一、前期准备
三个包:Numpy、Pandas和matplotlib;工具:jupyter notebook。首先确保导入这两个包
#导入Numpy包
import numpy as np
#导入Pandas包
import pandas as pd
二、基础知识
Pandas有三种数据结构:Series、DataFrame和Panel。Series类似于一维数组;DataFrame是类似表格的二维数组;Panel可以视为Excel的多表单Sheet。
1.read_table
read_table(filepath_or_buffer, sep=False, delimiter=None, header=’infer’, names=None, index_col=None, usecols=None, squeeze=False, prefix=None, mangle_dupe_cols=True, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skipinitialspace=False, skiprows=None, skipfooter=0, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, skip_blank_lines=True, parse_dates=False, infer_datetime_format=False, keep_date_col=False, date_parser=None, dayfirst=False, iterator=False, chunksize=None, compression=’infer’, thousands=None, decimal=b’.’, lineterminator=None, quotechar='”‘, quoting=0, doublequote=True, escapechar=None, comment=None, encoding=None, dialect=None, tupleize_cols=None, error_bad_lines=True, warn_bad_lines=True, delim_whitespace=False, low_memory=True, memory_map=False, float_precision=None)
可以用于读取csv、excel、dat文件。
2.merge
merge(left, right, how=‘inner’, on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=(’_x’, ‘_y’), copy=True, indicator=False, validate=None)
连接两个DataFrame并返回连接之后的DataFrame。
3.iloc
iloc函数:通过行号来取行数据(如取第二行的数据)
4.pivot_table
通过使用pandas.pivot_table()函数,可以实现与电子表格软件(例如Excel)的数据透视表功能相同的处理
5.groupby
和sql中的分组类似,pandas中的groupby函数也是先将df按照某个字段进行拆分,将相同属性分为一组;然后对拆分后的各组执行相应的转换操作;最后输出汇总转换后的各组结果。
三、具体案例
数据分析步骤:1.提出问题 2.理解数据 3.数据清洗 4.构建模型 5.数据可视化
3.1 MoviesLens 1M数据集
GroupLens实验室提供了一些从MoviesLens用户那里收集的20世纪90年代末到21世纪初的电影评分数据的集合。浙西额数据提供了电影的评分、流派、年份和观众数据(年龄、邮编、性别、职业)。 MovisLens1M数据集包含6000个用户对4000部电影的100万个评分。数据分布在三个表格之中:分别包含评分、用户信息和电影信息。
下载地址为:http://files.grouplens.org/datasets/movielens/,有好几种版本,对应不同数据量。
#读取users.dat文件
unames = ["user_id", "gender", "age", "occupation", "zip"]
users = pd.read_table("datasets/movielens/users.dat", sep="::",header=None, names=unames, engine="python")
#读取ratings.dat文件
rnames = ["user_id", "movie_id", "rating", "timestamp"]
ratings = pd.read_table("datasets/movielens/ratings.dat", sep="::",header=None, names=rnames, engine="python")
#读取movies.dat文件
mnames = ["movie_id", "title", "genres"]
movies = pd.read_table("datasets/movielens/movies.dat", sep="::",header=None, names=mnames, engine="python")
首先读取users.dat、rating.dat、movies.dat三个文件,并将他们存储在不同的DataFrame中,分别命名为users、ratings、movies。
users.head(5)
ratings.head(5)
movies.head(5)
ratings
分别输出三个DataFrame的前五行,并输出ratings的全部数据。

data = pd.merge(pd.merge(ratings, users), movies)
data
data.iloc[0]
使用merge函数将ratings,users和movies进行合并,保留了三个DataFrame中所有的数据,并将他们之间重复的数据和行进行合并。合并生成名为data的新DataFrame,并输出整个数据以及读取第一行数据。

mean_ratings = data.pivot_table("rating", index="title",columns="gender", aggfunc="mean")
mean_ratings.head(5)
使用pivot_table函数实现数据透视表功能,对rating中title列求均值,columns参数就是用来显示字符型数据的,显示性别数据。求均值生成名为mean_ratings的新DataFrame,并读取输出前五行数据。

