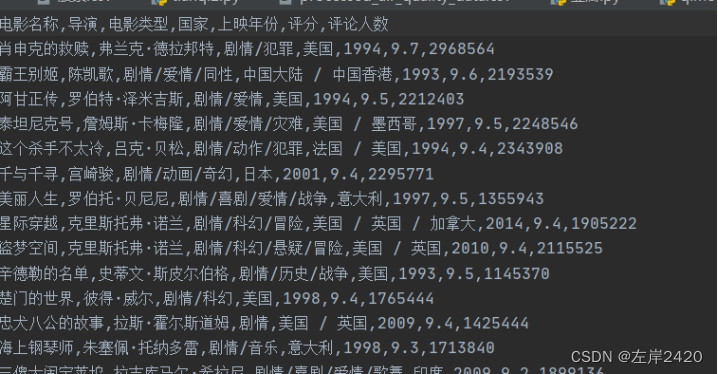
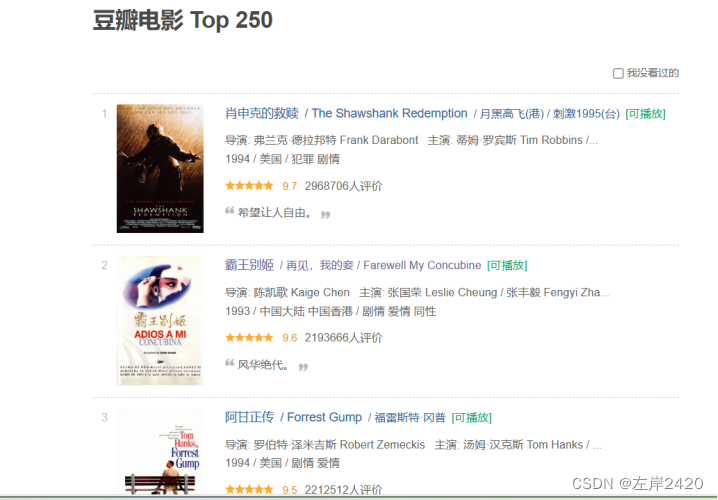
一:爬虫1、爬取的目标将豆瓣电影网上的电影的基本信息,比如:电影名称、导演、电影类型、国家、上映年份、评分、评论人数爬取出来,并将爬取的结果放入csv文件中,方便存储。 2、网站结构 图1豆瓣网网站结构详情 此次实验爬取豆瓣网中电影页面中的电影的基本信息。 每一个电影包括电影名称、导演、电影类型、国家、上映年份、评分、评论人数。页面具体情况如图2所示。
图2豆瓣网电影基本信息详情 3、爬虫技术方案1)、所用技术: 网站解析的使用的是Xpath、数据存储使用的是csv。 2)、爬取步骤: 1、导入所需的库,如re、time、requests、lxml、random和csv。 2、定义一个名为main的函数,该函数接受两个参数:page(页码)和f(文件对象)。 3、在main函数中,构造请求URL,设置请求头,并发送GET请求以获取网页内容。 4、使用lxml库解析网页内容,提取电影详情页的链接列表和电影名称列表。 5、遍历链接列表和名称列表,对于每个链接和名称,调用get_info函数来获取电影的详细信息。 6、在get_info函数中,同样构造请求URL,设置请求头,并发送GET请求以获取电影详情页的内容。 7、使用lxml库解析电影详情页的内容,提取导演、电影类型、国家、上映时间、评分和评论人数等信息。 8、打印提取到的信息,并将其写入CSV文件中。 9、在主程序中,创建一个CSV文件,并写入表头标题。 10、使用for循环遍历10个页面,调用main函数来爬取每一页的电影信息。 11、在每次循环之间,让程序休息一段时间,以避免过于频繁的请求导致IP被封禁。 4、爬取过程:
1)、导入所需要的包
