本文发表于ICCV2023
论文地址:ICCV 2023 Open Access Repository (thecvf.com)
官方实现代码:lllyasviel/ControlNet: Let us control diffusion models! (github.com)

Abstract
论文提出了一种神经网络架构ControlNet,可以将空间条件控制添加到大型的预训练文本到图像扩散模型中。ControlNet将预训练好的大型扩散模型锁定,通过克隆的方式重新使用其深度和强大的编码层,以学习需要加入的各种条件控制,并通过一个特殊的卷积层“零卷积”连接。
通过各种实验证明,通过ControlNet来实现各种如边缘、深度、分割、人体姿势等条件控制的扩散模型是十分有效的,且无论对于大型还是小型数据集而言,训练都是鲁棒的,大量结果表明ControlNet可以促进更广泛的应用程序来控制图像扩散模型。
一、Introduction
目前文本生成图像的扩散模型可以给我们带来高质量的图像生成。然而,文本生成图像模型在对图像的空间组成提供的控制方面是有限的;仅仅通过文本提示精确的表达复杂的布局、姿势、形状和形式比较困难。因此生成一个与我们心理意向准确匹配的图像通常需要无数次的试验。于是我们试图通过提供额外的图像来直接指定想要的图像组合,从而实现更细粒度的空间控制,比如边缘图、人体姿势骨架、分割图、深度、法线等,这些通常被视为图像生成过程中的条件。
以端到端的方式学习大型文本到图像扩散模型的条件控制是具有挑战性的。特定条件的训练数据量可能显著小于可用于一般文本到图像训练的数据。直接微调或继续训练具有有限数据的大型预训练模型可能会导致过度拟合和灾难性遗忘。
本文介绍了ControlNet,这是一种端到端的神经网络架构,可以学习大型预训练文本到图像扩散模型的条件控制(在我们的实现中是稳定扩散)。
二、Related Work
1.微调神经网络
微调神经网络的一种方法是直接用额外的训练数据继续训练它。但这种方法可能导致过拟合、模式崩溃和灾难性遗忘。广泛的研究集中在开发微调策略,以避免这些问题。
这里主要简单介绍了HyperNetwork、Adapter、Addtiive Learning、Low-Rank Adaptation (LoRA)以及Zero-Initialized Layers。
2.图像扩散
这部分首先介绍了当前几个比较有名的图像扩散模型,包括潜在扩散模型LDM,也就是StableDiffusion的基础;以及GLIDE、Imagen、DALL-E2和Midjourney。
然后,介绍了目前比较流行的控制图像扩散模型的方法,主要包括MakeAScene、SpaText、Textual Inversion和DreamBooth等,最后还简单聊了一下图像到图像的转换条件。
三、Method
1.ControlNet

