hello"
b = "World"print(a * 2 ) # HelloHello
print(a +" "+ b ) # Hello World切片操作
切片 语法:str[start:end:step]
start是开始索引end是结束索引,step是步长(切片时获取的元素的间隔,可以为正整数,也可以为负整数。步长不能为0理解为间隔。每隔 step-1 个取一次, step 为负数,表示从右往左获取)注意:切下的小切片包括start位置的元素,但不包括end位置的元素,start和end都可以省略。
m = 'zxcvbnm'
print(m[5]) # m[index] ==> 获取指定下标上的数据 打印n# 切片语法 m[start:end:step]
# 包含start,不包含end
# step 指的是步长,理解为间隔。每隔 step-1 个取一次
# step 为负数,表示从右往左获取
print(m[2:5]) # 包含start,不包含end 打印cvb
print(m[2:]) # 如果只设置了start,会"截取"到最后 打印cvbnm
print(m[:5]) # 如果值设置了end,会从头开始"截取" 打印zxcvb# 步长默认为 1
print(m[1:5:2]) # xv
print(m[1:6:2]) # xvn
print(m[1:5:1]) # xcvb
# print(m[3:15:0]) # 步长不能为0
print('------------------')
print(m[5:1:-1]) # nbvc
print(m[::]) # zxcvbnm 从头到尾复制
print(m[::-1]) # mnbvcxz 从尾到头倒叙# start和end如果是负数,表示从右边数
print(m[-5:-2]) # cvb
字符串常见的操作
max() 用于返回最后一个元素
min() 用于返回第一个元素
len() 获取长度
str—a指定检索的字符串
beg—开始检索,默认为0
end—结束检索,默认为字符串的长度
- 可以获取指定字符的下标 带有 r 的从右边开始查找 否则左边查找 查到第一个就停止
find(str,start,end)
index(str,start,end)
rfind(str,start,end)
rindex(str,start,end)
判断
startswith(str, start) 是否以指定的子字符串开始
endswith(str, start) 是否以指定的子字符串结束
isalpha() 用于判断字符串中是否只含有字母。
isdigit() 用来判断字符串是否全部是数字
isalnum() 判断是否由数字和字母组成
isspace() 判断字符串是否只含有空字符
- 返回结果为True的两个必要条件
①字符串至少含有一个字符
②字符串是空字符,空字符可为可为空格(’ ‘)、横向制表符(’\t’)、回车符(‘\r’)、换行(‘\n’)、换页(‘\f’)等其他情况返回结果为False
替换内容
- replace(old ,new)用来替换字符串,把old替换成 new
计算出现次数
- count(搜索的子字符串, start, end )
- start — 字符串开始搜索的位置,默认为第一个字符,第一个字符索引值为0
- end — 字符串中结束搜索的位置,字符中第一个字符的索引为0,。默认为字符串的最后一个位置。
- 返回值 — 返回子字符串在字符串中出现的次数
切割字符串
- split(str, num) 从左向右寻找
- str :(可选)指定分隔符,默认为空字符
num :(可选)分割次数,默认 -1,即分割所有
不给参数时,「默认」以「空字符串」作为分隔符
分隔符必须是「字符串类型」或者不指定,否则会报错 TypeError: must be str or None- rsplit(str, num) 从右向左寻找 同上
- splitlines()
- 按照行(‘\r’, ‘\r\n’,‘ \n’)分隔,返回一个包含各行作为元素的列表,不用传参
如果是‘\n\r’,则会识别成一个空元素- partition() 从左往右找分隔符
- rpartition() 从右往左找分隔符
修改⼤⼩写
- capitalize() 第⼀个单词的⾸字⺟⼤写。
-title() 每个单词的⾸字⺟⼤写。
-upper() 所有都变成⼤写
-lower() 所有都变成⼩写。
空格处理
- ljust() 返回指定⻓度的字符串,并在右侧使⽤空⽩字符补全(左对⻬)。
-rjust() 返回指定⻓度的字符串,并在左侧使⽤空⽩字符补全(右对⻬)
-center() 返回指定⻓度的字符串,并在两端使⽤空⽩字符补全(居中对⻬)
-lstrip() 删除左边的空⽩字符
-rstrip() 删除右边的空⽩字符。
-strip() 删除两边的空⽩字符。
字符串拼接
- 字符.join(参数) 把参数进⾏遍历,取出参数⾥的每⼀项,然后再在后⾯加上字符,最后一个不添加
word = 'Hello'
# max()函数用于返回最后一个元素
# min()函数用于返回第一个元素
# len()函数获取长度
print(max(word)) # o
print(min(word)) # H
print(len(word)) # 5
x = 'abcdefghijklmndsfasdfsadfadl'# 查找内容相关的方法 find/index/rfind/rindex 可以获取指定字符的下标
print(x.find('l')) # 11
print(x.index('l')) # 11print(x.find('p')) # -1 如果字符在字符串里不存在,结果是 -1
# print(x.index('p')) # 使用index,如果字符不存在,会报错print(x.find('l', 4, 9)) # -1print(x.rfind('l')) # 27
print(x.rindex('l'))# 27# startswith,endswith,isalpha,isdigit,isalnum,isspace
# is开头的是判断,结果是一个布尔类型
print('hello'.startswith('he')) # True
print('hello'.endswith('o')) # True
print('he45llo'.isalpha()) # False alpha字母
print('good'.isdigit()) # False
print('123'.isdigit()) # True
print('⁴'.isdigit()) # True
print('123⁴'.isdigit()) # True
print('3.14'.isdigit()) # False
print('⑴'.isdigit()) # False
print('(1)'.isdigit()) # False
print('+1'.isdigit()) # False
print('-1'.isdigit()) # False#「bytes」也是字符串的一种类型,它也可以使用 isdigit() ,并在纯数字的时候返回 True
byte1 = b'123'
print(type(byte1)) # <class 'bytes'>
print(byte1.isdigit()) # True
print(b'abc'.isdigit()) # False# alnum 判断是否由数字和字母组成
print('ab12hello'.isalnum()) # True
print('hello'.isalnum()) # True
print('1234'.isalnum()) # True
print('4 - 1'.isalnum()) # Falseprint('h o'.isspace()) # False# replace方法:用来替换字符串
word = 'hello'
m = word.replace('l', 'x') # replace 将字符串里 l 替换成 x
print(word) # hello 字符串是不可变数据类型!!!
print(m) # hexxo 原来的字符串不会改变,而是生成一个新的字符串来保存替换后的结果# 切割字符串
a = "dlrblist"
a1 = a.split("l", 1)
print(a1) # ['d', 'rblist']b = "dlrblist"
b1 = b.rsplit("l", 1)
print(b1) # ['dlrb', 'ist']c = "hello\nworld\r\ndlrb\r你好\n\r世界"
c1 = c.splitlines()
print(c1) # ['hello', 'world', 'dlrb', '你好', '', '世界']p= "www.ilovefishc.com"
print(p.partition(".")) # ('www', '.', 'ilovefishc.com')
print(p.rpartition(".")) # ('www.ilovefishc', '.', 'com')
# 修改大小写# capitalize 让第一个单词的首字母大写
print('hello world.good morning\nyes'.capitalize())# Hello world.good morning# yes# upper 全大写
print('hello'.upper()) # HELLO# lower 全小写
print('WoRLd'.lower()) # 面向对象里,我们称之为方法 world# title 每个单词的首字母大写
print('good morning'.title()) # Good Morning# 空格处理
# ljust(width,fillchar)
# width 长度 fillchar 填充字符,默认是空格
# 让字符串以指定长度显示,如果长度不够,默认在右边使用空格补齐
print('Monday'.ljust(10, '+')) # Monday++++
print('Tuesday'.rjust(12, '-')) # -----Tuesday
print('Wednesday'.center(20, '*')) # *****Wednesday******print('+++++apple+++'.lstrip('+')) # apple+++
print(' pear '.rstrip()) # pear
print(' banana '.strip()) # banana# 以某种固定格式显示的字符串,我们可以将它切割成为一个列表
x = 'zhangsan+lisi+wangwu+jack+tony+henry+chris'
names = x.split('+')
print(names) # ['zhangsan', 'lisi', 'wangwu', 'jack', 'tony', 'henry', 'chris']# 将列表转换成为字符串
fruits = ['apple', 'pear', 'peach', 'banana', 'orange', 'grape']
print('-'.join(fruits)) # apple-pear-peach-banana-orange-grape
print('*'.join('hello')) # iterable可迭代对象 h*e*l*l*o
print('+'.join(('yes', 'ok'))) # yes+ok# 字符串的运算符
# 字符串和字符串之间可以使用加法运算,作用是拼接两个字符串
# 字符串和数字之间可以使用乘法运算,目的是将指定的字符串重复多次
# 字符串和数字之间做 == 运算结果是False,做 != 运算,结果是True
# 字符串之间做比较运算,会逐个比较字符串的编码值
# 不支持其他的运算符
# count
a = "balala woo gaga"
print(a.count("a", 2)) # 4print(a.count("a",2,7)) # 2
# 字符串拼接join
mystr = 'a'
print(mystr.join('hxmdq')) #haxamadaq 把hxmd⼀个个取出,并在后⾯添加字符a. 最后的 q 保留,没有加 a
print(mystr.join(['hi','hello','good'])) #hiahelloagood 作⽤:可以把列表或者元组快速的转变成为字符串,并且以指定的字符分隔。
txt = '_'
print(txt.join(['hi','hello','good'])) #hi_hello_good
print(txt.join(('good','hi','hello'))) #good_hi_hell
成员测试
成员测试运算符有两个:in和not in
in用于测试是否包含某一个元素not in用于测试是否不包含某一个元素
a = "hello"
print("e" in a) # True
print("e" not in a) # False
常用的转义符
| 字符表示 | Unicode编码 | 说明 |
|---|---|---|
| \t | \u0009 | 水平制表符 |
| \n | \u000a | 换行 |
| \r | \U000d | 回车 |
\" | \u0022 | 双引号 |
\' | \u0027 | 单引号 |
| \ | \u005c | 反斜线 |
| r"内容" | 原始字符串中的\n 表示\和n 两个字符 |
列表
列表(list)是一种可变序列类型,我们可以追加、插入、删除和替换列表中的元素。
使用[ ]来表示一个列表,列表里的每一个数据我们称之为元素
元素之间使用逗号进行分割
和字符串一样,都可以使用下标来获取元素和对元素进行切片
同时,我们还可以使用下标来修改列表里的元素
也可以通过下标来实现切片
创建列表
创建列表有两种方法。
1、
list(iterable)函数:参数iterable是可迭代对象(字符串、列表、 元组、集合和字典等)。
2、[元素1,元素2,元素3,⋯]:指定具体的列表元素,元素之间以 逗号分隔,列表元素需要使用中括号括起来
添加元素
添加元素的方法
append() 在列表中追加单个元素,在列表的最后面追加一个数据extend() 在列表中追加多个元素使用 += 在列表中追加多个元素insert (index,object) 插入元素index 表示下标,在哪个位置插入数据object 表示对象,具体插入哪个数据
heros= ['阿珂', '嬴政', '韩信', '露娜', '后羿', '亚瑟', '李元芳']
heros1= ['阿珂', '嬴政', '韩信', '露娜', '后羿', '亚瑟', '李元芳']
heros2= ['阿珂', '嬴政', '韩信', '露娜', '后羿', '亚瑟', '李元芳']
heros3= ['阿珂', '嬴政', '韩信', '露娜']
heros4= ['后羿', '亚瑟', '李元芳']
#
heros.append('黄忠')
print(heros) # ['阿珂', '嬴政', '韩信', '露娜', '后羿', '亚瑟', '李元芳', '黄忠']# insert(index,object) 需要两个参数
# index 表示下标,在哪个位置插入数据
# object 表示对象,具体插入哪个数据
heros1.insert(3, '李白') # ['阿珂', '嬴政', '韩信', '李白', '露娜', '后羿', '亚瑟', '李元芳']
print(heros1)x = ['马可波罗', '米莱迪', '狄仁杰']
# extend(iterable) 需要一个可迭代对象
# A.extend(B) ==> 将可迭代对象 B 添加到 A 里
heros2.extend(x)
print(heros2) # ['阿珂', '嬴政', '韩信', '露娜', '后羿', '亚瑟', '李元芳', '马可波罗', '米莱迪', '狄仁杰']
print(x) # ['马可波罗', '米莱迪', '狄仁杰']heros3 += heros4
print(heros3) # ['阿珂', '嬴政', '韩信', '露娜', '后羿', '亚瑟', '李元芳']
替换 修改 元素
想替换列表中的元素时,将列表下标索引元素放在赋值符号(=) 的左边,进行赋值即可。
x = ['马可波罗', '米莱迪', '狄仁杰', '李白']
x[2] = '露娜'
print(x) # ['马可波罗', '米莱迪', '露娜', '李白']
列表删除和查询元素
删除数据有三个相关的方法
pop() 默认会删除列表里最后一个数据,并且返回这个数据 ,还可以传入index参数,用来删除指定位置上的数据 remove() 用来删除指定的元素如果找到匹配的元素x,则删除该元素,如果找到多个匹配的元素,则只删除第一个匹配的元素。如果数据在列表中不存在,会报错使用del 也可以删除一个指定数据,或者删除整个元素(毁尸灭迹)clear() 用来清空一个列表(还可以找到只是个空数据)
masters = ['王昭君', '甄姬', '貂蝉', '妲己', '小乔', '大乔']x = masters.pop(3)
print(masters) # ['王昭君', '甄姬', '貂蝉', '小乔', '大乔']# remove用来删除指定的元素
masters.remove('小乔')
# masters.remove('妲己')
print(masters) # ['王昭君', '甄姬', '貂蝉', '大乔']# 使用del 也可以删除一个数据
del masters[2]
print(masters) # ['王昭君', '甄姬', '大乔']# clear 用来清空一个列表
masters.clear()
print(masters)# a = 100
# del a
# print(a)
# 会报错
# Traceback (most recent call last):
# File "…….py", line 24, in <module>
# print(a)
# ^
# NameError: name 'a' is not definedtanks = ['亚瑟', '程咬金', '盾山', '张飞', '廉颇', '程咬金']
# 查询相关的方法
print(tanks.index('盾山')) # 2
# print(tanks.index('庄周')) 如果元素不存在,会报错
print(tanks.count('程咬金')) # 2
# in 运算符
print('张飞' in tanks) # True
print('苏烈' in tanks) # False遍历 冒泡排序
将所欲的数据都访问一遍。遍历针对的是可迭代对象
# while循环遍历 / for...in 循环遍历
killers = ['李白', '兰陵王', '韩信', '赵云', '阿珂', '孙悟空']# for...in循环的本质就是不断的调用迭代器的 next 方法查找下一个数据
for k in killers:print(k)i = 0
while i < len(killers):print(killers[i])i += 1
nums = [1, 2, 3, 4, 5, 6, 7, 9, 8]count = 0
j = 0
# 第一趟比较时, j=0,多比价了0次
# 第二趟比较时, j=1,多比较了1次
# 第三趟比较时, j=2,多比价了2次
while j < len(nums) - 1:# 在每一趟里都定义一个flagflag = True # 假设每一趟都没有换行i = 0while i < len(nums) - 1 - j:count += 1if nums[i] > nums[i + 1]:# 只要交换了,假设就不成立flag = Falsenums[i], nums[i + 1] = nums[i + 1], nums[i]i += 1if flag:# 这一趟走完以后,flag依然是True,说明这一趟没有进行过数据交换breakj += 1print(nums) # [1, 2, 3, 4, 5, 6, 7, 8, 9]print('比较了%d次' % count) # 比较了15次
排序
nums1 = [6, 5, 3, 1, 8, 7, 2, 4]nums2 = [6, 5, 3, 1, 8, 7, 2, 4]# 调用列表的 sort 方法可以直接对列表进行排序# 直接对原有的列表进行排序nums3 = nums1nums1.sort()nums3.sort(reverse=True)print(nums1) # [1, 2, 3, 4, 5, 6, 7, 8]print(nums3) # [8, 7, 6, 5, 4, 3, 2, 1]# 内置函数sorted,不会改变原有的列表数据,会生成一个新的有序数据x = sorted(nums2)print(nums2) # [6, 5, 3, 1, 8, 7, 2, 4]print(x) # [1, 2, 3, 4, 5, 6, 7, 8]
列表随机 嵌套 与创建
import random# 一个学校,有3个办公室,现在有10位老师等待工位的分配,请编写程序,完成随机的分配
teachers = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J']
rooms = [[], [], []]for teacher in teachers:room = random.choice(rooms) # choice 从列表里随机选择一个数据room.append(teacher)print(rooms)
# 第0个房间有3个人,分别是...# 带下标我们一般都使用while
# for循环也可以带下标
for i, room in enumerate(rooms):print('房间%d里一共有%d个老师,分别是:' % (i, len(room)),end='')for teacher in room:print(teacher, end=' ')print()# 列表推导式作用是使用简单的语法创建一个列表
nums = [i for i in range(10)]
print(nums) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]x = [i for i in range(10) if i % 2]
print(x) # [1, 3, 5, 7, 9]# points 是一个列表。这个列表里的元素都是元组
points = [(x, y) for x in range(5, 7) for y in range(10, 12)]
print(points) # [(5, 10), (5, 11), (6, 10), (6, 11)]# 了解即可
# 请写出一段 Python 代码实现分组一个 list 里面的元素,比如 [1,2,3,...100]变成 [[1,2,3],[4,5,6]....]
m = [i for i in range(1, 21)]
print(m) # [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20]
# m[0:3] j ==> 0
# m[3:6] j ==> 3
# j ==> 6n = [m[j:j + 3] for j in range(0, 20, 3)]
print(n) # [[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12], [13, 14, 15], [16, 17, 18], [19, 20]]拷贝 复制
浅拷贝
赋值自带copy()方法,引入 import copy copy.copy()深拷贝
引入 import copy copy.deepcopy()
1、通过直接赋值的方式
old_list = [1, 2, 3]new_list = old_listprint(id(old_list), id(new_list)) # 1530306843208 1530306843208old_list.append(6)print(old_list, new_list) # [1, 2, 3, 6] [1, 2, 3, 6]print(id(old_list), id(new_list)) # 1530306843208 1530306843208# 可见结果是完全一样的(包括值和地址)2、浅拷贝:使用copy()
调用copy方法,可以复制一个列表
这个新列表和原有的列表内容一样,但是指向不同的内存空间
old_list = [1, 2, 3] new_list2 = old_list.copy() print(old_list, new_list2) # [1, 2, 3] [1, 2, 3] print(id(old_list), id(new_list2)) # 2089174717000 2089174717512old_list.append(6) new_list2.append("浅拷贝") print(old_list, new_list2) # [1, 2, 3, 6] [1, 2, 3, '浅拷贝'] print(id(old_list), id(new_list2)) # 2089174717000 2089174717512# 可以看出只有最开始的两个列表的值是一样的,其他没有什么联系,改变了某一个列表的值也不会对另一个列表产生影响(浅拷贝)再看另一个list包含另一个list的情况:old_list = [1, 2, 3, [4, 5]] new_list2 = old_list.copy() print(old_list, new_list2) # [1, 2, 3, [4, 5]] [1, 2, 3, [4, 5]] print(id(old_list), id(new_list2)) # 2722822378568 2722822943112old_list[3][0] = 5 print(old_list, new_list2) # [1, 2, 3, [5, 5]] [1, 2, 3, [5, 5]] print(id(old_list), id(new_list2)) # 2722822378568 2722822943112# 替换列表中的第四位元素中的第一个元素,可以看到地址都没有变化,但是值都变了,原因是浅拷贝只是拷贝了第四个元素,而不管里面的值。3、深拷贝:使用copy库中的deepcopy()
包含对象里面的子对象的拷贝,所以原始对象的改变不会造成深拷贝里任何子元素的改变
import copyold_list = [1, 2, 3, [4, 5]]new_list3 = copy.deepcopy(old_list)print(old_list, new_list3) # [1, 2, 3, [4, 5]] [1, 2, 3, [4, 5]]print(id(old_list), id(new_list3)) # 2145661532104 2145661482312old_list.append(6)print(old_list, new_list3) # [1, 2, 3, [4, 5], 6] [1, 2, 3, [4, 5]]print(id(old_list), id(new_list3)) # 2145661532104 2145661482312#该部分和浅拷贝一样,因为都对第一层的对象做了拷贝import copyold_list = [1, 2, 3, [4, 5]]new_list3 = copy.deepcopy(old_list)print(old_list, new_list3) # [1, 2, 3, [4, 5]] [1, 2, 3, [4, 5]]print(id(old_list), id(new_list3)) # 1208770731400 1208770803784old_list[3][0] = 5print(old_list, new_list3) # [1, 2, 3, [5, 5]] [1, 2, 3, [4, 5]]print(id(old_list), id(new_list3)) # 1208770731400 1208770803784#该部分和浅拷贝一样,因为都对第一层的对象做了拷贝
交换两个变量的值
a = 13
b = 20# 方法一:使用第三个变量实现
# c = b
# b = a
# a = c# 方法二:使用运算符来实现.只能是数字
# a = a + b
# b = a - b
# a = a - b# 方法三:使用异或运算符
# a = a ^ b
# b = a ^ b
# a = a ^ b# 方法四:使用Python特有
a, b = b, aprint(a) # 20
print(b) # 13
元组
元组和列表很像,都是用来保存多个数据
元素之间以逗号分隔。使用一对小括号()来表示一个元组,也可以省略小括号。
元组和列表的区别在于,列表是可变的,而元组是不可变数据类型
如果元组里只有一个元素,要在最后面加,
创建元组时有两种方法。tuple(iterable)函数:参数iterable是可迭代对象(字符串、列表、元组、集合和字典等)。 (元素1,元素2,元素3,⋯):指定具体的元组元素,元素之间以逗号分隔。对于元组元素,可以使用小括号括起来,也可以省略小括号。
words = ['hello', 'yes', 'good', 'hi'] # 列表,使用 [] 表示
nums = (9, 4, 3, 1, 9, 7, 6, 9, 3, 9) # 元组,使用 () 来表示
nums1 = 9, 4, 3, 1, 9, 7, 6, 9, 3, 9 # 元组,也可以省略小括号
print(type(nums)) # <class 'tuple'>
print(type(nums1)) # <class 'tuple'># 和列表一样,也是一个有序的存储数据的容器
# 可以通过下标来获取元素
print(nums[3]) # 1
# nums[3] = 40 # 元组是不可变数据类型,不能修改
print(nums.index(7)) # 5
print(nums.count(9)) # 4# 特殊情况:如何表示只有一个元素的元组?