ratings_by_title = data.groupby("title").size()
ratings_by_title.head()
active_titles = ratings_by_title.index[ratings_by_title >= 250]
active_titles
使用groupby函数对data这一DataFrame按照电影名称title分组,并计算每个电影标题对应的评分数量。第二行代码显示每个电影标题对应的评分数量。第三四行代码统计对应评分数量大于250的电影标题将其定义为active_titles并输出。

mean_ratings = mean_ratings.loc[active_titles]
mean_ratings
读取mean_ratings中评分数量大于250的电影标题对应的数据并输出。

mean_ratings = mean_ratings.rename(index={"Seven Samurai (The Magnificent Seven) (Shichinin no samurai) (1954)":"Seven Samurai (Shichinin no samurai) (1954)"})
使用rename函数将mean_ratings中Seven Samurai (The Magnificent Seven) (Shichinin no samurai) (1954)重新更改为Seven Samurai (Shichinin no samurai) (1954)。
top_female_ratings = mean_ratings.sort_values("F", ascending=False)
top_female_ratings.head()
根据女性的评分使用排序函数对mean_ratings进行降序排序并输出。

mean_ratings["diff"] = mean_ratings["M"] - mean_ratings["F"]
用mean_ratings中男性评分减去女性评分计算出男女评分差异diff。
sorted_by_diff = mean_ratings.sort_values("diff")
sorted_by_diff.head()
根据diff列的值使用排序函数对mean_ratings进行升序排序并输出。

sorted_by_diff[::-1].head()
使用切片操作对diff进行逆序排序,并输出。
rating_std_by_title = data.groupby("title")["rating"].std()
rating_std_by_title = rating_std_by_title.loc[active_titles]
rating_std_by_title.head()
std函数用于表示标准差。对电影标题title根据评分标准差分组。并读取活跃标题(评分数量大于250的电影标题)的标准差输出。

rating_std_by_title.sort_values(ascending=False)[:10]
根据评分标准差进行降序排序并读取前十行,也即输出评分标准差最大的十个电影标题。

movies["genres"].head()
movies["genres"].head().str.split("|")
movies["genre"] = movies.pop("genres").str.split("|")
movies.head()
读取电影中genres列数据,并通过|分隔开。将分割后的数据命名为genre列,原数据列genres删除。
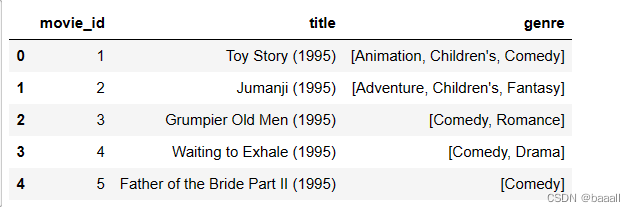
movies_exploded = movies.explode("genre")
movies_exploded[:10]
使用explode函数将genre列中分割的数据展开成单独的几列数据并记为movies_exploded这个新DataFrame,输出前十行数据。

ratings_with_genre = pd.merge(pd.merge(movies_exploded, ratings), users)
ratings_with_genre.iloc[0]
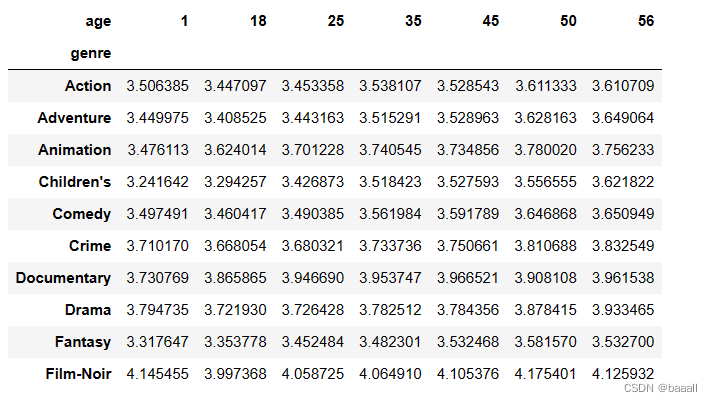
genre_ratings = (ratings_with_genre.groupby(["genre", "age"])["rating"].mean().unstack("age"))
genre_ratings[:10]
将movies_exploded,ratings,users这三个合并起来生成一个新DataFrame,并读取第一行数据。按照genre和age进行分组,并计算每个组评分的平均值,使用unstack函数将结果重塑为以age为列索引的形式。
3.2 美国1880-2010年的婴儿名字
美国社会保障局(SSA)提供了从1880年至现在的婴儿姓名频率的数据。可以使用这些数据做很多事情:根据给定的名字对婴儿名字随时间的比例进行可视化,确定一个名字的相对排位,确定每年最受欢迎的名字,或者流行程度最高或最低的名字
数据集下载地址:http://github.com/wesm/pydata-book
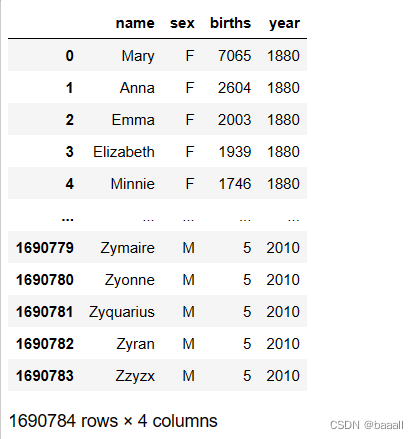
names1880 = pd.read_csv("datasets/babynames/yob1880.txt",names=["name", "sex", "births"])
names1880
读取名为“yob1880.txt”文件,并将其列名设为name,sex,births。

