Tcp连接建立时的影响因素
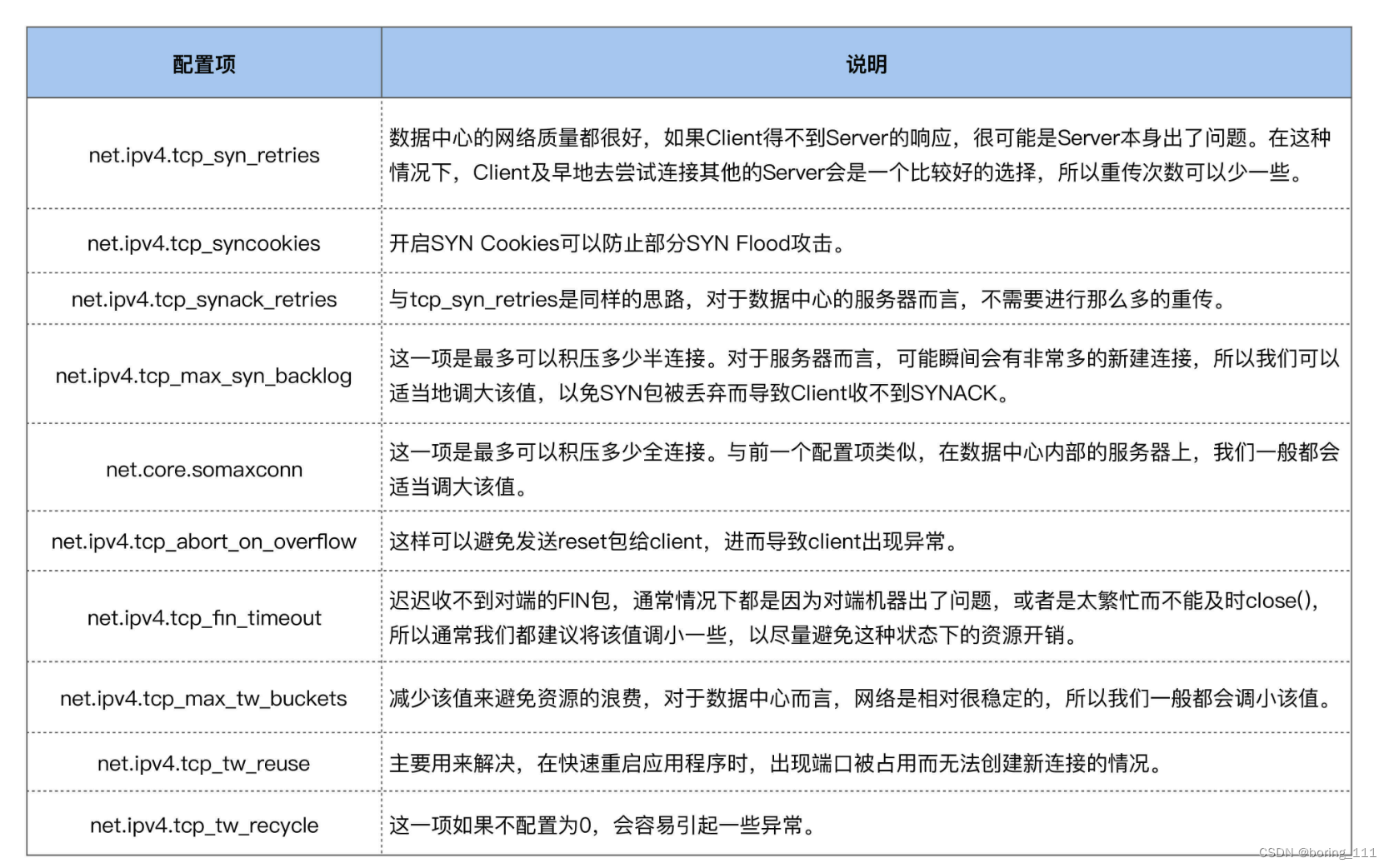
在Client发出SYN后,如果过了1秒 ,还没有收到Server的响应,那么就会进行第一次重传;如果经过2s的时间还没有收到Server的响应,就会进行第二次重传;一直重传tcp_syn_retries次。
对于tcp_syn_retries为3而言,总共会重传3次,也就是说从第一次发出SYN包后,会一直等待(1 + 2 + 4 + 8)秒,如果还没有收到Server的响应,connect()就会产生ETIMEOUT的错误。
Server中积压的半连接较多,也有可能是因为有些恶意的Client在进行SYN Flood攻击。典型的SYN Flood攻击如下:Client高频地向Server发SYN包,并且这个SYN包的源IP地址不停地变换,那么Server每次接收到一个新的SYN后,都会给它分配一个半连接,Server的SYNACK根据之前的SYN包找到的是错误的Client IP, 所以也就无法收到Client的ACK包,导致无法正确建立TCP连接,这就会让Server的半连接队列耗尽,无法响应正常的SYN包。