# ages = (18) # 这种书写方式,ages是一个整数,并不是一个元组
ages1 = (18) # 这种书写方式,ages是一个整数,并不是一个元组
ages2 = (18,) # 如果元组里只有一个元素,要在最后面加 ,
print(type(ages1)) # <class 'int'>
print(type(ages2)) # <class 'tuple'># tuple 内置类
# print(tuple(18))
print(tuple('hello')) # ('h', 'e', 'l', 'l', 'o')# 怎样把列表转换成为元组?元组转换成为列表?
print(tuple(words)) # tuple list set 都是这样使用的 ('hello', 'yes', 'good', 'hi')
print(list(nums1)) # [9, 4, 3, 1, 9, 7, 6, 9, 3, 9]heights = ("189", "174", "170")
print('*'.join(heights)) # 189*174*170
print("".join(('h', 'e', 'l', 'l', 'o'))) # hello# 元组也可以遍历
for i in nums:print(i)j = 0
while j < len(nums):print(nums[j])j += 1
集合
创建集合
集合(set)是一种可迭代的、无序的、不能包含重复元素的容器类型的数据。
两种方式创建集合:
set(iterable)函数:参数iterable是可迭代对象(字符串、列表、元组、集合和字典等)。 {元素1,元素2,元素3,⋯}:指定具体的集合元素,元素之间以逗号分隔。对于集合元素,需要使用大括号括起来。
z = set("hello")
a = {10, 5, 7, 5, 4, 3}
b = {}print(z) # {'o', 'h', 'l', 'e'}
print(a) # {3, 4, 5, 7, 10}
print(type(b)) # <class 'dict'>
修改集合
add(elem):添加元素,如果元素已经存在,则不能添加,不会 抛出错误。
remove(elem):删除元素,如果元素不存在,则抛出错误。
clear():清除集合。
# 无序 每次打印都会不一样
ames = {'lisi', 'zhangsan', 'tony', 'jack'}
print(names) # {'zhangsan', 'lisi', 'jack', 'tony'}
# set 进行增删改查
names.add('阿珂') # 添加一个元素 无序 所以可能添加到任何地方,每次打印都会不一样
print(names) # {'zhangsan', 'jack', '阿珂', 'tony', 'lisi'}names.pop() # 删除一个 无序 随机删除每次的第一个
print(names) # {'jack', '阿珂', 'tony', 'lisi'}names.remove('jack') # 删除一个指定的元素 指定可以删除任何位置
print(names) # {'阿珂', 'tony', 'lisi'}print('jack' in names) # False# union 将多个集合合并生成一个新的集合
# A.update(B) 将B拼接到A里
names.update(['刘能', '赵四'])
print(names) # {'阿珂', '赵四', 'tony', 'lisi', '刘能'}# 空集合的表示方式不是 {} , {} 表示的是空字典
# 空集合 set()
names.clear() # 清空一个集合
print(names) # set()
使用 运算符
first = {'李白', '白居易', '李清照', '杜甫', '王昌龄', '王维', '孟浩然', '王安石'}
second = {'李商隐', '杜甫', '李白', '白居易', '岑参', '王昌龄'}# set 支持很多算数运算符
print(first - second) # A - B 求A和B的 差集
print(second - first)
print(first & second) # A & B 求A和B的 交集
print(first | second) # A | B 求A和B的 并集
print(first ^ second) # A ^ B 求A和B差集的并集
# print(first + second) # 会报错# {'孟浩然', '王维', '王安石', '李清照'}
# {'岑参', '李商隐'}
# {'白居易', '李白', '杜甫', '王昌龄'}
# {'岑参', '白居易', '孟浩然', '王安石', '李清照', '王昌龄', '李商隐', '王维', '李白', '杜甫'}
# {'岑参', '李清照', '李商隐', '王维', '孟浩然', '王安石'}# print(first + second) # 会报错
去重排序
nums = [5, 8, 7, 6, 4, 1, 3, 5, 1, 8, 4]# 去重
x = set(nums)
y = list(x)
# 排序
y.sort(reverse=True)
print(y) # [8, 7, 6, 5, 4, 3, 1]
字典
字典不仅可以保存值,还能对值进行描述
使用大括号来表示一个字典,不仅有值value,还有值的描述key
字典里的数据都是以键值对key:value的形式保留的 key和value之间使用冒号:来
连接 多个键值对之间使用逗号,来分割
字典里的key不允许重复,如果key重复了,后一个key对应的值会覆盖前一个
字典里的value可以是任意数据类型,但是key只能使用不可变数据类型,一般使用字符串
字典的数据在保存时,是无序的,不能通过下标来获取
使用字典的get方法,如果key不存在,会默认返回 None,而不报错
创建字典
创建字典。
1 dict()函数。
2 {key1:value1,key2:value2,…,key_n:value_n}:指定具体的字典键值对,键值对之间以逗号分隔,最后用大括号括起来。
增删改查
items():返回字典的所有键值对。
keys():返回字典键
values(): 返回字典值
person = {'name': 'zhangsan', 'age': 18, 'sex': 'boy'}print(person.items())# 返回字典的所有键值对# dict_items([('name', 'zhangsan'), ('age', 18), ('sex', 'boy')])print( list ( person.items() ) )# dict_items可以使用list()函数返回键值对列表# [('name', 'zhangsan'), ('age', 18), ('sex', 'boy')]print(person.keys())# 返回字典键 dict_keys# dict_keys(['name', 'age', 'sex'])print( list( person.keys() ) )# dict_keys可以使用list()函数返回键列表# ['name', 'age', 'sex']print(person.values())# 返回字典值 dict_values# dict_values(['zhangsan', 18, 'boy'])print( list( person.values() ) )# ddict_values可以使用list()函数返回值列表# ['zhangsan', 18, 'boy']
使用key获取到对应的value
使用字典的get()方法,如果key不存在,会默认返回 None,而不报错
get()方法如果根据key获取不到value,可以给定默认值
person = {'name': 'zhangsan', 'age': 18, 'x': 'y'}# 查找数据(字典的数据在保存时,是无序的,不能通过下标来获取)print(person['name']) # 使用key获取到对应的value zhangsan# print(person['height']) # 如果要查找的key不存在,会直接报错# 需求:获取一个不存在的key时,不报错,如果这个key不存在,使用默认值# 使用字典的get方法,如果key不存在,会默认返回 None,而不报错print(person.get('height')) # None# 如果根据key获取不到value,使用给定的默认值print(person.get('gender', 'female')) # femaleprint(person.get('name', 'lisi')) # zhangsan# 不会修改原数据print(person) # {'name': 'zhangsan', 'age': 18, 'x': 'y'}
直接使用key可以修改对应的value
如果key存在,是修改key对应的value;如果key在字典里不存在,会往字典里添加一个新的key:value
pop() : 把 键名 对应的键值对删除了,执行结果是被删除的value
popitem() : 删除一个元素,结果是被删除的这个元素组成的键值对
del … : del 字典[" 键名"] 把 键名 对应的键值对删除了
clear() : 用来清空一个字典
update() 方法 可以将两个字典合并成为一个字典
字典之间不支持加法运算
person = {'name': 'zhangsan', 'age': 18, 'addr': '襄阳'}# 直接使用key可以修改对应的valueperson['name'] = 'lisi' print(person) # {'name': 'lisi', 'age': 18, 'addr': '襄阳'}# 如果key存在,是修改key对应的value;# 如果key在字典里不存在,会往字典里添加一个新的key-valueperson['gender'] = 'female'print(person) # {'name': 'lisi', 'age': 18, 'addr': '襄阳', 'gender': 'female'}# pop()把name对应的键值对删除了,执行结果是被删除的valuex = person.pop('name')print(x) # lisiprint(person) # {'age': 18, 'addr': '襄阳', 'gender': 'female'}# popitem 删除一个元素,结果是被删除的这个元素组成的键值对result = person.popitem()print(result) # ('gender', 'female')print(person) # {'age': 18, 'addr': '襄阳'}# del ... del person['age']print(person) # {'addr': '襄阳'}person.clear() # 用来清空一个字典print(person) # {}person1 = {'name': 'zhangsan', 'age': 18}person2 = {'addr': '襄阳', 'height': 180}person1.update(person2)print(person1) # {'name': 'zhangsan', 'age': 18, 'addr': '襄阳', 'height': 180}# 字典之间不支持加法运算# print(person1 + person2)
遍历字典
person = {'name': 'zhangsan', 'age': 18, 'height': '180cm'}# 特殊在列表和元组是一个单一的数据,但是字典是键值对的形式# 第一种遍历方式: 直接for...in循环字典
for x in person: # for...in循环获取的是keyprint(x, '=', person[x])
# name = zhangsan
# age = 18
# height = 180cm# 第二种方式:获取到所有的key,然后再遍历key,根据key获取value
# print(person.keys()) # dict_keys(['name', 'age', 'height'])
for k in person.keys():print(k, '=', person[k])
# name = zhangsan
# age = 18
# height = 180cm# 第三种方式:获取到所有的value.
# 只能拿到值,不能拿到key
for v in person.values():print(v)
# zhangsan
# 18
# 180cm# 第四种遍历方式:
# print(person.items()) # dict_item([('name', 'zhangsan'), ('age', 18), ('height', '180cm')])# for item in person.items(): # 列表里的元素是元组,把元组当做整体进行遍历
# print(item[0], '=', item[1])for k, v in person.items():print(k, '=', v)
# name = zhangsan
# age = 18
# height = 180cm
练习
students = [{'name': '张三', 'age': 18, 'score': 52, 'tel': '1388888998', 'gender': 'female'},{'name': '李四', 'age': 28, 'score': 89, 'tel': '1388666666', 'gender': 'male'},{'name': '王五', 'age': 21, 'score': 95, 'tel': '1365588889', 'gender': 'unknown'},{'name': 'jerry', 'age': 20, 'score': 90, 'tel': '156666789', 'gender': 'unknown'},{'name': 'chris', 'age': 17, 'score': 98, 'tel': '13777775523', 'gender': 'male'},{'name': 'jack', 'age': 23, 'score': 52, 'tel': '13999999928', 'gender': 'female'},{'name': 'tony', 'age': 15, 'score': 98, 'tel': '1388888888', 'gender': 'unknown'}
]# (1) 统计不及格学生的个数
# (2) 打印不及格学生的名字和对应的成绩
# (3) 统计未成年学生的个数
# (4) 打印手机尾号是8的学生的名字
# (5) 打印最高分和对应的学生的名字
count = 0
teenager_count = 0
max_score = students[0]['score'] # 假设第0个学生的成绩是最高分
# max_index = 0 # 假设最高分的学生下标是 0
for i, student in enumerate(students):if student['score'] < 60:count += 1print('%s不及格,分数是%d' % (student['name'], student['score']))if student['age'] < 18:teenager_count += 1# if student['tel'].endswith('8'):if student['tel'][-1] == '8':print('%s的手机号以8结尾' % student['name'])if student['score'] > max_score: # 遍历时,发现了一个学生的成绩大于假设的最大数max_score = student['score']# max_index = i # 修改最高分的同时,把最高分的下标也修改print('不及格的学生有%d个' % count)
print('未成年的学生有%d个' % teenager_count)
print('最高成绩是%d' % max_score)for student in students:if student['score'] == max_score:print('最高分是%s' % student['name'])# print('最高分名字是%s' % students[max_index]['name'])# (6) 删除性别不明的所有学生(这个地方有个坑,跳不出来的话大家可以在群里套路,或者等老师的解答)
# 方法一,将不需要删除的数据添加到新列表
new_students = [x for x in students if x['gender'] != 'unknown']
print(new_students)# 方法二,使用for循环倒着删除要删除的数据,避免“坑”
i = 0
for i in range(len(students) - 1, -1, -1):if students[i]['gender'] == 'unknown':students.remove(students[i])
print(students)# 方法三,使用while循环删除需要删除的数据,并及时补齐因删除数据而导致的列表数据索引变化,避免漏删数据
i = 0
while i < len(students):if students[i]['gender'] == 'unknown':students.remove(students[i])i -= 1i += 1
print(students)# 方法四,遍历在新的列表操作,删除是在原来的列表操作(students[:]是studens的切片,所以修改students对切片无影响)
i = 0
for student in students[:]:if student['gender'] == 'unknown':students.remove(student)
print(students)# 方法五,使用内建函数filter()和匿名函数
new_students = filter(lambda x: x['gender'] != 'unknown', students)
print(list(new_students))print('-------------------------------')
# (7) 将列表按学生成绩从大到小排序(选做)
for j in range(0, len(students) - 1):for i in range(0, len(students) - 1 - j):if students[i]['score'] < students[i + 1]['score']:students[i], students[i + 1] = students[i + 1], students[i]
print(students)# 张三不及格,分数是52
# 张三的手机号以8结尾
# jack不及格,分数是52
# jack的手机号以8结尾
# tony的手机号以8结尾
# 不及格的学生有2个
# 未成年的学生有2个
# 最高成绩是98
# 最高分是chris
# 最高分是tony
# [{'name': '张三', 'age': 18, 'score': 52, 'tel': '1388888998', 'gender': 'female'}, {'name': '李四', 'age': 28, 'score': 89, 'tel': '1388666666', 'gender': 'male'}, {'name': 'chris', 'age': 17, 'score': 98, 'tel': '13777775523', 'gender': 'male'}, {'name': 'jack', 'age': 23, 'score': 52, 'tel': '13999999928', 'gender': 'female'}]
# [{'name': '张三', 'age': 18, 'score': 52, 'tel': '1388888998', 'gender': 'female'}, {'name': '李四', 'age': 28, 'score': 89, 'tel': '1388666666', 'gender': 'male'}, {'name': 'chris', 'age': 17, 'score': 98, 'tel': '13777775523', 'gender': 'male'}, {'name': 'jack', 'age': 23, 'score': 52, 'tel': '13999999928', 'gender': 'female'}]
# [{'name': '张三', 'age': 18, 'score': 52, 'tel': '1388888998', 'gender': 'female'}, {'name': '李四', 'age': 28, 'score': 89, 'tel': '1388666666', 'gender': 'male'}, {'name': 'chris', 'age': 17, 'score': 98, 'tel': '13777775523', 'gender': 'male'}, {'name': 'jack', 'age': 23, 'score': 52, 'tel': '13999999928', 'gender': 'female'}]
# [{'name': '张三', 'age': 18, 'score': 52, 'tel': '1388888998', 'gender': 'female'}, {'name': '李四', 'age': 28, 'score': 89, 'tel': '1388666666', 'gender': 'male'}, {'name': 'chris', 'age': 17, 'score': 98, 'tel': '13777775523', 'gender': 'male'}, {'name': 'jack', 'age': 23, 'score': 52, 'tel': '13999999928', 'gender': 'female'}]
# [{'name': '张三', 'age': 18, 'score': 52, 'tel': '1388888998', 'gender': 'female'}, {'name': '李四', 'age': 28, 'score': 89, 'tel': '1388666666', 'gender': 'male'}, {'name': 'chris', 'age': 17, 'score': 98, 'tel': '13777775523', 'gender': 'male'}, {'name': 'jack', 'age': 23, 'score': 52, 'tel': '13999999928', 'gender': 'female'}]
# -------------------------------
# [{'name': 'chris', 'age': 17, 'score': 98, 'tel': '13777775523', 'gender': 'male'}, {'name': '李四', 'age': 28, 'score': 89, 'tel': '1388666666', 'gender': 'male'}, {'name': '张三', 'age': 18, 'score': 52, 'tel': '1388888998', 'gender': 'female'}, {'name': 'jack', 'age': 23, 'score': 52, 'tel': '13999999928', 'gender': 'female'}]# 用三个元组表示三门学科的选课学生姓名(一个学生可以同时选多门课)sing = ('李白', '白居易', '李清照', '杜甫', '王昌龄', '王维', '孟浩然', '王安石')
dance = ('李商隐', '杜甫', '李白', '白居易', '岑参', '王昌龄')
rap = ('李清照', '刘禹锡', '岑参', '王昌龄', '苏轼', '王维', '李白')
# (1) 求选课学生总共有多少人
# 元组之间支持加法运算
# 使用集合set可以去重
total = set(sing + dance + rap)
print(len(total))# (2) 求只选了第一个学科的人的数量和对应的名字
sing_only = []
for p in sing:if p not in dance and p not in rap:sing_only.append(p)
print('只选择了第一个学科的有{}人,是{}'.format(len(sing_only), sing_only))# (3) 求只选了一门学科的学生的数量和对应的名字
# (4) 求只选了两门学科的学生的数量和对应的名字
# (5) 求只选了三门学生的学生的数量和对应的名字p_dict = {} # 空字典
all_persons = sing + dance + rap
print(all_persons)
# ('李白', '白居易', '李清照', '杜甫', '王昌龄', '王维', '孟浩然', '王安石', '李商隐', '杜甫', '李白', '白居易', '岑参', '王昌龄', '李清照', '刘禹锡', '岑参', '王昌龄', '苏轼', '王维', '李白')
for name in all_persons:if name not in p_dict:p_dict[name] = all_persons.count(name)
print(p_dict)for k, v in p_dict.items():if v == 1:print('报了一门的有', k)elif v == 2:print('报了两门的有', k)elif v == 3:print('报了三门的有', k)# 12
# 只选择了第一个学科的有2人,是['孟浩然', '王安石']
# ('李白', '白居易', '李清照', '杜甫', '王昌龄', '王维', '孟浩然', '王安石', '李商隐', '杜甫', '李白', '白居易', '岑参', '王昌龄', '李清照', '刘禹锡', '岑参', '王昌龄', '苏轼', '王维', '李白')
# {'李白': 3, '白居易': 2, '李清照': 2, '杜甫': 2, '王昌龄': 3, '王维': 2, '孟浩然': 1, '王安石': 1, '李商隐': 1, '岑参': 2, '刘禹锡': 1, '苏轼': 1}
# 报了三门的有 李白
# 报了两门的有 白居易
# 报了两门的有 李清照
# 报了两门的有 杜甫
# 报了三门的有 王昌龄
# 报了两门的有 王维
# 报了一门的有 孟浩然
# 报了一门的有 王安石
# 报了一门的有 李商隐
# 报了两门的有 岑参
# 报了一门的有 刘禹锡
# 报了一门的有 苏轼
转换相关的方法
将字符串转换为数字,可以使用int()和float()实现,如果成功则返回数字,否则引发异常
将数字转换为字符串,可以使用str()函数,
Python里有一个比较强大的内置函数eval,可以执行字符串里的代码
import jsonjson.dumps()把列表、元组、字典等转换成为JSON字符串json.loads() 将json字符串转换成为Python里的数据
| Python | JSON |
|---|---|
| True | true |
| False | false |
| 字符串 | 字符串 |
| 字典 | 对象 |
| 列表、元组串 | 数组 |
# 内置类 list tuple set
nums = [9, 8, 4, 3, 2, 1]