names1880.groupby("sex")["births"].sum()
按照性别分组,并计算每组生日的总和。

pieces = []
for year in range(1880, 2011):path = f"datasets/babynames/yob{year}.txt"frame = pd.read_csv(path, names=["name", "sex", "births"])# Add a column for the yearframe["year"] = yearpieces.append(frame)# Concatenate everything into a single DataFrame
names = pd.concat(pieces, ignore_index=True)
names
提取从数据集中读取1880-2011年间的数据并生成names这个DataFrame。
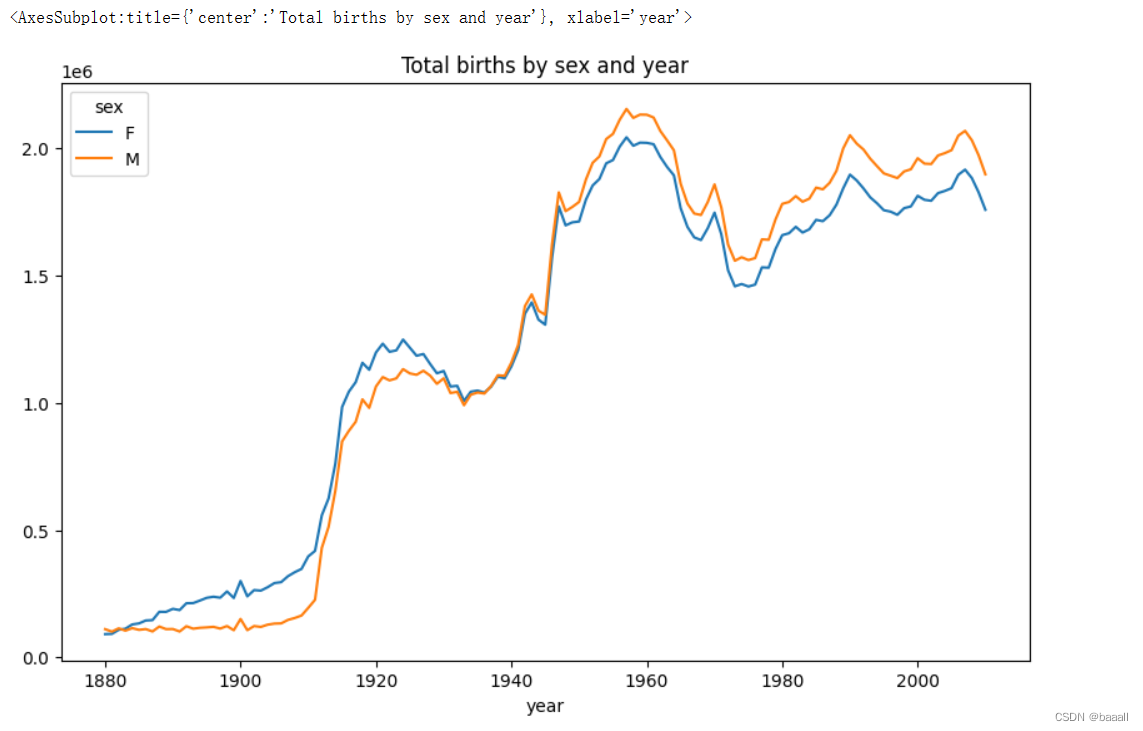
total_births = names.pivot_table("births", index="year",columns="sex", aggfunc=sum)
total_births.tail()
total_births.plot(title="Total births by sex and year")
使用pivot_table函数以births和sex分组的出生数总和,并显示最后几行。
绘制一个标题为Total births by sex and year的折线图。
def add_prop(group):group["prop"] = group["births"] / group["births"].sum()return group
names = names.groupby(["year", "sex"], group_keys=False).apply(add_prop)
names
定义一个增加组的函数add_prop,表示每个名字在出生年份和性别组中的比例,每个名字的出生率。
对names按照年份和性别分组,并对每组应用add_prop函数。
names.groupby(["year", "sex"])["prop"].sum()
通过年份和性别分组,并计算对每组中的每个名字比例的总和。