解决:通过Tcp sync cookie。Server收到SYN包时,不去分配资源来保存Client的信息,而是根据这个SYN包计算出一个Cookie值,然后将Cookie记录到SYNACK包中发送出去。对于正常的连接,该Cookies值会随着Client的ACK报文被带回来。然后Server再根据这个Cookie检查这个ACK包的合法性,如果合法,才去创建新的TCP连接
连接释放的过程
当应用程序调用close()时,会向对端发送FIN包,然后会接收ACK;对端也会调用close()来发送FIN,然后本端也会向对端回ACK,
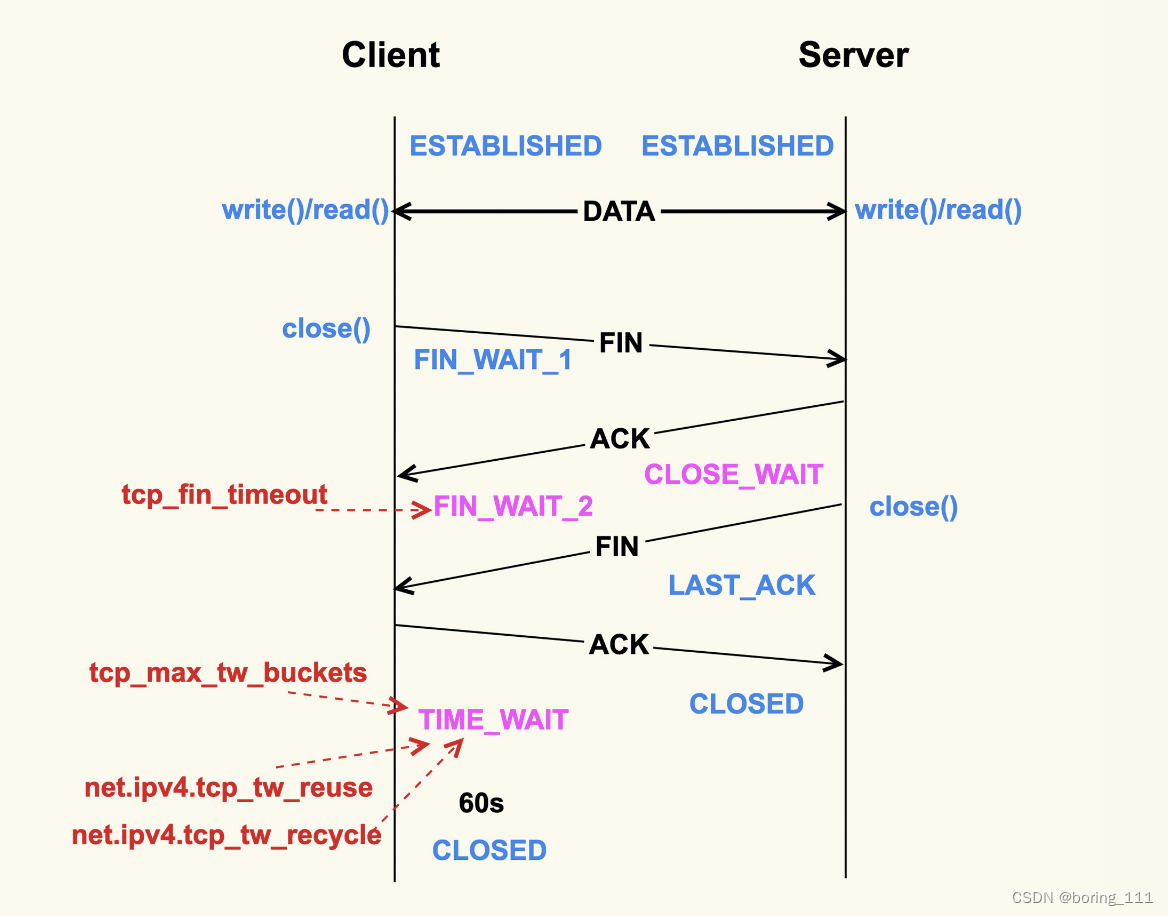
fin_wait_2状态,等待对端close发送fin 报文,关闭连接,如果连接得不到释放的话,就会等待对方fin报文。Linux为了防止这种资源的开销,设置了这个状态的超时时间tcp_fin_timeout,默认为60s,超过这个时间后就会自动销毁该连接。实际上可以调节为2s足够。
我们再来看TIME_WAIT状态,TIME_WAIT状态存在的意义是:最后发送的这个ACK包可能会被丢弃掉或者有延迟,这样对端就会再次发送FIN包。如果不维持TIME_WAIT这个状态,那么再次收到对端的FIN包后,本端就会回一个Reset包,这可能会产生一些异常。
数据传输时可以调节的参数