x = tuple(nums) # 使用tuple内置类转换成为元组
print(x) # (9, 8, 4, 3, 2, 1)y = set(nums) # 使用set内置类转换成为集合
print(y) # {1, 2, 3, 4, 8, 9}z = list({'name': 'zhangsan', 'age': 18, 'score': 98})
print(z) # ['name', 'age', 'score']# Python里有一个比较强大的内置函数eval,可以执行字符串里的代码
a = 'input("请输入您的用户名")' # a是一个字符串
b = '1+1'
print(eval(b)) # 2import json# JSON的使用,把列表、元组、字典等转换成为JSON字符串
person = {'name': 'zhangsan', 'age': 18, 'gender': 'female'}
# 字典如果想要把它传给前端页面或者把字典写入到一个文件里
m = json.dumps(person) # dumps将字典、列表、集合、元组等转换成为JSON字符串
print(m) # '{"name": "zhangsan", "age": 18, "gender": "female"}'
print(type(m)) # <class 'str'>
# print(m['name']) 不能这样使用,m是一个字符串,不能再像字典一样根据key获取valueprint(json.dumps(['hello', 'good', 'yes', True])) # ["hello", "good", "yes", true]
print(json.dumps(('hello', 'good', 'yes', False))) # ["hello", "good", "yes", false]n = '["hello","good"]'
p = eval(n)
print(type(p)) # <class 'list'>
s = json.loads(n) # loads可以将json字符串转换成为Python里的数据
print(s) # ['hello', 'good']
print(type(s)) # <class 'list'>
# + :可以用来拼接,用于 字符串、元组、列表
print('hello' + 'world')
print(('good', 'yes') + ('hi', 'ok'))
print([1, 2, 3] + [4, 5, 6])# -:只能用户集合,求差集
print({1, 2, 3} - {3})# *:可以用于字符串元组列表,表示重复多次。不能用于字典和集合
print('hello' * 3)
print([1, 2, 3] * 3)
print((1, 2, 3) * 3)# in:成员运算符
print('a' in 'abc')
print(1 in [1, 2, 3])
print(4 in (6, 4, 5))# in 用于字典是用来判断key是否存在
print('zhangsan' in {'name': 'zhangsan', 'age': 18, 'height': '180cm'})
print('name' in {'name': 'zhangsan', 'age': 18, 'height': '180cm'})
print(3 in {3, 4, 5})# nums = [19, 82, 39, 12, 34, 58]
nums = (19, 82, 39, 12, 34, 58)
# nums = {19, 82, 39, 12, 34, 58}
# 带下标的遍历 enumerate 类的使用,一般用户列表和元组等有序的数据for i, e in enumerate(nums):print('第%d个数据是%d' % (i, e))person = {'name': 'zhangsan', 'age': 18, 'height': '180cm'}
for i, k in enumerate(person):print(i, k)# helloworld
# ('good', 'yes', 'hi', 'ok')
# [1, 2, 3, 4, 5, 6]
# {1, 2}
# hellohellohello
# [1, 2, 3, 1, 2, 3, 1, 2, 3]
# (1, 2, 3, 1, 2, 3, 1, 2, 3)
# True
# True
# True
# False
# True
# True
# 第0个数据是19
# 第1个数据是82
# 第2个数据是39
# 第3个数据是12
# 第4个数据是34
# 第5个数据是58
# 0 name
# 1 age
# 2 height
内置函数
Python内置函数
| 函数名 | 分类 | 备注 |
|---|---|---|
| bool() | 数据类型 | 布尔型(True,False) |
| int () | 数据类型 | 整型(整数) |
| float() | 数据类型 | 浮点型(小数) |
| complex () | 数据类型 | 浮点型(小数) |
| bin() | 进制转换 | 将给的参数转换成二进制 |
| oct() | 进制转换 | 将给的参数转换成八进制 |
| hex() | 进制转换 | 将给的参数转换成十六进制 |
| divmode() | 数学运算 | 返回商和余数 |
| round() | 数学运算 | 四舍五入 |
| pow() | 数学运算 | pow(a, b) 求a的b次幂, 如果有三个参数. 则求完次幂后对第三个数取余 |
| min() | 数学运算 | 求最小值 |
| max() | 数学运算 | 求最大值 |
| sum() | 数学运算 | 求和 |
| dict() | 数据集合 | 创建一个字典 |
| set() | 数据集合 | 创建一个集合 无序排序且不重复,是可变的,有add(),remove()等方法。既然是可变的,所以它不存在哈希值。基本功能包括关系测试和消除重复元素。集合对象还支持union(联合),intersection(交集),difference(差集)和sysmmetric_difference(对称差集)等数学运算。作为一个无序的集合,set不记录元素位置或者插入点。因此,set不支持indexing,或其它类序列的操作。 |
| len() | 返回一个对象中的元素的个数 | |
| sorted() | 对可迭代对象进行排序操作 (lamda),sorted(Iterable, key=函数(排序规则), reverse=False)Iterable: 可迭代对象key() 排序规则(排序函数), 在sorted内部会将可迭代对象中的每一个元素传递给这个函数的参数. 根据函数运算的结果进行排序 | |
| reverse() | 是否是倒叙. True: 倒叙, False: 正序 | |
| enumerate() | 获取集合的枚举对象 | |
| all() | 可迭代对象中全部是True, 结果才是True | |
| any() | 可迭代对象中有一个是True, 结果就是True | |
| zip() | 函数用于将可迭代的对象作为参数, 将对象中对应的元素打包成一个元组, 然后返回由这些元组组成的列表. 如果各个迭代器的元素个数不一致, 则返回列表长度与最短的对象相同 | |
| fiter() | 过滤 (lamda)语法:fiter(function. Iterable)function: 用来筛选的函数. 在filter中会自动的把iterable中的元素传递给function. 然后根据function返回的True或者False来判断是否保留留此项数据 , Iterable: 可迭代对象 | |
| map() | 会根据提供的函数对指定序列列做映射(lamda) 语法 : map(function, iterable) 可以对可迭代对象中的每一个元素进行映射. 分别去执行 function | |
| list() | 数据结构_ | 将一个可迭代对象转换成列表 |
| tuple() | 数据结构_ | 将一个可迭代对象转换成元组 |
| reversed() | 将一个序列翻转, 返回翻转序列的迭代器 | |
| slice() | 列表的切片 | |
| str() | 将数据转化成字符串 | |
| format() | 与具体数据相关, 用于计算各种小数, 精算 | |
| bytes() | 把字符串转化成bytes类型 | |
| bytearray() | 返回一个新字节数组. 这个数字的元素是可变的, 并且每个元素的值得范围是[0,256) | |
| ord() | 输入字符找带字符编码的位置 | |
| chr() | 输入位置数字找出对应的字符 | |
| ascii() | 是ascii码中的返回该值 不是就返回u | |
| repr() | 返回一个对象的string形式 | |
| locals() | 作用域相关 | 返回当前作用域中的名字 |
| globals() | 作用域相关 | 返回全局作用域中的名字 |
| range() | 迭代器生成器相关 | 生成数据 |
| next() | 迭代器生成器相关 | 迭代器向下执行一次, 内部实际使用了__ next__()方法返回迭代器的下一个项目 |
| iter() | 迭代器生成器相关 | 获取迭代器, 内部实际使用的是__ iter__()方法来获取迭代器 |
| eval() | 字符串类型代码的执行 | 执行字符串类型的代码. 并返回最终结果 语法: eval(expression[, globals[, locals]])参数 expression – 表达式。 globals – 变量作用域,全局命名空间,如果被提供,则必须是一个字典对象。 locals – 变量作用域,局部命名空间,如果被提供,可以是任何映射对象。 返回值:表达式计算结果。 |
| exec() | 字符串类型代码的执行 | 执行字符串类型的代码 |
| compile() | 字符串类型代码的执行 | 将字符串类型的代码编码. 代码对象能够通过exec语句来执行或者eval()进行求值 |
| print() | 输入输出 | 打印输出 |
| input() | 输入输出 | 获取用户输出的 |
| hash() | 内存相关 | 获取到对象的哈希值(int, str, bool, tuple). hash算法:(1) 目的是唯一性 (2) dict 查找效率非常高, hash表.用空间换的时间 比较耗费内存 |
| open() | 文件操作相关 | 用于打开一个文件, 创建一个文件句柄 |
| __ import__() | 模块相关 | 用于动态加载类和函数 |
| help() | 帮 助 | 函数用于查看函数或模块用途的详细说明 |
| callable() | 调用相关 | 用于检查一个对象是否是可调用的. 如果返回True, object有可能调用失败, 但如果返回False. 那调用绝对不会成功 |
| dir() | 查看内置属性 | 查看对象的内置属性, 访问的是对象中的__dir__()方法 包含参数的方括号 [ ] 表示参数是可选参数。 当提供参数对象时,它返回对象内可用的属性,当不提供参数时,它返回当前作用域中可用的名称。 当对象内定义了 dir() 方法时,调用 dir(object) 函数时,对象内的 dir() 方法被调用,并返回在 dir() 方法内定义的属性列表。 如对象内没定义了 dir() 方法,调用 dir(object) 函数时,返回 dict 属性(如果定义了)和对象的数据类型内包含的属性(包括方法)。 dir([object]) 参数:object:任意一个变量对象。 返回值:当提供参数对象时,它返回对象内可用的属性,当不提供参数时,它返回当前作用域中可用的名称。 |
| setattr() | setattr() 函数的功能相对比较复杂,它最基础的功能是修改类实例对象中的属性值。其次,它还可以实现为实例对象动态添加属性或者方法。setattr() 函数对应函数getattr(),用于设置属性值,若属性不存在,则先创建在赋值。给对象的属性赋值,若属性不存在,先创建再赋值。 setattr() 函数的语法格式如下: setattr(obj, name, value) 参数 object – 对象 name – 字符串,属性名 value – 属性值。 返回值 :无 | |
| getattr() | 函数获取某个类实例对象中指定属性的值。没错,和 hasattr() 函数不同,该函数只会从类对象包含的所有属性中进行查找。 getattr() 函数的语法格式如下: getattr(obj, name[, default])参数 : object – 对象 name – 字符串,对象属性 default-- 默认返回值,如果不提供该参数,在没有对应属性时,将触发AttrbuteError. 返回值 :返回对象属性值 | |
| hasattr() | 函数用来判断某个类实例对象是否包含指定名称的属性或方法。 判断一个对象里面是否有name属性或者name方法,返回BOOL值,有name特性返回True, 否则返回False。 需要注意的是name是一个字符串字面值或字符串类型变量。 语法格式如下: asattr(obj, name)参数: object – 对象 name – 字符串,属性名 返回值 :如果对象有该属性返回 True,否则返回 False。 | |
| delattr() | delattr() 函数用来删除指定对象的指定名称的属性,和setattr函数作用相反,属性必须存在,否则发出AttributeError。delattr(object, name) | |
| id() | 用于获取对象的 “identity” (唯一身份标示值,其实际值是内存地址),这个值是在对象的生命周期内是唯一且恒定的。如果两个对象的生命周期没有重叠,那么这两个对象使用 id() 函数返回的标示符(内存地址)可能相同。id(object) 参数解释:object:任意一个对象,可以是变量,函数,类。 返回值解释:函数返回当前对象的参数的”identity” (内存地址)唯一标示符。 | |
| object() | ||
| staticmethod() | 静态方法 | staticmethod是一种装饰器,它可以将一个方法转换为静态方法。静态方法是属于类的方法,可以通过类名或实例名直接调用,而不需要传入self参数。通过使用staticmethod,我们可以将不需要访问实例属性或类属性的方法定义为静态方法,从而提高代码的灵活性和复用性。 语法格式如下: @staticmethod def 静态方法名():pass |
| classmethod() | 类方法 | python中 定义 class 时,只能有一个 初始化方法,不能按照不同情况初始化类。可以借助 class 方法来实现这个需求。 |
| isinstance() | isinstance() 函数来判断一个对象是否是一个已知的类型,类似 type()。 语法: isinstance(object, classinfo) 参数含义 object – 实例对象。 classinfo – 可以是直接或间接类名、基本类型或者由它们组成的元组。 返回值: 如果对象的类型与参数二的类型(classinfo)相同则返回 True,否则返回 False。 | |
| issubclass() | issubclass 函数主要用于判断一个对象是否为另外一个对象的子类, 语法如下: issubclass(child_class,father_class) 参数: child_class — 类对象; father_class — 类对象; 返回值: 如果child_class 是 father_class 的子类,返回True,否则返回 False; | |
| super() | 用于调用父类(超类)的一个方法。super 是用来解决多重继承问题的,直接用类名调用父类方法在使用单继承的时候没问题,但是如果使用多继承,会涉及到查找顺序(MRO)、重复调用(钻石继承)等种种问题。 语法 super(type[, object-or-type]) 参数 type – 类 object-or-type – 类,一般是 self Python 3 可以使用直接使用 super().xxx 代替 super(Class, self).xxx | |
| property() | 语法: property(fget=None, fset=None, fdel=None, doc=None)参数说明: fget 是获取属性值的函数。 fset 是设置(修改)属性值的函数。 fdel 是删除属性值的函数。 doc 是属性描述信息。如果省略,会把 fget 方法的文档字符串(docstring)拿来用(如果有的话)。 返回 property 属性(attribute) @property装饰器可以做到和内置函数property() 相同的事情 被 @property 装饰的方法是获取属性值的方法,被装饰方法的名字会被用做 属性名。 被 @属性名.setter 装饰的方法是设置属性值的方法。 被 @属性名.deleter 装饰的方法是删除属性值的方法 | |
| type() | 有两种语法形式, type(object)此种形式的 tpye() 函数用于获取特定对象的数据类型。 必须参数解释:object:任意一个对象,可以是变量,函数,类。 返回值解释:函数返回当前参数变量的数据类型,形式为 <class ‘int’>。 type(name, bases, dict) 此种形式的 tpye() 函数用于创建一个新的数据类型,它是类定义的动态形式。 必须参数解释: name:要创建的新类(class)的名称。 bases:参数是一个元组(tuple),它的元素是新类的基类,它表示创建的新类继承自这些类。 dict:参数是一个字典,字典元素的键值对表示,新类的 属性名:属性值。 返回值解释:函数返回创建的新类(数据类型) | |
| vars() | 语法为:vars([object])参数 object – 对象 返回值 返回对象object的属性和属性值的字典对象,如果没有参数,就打印当前调用位置的属性和属性值 类似 locals()。 | |
| memoryview() | class memoryview(object) |
函数
- 函数的声明,使用关键字 def 来声明一个函数
- 函数的格式 def 函数名(形参1,形参2…)
- 函数的调用 函数名(实参1,实参2…)
- 函数返回值 使用 return 语句返回函数的执行结果
- 函数返回多个结果,就是将多个数据打包成一个整体返回。 可以使用列表和字典,通常情况下选择使用元组
函数名也是一个标识符。
由数字、字母下划线组成,不能以数字开头;
严格区分大小写;不能使用关键字 遵守命名规范,使用下划线连接;顾名思义
注意:
函数的三要素: 函数名、参数和返回值 在有一些编程语言里,允许函数重名,在Python里不允许函数的重名 如果函数重名了,后一个函数会覆盖前一个函数
def 函数名(参数):函数体,函数要执行的操作调用函数: 函数名(参数)# 函数定义好了以后并不会自动执行
# 函数声明时,括号里的参数我们称之为形式参数,简称形参
# 形参的值是不确定的,只是用来占位的
# 调用函数时传递数据
# 函数调用时传入的参数,才是真正参与运算的数据,我们称之为实参def tell_story(person1, person2):print('person1的值' + person1)print('person2的值' + person2)
tell_story('老道', '道童') # 会把实参一一对应的传递,交给形参处理
# 还可以通过定义变量名的形式给形参赋值,“关键字=实参”的形式,其中,关键字的名称就是定义函数时形参的名称。
tell_story(person2='青年', person1='禅师')# 返回值就是函数执行的结果,并不是所有的函数都必须要有返回值
def add(a, b):c = a + b # 变量c在外部是不可见的,只能在函数内部使用return c # return 表示一个函数的执行结果
# 多个返回值
def test(a, b):x = a // by = a % b# 一般情况下,一个函数最多只会执行一个return语句# 特殊情况(finally语句)下,一个函数可能会执行多个return语句# return x # return语句表示一个函数的结束# return {'x': x, 'y': y}# return [x, y]# return (x, y)return x, y # 返回的本质是一个元组def add(a: int, b: int):"""这个函数用来将两个数字相加:param a: 第一个数字:param b: 第二个数字:return: 两个数字相加的结果"""return a + b
全局变量 局部变量
变量可以在模块中创建,作用域(变量的有效范围)是整个模块,
被称为全局变量。变量也可以在函数中创建,在默认情况下作用域是整
个函数,被称为局部变量。
内置函数
globals()可以查看全局变量locals()可以查看局部变量
使用global 变量对变量进行声明,可以通过函数修改全局变量的值
a = 100 # 这个变量是全局变量,在整个py文件里都可以访问
word = '你好'def test():x = 'hello' # 这个变量是在函数内部定义的变量,它是局部变量,只能在函数内部使用print('x = {}'.format(x))# 如果局部变量的名和全局变量同名,会在函数内部又定义一个新的局部变量# 而不是修改全局变量a = 10print('函数内部a = {}'.format(a))# 使用global对变量进行声明,可以通过函数修改全局变量的值global wordword = 'ok'print('locals = {},globals = {}'.format(locals(), globals()))test()
# print(x) # x只能在函数内部使用
print('函数外部a = {}'.format(a))
print('函数外部word={}'.format(word))# 内置函数 globals()可以查看全局变量 locals()可以查看局部变量# 在Python里,只有函数能够分割作用域
if 3 > 2:m = 'hi'print(m)print(globals())# x = hello
# 函数内部a = 10
# locals = {'x': 'hello', 'a': 10},globals = {'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x000001C835039700>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': '位置.py', '__cached__': None, 'a': 100, 'word': 'ok', 'test': <function test at 0x000001C834EE9080>}
# 函数外部a = 100
# 函数外部word=ok
# hi
# {'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x000001C835039700>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': '位置.py', '__cached__': None, 'a': 100, 'word': 'ok', 'test': <function test at 0x000001C834EE9080>, 'm': 'hi'}默认参数
# 缺省参数要放在后面
def say_hello(name, age, city="襄阳"): # 形参city设置了一个默认值print("大家好,我是{},我今年{}岁了,我来自{}".format(name, age, city))say_hello('jack', 19) # 如果没有传递参数,会使用默认值
say_hello(name='tony', age=23, city='北京') # 如果传递参数,就使用传递的实参# 如果有位置参数和关键字参数,关键字参数一定要放在位置参数的后面
say_hello('jerry', age=24, city='南京') # 可以直接传递单个参数,也可以使用变量赋值的形式传参
say_hello(name='henry', city='成都', age=21)# 缺省参数:
# 有些函数的参数是,如果你传递了参数,就使用传递的参数
# 如果没有传递参数,就使用默认的值# print函数里end就是一个缺省参数
# print('hello', '你好', sep="____")
可变参数
*可变参数表示可变位置参数
**可变参数表示可变的关键字参数
def add(a, b, *args, mul=1, **kwargs):print('a = {},b={}'.format(a, b))print('args = {}'.format(args)) # 多出来的可变参数会以元组的形式保存到args里print('mul = {}'.format(mul)) # 没有传值 默认是1print('kwargs = {}'.format(kwargs)) # 多出来的关键字参数会以字典的形式保存c = a + bfor arg in args:c += argreturn c * mulprint(add(1, 3, 5, 7, mul=2, x=0, y=4))
# a = 1,b=3
# args = (5, 7)
# mul= 2
# kwargs = {'x': 0, 'y': 4}
# 32print(add(9, 5, 4, 2, 0, p=9, q=10))
# a = 9,b=5
# args = (4, 2, 0)
# mul= 1
# kwargs = {'p': 9, 'q': 10}
# 20print(add(8, 9, 7, 5, 7, 9, 8, 7, 5, 3, t=0, m=5))
# a = 8,b=9
# args = (7, 5, 7, 9, 8, 7, 5, 3)
# mul= 1
# kwargs = {'t': 0, 'm': 5}
# 68
可变类型和不可变类型传参
def test(a):print('修改前a的内存地址0x%X' % id(a))a = 100print('修改后a的内存地址0x%X' % id(a))def demo(nums):print('修改前nums的内存地址0x%X' % id(nums))nums[0] = 10print('修改后nums的内存地址0x%X' % id(nums))x = 1
print('调用前x的内存地址0x%X' % id(x))
test(x)
print('调用后x的内存地址0x%X' % id(x))
print(x) # 1y = [3, 5, 6, 8, 2]
print('调用前y的内存地址0x%X' % id(y))
demo(y)
print('调用后y的内存地址0x%X' % id(y))
print(y) # [10, 5, 6, 8, 2]# 调用前x的内存地址0x7FFF907EC9B8
# 修改前a的内存地址0x7FFF907EC9B8
# 修改后a的内存地址0x7FFF907ED618
# 调用后x的内存地址0x7FFF907EC9B8
# 1
# 调用前y的内存地址0x2854620D100
# 修改前nums的内存地址0x2854620D100
# 修改后nums的内存地址0x2854620D100
# 调用后y的内存地址0x2854620D100
# [10, 5, 6, 8, 2]
递归函数
递归简单来说,就是函数内部自己调用自己
递归最重要的就是找到出口(停止的条件)
