css选择器整理:https://blog.csdn.net/qq_40910788/article/details/84842951
目标:爬取某文章网站列表:
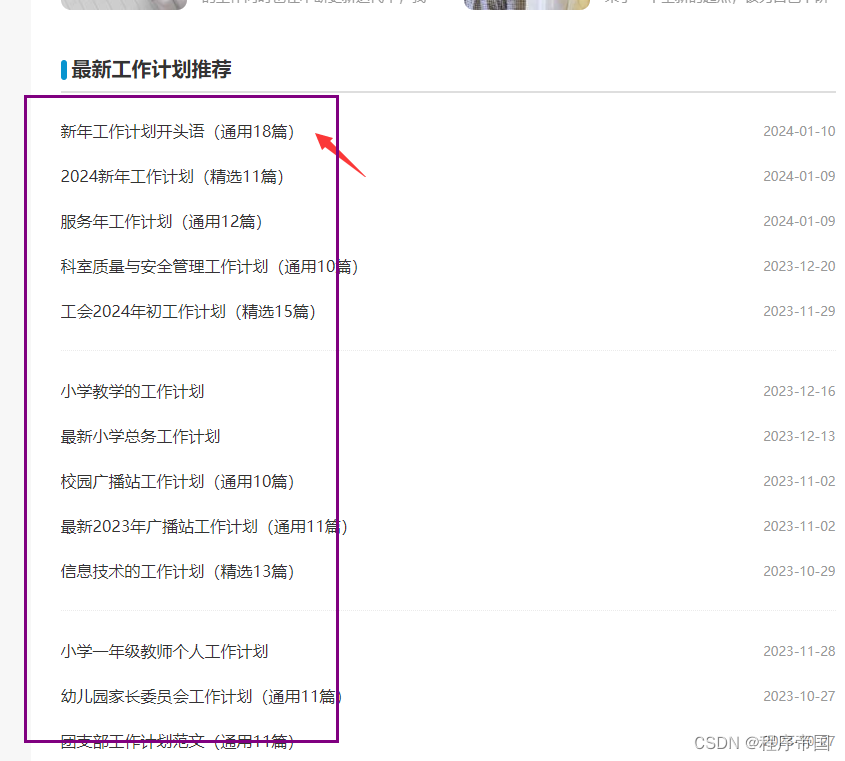
基础代码如下:
import random
import time
import urllib.request
import redef reptileTest(url):try:my_headers = ["Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36","Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.153 Safari/537.36","Mozilla/5.0 (Windows NT 6.1; WOW64; rv:30.0) Gecko/20100101 Firefox/30.0","Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.75.14 (KHTML, like Gecko) Version/7.0.3 Safari/537.75.14","Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2; Win64; x64; Trident/6.0)"]randdom_header = random.choice(my_headers)rep = urllib.request.Request(url)rep.add_header("User-Agent", randdom_header)rep.add_header("GET", url)res = urllib.request.urlopen(rep, timeout=5)html = res.read().decode("gb2312", 'ignore')from bs4 import BeautifulSoupweb = BeautifulSoup(html, features="html.parser")# 开始使用选择器选择目标标签except Exception as ex:print("异常%s" % ex)1.F12或右键查看网页源代码确定采集目标
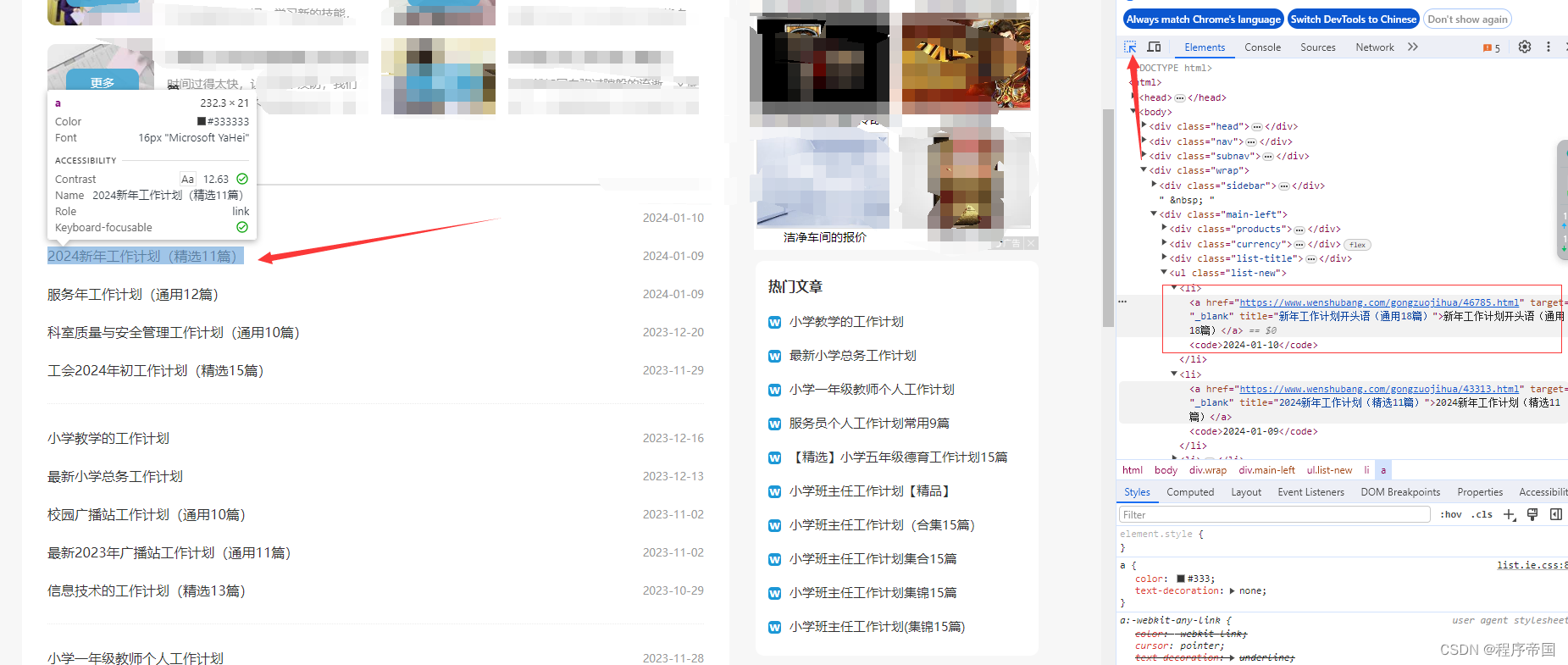
2.确定目标后分析前后整体标签

