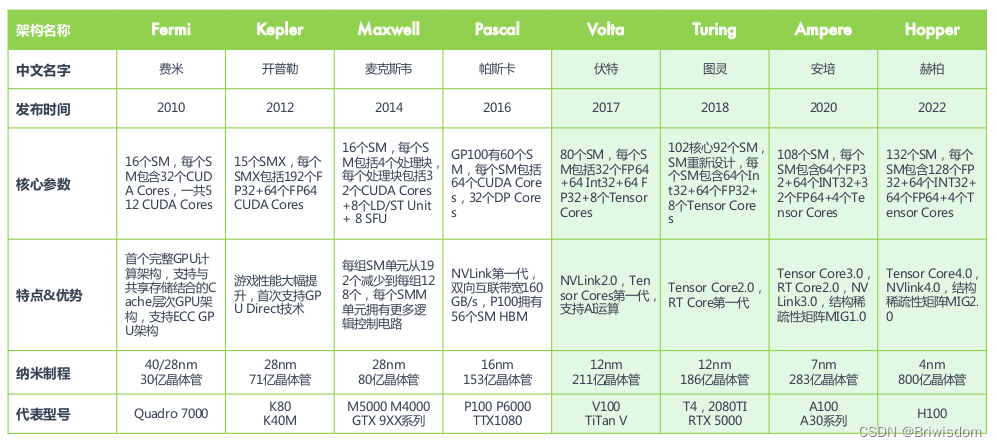
英伟达的GPU产品架构发展如下图,Tensor Core是从2017年的Volta架构开始演变的针对AI模型大量乘加运算的特殊处理单元。本文主要梳理一些关于Tensor Core的一些基础概念知识。
什么是混合精度?
混合精度在底层硬件算子层面,使用半精度(FP16)作为输入和输出,使用全精度(FP32)进行中间结果计算从而不损失过多精度的技术。这个底层硬件层面其实指的就是Tensor Core,所以GPU上有Tensor Core是使用混合精度训练加速的必要条件。
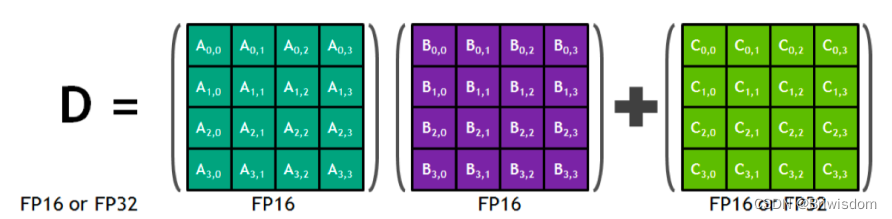
CUDA Core和Tensor Core的区别
对CUDA Core来说,GPU并行模式实现深度学习模型的功能过于通用,比如常见的conv/GEMM操作,被编码为FMA(fused multiply-add)实现,硬件层面会把数据按照:寄存器-ALU-寄存器-ALU-寄存器,方式来回搬运。并且一个时钟周期完成一个FMA。
Tensor Core则对深度学习模型常见的conv/GEMM 提供可编程矩阵乘法和累加单元(matrix-multiply-and-accumulate units),可为AI训练和推理提供较高的Tensor TFLOPS算力。一个时钟周期可以完成多个FMA操作。
什么是CUDA中的bank冲突?
共享内存和bank: 在CUDA架构中,共享内存是一个非常快速的内存类型,它位于每个线程块内部并为该线程块内的所有线程提供服务。为了实现高吞吐量的访问,共享内存被划分为多个独立的存储区域,称为“banks”。每个bank可以在单个时钟周期内独立地服务一个线程。
bank冲突: 当两个或更多的线程在同一时钟周期内尝试访问同一个bank中的不同地址时,就会发生bank冲突。由于每个bank在一个时钟周期内只能服务一个线程,因此这些访问会被序列化,导致延迟。
例如,假设有两个线程在同一时钟周期内访问第一个bank中的不同地址。第一个线程的访问会被立即处理,而第二个线程的访问则需要等待下一个时钟周期。这就导致了额外的延迟,从而降低了性能。
避免bank冲突: 为了避免bank冲突,程序员需要仔细设计数据的访问模式和数据的布局。理想的情况是,同一时钟周期内的所有线程访问的地址分布在不同的banks上,这样每个线程的访问都可以在一个时钟周期内被处理,从而实现最大的吞吐量。
参考:
Releases · chenzomi12/DeepLearningSystem · GitHub
CUDA 中的 bank 冲突 是什么? - 知乎


)


)



)