# 使用递归求 n! n!=n*(n-1)!
def factorial(n):if n == 0:return 1return n * factorial(n - 1)print(factorial(6)) # 720# 使用递归求斐波那契数列的第 n 个数字
# 1,1,2,3,5,8,13,21,34,55,89,144
def fibonacci(n):if n == 1 or n == 2:return 1return fibonacci(n - 2) + fibonacci(n - 1)print(fibonacci(9)) # 34lambda() 匿名函数
除了使用 def 关键字定义一个函数以外,我们还能使用 lambda 表达式定义一个函数
匿名函数 用来表达一个简单的函数,函数调用的次数很少,基本上就是调用一次 调用匿名函数两种方式:
- 给它定义一个名字(很少这样使用)
- 把这个函数当做参数传给另一个函数使用(使用场景比较多)
注意: lambda体部分不能是一个代码块,不能包含多条语句,只有一条语句,语句会计算一个结果并返回给lambda()函数,但与有名称的函数不同的是,不需要使用return语句返回。
# 有名称的函数 定义的add()
def add(a, b):c = a + b # 变量c在外部是不可见的,只能在函数内部使用return c # return 表示一个函数的执行结果
x = add(4, 5) # 函数名(实参) 作用是调用函数,获取到函数的执行结果,并赋值给变量 x
print(x)#lambda() 匿名函数
mul = lambda a, b: a + b
print(mul(4, 5))
def calc(a, b, fn):c = fn(a, b)return c# def add(x, y):
# return x + y# def minus(x, y):
# return x - y# 回调函数
# x1 = calc(1, 2, add) # a=1,b=2,fn=add
# x2 = calc(10, 5, minus) # a=10,b=5,fn=minusx3 = calc(5, 7, lambda x, y: x + y)
x4 = calc(19, 3, lambda x, y: x - y)
x5 = calc(2, 7, lambda x, y: x * y)
x6 = calc(12, 3, lambda x, y: x / y)print(x3, x4, x5, x6, sep='\n')# 12
# 16
# 14
# 4.0
内置函数的使用
sort() 方法 : 会直接对列表进行排序 字典排序时需要传递参数 key(键名) 指定比较规则
sorted() 内置函数 : 不会改变原有的数据,而是生成一个新的有序的列表
nums = [4, 8, 2, 1, 7, 6] ints = (5, 9, 2, 1, 3, 8, 7, 4)nums.sort()print(nums) # [1, 2, 4, 6, 7, 8] x = sorted(ints)print(ints) # (5, 9, 2, 1, 3, 8, 7, 4)print(x) # [1, 2, 3, 4, 5, 7, 8, 9]students = [{'name': 'zhangsan', 'age': 18, 'score': 98, 'height': 180},{'name': 'lisi', 'age': 21, 'score': 97, 'height': 185},{'name': 'jack', 'age': 22, 'score': 100, 'height': 175},{'name': 'tony', 'age': 23, 'score': 90, 'height': 176},{'name': 'henry', 'age': 20, 'score': 95, 'height': 172} ]# students.sort() # foo() takes 0 positional arguments but 1 was given # foo这个函数需要 0 个位置参数,但是在调用的时候传递了一个参数 # def foo(ele): # # print("ele = {}".format(ele)) # return ele['height'] # 通过返回值告诉sort方法,按照元素的那个属性进行排序# 需要传递参数 key 指定比较规则 # key参数类型是函数# 在sort内部实现的时候,调用了foo方法,并且传入了一个参数,参数就是列表里的元素 # students.sort(key=foo)students.sort(key=lambda ele: ele['age']) print(students) # [{'name': 'zhangsan', 'age': 18, 'score': 98, 'height': 180}, {'name': 'henry', 'age': 20, 'score': 95, 'height': 172}, {'name': 'lisi', 'age': 21, 'score': 97, 'height': 185}, {'name': 'jack', 'age': 22, 'score': 100, 'height': 175}, {'name': 'tony', 'age': 23, 'score': 90, 'height': 176}]filter() : 对可迭代对象进行过滤,得到的是一个filter对象
两个参数,第一个参数是函数,第二个参数是可迭代对象
# filter 对可迭代对象进行过滤,得到的是一个filter对象ages = [12, 23, 30, 17, 16, 22, 19] # filter可以给定两个参数,第一个参数是函数,第二个参数是可迭代对象 # filter结果是一个 filter 类型的对象,filter对象也是一个可迭代对象 x = filter(lambda ele: ele > 18, ages) print(x) # <filter object at 0x000002670373E908>adult = list(x) print(adult) # [23, 30, 22, 19]map() : 第一个参数接受一个函数名,后面的参数接受一个或多个可迭代的序列,返回的是一个集合。
把函数依次作用在list中的每一个元素上,得到一个新的list并返回。注意,map不改变原list,而是返回一个新list。
通过map还可以实现类型转换
# map() 函数+ lambda表达式 bonuses = [100, 200, 300] iterator = map(lambda x: x*2, bonuses) print(list(iterator)) # 输出:[200, 400, 600]# map() 函数输入多个可迭代对象iterable b1 = [100, 200, 300] b2 = [1, 2, 3]iterator = map(lambda x,y : x*y, b1, b2) print(list(iterator)) # 输出:[100, 400, 900]def double_func(x):>return x* 2bonuses = [100, 200, 300]iterator = map(double_func, bonuses) print(list(iterator)) # 输出:[200, 400, 600]# print(iterator) # 输出:<map object at 0x000001171E2A5540># 通过lambda函数使返回值是一个元组: c = map(lambda x, y : (x**y,x+y),[2,4,6],[3,2,1]) print(list(c)) # [(8, 5), (16, 6), (6, 7)]# 通过map还可以实现类型转换 #将元组转换为list:v = map(int, (1, 2, 3)) print(list(v)) #[1, 2, 3]#将字符串转换为list:x = map(int, '1234') print(list(x)) # [1, 2, 3, 4]#提取字典中的key,并将结果放在一个list中: f = map(int, {1: 2, 2: 3, 3: 4}) print(list(f)) # [1, 2, 3]reduce() : 函数原本在python2中也是个内置函数,不过在python3中被移到functools模块中
from functools import reduce 导入模块的语法
reduce函数先从列表(或序列)中取出2个元素执行指定函数,并将输出结果与第3个元素传入函数,输出结果再与第4个元素传入函数,…,以此类推,直到列表每个元素都取完。
与内置函数map和filter不一样的是,在性能方面,reduce相比较for循环来说没有优势,甚至在实际测试中reduce比for循环更慢。
from functools import reduce # 导入模块的语法# reduce 以前是一个内置函数 # 内置函数和内置类都在 builtins.py文件里def foo(x, y): # x=100,y=89;x=189,y=76;x=265,y=87return x + y scores = [100, 89, 76, 87] print(reduce(foo, scores)) # 352students = [{'name': 'zhangsan', 'age': 18, 'score': 98, 'height': 180},{'name': 'lisi', 'age': 21, 'score': 97, 'height': 185},{'name': 'jack', 'age': 22, 'score': 100, 'height': 175},{'name': 'tony', 'age': 23, 'score': 90, 'height': 176},{'name': 'henry', 'age': 20, 'score': 95, 'height': 172} ]def bar(x, y):# x= 0# y = {'name': 'zhangsan', 'age': 18, 'score': 98, 'height': 180},return x + y['age']print(reduce(bar, students, 0)) # 104print(reduce(lambda x, y: x + y['age'], students, 0)) # 104# for循环def sum_func(arr):if len(arr) <= 0:return 0else:out = arr[0]for v in arr[1:]:out += vreturn outa = [1, 2, 3, 4, 5]print(sum_func(a)) # 15# reduce a = [1, 2, 3, 4, 5]def add(x, y): return x + y print(reduce(add, a)) # 15
# staticmethod的使用示例
# 下面通过一个实际的示例来演示staticmethod的使用方法。假设我们有一个名为MathUtil的类,其中包含了一个计算两个数相加的静态方法add:class MathUtil:@staticmethoddef add(x, y):return x + y
#在上面的示例中,我们使用@staticmethod装饰器将add方法定义为静态方法。这样一来,我们就可以通过类名或实例名直接调用add方法,而不需要创建MathUtil的实例对象:print(MathUtil.add(3, 5)) # 输出8#使用staticmethod有以下几个好处:
#1. 提高代码的可读性:将不需要访问实例属性或类属性的方法定义为静态方法,可以更清晰地表达方法的用途,提高代码的可读性。
#2. 提高代码的复用性:静态方法可以在不创建类实例的情况下直接调用,从而提高方法的复用性。
#3. 减少不必要的内存消耗:静态方法不需要访问实例属性,因此不会创建实例对象,从而减少不必要的内存消耗。#在使用staticmethod时,需要注意以下几点:
#1. 静态方法中无法访问实例属性或类属性,因此在定义静态方法时,需要确保方法的功能与实例属性或类属性无关。
#2. 静态方法的调用可以通过类名或实例名来进行,但通常建议使用类名进行调用,以表明该方法与类本身相关,而不是与特定的实例对象相关。
#3. 静态方法通常用于定义一些通用的功能性方法,例如数学计算、类型转换等,它们与特定的实例对象无关。
# 无参数情况下的使用:# 当在全局作用域内调用 vars() 函数时,它返回当前全局作用域中的变量和值的字典。
# 当在函数内部调用 vars() 函数时,它返回当前函数的局部变量和值的字典。
# 有参数情况下的使用:# 如果传递一个对象作为参数给 vars() 函数,它将返回该对象的属性和属性值的字典。
# 对于自定义类的实例对象,vars() 函数返回的字典将包含实例的属性和属性值。
# 对于内置类的实例对象(如列表、字符串等),vars() 函数返回的字典通常只包含内置属性和方法,并不包含实例化时添加的自定义属性。# 1. 获取对象的属性和属性值:
class Person:def __init__(self, name, age):self.name = nameself.age = age
person = Person("Alice", 25)
attributes = vars(person)
print(attributes) # {'name': 'Alice', 'age': 25}# 2. 获取当前作用域的局部变量:
def my_function():x = 10y = 20local_vars = vars()print(local_vars) # {'x': 10, 'y': 20}
my_function()# 3. 获取全局作用域的变量:
global_var = 100def print_global_vars():global_vars = vars()print(global_vars) # {'global_var': 100, ... (其他全局变量)}
print_global_vars()# 4. 获取模块的全局变量:
# my_module.py
x = 10
y = 20
module_vars = vars()
print(module_vars) # {'__name__': '__main__', '__doc__': None, '__package__': None, 'x': 10, 'y': 20}
高级函数 函数嵌套
# 1. 一个函数作为另一个函数的参数
# 2. 一个函数作为另一个函数的返回值
# 3. 函数内部再定义一个函数def foo():print('我是foo,我被调用了')return 'foo'def bar():print('我是bar,我被调用了')return foox()y = bar()()
print(y)# 装饰器
def outer():m = 100def inner():n = 90print('我是inner函数')print('我是outer函数')return innerouter()()
函数练习代码
# 编写一个函数,求多个数中的最大值
import randomdef get_max(*args):x = args[0]for arg in args:if arg > x:x = argreturn x# 编写一个函数,实现摇骰子的功能,打印N个骰子的点数和
def get_sum(n):m = 0for i in range(n):x = random.randint(1, 6)m += xreturn m# 编写一个函数,提取指定字符串中所有的字母,然后拼接在一起产生一个新的字符串
def get_alphas(word):new_str = ''for w in word:if w.isalpha():new_str += wreturn new_str# 写一个函数,默认求10的阶乘,也可以求其他数字的阶乘
def get_factorial(n=10):x = 1for i in range(1, n + 1):x *= ireturn x# 写一个函数,求多个数的平均值
def get_average(*args):x = 0for arg in args:x += argreturn x / len(args)# 写一个自己的capitalize函数,能够将指定字符串的首字母变成大写字母
def my_capitalize(word):c = word[0]if 'z' >= c >= 'a':new_str = word[1:]return c.upper() + new_strreturn word# 写一个自己的endswith函数,判断一个字符串是否以指定的字符串结束
def my_endswith(old_str, str1):return old_str[-len(str1):] == str1# 写一个自己的isdigit函数,判断一个字符串是否是纯数字字符串
def my_digit(old_str):for s in old_str:if not '0' <= s <= '9':return Falsereturn True# 写一个自己的upper函数,将一个字符串中所有的小写字母变成大写字母
# a==>97 A ==> 65 32
def my_upper(old_str):new_str = ''for s in old_str:if 'a' <= s <= 'z':upper_s = chr(ord(s) - 32)new_str += upper_selse:new_str += sreturn new_str# 写一个函数实现自己in操作,判断指定序列中,指定的元素是否存在
def my_in(it, ele):for i in it:if i == ele:return Trueelse:return False# 写一个自己的replace函数,将指定字符串中指定的旧字符串转换成指定的新字符串
# 方法一
def my_replace1(all_str, old_str, new_str):return new_str.join(all_str.split(old_str))#方法二
def my_replace(all_str, old_str, new_str):result = ''i = 0while i < len(all_str):temp = all_str[i:i + len(old_str)]if temp != old_str:result += all_str[i]i += 1else:result += new_stri += len(old_str)return result# 写一个自己的max函数,获取指定序列中元素的最大值。如果序列是字典,取字典值的最大值
def get_max2(seq):# if type(seq) == dict: # 另一种写法if isinstance(seq, dict): # 看对象seq是否是通过dict类创建出来的实例seq = list(seq.values())x = seq[0]for i in seq:if i > x:x = ireturn xprint(get_max(1, 9, 6, 3, 4, 5))
print(get_sum(5))
print(get_alphas('hello123good456'))
print(get_factorial())
print(get_average(1, 2, 3, 4, 5, 6))
print(my_capitalize('hello'))
print(my_capitalize('34hello'))
print(my_endswith('hello', 'lxo'))
print(my_digit('12390'))
print(my_upper('hel34lo'))
print(my_in(['zhangsan', 'lisi', 'wangwu'], 'jack'))
print(my_in({'name': 'zhangsan', 'age': '18'}, 'name'))
print(my_replace1('how you and you fine you ok', 'you', 'me'))
print(my_replace('how you and you fine you ok', 'you', 'me'))
# ['zhangsan','lisi','wangwu'] ==> zhangsan_lisi_wangwuprint(get_max2([2, 4, 8, 1, 9, 0, 7, 5]))
print(get_max2({'x': 10, 'y': 29, 'z': 32, 'a': 23, 'b': 19, 'c': 98}))闭包的概念
闭包定义:
在函数嵌套的前提下,内部函数使用了外部函数的变量,并且外部函数返回了内部函数,我们把这个使用外部函数变量的内部函数称为闭包闭包的构成条件:
在函数嵌套(函数里面在定义函数)的前提下 内部函数使用了外部函数的变量(还包括外部函数的参数) 外部函数返回了内部函数闭包书写步骤:
定义外部函数 定义外部函数,在内部函数中使用外部函数的变量 外部函数返回内部函数的地址闭包的使用
案例:根据配置信息使用闭包实现不同人的对话信息,例如对话:
张三:到北京了吗?
李四:已经到了,放心吧。
实现步骤说明
定义外部函数接受不同的配置信息参数,参数是人名
定义内部函数接受对话信息参数
在内部函数里面把配置信息和对话信息进行拼接输出
def outer(name):# 定义内部函数,参数是 说话的信息print(f'{name}:到北京了吗?')def inner(name1):# 内部函数中,将name和info进行拼接输出print(f'{name1}:已经到了,放心吧。')# 外部函数返回内部函数的地址return inner# 创建闭包实例 if __name__ == '__main__':func = outer('张三')func('李四') # 注意点:由于闭包引用了外部函数的变量,则外部函数的变量没有及时释放,消耗内存。
闭包修改外部函数变量(理解)
函数内部想要修改全局变量,使用global关键字
在闭包函数内部,想要修改外部函数的局部变量,需要使用nonlocal关键字
def outer():num = 10def inner():#不写 nonlocal num = 100就不是修改外部变量的值,重新定义的局部变量nonlocal num # 声明使用外部变量 num 不重新定义 只能写在最上面print(' inner里的num = ', num)num = 100print(' inner外面的 num 被修改成 ', num)print(f'调用inner之前:{num}')inner()print(f'调用inner之后:{num}')return innerprint(f'^^^^^^^^^^^^^^^写法一^^^^^^^^^^^^^^^') func = outer() func()print(f'^^^^^^^^^^^^^^^写法二^^^^^^^^^^^^^^^') outer()()# ^^^^^^^^^^^^^^^写法一^^^^^^^^^^^^^^^ # 调用inner之前:10 # inner里的num = 10 # inner外面的 num 被修改成 100 # 调用inner之后:100 # inner里的num = 100 # inner外面的 num 被修改成 100 # ^^^^^^^^^^^^^^^写法二^^^^^^^^^^^^^^^ # 调用inner之前:10 # inner里的num = 10 # inner外面的 num 被修改成 100 # 调用inner之后:100 # inner里的num = 100 # inner外面的 num 被修改成 100
计算时间的代码
import time # time模块可以获取当前的时间def cal_time(fn):start = time.time() # time模块里的time方法,可以获取当前时间的时间戳fn()end = time.time()print('代码运行耗时{}秒'.format(end - start))def demo():x = 0for i in range(1, 100000000):x += iprint(x)def foo():print('hello')time.sleep(3) # 暂停 3秒 执行下边的代码print('world')cal_time(demo)
cal_time(foo)
装饰器
Python 中的装饰器是一种语法糖,可以在运行时,动态的给函数或类添加功能。
装饰器本质上是一个函数,使用 @ + 函数名就是可实现绑定给函数的第二个功能 。
将一些通用的、特定函数的功能抽象成一个装饰器,可以重复利用这些功能
用于在不修改原始函数或类代码的情况下,对其进行功能扩展或修改。装饰器基于函数式编程的概念,通过将函数作为参数传递给另一个函数,并返回一个新的函数来实现。
def 装饰器函数名 (fn):
def 内函数名 (a, b):
fn(a,b)
函数块执行代码
return 内函数名
@装饰器函数名
def function( a,b):
pass
def msg_service(fn):def servemoney2(name,x):print("欢迎存钱")fn(name,x)print("存钱结束")return servemoney2@msg_service
def servemoney(name,x):print(name,'存了',x,'元')
servemoney("小张",100)# @msg_service的作用相当于servemoney = msg_service(servemoney)# 执行结果
# 欢迎存钱
# 小张 存了 100 元
# 存钱结束import timedef cal_time(fn):print('我是外部函数,我被调用了!!!')print('fn = {}'.format(fn))def inner():start = time.time()fn()end = time.time()print('代码耗时', end - start)return inner@cal_time # 第一件事调用cal_time;第二件事把被装饰的函数传递给fn
def demo():x = 0for i in range(1, 100000000):x += iprint(x)# 第三件事:当再次调用demo函数时,才是的demo函数已经不再是上面的demo
print('装饰后的demo = {}'.format(demo))
demo()# 我是外部函数,我被调用了!!!