def get_top1000(group):return group.sort_values("births", ascending=False)[:1000]
grouped = names.groupby(["year", "sex"])
top1000 = grouped.apply(get_top1000)
top1000.head()
定义一个get_top1000的函数,该函数根据births进行降序排序,并取前1000行,也即births值最大的前1000。根据年份和性别分组,并对每个分组应用get_top1000函数。

top1000 = top1000.reset_index(drop=True)
top1000.head()
使用reset_index()函数对top1000 DataFrame 进行重置索引,并丢弃原始索引。设置drop=True可以移除原始索引列,以便在重置索引后不保留它。

boys = top1000[top1000["sex"] == "M"]
girls = top1000[top1000["sex"] == "F"]
total_births = top1000.pivot_table("births", index="year",columns="name",aggfunc=sum)
total_births.info()
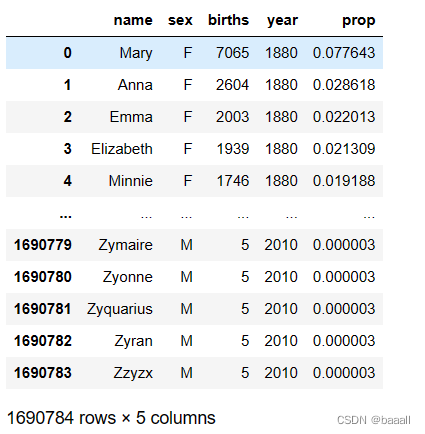
subset = total_births[["John", "Harry", "Mary", "Marilyn"]]
subset.plot(subplots=True, figsize=(12, 10),title="Number of births per year")
根据性别将top1000的值分为boys和girls两个数据集。并对births进行数据透视。
使用info()方法打印出total_births的全部数据,并选择John、Harry、Mary、Marilyn四个名字绘制标题为Number of births per year的折线图。
plt.figure()
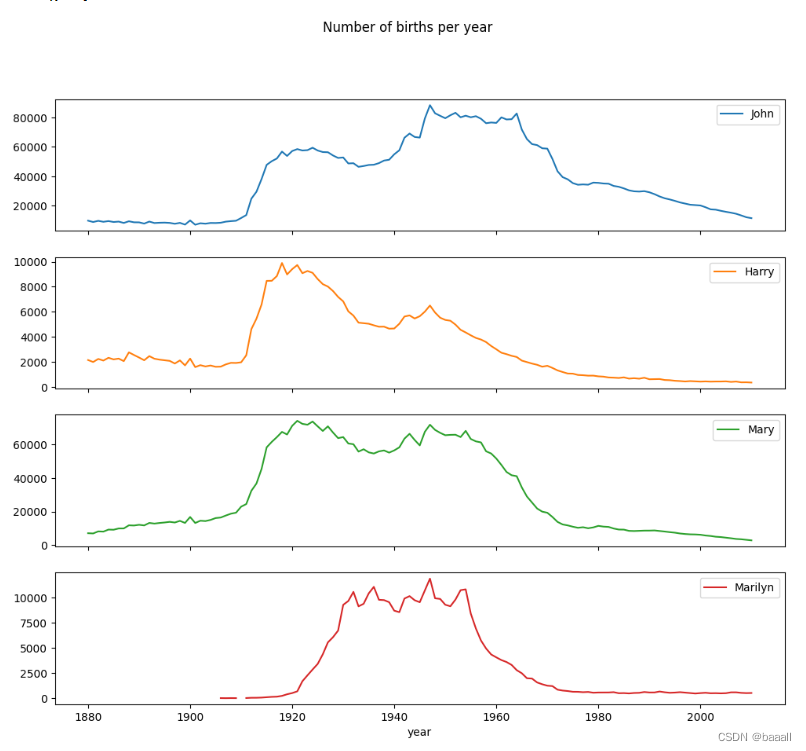
table = top1000.pivot_table("prop", index="year",columns="sex", aggfunc=sum)
table.plot(title="Sum of table1000.prop by year and sex",yticks=np.linspace(0, 1.2, 13))
对prop进行数据透视图,绘制标题为Sum of table1000.prop by year and sex的折线图。

