前言
DFS这部分难度不大,大家应该完全掌握!!!
一、DFS的基本内容
内容:
深度优先遍历图的方法是,从图中某顶点v出发:
(1)访问顶点v;
(2)依次从v的未被访问的邻接点出发,对图进行深度优先遍历;直至图中和v有路径相通的顶点都被访问;
(3)若此时图中尚有顶点未被访问,则从一个未被访问的顶点出发,重新进行深度优先遍历,直到图中所有顶点均被访问过为止
深度优先搜索是一种在开发爬虫早期使用较多的方法。它的目的是要达到被搜索结构的叶结点(即那些不包含任何超链的HTML文件) 。在一个HTML文件中,当一个超链被选择后,被链接的HTML文件将执行深度优先搜索,即在搜索其余的超链结果之前必须先完整地搜索单独的一条链。深度优先搜索沿着HTML文件上的超链走到不能再深入为止,然后返回到某一个HTML文件,再继续选择该HTML文件中的其他超链。当不再有其他超链可选择时,说明搜索已经结束。
模板:
void DFS(int step){if(满足边界条件){相应操作 }for(尝试每种可能){if(满足条件){标记继续下一步DFS(step + 1)恢复初始状态(回溯的时候需要) }}
}二、例题
1.全排列
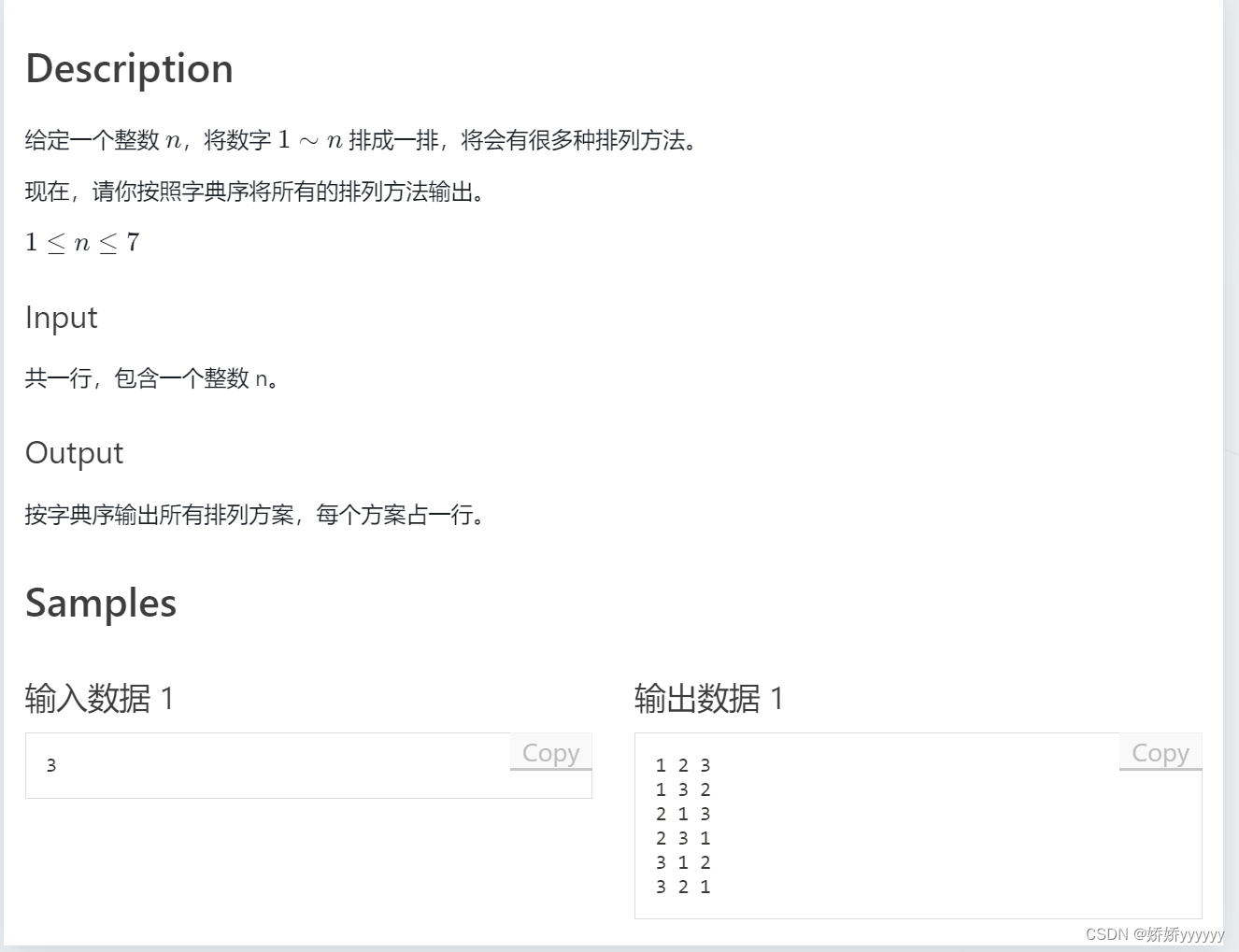
AC代码:
DFS:
#include <iostream>
using namespace std;
const int N = 10;
int n;
int path[N];
bool st[N];//true表示这个点已经用过了,false表示这个点没用过void dfs(int u) {if (u == n) {//当走到最后一个位置的时候,说明此时已经把所有位置填满了,就输出for (int i = 0; i < n; i++)printf("%d ", path[i]);puts("");return ;}for (int i = 1; i <= n; i++)//没走到最后一个位置,就枚举一下当前这个位置可以填哪些数if (!st[i]) {//如果当前这个数没有被用过path[u] = i;//把i放到当前这个位置上去st[i] = true;//记录i已经被用过了dfs(u + 1);//递归到下一层// path[u] = 0;恢复现场st[i] = false;//恢复现场}