import re:导入正则表达式模块,用于处理字符串。 from time import sleep:从time模块导入sleep函数,用于让程序暂停执行一段时间。 import requests:导入requests模块,用于发送HTTP请求。 from lxml import etree:从lxml模块导入etree函数,用于解析HTML文档。 import random:导入random模块,用于生成随机数。 import csv:导入csv模块,用于操作CSV文件。 2)、设置请求头,定义min函数接收参数,访问连接提取列表
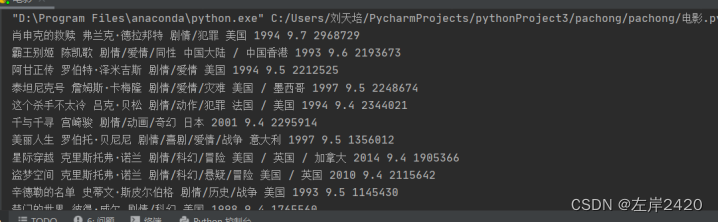
3)、使用正则表达式开始爬取网页信息4)、将爬取结果放入csv文件中5、爬虫结果
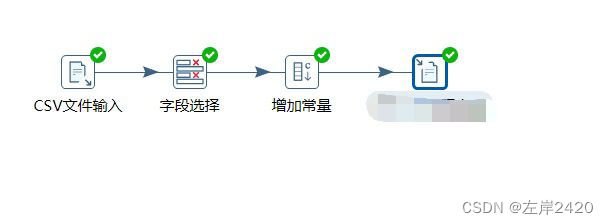
 二:预处理1、删除列
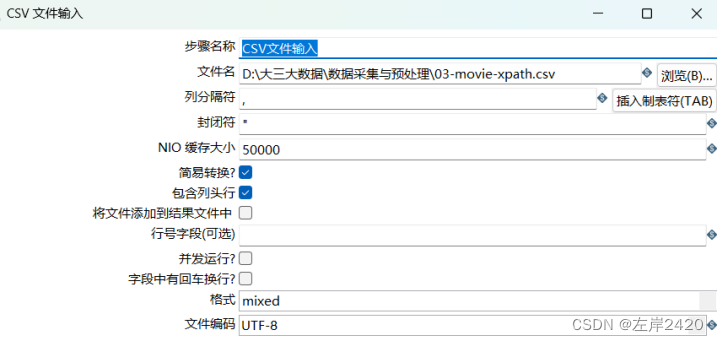
1)、新建转换,之后使用文件输入,将csv文件输入进行处理
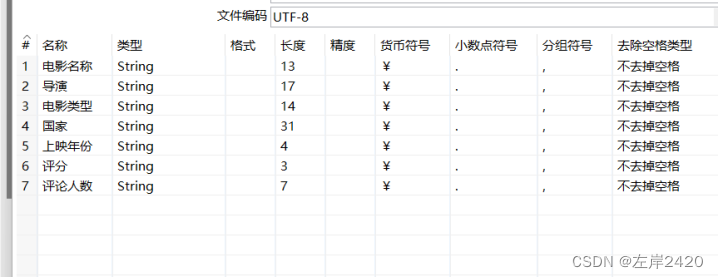
之后进行字段获取。
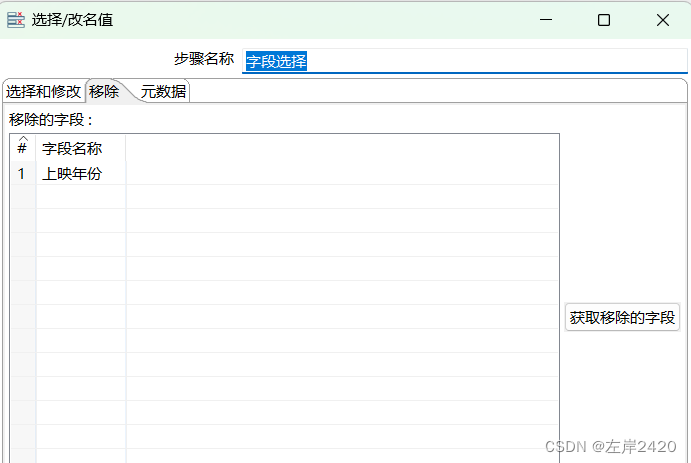
2)、选择转换中的字段选择进行列删除,将上映时间这个列进行删除。
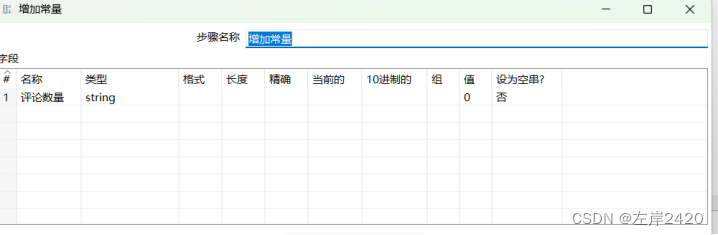
2、选择转换中的增加常量,增加评论数量这一列,查询电影评论的数量这一情况。
4、预处理完全处理全流程:
三:爬虫数据源代码代码: |
基于爬虫和Kettle的豆瓣电影的采集与预处理
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.mzph.cn/news/616427.shtml
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章
)
Polars使用指南(二)
在上一篇文章中,我们介绍了Polars的优势和Polars.Series的常用API,本篇文章我们继续介绍Polars.Series的扩展API。
对于一些特殊的数据类型,如 pl.Array、list、str 等,Polars.Series 提供了基于属性的直接操作API,如…