df = boys[boys["year"] == 2010]
df
得到2010年男孩出生人数表

prop_cumsum = df["prop"].sort_values(ascending=False).cumsum()
prop_cumsum[:10]
prop_cumsum.searchsorted(0.5)
对2010年男孩出生人数表中prop值进行降序排序并计算累计和,并提取前10行,使用 searchsorted() 方法找到累计和达到 0.5 时的索引位置。

df = boys[boys.year == 1900]
in1900 = df.sort_values("prop", ascending=False).prop.cumsum()
in1900.searchsorted(0.5) + 1
得到1900年男孩出生人数表, 对表中prop值进行降序排序并计算累计和, searchsorted() 方法找到累计和达到 0.5 时的后一个索引位置。

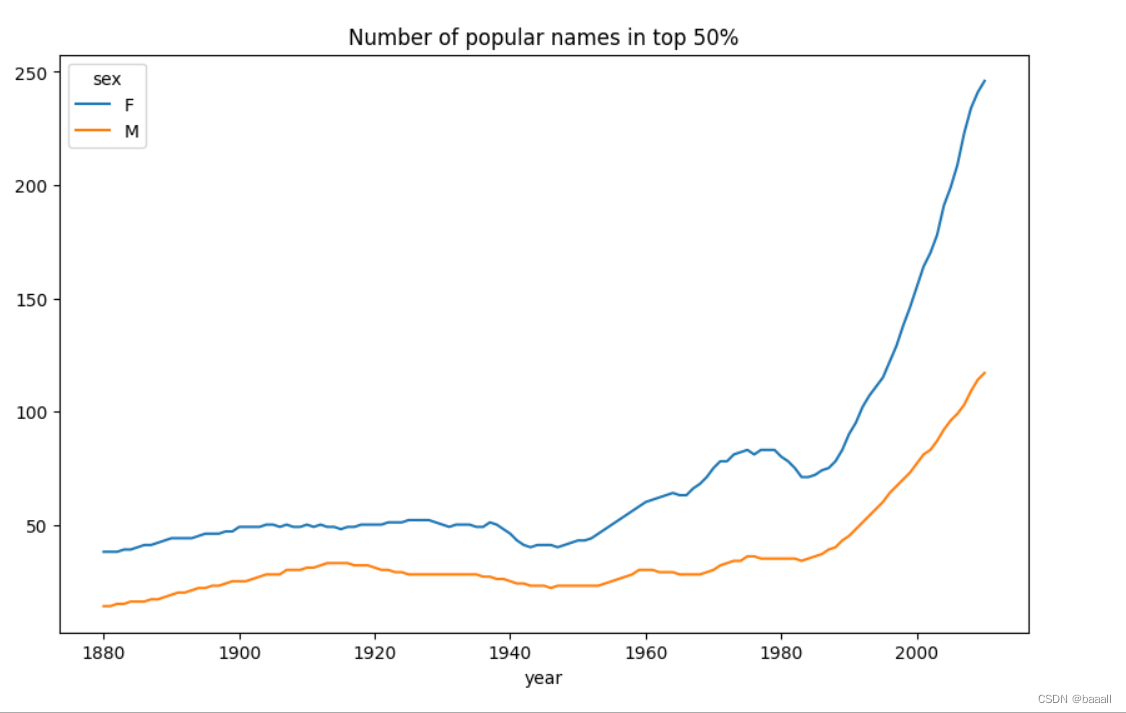
def get_quantile_count(group, q=0.5):group = group.sort_values("prop", ascending=False)return group.prop.cumsum().searchsorted(q) + 1diversity = top1000.groupby(["year", "sex"]).apply(get_quantile_count)
diversity = diversity.unstack()
fig = plt.figure()
diversity.head()
diversity.plot(title="Number of popular names in top 50%")
定义一个get_quantile_count函数,对prop值进行降序排序并计算累计和, searchsorted() 方法找到累计和达到 0.5 时的后一个索引位置。
根据年份和性别分组,并对每组应用get_quantile_count函数,得到diversity这个新DataFrame,并绘制标题为Number of popular names in top 50%的折线图。
def get_last_letter(x):return x[-1]last_letters = names["name"].map(get_last_letter)
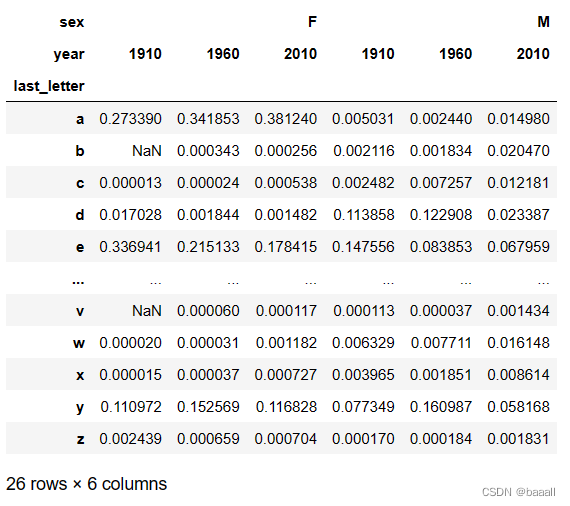
last_letters.name = "last_letter"table = names.pivot_table("births", index=last_letters,columns=["sex", "year"], aggfunc=sum)
subtable = table.reindex(columns=[1910, 1960, 2010], level="year")
subtable.head()
定义一个返回字符串最后一个字母的函数。
使用map函数对names中每一个名字提取最后一个字母。进行数据透视。
展示1910,1960,2010年的数据。