其中我们要采集的是a标签中的文字以及url,而包含我们要采集整体内容的标签是外层的ul标签,ul标签的class就是选择器要用到的内容,ctrl+f,检查此样式是否唯一

如果唯一,那么我们直接使用选择选择此样式得到的结果就是这个整体的ul
class的内容在选择器里需要加“.”标识为class,代码如下
# web.select为选择器代码
articlelist = web.select(".list-new ")
然后向下一级指定获取的标签 li 再下一级是 a,这里都是获取标签,标签无需加任何修饰
# > 代表获取当前标签下的内容,如果使用空格则标识获取当前标签下同级的内容
articlelist = web.select(".list-new > li > a")
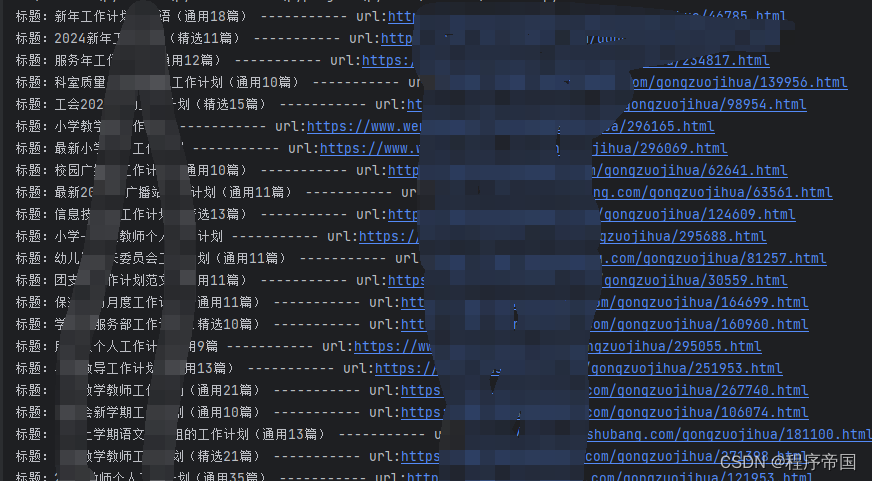
运行结果:
完整代码:
import random
import time
import urllib.request
import redef reptileTest(url):try:my_headers = ["Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36","Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.153 Safari/537.36","Mozilla/5.0 (Windows NT 6.1; WOW64; rv:30.0) Gecko/20100101 Firefox/30.0","Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.75.14 (KHTML, like Gecko) Version/7.0.3 Safari/537.75.14","Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2; Win64; x64; Trident/6.0)"]randdom_header = random.choice(my_headers)rep = urllib.request.Request(url)rep.add_header("User-Agent", randdom_header)rep.add_header("GET", url)res = urllib.request.urlopen(rep, timeout=5)html = res.read().decode("gb2312", 'ignore')from bs4 import BeautifulSoupweb = BeautifulSoup(html, features="html.parser")# 开始使用选择器选择目标标签articlelist = web.select(".list-new > li > a")#取值for a in articlelist:print("标题:"+a.text+" ----------- url:"+a.get("href"))except Exception as ex:print("异常%s" % ex)reptileTest("目标页面url")





: You must reset your password using ALTER USER 解决办法)
:将gem5扩展到ARM——Extending gem5 for ARM)

:从入门到精通的【图像增强】之旅)




![[paddle]paddlehub部署paddleocr的hubserving服务](http://pic.xiahunao.cn/[paddle]paddlehub部署paddleocr的hubserving服务)