# fn = <function demo at 0x000002293D2DFCE0>
# 装饰后的demo = <function cal_time.<locals>.inner at 0x000002293D159080>
# 4999999950000000
# 代码耗时 3.033639430999756
# 产品经理: 提需求 / 改需求.
# 如果超过22点不让玩儿游戏,如果不告诉时间,默认让玩儿游戏
# 开放封闭原则def can_play(fn):def inner(x, y, *args, **kwargs):# print(args)# clock = kwargs['clock'] # 不传值拿不到clock 会报错clock = kwargs.get('clock', 23) # 用.get() 拿不到值不报错 还可以设置默认值if clock <= 22:fn(x, y)else:print('太晚了,赶紧睡')return inner@can_play
def play_game(name, game):print('{}正在玩儿{}'.format(name, game))play_game('张三', '王者荣耀', m='hello', n='good', clock=18)
play_game('李四', '吃鸡')# 张三正在玩儿王者荣耀
# 太晚了,赶紧睡
模块
模块的概念
- 模块是python程序架构的一个核心概念。
- 每一个以扩展名py结尾的python源代码文件都是一个模块
- 模块名同样也是一个标识符,需要符合标识符的命名规则
- 在模块中定义的全局变量、函数、类都是提供给外界直接使用的工具
- 模块就好比工具包,要想使用这个工具包中的工具,就需要先的导入这个模块
模块的导入方式
在导入模块时,每个导入的模块应该独占一行(推荐使用)
不仅可以引入函数,还可以引入一些全局变量、类等。【下方 工具名 包含函数、全局变量、类】
- 语法格式:
import 模块名导入整个模块import 模块名 as 模块别名导入整个模块的同时给该模块取个较短的别名 可以逗号隔开引用多个from 模块名 import *从模块导入所有工具from 模块名 import 工具名从模块导入某一个from 模块名 import 工具名 as 模块别名从模块导入某一个,可能不同的模块名存在相同的工具名可以取个别名便于区分
- 使用方式
模块名或模块别名. 工具名
一个模块本质上就是一个py文件
自己定义一个模块,其实就是自己写一个py文件
import 我的模块如果一个py文件想要当做一个模块被导入,文件名一定要遵守命名规范
由数字、字母下划线组成,不能以数字开头
导入了一个模块,就能使用这个模块里变量和函数
安装三方模块
一、Python修改镜像源
python默认的官方仓库服务器在国外。因此,我们可以将镜像源修改为国内服务器镜像源
| 镜像站名 | 镜像站网址 |
|---|---|
| 清华大学开源软件镜像站 |   |
| 中国科学技术大学 |   |
| 阿里云开源镜像站 |  |
| 网易开源镜像站 |  |
| 搜狐开源镜像 |  |
| 浙江大学开源镜像站 |   |
| 腾讯开源镜像站 |  |
# windows:
# 配置中科大镜像
pip config set global.index-url https://mirrors.ustc.edu.cn/pypi/web/simple# 配置阿里源
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
# 配置腾讯源
pip config set global.index-url http://mirrors.cloud.tencent.com/pypi/simple
# 配置豆瓣源
pip config set global.index-url http://pypi.douban.com/simple/## 你只需配置其中一个即可修改镜像源
# 临时修改镜像源
#临时修改镜像源使用下面的命令
pip install 库名 -i 镜像地址#比如我要安装 numpy 库 并使用 阿里云 的镜像源
pip3 install numpy -i https://mirrors.aliyun.com/pypi/simple# 永久修改镜像源
# windows
# 打开我的电脑,在地址栏中输入 %APPDATA% 按回车跳转到目标目录。在目录下创建一个
# pip文件,再其内部创建一个pip.ini 文件。
#编辑文件输入以下信息。以豆瓣为例!
# 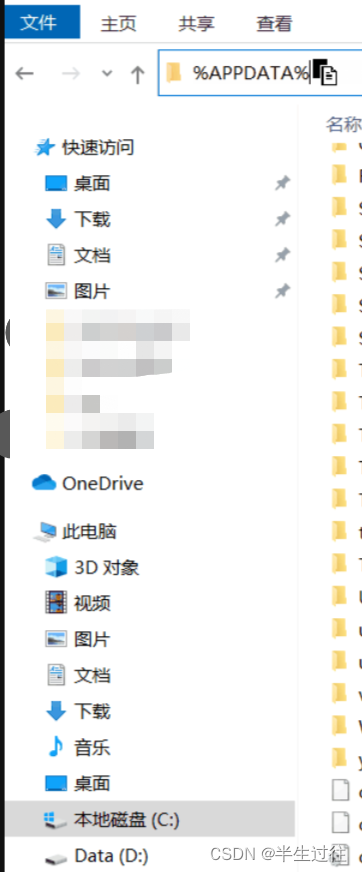[global]timeout = 6000 index-url = https://pypi.douban.com/simple/trusted-host = pypi.douban.com
timeout = 6000
index-url = https://pypi.douban.com/simple/
trusted-host = pypi.douban.com
二、Python安装三方模块
方法一:
使用命令安装
windows系统:pip install 模块名
mac、linux系统:pip3 install 模块名
卸载 :pip uninstall 模块名
显示安装列表:pip list
列出当前环境安装的模块名和版本号:pip freezepip freeze > file_name 将安装的模块名和版本号重定向输出到指定的文件 pip install -r file_name 读取文件里模块名和版本号并安装
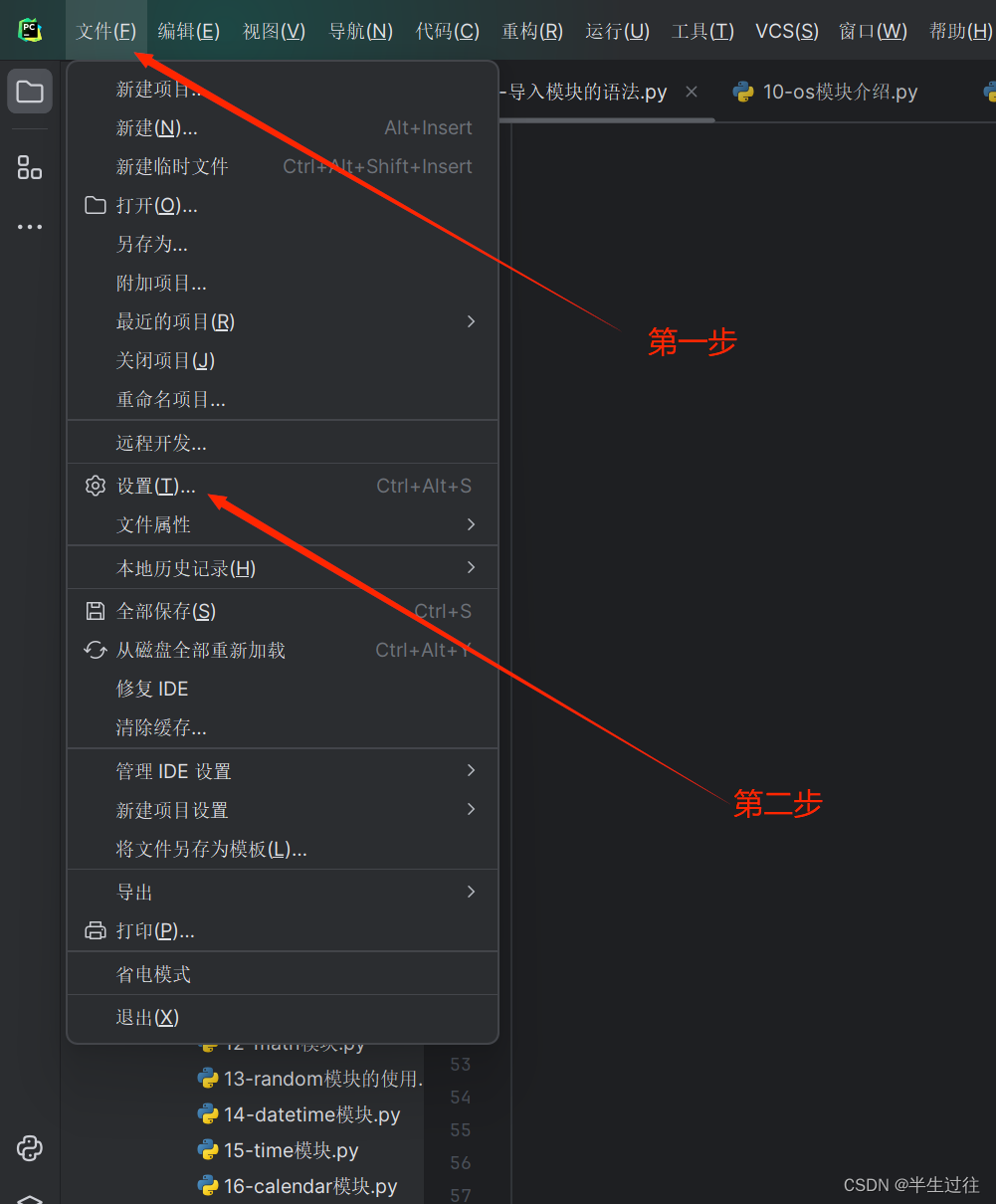
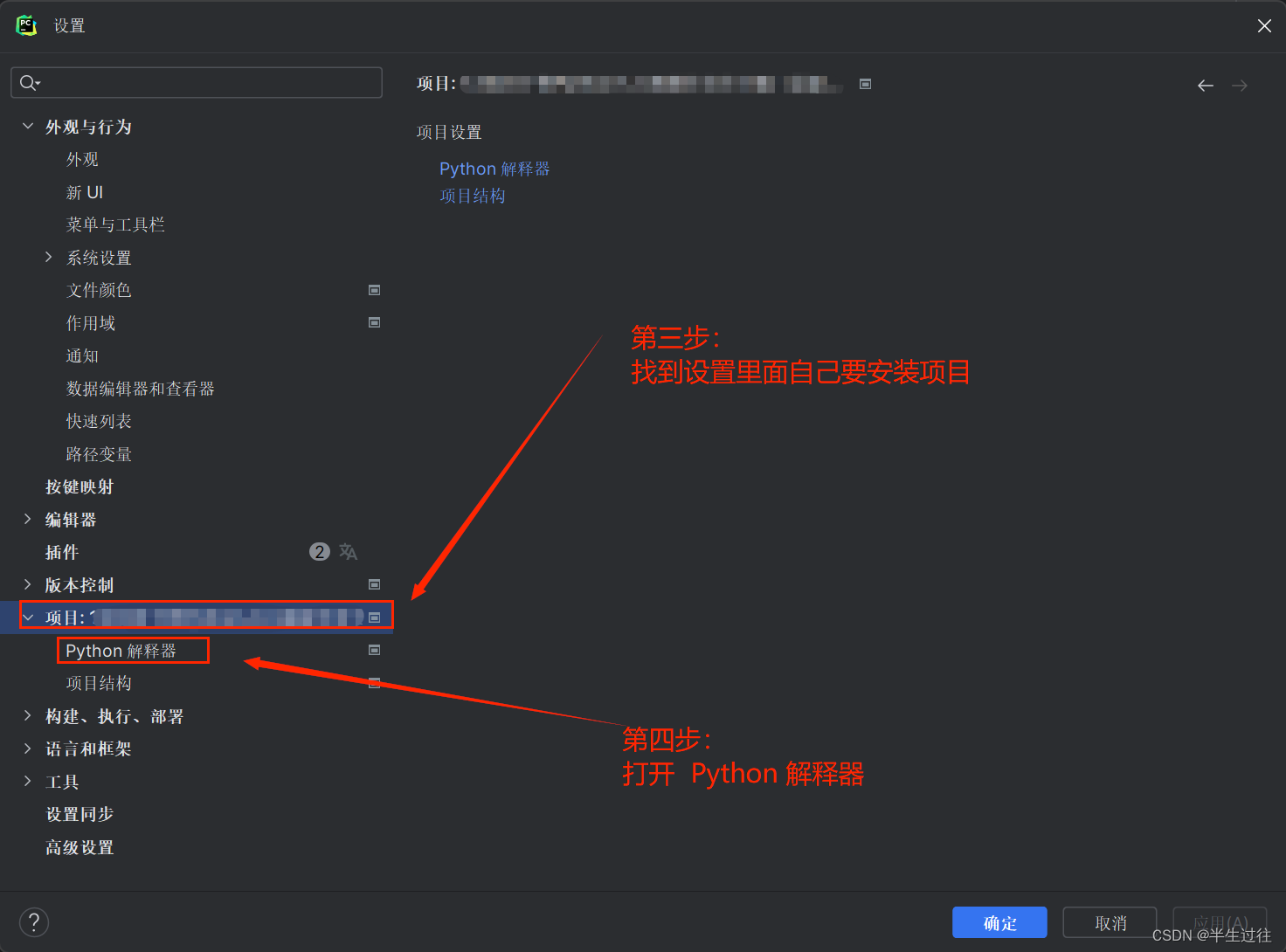
方法二:使用pycharm自带的可视化界面安装 【推荐 安装过程可以关闭安装的弹窗,在后台进行安装,不影响接下来的编码工作。】
setting --> project:项目名 --> python interpreter --> + --> 搜索模块名 --> install package
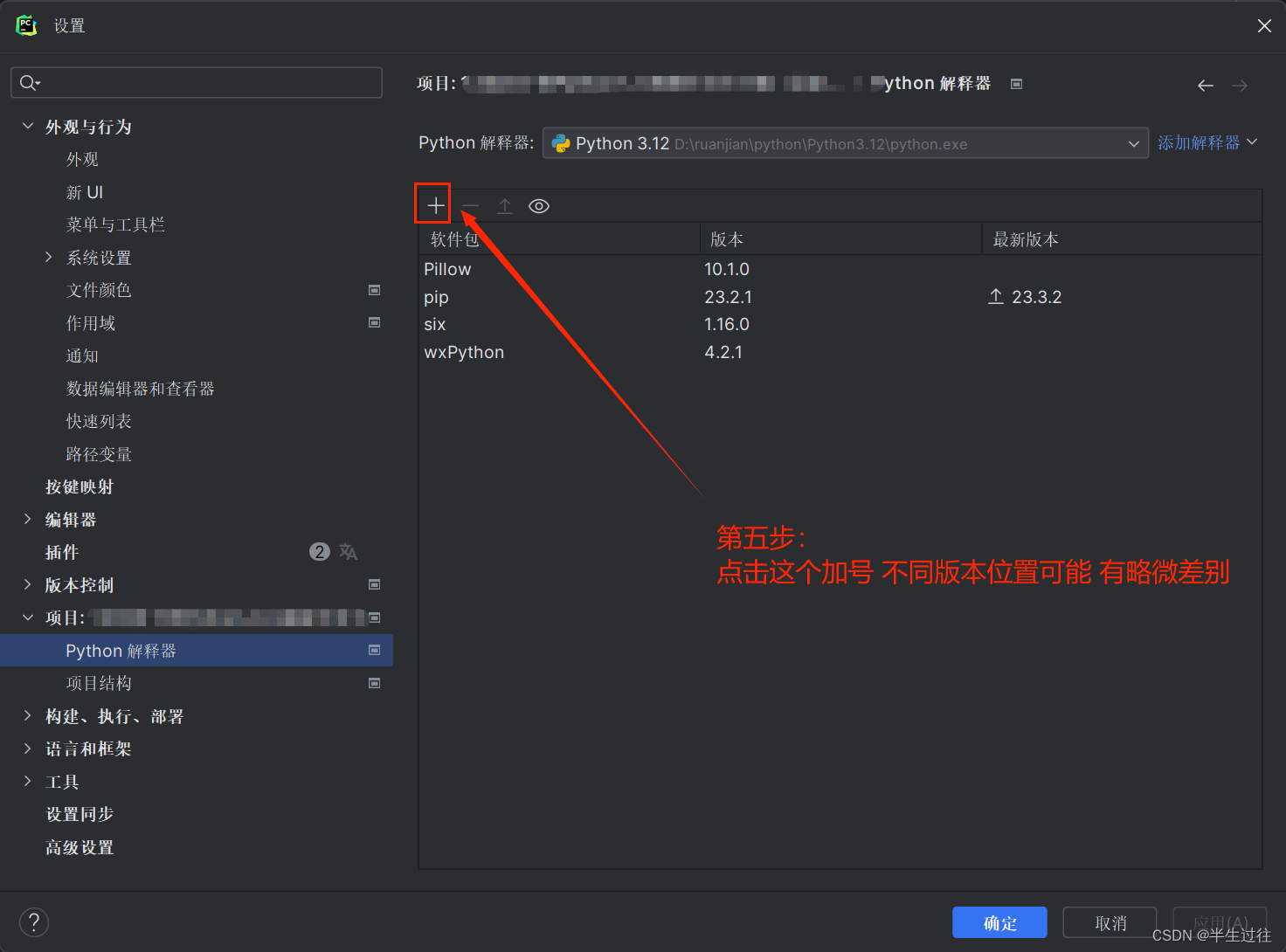
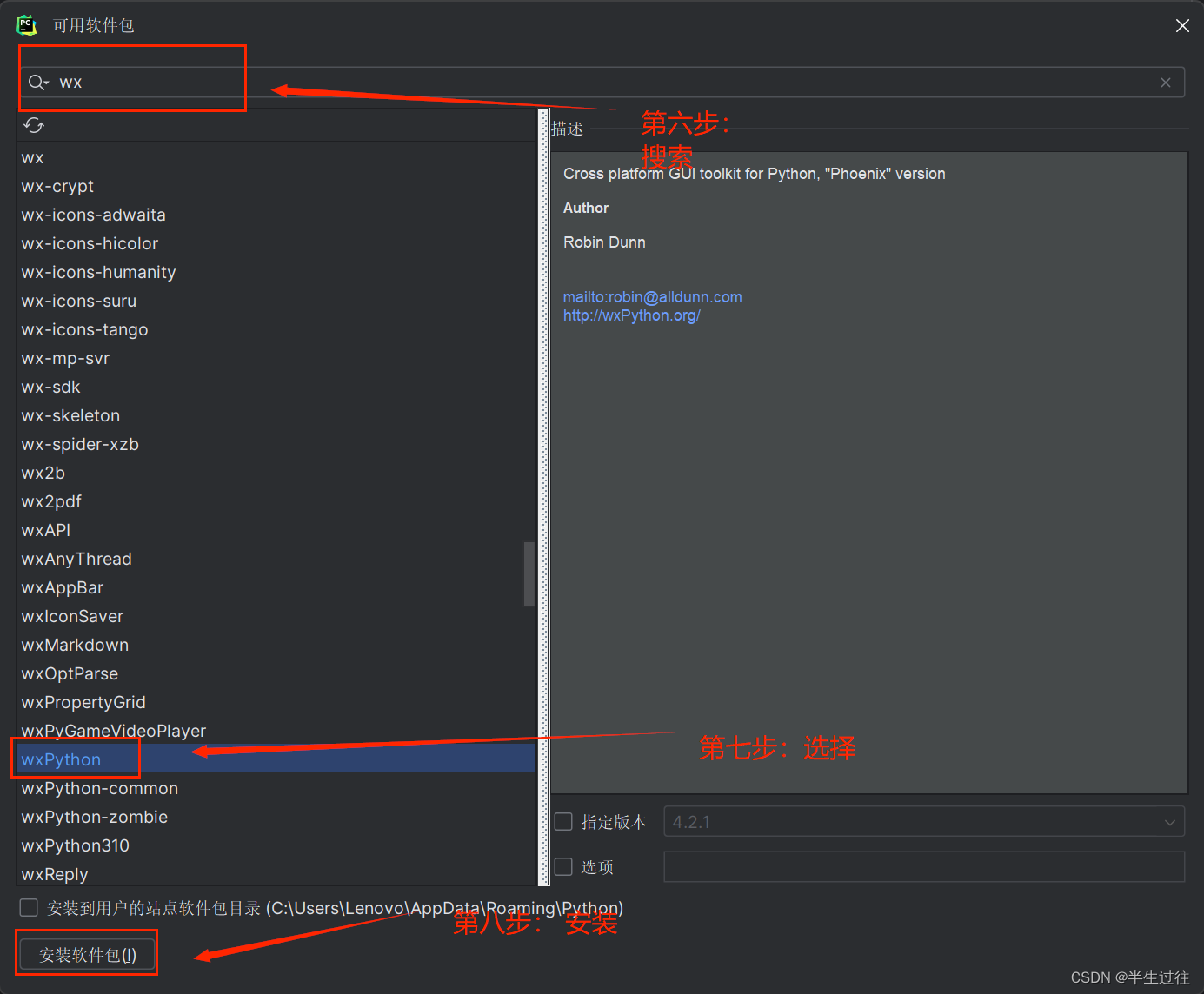
常用的内置模块
-
os 模块
-
# os全称 OperationSystem操作系统# os 模块里提供的方法就是用来调用操作系统里的方法import os# os.name ==> 获取操作系统的名字 windows系列 ==>nt / 非windows ==>posixprint(os.name) # ntprint(os.sep) # 路径的分隔符 windows \ 非windows /# os模块里的 path 经常会使用# abspath ==> 获取文件的绝对路径print(os.path.abspath('文件.py'))# isdir判断是否是文件夹print(os.path.isdir('文件.py')) # Falseprint(os.path.isdir('新建文件夹')) # True# isfile 判断是否是文件print(os.path.isfile('文件.py')) # Trueprint(os.path.isfile('新建文件夹')) # False# exists 判断是否存在print(os.path.exists('存在的.py')) # Trueprint(os.path.exists('mmm.py')) # Falsefile_name = '2020.2.21.demo.py'print(file_name.rpartition('.')) # ('2020.2.21.demo', '.', 'py')print(os.path.splitext(file_name)) # ('2020.2.21.demo', '.py')# os里其他方法的介绍# os.getcwd() # 获取当前的工作目录,即当前python脚本工作的目录# os.chdir('test') # 改变当前脚本工作目录,相当于shell下的cd命令# os.rename('毕业论文.txt','毕业论文-最终版.txt') # 文件重命名# os.remove('毕业论文.txt') # 删除文件# os.rmdir('demo') # 删除空文件夹# os.removedirs('demo') # 删除空文件夹# os.mkdir('demo') # 创建一个文件夹# os.chdir('C:\\') # 切换工作目录# os.listdir('C:\\') # 列出指定目录里的所有文件和文件夹# os.name # nt->widonws posix->Linux/Unix或者MacOS# os.environ # 获取到环境配置# os.environ.get('PATH') # 获取指定的环境配置
-
-
os 模块
-
# sys 系统相关的功能import sysprint(sys.path) # 结果是一个列表,表示查找模块的路径# sys.stdin # 可以像input一样,接收用户的输入。接收用户的输入,和 input 相关# sys.stdout 和 sys.stderr 默认都是在控制台# sys.stdout # 修改sys.stdout 可以改变默认输出位置# sys.stderr # 修改sys.stderr 可以改变错误输出的默认位置print('hello world') # 程序退出,和内置函数exit功能一致 并给一个退出码 100 正常的退出码应该是0 sys.exit(100) # 进程已结束,退出代码为 100 # 呵呵呵呵不会打印print('呵呵呵呵')
-
-
math 数学计算相关的模块
-
# 数学计算相关的模块import mathprint(math.fabs(-100)) # 取绝对值print(math.ceil(34.01)) #向上取整print(math.factorial(5)) # 计算阶乘print(math.floor(34.98)) # 向下取整# round() 内置函数,实现四舍五入到指定位数print(math.pi) # π的值,约等于 3.141592653589793print(math.pow(2, 10)) # 2的10次方print(math.sin(math.pi / 6)) # 正弦值print(math.cos(math.pi / 3)) # 余弦值print(math.tan(math.pi / 2)) # 正切值# 100.0# 35# 120# 34# 3.141592653589793# 1024.0# 0.49999999999999994# 0.5000000000000001# 1.633123935319537e+16
-
-
random模块
-
# random 模块主要用于生成随机数或者从一个列表里随机获取数据。print(random.random()) # 生成 [0,1)的随机浮点数print(random.uniform(20, 30)) # 生成[20,30]的随机浮点数print(random.randint(10, 30)) # 生成[10,30]的随机整数print(random.randrange(20, 30)) # 生成[20,30)的随机整数print(random.choice('abcdefg')) # 从列表里随机取出一个元素print(random.sample('abcdefghij', 3)) # 从列表里随机取出指定个数的元素
-
-
datetime模块
-
# datetime模块主要用来显示日期时间,这里主要涉及 date类,用来显示日期;time类,用来显示时间;dateteime类,用来显示日期时间;timedelta类用来计算时间。import datetime print(datetime.date(2020, 1, 1)) # 创建一个日期 print(datetime.time(18, 23, 45)) # 创建一个时间 print(datetime.datetime.now()) # 获取当前的日期时间 print(datetime.datetime.now() + datetime.timedelta(3)) # 计算三天以后的日期时间
-
-
time模块
-
# 除了使用datetime模块里的time类以外,Python还单独提供了另一个time模块,用来操作时间。time模块不仅可以用来显示时间,还可以控制程序,让程序暂停(使用sleep函数)print(time.time()) # 获取从1970-01-01 00:00:00 UTC 到现在时间的秒数print(time.strftime("%Y-%m-%d %H:%M:%S")) # 按照指定格式输出时间print(time.asctime()) #Mon Apr 15 20:03:23 2019print(time.ctime()) # Mon Apr 15 20:03:23 2019print('hello')print(time.sleep(10)) # 让线程暂停10秒钟print('world')
-
-
calendar模块
-