subtable.sum()
letter_prop = subtable / subtable.sum()
letter_prop
展示每个年份和性别组合中每个名字的总和,以及占比
import matplotlib.pyplot as pltfig, axes = plt.subplots(2, 1, figsize=(10, 8))
letter_prop["M"].plot(kind="bar", rot=0, ax=axes[0], title="Male")
letter_prop["F"].plot(kind="bar", rot=0, ax=axes[1], title="Female",legend=False)
导入matplotlib包分别以男生和女生绘制两幅柱状图。

letter_prop = table / table.sum()dny_ts = letter_prop.loc[["d", "n", "y"], "M"].T
dny_ts.head()
统计最后男生中名字最后一个字母为d、n、y的比例。
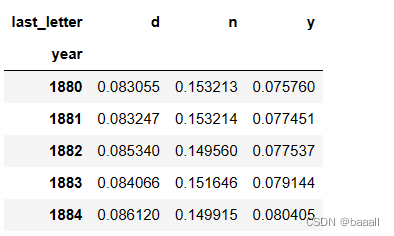
并绘制折线图。

all_names = pd.Series(top1000["name"].unique())
lesley_like = all_names[all_names.str.contains("Lesl")]
lesley_like
从top1000 DataFrame的"name"列获取唯一的姓名,并将结果存储在all_names变量中。选择all_names中包含"Lesl"的姓名,并将结果赋值给lesley_like变量。显示lesley_like Series,即包含以"Lesl"开头的姓名。

filtered = top1000[top1000["name"].isin(lesley_like)]
filtered.groupby("name")["births"].sum()
根据top1000 DataFrame中的"name"列与lesley_like中的姓名进行匹配,筛选出匹配的行数据,并将结果赋值给filtered变量。 对filtered DataFrame按姓名进行分组,计算每个姓名的出生人数总和,并显示结果。

table = filtered.pivot_table("births", index="year",columns="sex", aggfunc="sum")
table = table.div(table.sum(axis="columns"), axis="index")
table.tail()
根据年份和性别对filtered进行透视,计算每个年份和性别的出生人数总和,并将结果存储在table变量中。对table进行归一化,即每行的总和作为除数,计算每个年份和性别的归一化比例。table归一化后最后几行的结果。

fig = plt.figure()
table.plot(style={"M": "k-", "F": "k--"})
绘制折线图,其中男生用实线,女生用虚线。