拥塞控制查看方法



重传率计算:retrans = (RetransSegs-last RetransSegs) / (OutSegs-last OutSegs) * 100
tcpdump抓包原理

warning
1.如果网络包已经被网卡丢弃了,那么tcpdump是抓不到它的
2.,比如因为发送缓冲区满而被丢弃,tcpdump同样抓不到它
轻量级追踪方式是TCP Tracepoints。
tcpdump的能力范围简单地总结为:网卡以内的问题可以交给tcpdump来处理;对于网卡以外(包括网卡上)的问题,tcpdump可能就捉襟见肘了。这个时候,你需要在对端也使用tcpdump来抓包。
后面有空可以玩一下这些工具。
- Kprobe是一个很通用的追踪工具,在低版本内核上,你可以使用这个方法来追踪TCP重传事件;
- Tracepoint是一个更加轻量级也更加方便的追踪TCP重传的工具,但是需要你的内核版本为4.16+;
- 如果你想要更简单些,那你可以直接使用tcpretrans这个工具。
Tcp如何高效利用本机cpu
首先先说说收包过程,网卡以DMA方式放入ringBuffer中,软中断把skb取走,然后把新的skb挂上去。其中指针数据是预先分配好的,而skb是动态分配的。
查看ringbuffer是256

满了,就网卡丢弃了。

网络包的处理分为硬中断和软中断。
硬中断:把poll_list添加到per-cpu的softnet_data的poll_list里面。
软中断:对softnet_data的poll_list进行变量。(内核线程ksoftirqd).
同时软中断线程和硬中断线程具有核亲密性,会在同一个核上处理。


可以通过中断号看对应亲和的核。

1000 第四个CPU, cpu3
所以我们可以加大ens33的网卡队列数,并且设置队列中断号上的smp_affinity,将硬中断打散到不同的cpu上。
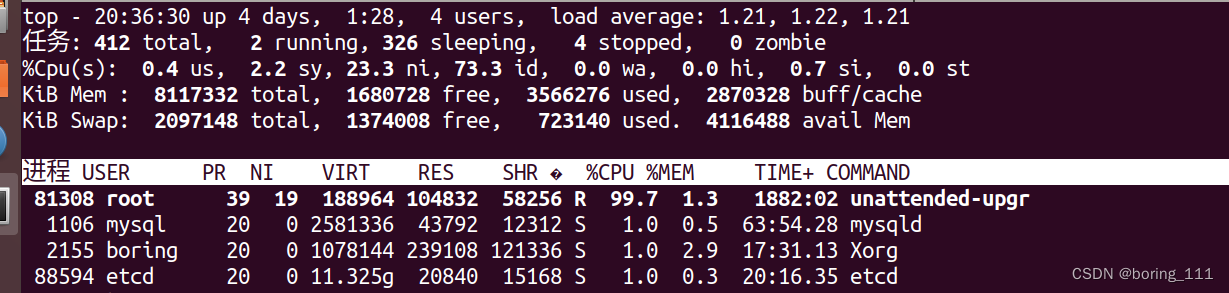
还可以通过top观察
还可以通过dpdk可以绕过内核协议栈,更高效的节约指令,从根源上节省和提高cpu。
关于dpdk下次有机会聊聊。





(VP-13,寒假加训))




)
——前言)