# calendar模块用来显示一个日历,使用的不多,了解即可。# 周一到周 日分别对应 0 ~ 6print( calendar.setfirstweekday(calendar.SUNDAY)) # 设置每周起始日期码。 6print(calendar.firstweekday()) # 返回当前每周起始日期的设置。默认情况下,首次载入 calendar模块时返回0,即星期一。c = calendar.calendar(2023) # 生成2023年的日历,并且以周日为其实日期码print(c) #打印2023年日历print(calendar.isleap(2014)) # True.闰年返回True,否则返回Falsecount = calendar.leapdays(1996,2014) # 获取1996年到2014年一共有多少个闰年print(calendar.month(2024, 1)) # 打印2024年1月的日历
-
-
hashlib模块模块 hmac模块
-
# 这两个模块都是用来进行数据加密# hashlib模块里主要支持两个算法 md5 和 sha 加密# 加密方式: 单向加密:只有加密的过程,不能解密md5/sha 对称加密 非对称加密rsa# hashlib是一个提供字符加密功能的模块,包含MD5和SHA的加密算法,具体支持md5,sha1, sha224, sha256, sha384, sha512等算法。 该模块在用户登录认证方面应用广泛,对文本加密也很常见。import hashlib# 待加密信息str = '这是一个测试'# 创建md5对象hl = hashlib.md5('hello'.encode(encoding='utf8'))print('MD5加密后为 :' + hl.hexdigest())h1 = hashlib.sha1('123456'.encode())print(h1.hexdigest())# 7c4a8d09ca3762af61e59520943dc26494f8941bh2 = hashlib.sha224('123456'.encode())# 224位 一个十六进制占4位print(h2.hexdigest())# f8cdb04495ded47615258f9dc6a3f4707fd2405434fefc3cbf4ef4e6h3 = hashlib.sha256('123456'.encode())print(h3.hexdigest())# 8d969eef6ecad3c29a3a629280e686cf0c3f5d5a86aff3ca12020c923adc6c92h4 = hashlib.sha384('123456'.encode())print(h4.hexdigest())# 0a989ebc4a77b56a6e2bb7b19d995d185ce44090c13e2984b7ecc6d446d4b61ea9991b76a4c2f04b1b4d244841449454# HMAC算法也是一种一种单项加密算法,并且它是基于上面各种哈希算法/散列算法的,只是它可以在运算过程中使用一个密钥来增增强安全性。hmac模块实现了HAMC算法,提供了相应的函数和方法,且与hashlib提供的api基本一致。import hmacprint("===hmac字符加密示例===")# 创建哈希对象# key和digestmod参数必须指定,key和msg(需要加密的内容)均为bytes类型,digestmod指定加密算法,比如‘md5’,'sha1’等hm = hmac.new(b'hash',b'helloworld',digestmod='sha1')print("hmac二进制加密:", hm.digest())print("hmac十六进制加密:", hm.hexdigest())print("===hmac中文加密示例===")ch = hmac.new("你好".encode(encoding="utf-8"), "世界".encode(encoding="utf-8"),digestmod='sha1')print("hmac二进制加密:", ch.digest())print("hmac十六进制加密:", ch.hexdigest())# ===hmac字符加密示例===# hmac二进制加密: b'\x85Bv\x94/\xbd\xab!wgQPW\xa13GO\xb0\xfd\x83'# hmac十六进制加密: 854276942fbdab217767515057a133474fb0fd83# ===hmac中文加密示例===# hmac二进制加密: b'\xf3\x9b*g"\xf2\x92iB\xa6\x0c\x80U@\x19X\xb7\x13\xd8\x1e'# hmac十六进制加密: f39b2a6722f2926942a60c8055401958b713d81e
-
-
copy模块
-
# copy模块里有copy和deepcopy两个函数,分别用来对数据进行深复制和浅复制。import copynums = [1, 5, 3, 8, [100, 200, 300, 400], 6, 7] nums1 = copy.copy(nums) # 对nums列表进行浅复制 nums2 = copy.deepcopy(nums) # 对nums列表进行深复制
-
-
uuid模块
-
方法 作用 uuid.uuid1() 基于MAC地址,时间戳,随机数来生成唯一的uuid,可以保证全球范围内的唯一性。 uuid.uuid2() 算法与uuid1相同,不同的是把时间戳的前4位置换为POSIX的UID。不过需要注意的是 python中没有基于DCE的算法,所以python的uuid模块中没有uuid2这个方法。uuid.uuid3(namespace,name) 通过计算一个命名空间和名字的md5散列值来给出一个uuid,所以可以保证命名空间中的不同名字具有不同的uuid,但是相同的名字就是相同的uuid了。namespace并不是一个自己手动指定的字符串或其他量,而是在uuid模块中本身给出的一些值。比如uuid.NAMESPACE_DNS,uuid.NAMESPACE_OID,uuid.NAMESPACE_OID这些值。这些值本身也是UUID对象,根据一定的规则计算得出。 uuid.uuid4() 通过伪随机数得到uuid,是有一定概率重复的 uuid.uuid5(namespace,name) uuid.uuid5(namespace,name) 和uuid3基本相同,只不过采用的散列算法是sha1 -
# 一般而言,在对uuid的需求不是很复杂的时候,uuid1或者uuid4方法就已经够用了,使用方法如下:import uuidprint(uuid.uuid1()) # 根据时间戳和机器码生成uuid,可以保证全球唯一print(uuid.uuid4()) # 随机生成uuid,可能会有重复# 使用命名空间和字符串生成uuid.# 注意一下两点:# 1. 命名空间不是随意输入的字符串,它也是一个uuid类型的数据# 2. 相同的命名空间和想到的字符串,生成的uuid是一样的print(uuid.uuid3(uuid.NAMESPACE_DNS, 'hello'))print(uuid.uuid5(uuid.NAMESPACE_OID, 'hello'))
-
自定义模块
除了使用系统提供的内置模块以外,我们还能自己写一个模块供自己的程序使用。一个py文件就是一个模块,所以,自定义模块很简单,基本上相当于创建一个py文件。但是,需要注意的是,如果一个py文件要作为一个模块被别的代码使用,这个py文件的名字一定要遵守标识符的命名规则。
__all__的使用
使用from <模块名> import *导入一个模块里所有的内容时,本质上是去查找这个模块的__all__属性,将__all__属性里声明的所有内容导入。如果这个模块里没有设置__all__属性,此时才会导入这个模块里的所有内容。
模块里的私有成员
模块里以一个下划线_开始的变量和函数,是模块里的私有成员,当模块被导入时,以_开头的变量默认不会被导入。但是它不具有强制性,如果一个代码强行使用以_开头的变量,有时也可以。但是强烈不建议这样使用,因为有可能会出问题。
# test1.py 文件:模块里没有__all__属性a = 'hello'
def fn():print('我是test1模块里的fn函数')
# test2.py 文件:模块里有__all__属性x = '你好'
y = 'good'
def foo():print('我是test2模块里的foo函数')
__all__ = ('x','foo')
# test3.py 文件:模块里有以_开头的属性m = '早上好'
_n = '下午好'
def _bar():print('我是test3里的bar函数')
# demo.py 文件from test1 import *
from test2 import *
from test3 import *print(a)
fn()print(x)
# print(y) 会报错,test2的__all__里没有变量 y
foo()print(m)
# print(_n) 会报错,导入test3时, _n 不会被导入import test3
print(test3._n) # 也可以强行使用,但是强烈不建议
__name__的使用
在实际开中,当一个开发人员编写完一个模块后,为了让模块能够在项目中达到想要的效果,这个开发人员会自行在py文件中添加一些测试信息,例如:
# test1.py 文件def add(a,b):return a+b# 这段代码应该只有直接运行这个文件进行测试时才要执行
# 如果别的代码导入本模块,这段代码不应该被执行
ret = add(12,22)
print('测试的结果是',ret)
# demo.py 文件import test1.py # 只要导入了tets1.py,就会立刻执行 test1.py 代码,打印测试内容
为了解决这个问题,python在执行一个文件时有个变量__name__.在Python中,当直接运行一个py文件时,这个py文件里的__name__值是__main__,据此可以判断一个一个py文件是被直接执行还是以模块的形式被导入。
name:当直接运行这个py文件的时候,值是__main__
如果这个py文件作为一个模块导入的时候,值是文件名
def add(a,b):return a+bif __name__ == '__main__': # 只有直接执行这个py文件时,__name__的值才是 __main__# 以下代码只有直接运行这个文件才会执行,如果是文件被别的代码导入,下面的代码不会执行ret = add(12,22)print('测试的结果是',ret)
包的使用
一个模块就是一个 py 文件,在 Python里为了对模块分类管理,就需要划分不同的文件夹。多个有联系的模块可以将其放到同一个文件夹下,为了称呼方便,一般把 Python里的一个代码文件夹称为一个包。里面的各个模块可以正常创建
-
PyCharm 中创建 Python 包
右键点击 PyCharm 中的 Python 工程根目录 , 选择 " New / Python Package " 选项 ,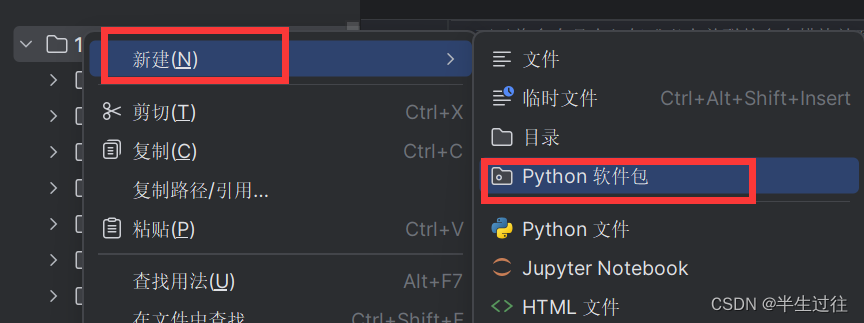
输入 Python 包名称 , 然后点击回车 , 创建 Python 包 ;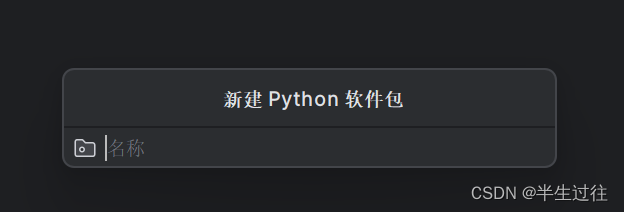
创建完成后 , 自动生成了一个 my_package 目录 , 该目录下自动生成了一个 __init__.py 文件 ;
__init__.py代码
__init__.py源码文件可以空着 , 但是必须要有 , 这是 Python 包的标志 ;
有了__init__.py源码文件之后 , 该目录才会被当做包对待
所以也可以直接去手动创建__init__.py空文件
普通目录图标与 包目录图标会与区别——中间有个点 (如下图)
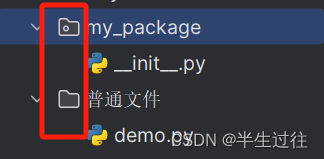
现有以下包newmsg,包里由两个模块,分别是sendmsg.py、recvmsg.py文件。在包的上级文件夹里,有一个test.py文件,
使用__init__.py文件,结合__all__属性,导入包里的所有模块。# 在newmsg包里的__init__.py文件里编写代码:__all__ = ["sendmsg","recvmsg"] # 指定导入的内容# test.py文件代码:from newmsg import * # 将newmsg里的__inint__.py文件里,__all__属性对应的所有模块都导入 sendmsg.sendmsg() recvmsg.recvmsg()
类与对象【面向对象】
面向过程:根据业务逻辑从上到下写代码。
面向对象:将变量与函数绑定到一起,分类进行封装,每个程序只要负责分配给自己的分类,这样能够更快速的开发程序,减少了重复代码。
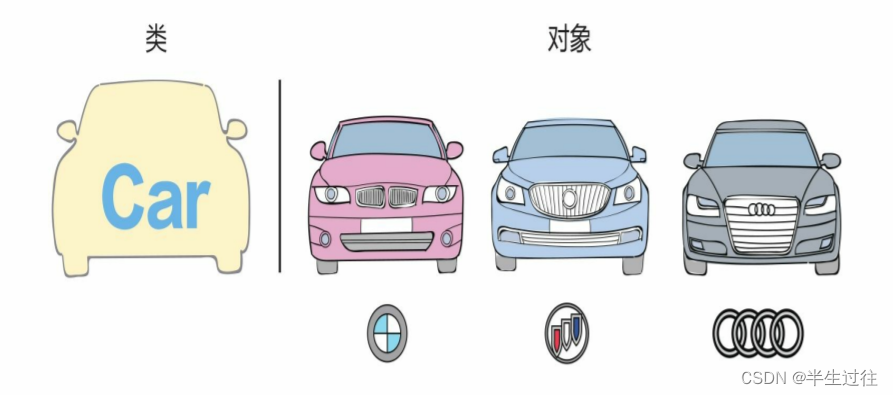
面向对象编程有三大特性: 封装、继承和多态
封装: 函数是对语句的封装;类是对函数和变量的封装 继承: 类和类之间可以认为手动的建立父子关系,父类的属性和方法,子类可以使用 多态: 是一种技巧,提高代码的灵活度
定义简单的类(只包含方法)
面向对象是更大的封装,在一个类中封装多个方法,这样通过这个类创建出来的对象,就可以直接调用这些方法了!
定义类 :使用 class 来定义一个类
在Python中要定义一个只包含方法的类,语法格式如下:
class 类名:
def 方法1(self,参数列表):
pass
def 方法2(self,参数列表):
pass
方法的定义格式和之前学习过的函数一样
方法里的 第一个参数必须是self,大家暂时先记住,稍后介绍 self.