}int main() {cin >> n;dfs(0);return 0;
}调库:
#include<iostream>
using namespace std;
#include<algorithm>
#include<vector>vector<int>v;
int n;
int main()
{cin>>n;for(int i=1;i<=n;i++){v.push_back(i);}do{for(int i=0;i<n;i++){cout<<v[i]<<" ";}cout<<endl;}while(next_permutation(v.begin(),v.end()));return 0;
}2.n皇后问题:
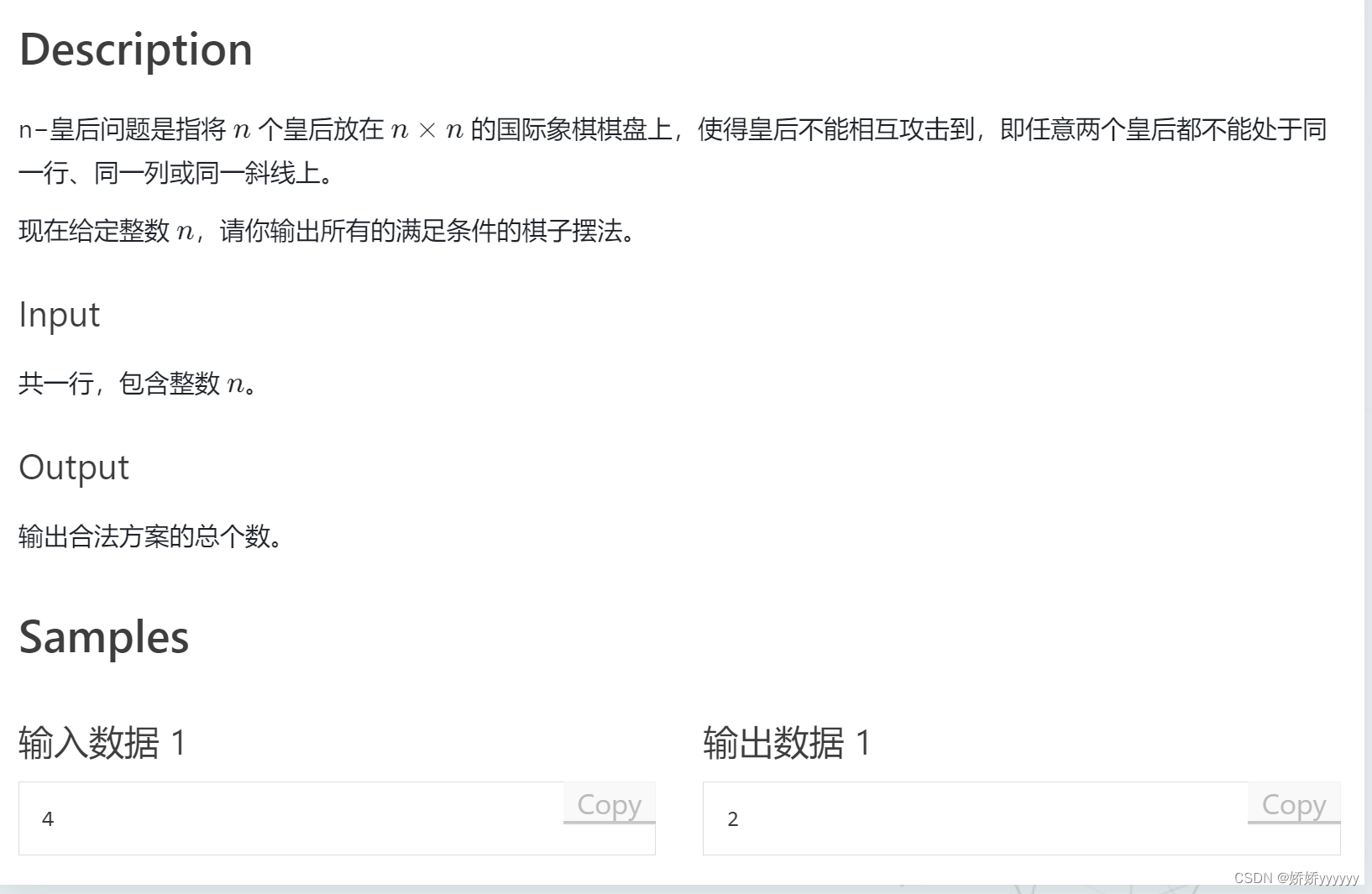
AC代码:
#include<bits/stdc++.h>using namespace std;int a[11],n,cnt;bool check(int x, int y)
{for(int i=1;i<=x;i++){if(a[i]==y) return false;if(a[i]+i==x+y) return false;if(i-a[i]==x-y) return false;}//两条对角线 以及列数return true;
}
void dfs(int row)
{if(row==n+1){cnt++;return ;}for(int i=1;i<=n;i++){if(check(row,i)){a[row]=i;//row为行 i为列dfs(row+1);a[row]=0;}}
}
int main()
{cin>>n;dfs(1);cout<<cnt<<endl;return 0;
}
、Cache(缓存))

 模型I/O:输入提示、调用模型、解析输出)
算法)


)





)