Web前端 ---- 【Vue3】Proxy响应式原理
目录 前言
安装Vue3项目
安装
Proxy
语法格式 前言 从本文开始进入vue3的学习。本文介绍vue3中的响应式原理,相较于vue2中通过object.defineProperty(vue2中的响应式)来实现响应式,vue3中换成了Proxy来进行实现。 安装Vue3项目…

Linux---gcc编译
目录 前言
一、gcc编译
二、程序的编译过程
三、gcc查看编译过程
1.预处理阶段
2.编译
3.汇编
4.链接
动静态库链接的内容
动静态库链接的优缺点
5.总结记忆 前言
在前面我们学会使用vim对文件进行编辑,如果是C或者C程序,我们编辑好了内容…

C++多态与虚函数的使用注意
文章目录 什么情况下用多态构造和析构的顺序为什么要把析构函数声明为虚函数为什么不能在构造函数和析构函数中使用虚函数什么情况下用多态
多态是面向对象编程中的一个重要概念,可以提高代码的可扩展性和可维护性。在以下情况下,可以考虑使用多态: 当有一个基类或接口,并…
)
监督学习 - 决策树(Decision Trees)
什么是机器学习
决策树(Decision Trees)是一种基于树形结构进行决策的模型,广泛应用于分类和回归任务。它通过对数据集进行递归划分,构建一棵树,每个节点代表一个特征,每个分支代表一个决策规则࿰…
)
数据结构二叉树创建及例题(上)
今天就带领大家来到树的世界,树无论是在考试上还是实际学习方面都是比较重点的,大家在这块知识要花时间搞懂. 文章目录 前言
一、树的二叉链表定义
二、二叉树三种遍历方式(递归方式)
1.先序遍历方式(根左右)
2.中序遍历方式(左根右) 3.后序遍历方式(左右根)
三、二叉树的…

单片机I/O口驱动MOS管
自记录:
使用单片机做一个PLC,输出可如下两种情况: 单片机I/O口驱动,为什么一般都选用三极管而不是MOS管?
1.单片机的IO口,有一定的带负载能力。但电流很小,驱动能力有限,一般在10-20mA以内。…

go-zero是什么?它有什么功能和特性?它值不值得我们去学习?我们该如何去学习呢?
go-zero是一个基于Go语言的Web和微服务开发框架,它提供了一系列的工具和库,帮助开发者构建高性能、可扩展的应用程序。go-zero采用了领域驱动设计(DDD)和依赖注入(DI)等先进的设计理念,使得开发…

Redis面试题10
Redis 支持哪些数据结构? Redis 支持以下几种常用的数据结构: 字符串(String):用于存储字符串值,可以是文本或二进制数据。 列表(List):用于存储一个有序的字符串列表&am…