类名要遵守大驼峰命名法。
魔法方法
也叫魔术方法,是内里的特殊的一些方法
- 特点:
1.不需要手动调用,会在合适的时机自动调用
2.这些方法,都是使用 __ 开始,使用 __ 结束(两个下_开始,两个_结束的方法)
3.方法名都是系统规定好的,在合适的时机自己调用
__init__方法
1.__init__()方法在创建对象时,会默认被调用,不需要手动的调用这个方法。
2.__init__()方法里的self参数,在创建对象时不需要传递参数,python解释器会把创建好的对象引用直接赋值给self
3.在类的内部,可以使用self来使用属性和调用方法;在类的外部,需要使用对象名来使用属性和调用方法。
4.如果有多个对象,每个对象的属性是各自保存的,都有各自独立的地址。
5.方法是所有对象共享的,只占用一份内存空间,方法被调用时会通过self来判断是哪个对象调用了实例方法。
__del__方法
1.创建对象后,python解释器默认调用__init__()方法
2.而当删除对象时,python解释器也会默认调用一个方法,这个方法为__del__()方法。
__str__方法
1.__str__方法返回对象的描述信息,使用print()函数打印对象时,其实调用的就是这个对象的__str__方法。
2.如果想要修改对象的输出的结果,可以重写__str__方法。
3.一般情况下,我们在打印一个对象时,可能需要列出这个对象的所有属性。class Person: def __init__(self,name,age):self.name = nameself.age = agedef __str__(self):return '哈哈'p = Person('张三',18) print(p) # 哈哈 打印对象时,会自动调用对象的 __str__ 方法class Student:def __init__(self,name,score):self.name = nameself.score = scoredef __str__(self):return '姓名是:{},成绩是{}分'.format(self.name,self.score)s = Student('lisi',95) print(s) # 姓名是:lisi,成绩是95分
__repr__方法
1.__repr__方法和__str__方法功能类似,都是用来修改一个对象的默认打印内容。在打印一个对象时,如果没有重写__str__方法,它会自动来查找__repr__方法。如果这两个方法都没有,会直接打印这个对象的内存地址。class Student:def __init__(self, name, score):self.name = nameself.score = scoredef __repr__(self):return 'helllo'class Person:def __repr__(self):return 'hi'def __str__(self):return 'good's = Student('lisi', 95) print(s) # hellop = Person() print(p) # good
__call__方法
1.对象后面加括号,触发执行。class Foo:def __init__(self):passdef __call__(self, *args, **kwargs):print('__call__')obj = Foo() # 执行 __init__obj() # 执行 __call__
当创建一个对象时,会自动调用__init__方法,当删除一个对象时,会自动调用__del__方法。
使用__str__和__repr__方法,都会修改一个对象转换成为字符串的结果。一般来说,__str__方法的结果更加在意可读性,而__repr__方法的结果更加在意正确性(例如:datetime模块里的datetime类)
class Person(object):def __init__(self, name, age):# 在创建对象时,会自动调用这个方法print('__init__方法被调用了')self.name = nameself.age = agedef __del__(self):# 当对象被销毁时,会自动调用这个方法print('__del__ 方法被调用了')def __repr__(self):return 'hello'def __str__(self):return '姓名:{},年龄:{}'.format(self.name, self.age)def __call__(self, *args, **kwargs):# print('__call__ 方法被调用了')# args = (1, 2, 4, 5),kwargs = {'m':'good', 'n':'hehehe', 'p':'heiheihei'}print('args={},kwargs={}'.format(args, kwargs))p = Person('zhangsan', 18)# 如果不做任何的修改,直接打印一个对象,是文件的 __name__.类型 内存地址
# print(p) # <__main__.Person object at 0x00000217467AEA08># 当打印一个对象的时候,会调用这个对象的 __str__ 或者 __repr__ 方法
# 如果两个方法都写了,选择 __str__
print(p)# print(repr(p)) # 调用内置函数 repr 会触发对象的 __repr__ 方法
# print(p.__repr__()) # 魔法方法,一般不手动的调用p(1, 2, 4, 5, m='good', n='hehehe', p='heiheihei') # 对象名() ==> 调用这个对象的 p.__call__() 方法# 打印结果如下
# __init__方法被调用了
# 姓名:zhangsan,年龄:18
# args=(1, 2, 4, 5),kwargs={'m': 'good', 'n': 'hehehe', 'p': 'heiheihei'}
# __del__ 方法被调用了
self的使用
给对象添加属性
python支持动态属性,当一个对象创建好了以后,直接使用对象.属性名 = 属性值就可以很方便的给对象添加一个属性。
哪个对象调用了方法,方法里的self指的就是谁。 通过self.属性名可以访问到这个对象的属性;通过self.方法名()可以调用这个对象的方法。
调用__new__方法,用来申请内存空间
调用__init__方法传入参数,将 self 指向创建好的内存空间,填充数据
__slots__这个属性直接定义在类里,是一个元组,用来规定对象可以存在的属性
class Student(object):# 这个属性直接定义在类里,是一个元组,用来规定对象可以存在的属性# 这里面没有的属性 下方都不可以调用,会报错__slots__ = ('name', 'age', 'city')def __init__(self, x, y):self.name = xself.age = ydef say_hello(self):print('大家好,我是', self.name)# Student('张三',18) 这段代码具体做了什么呢?
# 1. 调用 __new__ 方法,用来申请内存空间
# 2. 调用 __init__ 方法传入参数,将 self 指向创建好的内存空间,填充数据
# 3. 变量 s 也指向创建好的内存空间
s = Student('张三', 18)print(s.name) # 张三
s.say_hello() # 大家好,我是 张三# 没有属性,会报错
# print(s.height)# 直接使用等号给一个属性赋值
# 如果这个属性以前不存在,会给对象添加一个新的属性
# 动态属性
s.city = '上海' # 给对象添加了一个city属性
print(s.city) # 上海# 如果这个属性以前存在,会修改这个属性对应的值
s.name = 'jack'
print(s.name) # jack
__eq__方法
运算相关的魔法方法
== 运算符本质其实是调用对象的__eq__方法,获取__eq__方法的返回结果
!= 本质是调用__ne__方法 或者__eq__方法取反class Person:def __init__(self,name,age):self.name = nameself.age = agep1 = Person('zhangsan',18) p2 = Person('zhangsan',18) p2 = Person('zhangsan',19)# p1 和 p2 不是同一个对象,比较内存地址 print('0x%X' % id(p1)) # 0x20CE2A8EE88 print('0x%X' % id(p2)) # 0x20CE2A8EF08# is 身份运算符 可以用来判断两个对象是否是同一个对象 print('p1 is p2', p1 is p2) # Falseprint(p1 == p2) # false print(p1 == p3) # false比较运算符相关魔法方法
__eq__如果不重写,默认比较依然是内存地址class Student:def __init__(self, name, age):self.name = nameself.age = age# 使用== 运算符会自动调用这个方法def __eq__(self, other):return self.name == other.name and self.age == other.age# 使用 != 运算符会自动调用这个方法# def __ne__(self, other): # 使用 <运算符会自动调用这个方法def __lt__(self, other): return self.age < other.age# greater than 使用 > 会自动调用这个方法 # def __gt__(self, other): # 使用 <=运算符会自动调用这个方法def __le__(self, other): return self.age <= other.age# 使用 >= 运算符会自动调用# def __ge__(self, other): s1 = Student('zhangsan', 18) s2 = Student('zhangsan', 18) s3 = Student('lisi', 20) print(s1 == s2) print(s1 != s2) print(s1 > s2) print(s1 >= s2) print(s1 <= s2) print(s1 <= s2)# True # False # False # True # True # True算数运算符相关魔法方法
class Student:def __init__(self, name, age):self.name = nameself.age = age# 使用 >= 运算符会自动调用def __add__(self, other): return self.age + other# 使用 - 运算符会自动调用def __sub__(self, other):return self.age - other# 使用 * 运算符会自动调用def __mul__(self, other):return self.age * other# 使用 / 运算符会自动调用def __truediv__(self, other):return self.age / other# 使用 % 运算符会自动调用def __mod__(self, other):return self.age % other# 使用** 运算符会自动调用def __pow__(self, power, modulo=None):return self.age ** powers = Student('zhangsan', 18) print(s + 1) # 19 print(s - 2) # 16 print(s * 2) # 36 print(s / 5) # 3.6 print(s % 5) # 3 print(s ** 2) # 324类型转换相关魔法方法
class Student:def __init__(self, name, age):self.name = nameself.age = agedef __int__(self):return self.agedef __float__(self):return self.age * 1.0def __str__(self):return self.namedef __bool__(self):return self.age > 18s = Student('zhangsan', 18) print(int(s)) # 18 print(float(s)) # 18.0 print(str(s)) # zhangsan print(bool(s)) # Falseif s:print('hello')
面向对象 练习
# 房子(House) 有 户型、总面积 、剩余面积(等于总面积的60%) 和 家具名称列表 属性
# 新房子没有任何的家具
# 将 家具的名称 追加到 家具名称列表 中
# 判断 家具的面积 是否 超过剩余面积,如果超过,提示不能添加这件家具# 家具(Furniture) 有 名字 和 占地面积属性,其中
# 席梦思(bed) 占地 4 平米
# 衣柜(chest) 占地 2 平米
# 餐桌(table) 占地 1.5 平米
# 将以上三件 家具 添加 到 房子 中
# 打印房子时,要求输出:户型、总面积、剩余面积、家具名称列表class House(object):# 缺省参数def __init__(self, house_type, total_area, fru_list=None):if fru_list is None: # 如果这个值是Nonefru_list = [] # 将fru_list设置为空列表self.house_type = house_typeself.total_area = total_areaself.free_area = total_area * 0.6self.fru_list = fru_listdef add_fru(self, x): # x = bedif self.free_area < x.area:print('剩余面积不足,放不进去了')else:self.fru_list.append(x.name)self.free_area -= x.area# def __repr__(self):def __str__(self):return '户型={},总面积={},剩余面积={},家具列表={}'.format(self.house_type, self.total_area, self.free_area, self.fru_list)class Furniture(object):def __init__(self, name, area):self.name = nameself.area = area# 创建房间对象的时候,传入户型和总面积
house = House('一室一厅', 20) # 12sofa = Furniture('沙发', 10)
bed = Furniture('席梦思', 4)
chest = Furniture('衣柜', 2)
table = Furniture('餐桌', 1.5)# 把家具添加到房间里(面向对象关注点:让谁做)
house.add_fru(sofa)
house.add_fru(bed)
house.add_fru(chest)
house.add_fru(table)print(house) # print打印一个对象的时候,会调用这个对象的__repr__或者__str__ 方法,获取它们的返回值# 剩余面积不足,放不进去了
# 剩余面积不足,放不进去了
# 户型=一室一厅,总面积=20,剩余面积=0.0,家具列表=['沙发', '衣柜']
内置属性
使用内置函数
dir()可以查看一个对象支持的所有属性和方法,Python中存在着很多的内置属性。
类名.__dir__()等同于dir(类名)
___slots__
Python中支持动态属性,可以直接通过点语法直接给一个对象添加属性,代码更加的灵活。但是在某些情况下,我们可能需要对属性进行控制,此时,就剋使用__slots__实现。class Person(object):__slots__ = ('name', 'age')def __init__(self, name, age):self.name = nameself.age = age p = Person('张三', 18) p.name = '李四'# 对象p只能设置name和age属性,不能再动态添加属性 # p.height = 180 # 报错
__doc__
表示类的描述信息。class Foo:""" 描述类信息,这是用于…… """def func(self):passprint(Foo.__doc__) #输出: 描述类信息,这是用于……
__module__和__class__
__module__表示当前操作的对象在那个模块;
__class__表示当前操作的对象的类是什么。# test.py class Person(object):def __init__(self):self.name = 'laowang'# main.pyfrom test import Personobj = Person() print(obj.__module__) # 输出 test 即:输出模块 print(obj.__class__) # 输出 test.Person 即:输出类
__dict__
以字典的形式,显示对象所有的属性和方法。class Province(object):country = 'China'def __init__(self, name, count):self.name = nameself.count = countdef func(self, *args, **kwargs):print('func')# 获取类的属性,即:类属性、方法、 print(Province.__dict__) # 输出:{'__dict__': <attribute '__dict__' of 'Province' objects>, '__module__': '__main__', 'country': 'China', '__doc__': None, '__weakref__': <attribute '__weakref__' of 'Province' objects>, 'func': <function Province.func at 0x101897950>, '__init__': <function Province.__init__ at 0x1018978c8>}obj1 = Province('山东', 10000) print(obj1.__dict__) # 获取 对象obj1 的属性 # 输出:{'count': 10000, 'name': '山东'}obj2 = Province('山西', 20000) print(obj2.__dict__) # 获取 对象obj1 的属性 # 输出:{'count': 20000, 'name': '山西'}
__getitem____setitem__和__delitem__方法
这三个方法,是将对象当做字典一样进行操作。class Foo(object):def __getitem__(self, key):print('__getitem__', key)def __setitem__(self, key, value):print('__setitem__', key, value)def __delitem__(self, key):print('__delitem__', key)obj = Foo()result = obj['k1'] # 自动触发执行 __getitem__ obj['k2'] = 'laowang' # 自动触发执行 __setitem__ del obj['k1'] # 自动触发执行 __delitem__
类属性和对象属性
实例属性
通过类创建的对象被称为 实例对象,对象属性又称为实例属性,记录对象各自的数据,不同对象的同名实例属性,记录的数据各自独立,互不干扰。
class Person(object):def __init__(self,name,age):# 这里的name和age都属于是实例属性,每个实例在创建时,都有自己的属性self.name = nameself.age = age# 每创建一个对象,这个对象就有自己的name和age属性
p1 = Person('张三',18)
p2 = Person("李四",20)
类属性
类属性就是类对象所拥有的属性,它被该类的所有实例对象所共有,类属性可以通过类对象或者实例对象访问。
class Dog:type = "狗" # 类属性dog1 = Dog()
dog2 = Dog()# 不管是dog1、dog2还是Dog类,都可以访问到type属性
print(Dog.type) # 结果:狗
print(dog1.type) # 结果:狗
print(dog2.type) # 结果:狗
使用场景:
类的实例记录的某项数据始终保持一致时,则定义类属性。
实例属性要求每个对象为其单独开辟一份内存空间来记录数据,而类属性为全类所共有 ,仅占用一份内存,更加节省内存空间。
- 注意点:
-
尽量避免类属性和实例属性同名。如果有同名实例属性,实例对象会优先访问实例属性。
class Dog(object):type = "狗" # 类属性def __init__(self):self.type = "dog" # 对象属性# 创建对象 dog1 = Dog()print(dog1.type) # 结果为 “dog” 类属性和实例属性同名,使用 实例对象 访问的是 实例属性 -
类属性只能通过类对象修改,不能通过实例对象修改
lass Dog(object):type = "狗" # 类属性# 创建对象 dog1 = Dog() dog1.type = "dog" # 使用 实例对象 创建了对象属性typeprint(dog1.type) # 结果为 “dog” 类属性和实例属性同名,访问的是实例属性print(Dog.type) # 结果为 "狗" 访问类属性# 只有使用类名才能修改类属性 Dog.type = "土狗" print(Dog.type) # 土狗 dog2 = Dog() print(dog2.type) # 土狗 -
类属性也可以设置为私有,前边添加两个下划线。 如:
class Dog(object):count = 0 # 公有的类属性__type = "狗" # 私有的类属性print(Dog.count) # 正确 print(Dog.__type) # 错误,私有属性,外部无法访问。
-
私有属性和方法
在实际开发中,对象的某些属性或者方法可能只希望在对象的内部别使用,而不希望在外部被访问到,这时就可以定义私有属性和私有方法。
定义方法
在定义属性或方法时,在属性名或者方法名前增加两个下划线__,定义的就是私有属性或方法。
class Person:def __init__(self,name,age):self.name = nameself.age = ageself.__money = 2000 # 使用 __ 修饰的属性,是私有属性def __shopping(self, cost):self.__money -= cost # __money 只能在对象内部使用print('还剩下%d元'%self.__money)def test(self):self.__shopping(200) # __shopping 方法也只能在对象内部使用p = Person('张三',18)
# print(p.__money) 这里会报错,不能直接访问对象内部的私有属性
p.test()
# p.__shopping() 这里会报错,__shopping 只能在对象内部使用,外部无法访问访问私有属性和方法
私有属性不能直接使用,私有方法不能直接调用。但是,通过一些代码,我们也可以在外部访问一个对象的私有属性和方法。
直接访问
使用方式:在私有属性名或方法名前添加 _类名
class Person:def __init__(self,name,age):self.name = nameself.age = ageself.__money = 2000def __shopping(self, cost):self.__money -= costp = Person('李四',20)
print(p._Person__money) # 使用对象名._类名__私有属性名 可以直接访问对象的私有属性
p._Person__shopping(100) # 使用对象名._类名__函数名 可以直接调用对象的私有方法
print(p._Person__money)
注意:在开发中,我们强烈不建议使用 对象名._类名__私有属性名 的方式来访问对象的私有属性!
定义方法访问私有变量
在实际开发中,如果对象的变量使用了__ 来修饰,就说明它是一个私有变量,不建议外部直接使用和修改。如果硬要修改这个属性,可以使用定义get和set方法这种方式来实现。
class Person:def __init__(self,name,age):self.name = nameself.age = ageself.__money = 2000 # __money 是私有变量,外部无法访问def get_money(self): # 定义了get_money 方法,在这个方法里获取到 __moneyreturn self.__money # 内部可以访问 __money 变量def set_money(self,money): # 定义了set_money 方法,在这个方法里,可以修改 __moneyself.__money = moneyp = Person('王五',21)# 外部通过调用 get_money 和 set_money 这两个公开方法获取和修改私有变量
print(p.get_money())
p.set_money(8000)
print(p.get_money())
类方法、静态方法
-
类方法
第一个形参是类对象的方法
需要用装饰器@classmethod来标识其为类方法,对于类方法,第一个参数必须是类对象,一般以cls作为第一个参数。class Dog(object):__type = "狗"# 类方法,用classmethod来进行修饰@classmethoddef get_type(cls):return cls.__type print(Dog.get_type())使用场景:
当方法中 需要使用类对象 (如访问私有类属性等)时,
定义类方法 类方法一般和类属性配合使用 -
静态方法
需要通过装饰器@staticmethod来进行修饰,静态方法既不需要传递类对象也不需要传递实例对象(形参没有self/cls)。
静态方法 也能够通过 实例对象 和 类对象 去访问。class Dog(object):type = "狗"def __init__(self):name = None# 静态方法 @staticmethoddef introduce(): # 静态方法不会自动传递实例对象和类对象print("犬科哺乳动物,属于食肉目..")dog1 = Dog() Dog.introduce() # 可以用 实例对象 来调用 静态方法 dog1.introduce() # 可以用 类对象 来调用 静态方法使用场景:
当方法中 既不需要使用实例对象(如实例对象,实例属性),也不需要使用类对象 (如类属性、类方法、创建实例等)时,定义静态方法
取消不需要的参数传递,有利于 减少不必要的内存占用和性能消耗 -
注意点:
类中定义了同名的方法时,调用方法会执行最后定义的方法class Dog:def demo_method(self):print("对象方法")@classmethoddef demo_method(cls):print("类方法")@staticmethoddef demo_method(): # 被最后定义print("静态方法")dog1 = Dog() Dog.demo_method() # 结果: 静态方法 dog1.demo_method() # 结果: 静态方法
class Person(object):type = 'human'def __init__(self, name, age):self.name = nameself.age = agedef eat(self, food): # 对象方法有一个参数self,指的是实例对象print(self.name + '正在吃' + food)# 如果一个方法里没有用到实例对象的任何属性,可以将这个方法成static@staticmethoddef demo():print('hello')@classmethoddef test(cls): # 如果这个函数只用到了类属性,我们可以把定义成为一个类方法# 类方法会有一个参数 cls,也不需要手动的传参,会自动传参# cls 指的是类对象 cls is Personprint(cls.type)print('yes')p1 = Person('张三', 18)
# 实例对象在调用方法时,不需要给形参self传参,会自动的把实例对象传递给selfp2 = Person('李四', 19)# eat 对象方法,可以直接使用实例对象.方法名(参数)调用
# 使用对象名.方法名(参数)调用的方式,不需要传递self
# 会自动将对象名传递给self
p1.eat('红烧牛肉泡面') # 直接使用实例对象调用方法# 张三正在吃红烧牛肉泡面# 对象方法还可以使用 类对象来调用类名.方法名()
# 这种方式,不会自动给self传参,需要手动的指定self
Person.eat(p2, '西红柿鸡蛋盖饭')
# 李四正在吃西红柿鸡蛋盖饭# print(p1.eat)
# print(p2.eat)
# print(Person.eat)# 静态方法:没有用到实例对象的任何属性
Person.demo() # hello
p1.demo() # hello
#
# # 类方法:可以使用实例对象和类对象调用
p1.test()
# human
# yes
Person.test()
# human
# yes
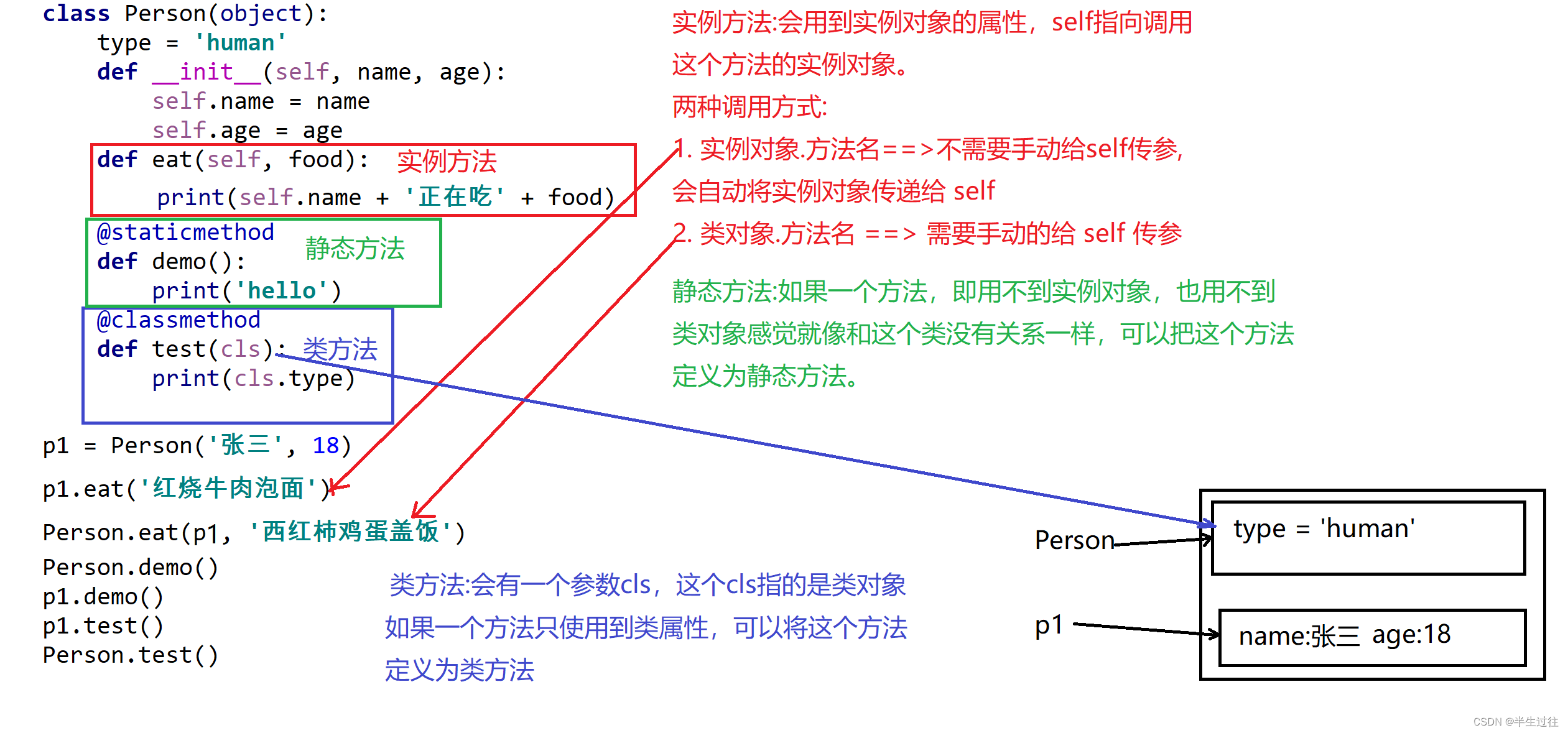
子类重写父类方法
# 继承特点:如果一个类A继承自类B,由类A创建出来的实例对象都能直接使用类B里定义的方法class Person(object):def __init__(self, name, age):self.name = nameself.age = agedef sleep(self):print(self.name + '正在睡觉')class Student(Person):def __init__(self, name, age, school):# self.name = name# self.age = age# 子类在父类实现的基础上,又添加了自己新的功能# 调用父类方法的两种方式:# 1. 父类名.方法名(self,参数列表)# Person.__init__(self, name, age)# 2. 使用super直接调用父类的方法。推荐使用第二种方式super(Student, self).__init__(name, age)self.school = schooldef sleep(self):print(self.name + '正在课间休息时睡觉')def study(self):print(self.name + '正在学习')s = Student('jerry', 20, '春田花花幼稚园') # 调用了父类的 __init__ 方法
s.sleep() # 调用了父类的 sleep方法
print(Student.__mro__)# 1. 子类的实现和父类的实现完全不一样,子类可以选择重写父类的方法。
# 2. 子类在父类的基础上又有更多的实现单例设计模式
__new__和__init__方法
class A(object):def __init__(self):print("这是 init 方法")def __new__(cls):print("这是 new 方法")return object.__new__(cls)A()
- .