3.3 美国农业部食品数据库
美国农业部提供了食物营养信息数据库。每种事务都有一些识别属性以及两份营养元素和营养比例的列表。这种形式的数据不适合分析,所以需要做一些工作将数据转换成更好的形式。
下载地址:http://www.nal.usda.gov/fnic/foodcomp/search/
import json
db = json.load(open("datasets/usda_food/database.json"))
len(db)
计算列表中元素的个数
db[0].keys()
db[0]["nutrients"][0]
nutrients = pd.DataFrame(db[0]["nutrients"])
nutrients.head(7)
获得db列表中索引为0的所有关键值。 从db列表中索引为0的元素中获取键为"nutrients"的值的列表,并返回列表中的第一个元素。将db列表中索引为0的元素中的"nutrients"值转换为Pandas DataFrame对象。 显示nutrients DataFrame的前7行数据。

info_keys = ["description", "group", "id", "manufacturer"]
info = pd.DataFrame(db, columns=info_keys)
info.head()
info.info()
包含要从数据库中提取的信息的键的列表。使用info_keys作为列名,创建包含db数据的Pandas DataFrame对象,并将其存储在info变量中。 显示info DataFrame的前几行数据。显示info DataFrame的基本信息。

pd.value_counts(info["group"])[:10]
从DataFrame info 中选择了名为 “group” 的列,该列包含了食物的分组信息。对选定列中的每个唯一值进行计数,并返回计数结果。取计数结果中的前 10 个值,即返回出现次数最多的前 10 个分组。

nutrients = []for rec in db:fnuts = pd.DataFrame(rec["nutrients"])fnuts["id"] = rec["id"]nutrients.append(fnuts)nutrients = pd.concat(nutrients, ignore_index=True)
nutrients
创建一个空列表。定义一个函数为每个记录创建一个包含营养信息的DataFrame对象,添加一个名为"id"的列,将记录的id值赋给该列的每个元素,并将每个记录的营养信息DataFrame添加到nutrients列表中, 将nutrients列表中的DataFrame对象合并为一个大的DataFrame,并重新索引行号。

nutrients.duplicated().sum() # number of duplicates
nutrients = nutrients.drop_duplicates()
计算duplicates的总值,并将其赋值给nutrients。
col_mapping = {"description" : "food","group" : "fgroup"}
info = info.rename(columns=col_mapping, copy=False)
info.info()
col_mapping = {"description" : "nutrient","group" : "nutgroup"}
nutrients = nutrients.rename(columns=col_mapping, copy=False)
nutrients
定义一个字典,里面有两个键值对。将其重命名为info,并输出。定义另一个字典,将其重命名为nutrients并输出。