用通俗易懂的方式讲解大模型分布式训练并行技术:序列并行
近年来,随着Transformer、MOE架构的提出,使得深度学习模型轻松突破上万亿规模参数,传统的单机单卡模式已经无法满足超大模型进行训练的要求。因此,我们需要基于单机多卡、甚至是多机多卡进行分布式大模型的训练。
而利用AI集群&a…

Maven_下载_安装_配置
文章参考:https://zhuanlan.zhihu.com/p/615382243
Maven简介 Maven 是 Apache 软件基金会的一个开源项目,是一个优秀的项目构建工具,它用来帮助开发者管理项目中的 jar,以及 jar 之间的依赖关系、完成项目的编译、测试、打包和发布等工作。 maven优点:…

31K+ stars 超炫酷的 Docker 可视化开源工具
31K stars 超炫酷的 Docker 可视化开源工具
原创 小奇 爱编程爱技术 2024-01-10 09:02 发表于北京 今天给大家分享一个适合开发人员使用的 Docker 可视化工具:LazyDocker。基于终端的一个可视化管理工具,支持健盘操作和鼠标点击。 相比 Portainer 功能没…
)
CCF模拟题 202309-2 坐标变换(其二)
问题描述 试题编号: 202309-2 试题名称: 坐标变换(其二) 时间限制: 1.0s 内存限制: 512.0MB
问题描述: 对于平面直角坐标系上的坐标 (x,y),小 P 定义了如下两…

为什么推荐大家使用动态住宅ip?怎么选择?
编辑代理ip的类型有很多,本文来介绍什么是动态住宅ip,为什么很多博主都推荐使用动态住宅ip,他到底有什么好处呢,接下来我们来学习一下。
一、什么是动态住宅ip
网络上的代理供应商很多,通常我们接触的比较多的几种类…
)
Python 实践——外星人入侵小游戏(上)
Python 实践——外星人入侵小游戏(上) 目录 Python 实践——外星人入侵小游戏(上)安装pip/pygame1.开始项目2.设置屏幕背景色基本操作: 3. 设置类4. 添加飞船图像5.导入程序基本操作:完整: 总结…

Springboot3+EasyExcel由浅入深
环境介绍 技术栈 springboot3easyexcel 软件 版本 IDEA IntelliJ IDEA 2022.2.1 JDK 17 Spring Boot 3 EasyExcel是一个基于Java的、快速、简洁、解决大文件内存溢出的Excel处理工具。
他能让你在不用考虑性能、内存的等因素的情况下,快速完成Excel的读、…

洛阳展馆讲解器,博物馆讲解器,无线讲解器出租,会展讲解器
无线一对多团队解说器的特点比较多,比如:1、声音传输的时分可以反抗噪音等,不会遭到搅扰。2、便利性,像这么细巧的语音导览可以随身携带,十分的便利。3、可以免去很多繁琐的进程,变得简单高效。4、明晰性&a…

mysql索引失效场景与mysql优化方式
索引失效场景
联合索引不满足最左匹配原则
索引列参与了运算,会导致全表扫描,索引失效
索引列参使用了函数
模糊查询时(like语句),模糊匹配的占位符位于条件的左侧
like %abc,like %abc% 都会导致失效…

【JVM的相关参数和调优】
文章目录 JVM 调优的参数类型一、标配参数二、X参数三、XX参数 JVM 调优的常用参数 JVM 调优的参数类型
一、标配参数
这类此参数在jdk的各个版本之间很少会变化,基本不改变
java -version,查看当前电脑上的jdk的版本信息 java -help,查看…
![安卓(雷电)模拟器清除屏幕密码[亲测可用]](http://pic.xiahunao.cn/安卓(雷电)模拟器清除屏幕密码[亲测可用])
安卓(雷电)模拟器清除屏幕密码[亲测可用]
1、设置磁盘可写
启动模拟器,然后在模拟器的设置界面,设置磁盘共享为可写入,重启模拟器,如下图: 2、找到模拟器目录
返回桌面,右键模拟器图标,打开文件所在目录,如下图:…