__new__至少要有一个参数cls,代表要实例化的类,此参数在实例化时由Python解释器自动提供- .
__new__必须要有返回值,返回实例化出来的实例,这点在自己实现__new__时要特别注意,可以return父类__new__出来的实例,或者直接是object的__new__出来的实例- .
__init__有一个参数self,就是这个__new__返回的实例,__init__在__new__的基础上可以完成一些其它初始化的动作,__init__不需要返回值
-
举个常见的单例模式例子,我们日常使用的电脑上都有一个回收站,在整个操作系统中,回收站只能有一个实例,整个系统都使用这个唯一的实例,而且回收站自行提供自己的实例。因此回收站是单例模式的应用。
确保某一个类只有一个实例,而且自行实例化并向整个系统提供这个实例,这个类称为单例类,单例模式是一种对象创建型模式。
# 实例化一个单例 class Singleton(object):__instance = None__is_first = Truedef __new__(cls, age, name):if not cls.__instance:cls.__instance = object.__new__(cls)return cls.__instancedef __init__(self, age, name):if self. __is_first: # 不会再创建第二个对象self.age = ageself.name = nameSingleton. __is_first = Falsea = Singleton(18, "张三") b = Singleton(28, "张三")print(id(a)) print(id(b))print(a.age) # 18 print(b.age) # 18a.age = 19 print(b.age)
class Singleton:__instance = None # 类属性__is_first = True@classmethoddef __new__(cls, *args, **kwargs):if cls.__instance is None:# 申请内存,创建一个对象,并把对象的类型设置为clscls.__instance = object.__new__(cls)return cls.__instancedef __init__(self, a, b):if self.__is_first:self.a = aself.b = bself.__is_first = False# 调用 __new__ 方法申请内存
# 如果不重写 __new__ 方法,会调用 object 的 __new__ 方法
# object的 __new__ 方法会申请内存
# 如果重写了 __new__ 方法,需要自己手动的申请内存
s1 = Singleton('呵呵', '嘿嘿嘿')
s2 = Singleton('哈哈', '嘻嘻嘻')
s3 = Singleton('嘎嘎', '嘤嘤嘤')print(s1 is s2) # True
print(s1.a, s1.b) # 呵呵 嘿嘿嘿
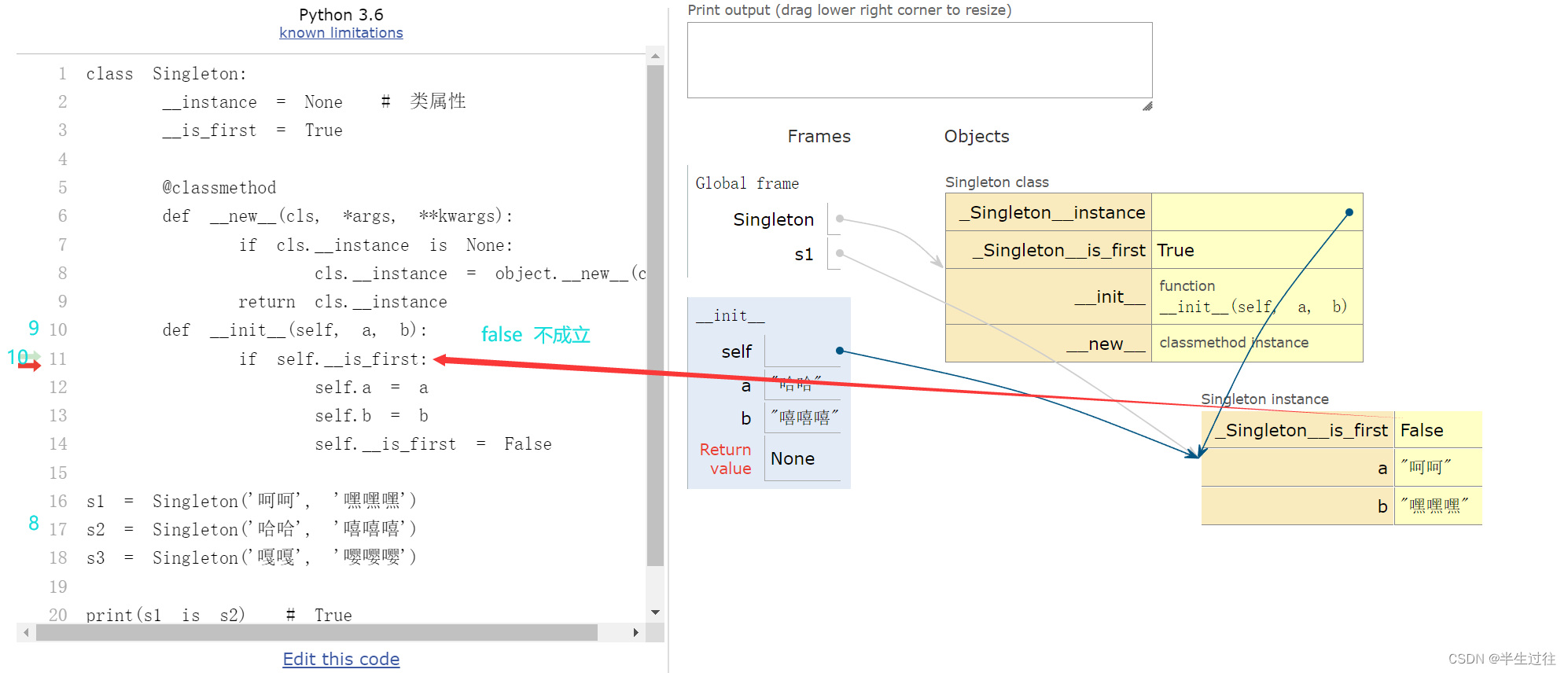

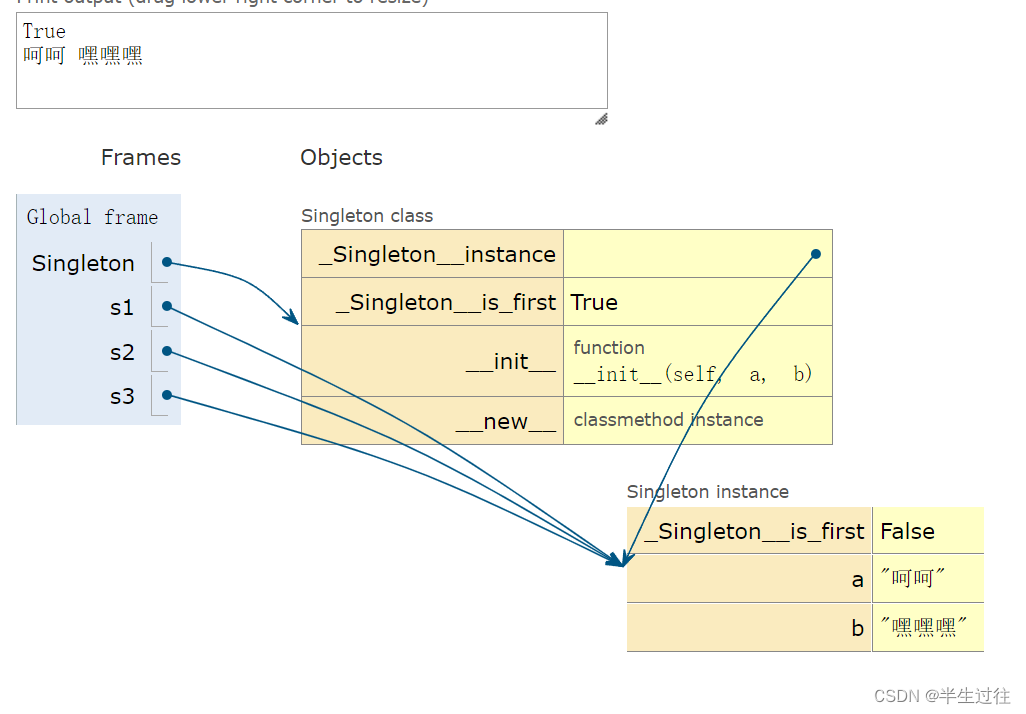
继承的基本使用
语法
class 类名(object):
pass
- 在程序中,继承描述的是多个类之间的所属关系。
- 如果一个类A里面的属性和方法可以复用,则可以通过继承的方式,传递到类B里。
- 那么类A就是基类,也叫做父类;类B就是派生类,也叫做子类。
单继承:子类只继承一个父类
子类继承自父类,可以享受父类中已经封装好的方法,不需要再次定义 子类中应该根据职责,封装子类特有的属性和方法。 子类拥有父类以及父类的父类中封装的所有属性和方法。
class Animal(object):def __init__(self, name, age):self.name = nameself.age = agedef sleep(self):print(self.name + '正在睡觉')class Dog(Animal):def bark(self):print(self.name + '正在叫')class Student(Animal):def study(self):print(self.name + '正在好好学习')# Dog() 调用 __new__ 方法,再调用 __init__ 方法
# Dog 里没有 __new__ 方法,会查看父类是否重写了 __new__ 方法
# 父类里也没有重写 __new__ 方法,查找父类的父类,找到了 object# 调用 __init__ 方法,Dog类没有实现,会自动找 Animal 父类
d1 = Dog('大黄', 3)# 父类里定义的属性,子类可以直接使用
print(d1.name) #大黄
d1.sleep() # 父类的方法子类实例对象可以直接调用 #大黄正在睡觉
d1.bark() #大黄正在叫s1 = Student('小明', 18)
s1.sleep() # 小明正在睡觉
s1.study() # 小明正在好好学习
多继承
Python中针对类提供了一个内置属性__mro__可以用来查看方法的搜索顺序。
MRO 是method resolution order的简称,主要用于在多继承时判断方法属性的调用顺序。
class A(object):def demo_a(self):print('我是A类里的方法demo_a')def foo(self):print('我是A类里的foo方法')class B(object):def demo_b(self):print('我是B类里的方法demo_b')def foo(self):print('我是B类里的foo方法')# Python里允许多继承
class C(A, B):passc = C()
c.demo_a() # 我是A类里的方法demo_a
c.demo_b() #我是B类里的方法demo_b# 如果两个不同的父类有同名方法,有一个类属性可以查看方法的调用顺序
c.foo() # 我是A类里的foo方法
print(C.__mro__) # (<class '__main__.C'>, <class '__main__.A'>, <class '__main__.B'>, <class 'object'>)
继承顺序
在调用方法时,按照__mro__的输出结果从左至右的顺序查找。 如果再当前类中找到方法,就直接执行,不再向下搜索。 如果没有找到,就顺序查找下一个类中是否有对应的方法,如果找到,就直接执行,不再继续向下搜索。 如果找到了最后一个类,依然没有找到方法,程序就会报错。
class A(object):passclass B(object):def foo(self):print('我是B类里的foo方法')class C(A):def foo(self):print('我是C类里的foo方法')class D(B):passclass E(object):passclass X(C, D, E):passx = X()
x.foo()
print(X.__mro__)
# (<class '__main__.X'>, <class '__main__.C'>, <class '__main__.A'>, <class '__main__.D'>, <class '__main__.B'>, <class '__main__.E'>, <class 'object'>)
自己类里定义的私有方法 对象名._类名__私有方法名()
class Animal(object):def __init__(self, name, age):self.name = nameself.age = ageself.__money = 1000def eat(self):print(self.name + '正在吃东西')def __test(self):print('我是Animal类里的test方法')class Person(Animal):def __demo(self):print('我是Person里的私有方法')p = Person('张三', 18)
print(p.name)
p.eat()
p._Person__demo() # 自己类里定义的私有方法 对象名._类名__私有方法名()
p._Animal__test() # 可以通过 对象名._父类名__私有方法调用()# 私有属性和方法,子类不会继承
# p._Person__test() # 父类的私有方法,子类没有继承
# print(p._Person__money)print(p._Animal__money)
新式类和经典类的概念:
- 新式类:继承自 object 的类我们称之为新式类
- 经典类:不继承自 object 的类
在python2里,如果不手动的指定一个类的父类是object,这个类就是一个经典类
python3里不存在 经典类,都是新式类
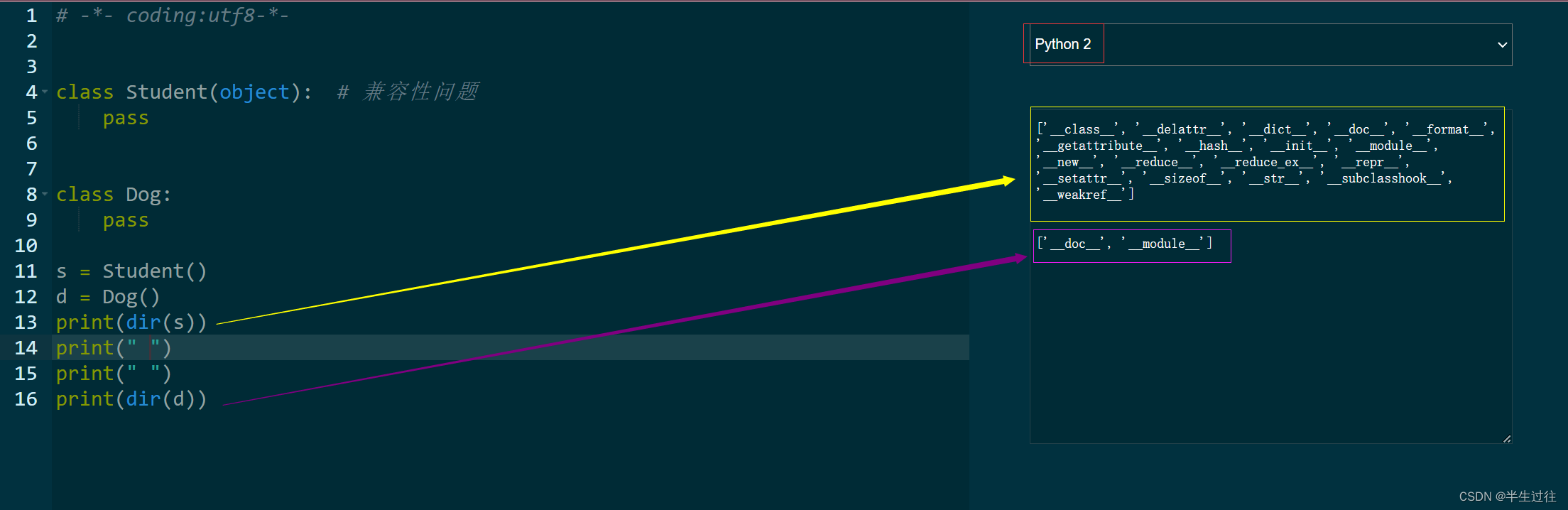

对象相关的内置函数
Python中的身份运算符用来判断两个对象是否相等;isinstance用来判断对象和类之间的关系;issublcass用啊里判断类与类之间的关系。
身份运算符
身份运算符用来比较两个对象的内存地址,看这两个对象是否是同一个对象。
class Person(object):def __init__(self, name, age):self.name = nameself.age = agep1 = Person('张三', 18)
p2 = Person('张三', 18)
p3 = p1print(p1 is p2) # False
print(p1 is p3) # True
isinstance
instance内置函数,用来判断一个实例对象是否是由某一个类(或者它的子类)实例化创建出来的。
c
lass Person(object):def __init__(self, name, age):self.name = nameself.age = ageclass Student(Person):def __init__(self, name, age, score):super(Student, self).__init__(name, age)self.score = scoreclass Dog(object):def __init__(self, name, color):self.name = nameself.color = colorp = Person('tony', 18)
s = Student('jack', 20, 90)
d = Dog('旺财', '白色')print(isinstance(p, Person)) # True.对象p是由Person类创建出来的
print(isinstance(s, Person)) # True.对象s是有Person类的子类创建出来的
print(isinstance(d, Person)) # False.对象d和Person类没有关系
issubclass
issubclass 用来判断两个类之间的继承关系。
class Person(object):def __init__(self, name, age):self.name = nameself.age = ageclass Student(Person):def __init__(self, name, age, score):super(Student, self).__init__(name, age)self.score = scoreclass Dog(object):def __init__(self, name, color):self.name = nameself.color = colorprint(issubclass(Student, Person)) # True
print(issubclass(Dog, Person)) # False


 BIN文件结构)

的数据交互)

超详细步骤)
)