ndata = pd.merge(nutrients, info, on="id")
ndata.info()
ndata.iloc[30000]
合并nutrients和info,并读取第30000行数据
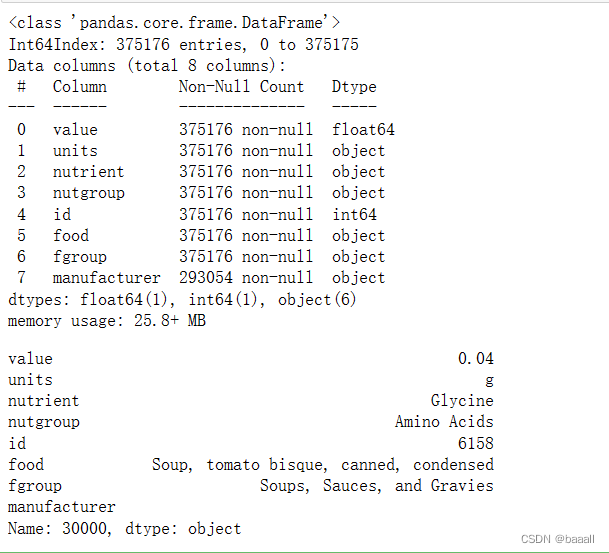
fig = plt.figure()
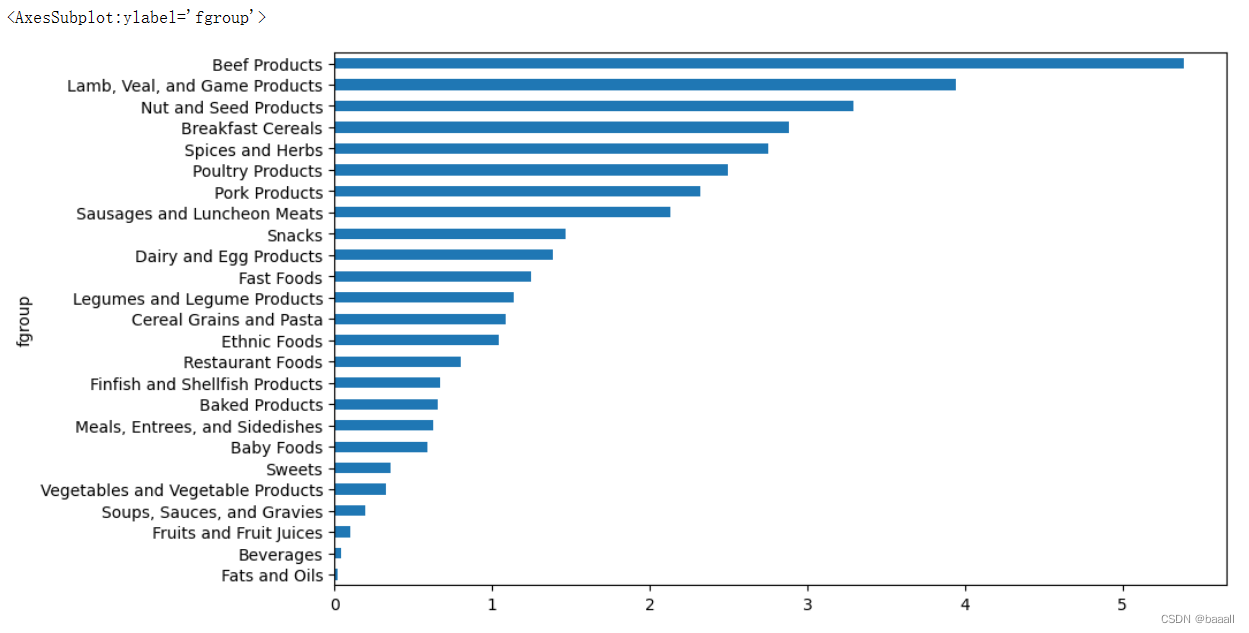
result = ndata.groupby(["nutrient", "fgroup"])["value"].quantile(0.5)
result["Zinc, Zn"].sort_values().plot(kind="barh")
以nutrient和fgroup分组,并排序绘制柱状图。
by_nutrient = ndata.groupby(["nutgroup", "nutrient"])def get_maximum(x):return x.loc[x.value.idxmax()]max_foods = by_nutrient.apply(get_maximum)[["value", "food"]]# make the food a little smaller
max_foods["food"] = max_foods["food"].str[:50]
max_foods.loc["Amino Acids"]["food"]
根据nutgroup和nutrient分组,并定义一个求最大值得函数,对value和food求最大值,对最大food读取前50行,读取Amino Acids行数据。

学习资源推荐
零基础Python学习资源介绍
👉Python学习路线汇总👈
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。(学习教程文末领取哈)

👉Python必备开发工具👈

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉Python学习视频600合集👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
👉实战案例👈
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
👉100道Python练习题👈
检查学习结果。

👉面试刷题👈

资料领取
上述这份完整版的Python全套学习资料已经上传CSDN官方,朋友们如果需要可以微信扫描下方CSDN官方认证二维码输入“领取资料” 即可领取。



![[Docker] Mac M1系列芯片上完美运行Docker](http://pic.xiahunao.cn/[Docker] Mac M1系列芯片上完美运行Docker)
