ControlNet会将附加的条件注入到神经网络的块中。
这个所谓的“网络块”用于指代通常放在一起以形成神经网络的单个单元的一组神经层,例如,resnet块、conv-bn-relu块、多头注意力块、Transformer块等。
论文中,以2D特征图为例,即x ∈ Rh×w×c,{h,w,c}分别为地图中通道的高度、宽度和数量。
为了将ControlNet添加到这样一个预先训练的神经块中,首先要锁定(冻结)原始块的参数Θ,同时将该块克隆到具有参数Θc的可训练副本中(图b)。可训练副本将外部条件向量c作为输入。当这种结构应用于稳定扩散等大型模型时,锁定的参数保留了用数十亿张图像训练的生产就绪模型,而可训练副本则重用这种大规模预训练模型,以建立一个深度,鲁棒性和强大的骨干来处理不同的输入条件。
然后,使用零卷积层将训练完的副本块与原始模型连接起来,并将学习到的额外条件信息映射到参数固定的预训练大模型中。如图(b)所示,将副本块与原始模型之间添加两个零卷积层,再与原始模型相连接,这两个零卷积层的权重会在训练过程中逐渐增加。通过这种连接方式,副本块的输出可以与原始模型的输出相加,从而将额外的条件信息引入到预训练大模型中。这样做的好处是,在训练初期,不会往大模型的深层特征中加入任何有害的噪声,同时也保护了预训练大模型的质量和能力。
2.ControlNet for Text-to-Image Diffusion
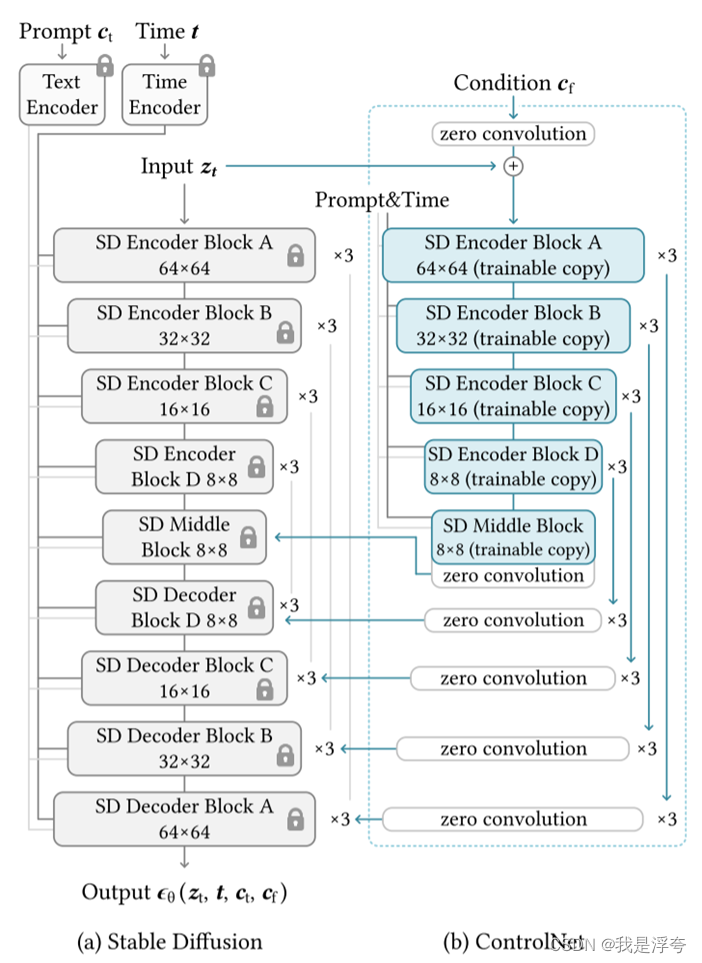
Stable Diffusion是一个在数十亿张图像上训练的大型文本-图像扩散模型,本质上是个U-Net,包括一个编码器、一个中间块和一个跳连解码器。编码器和解码器都有12个块,完整的模型包含25个块。在这些块中,有8个块是下采样或上采样的卷积层,17个块是主要块,每个块包含四个ResNet层和两个ViT。每个ViT包含几个交叉注意力。文本使用CLIP进行编码,扩散时间步使用位置编码进行编码。
如上图是将ControlNet添加到StableDiffusion中的结构图,如此连接ControlNet的方式在计算上是高效的-由于锁定的复制参数被冻结,因此在最初锁定的编码器中不需要梯度计算来进行微调。这种方法可以加快训练速度并节省GPU内存。在单个NVIDIA A100 PCIE 40 GB上进行的测试表明,与不使用ControlNet优化Stable Diffusion相比,使用ControlNet优化Stable Diffusion只需要增加约23%的GPU内存和34%的训练迭代时间。
3.Training
给定输入图像z0,图像扩散算法逐渐地将噪声添加到图像并产生噪声图像zt,其中t表示添加噪声的次数。给定包括时间步长t、文本提示ct以及特定于任务的条件cf的一组条件。

L是整个扩散模型的总体学习目标。输入的四个参数Zt,t,Ct,Cf分别是:
- Zt:潜在噪声向量
- t:时间步骤t
- Ct:文本提示Prompt
- Cf:额外添加的条件
在训练过程中,会随机将50%的文本提示ct替换为空字符串。这种方法增加了ControlNet直接识别输入条件图像中的语义的能力(例如,边缘、姿势、深度等)作为提示的替代。在训练过程中,由于零卷积不会给网络增加噪声,因此模型应该始终能够预测高质量的图像。
4.Inference
通过额外的方式进一步去控制ControlNet的外条件去影响去噪扩散过程:
Classifier-free guidance resolution weighting,StableDiffusion依赖于无分类器指导技术(CFG)来生成高质量的图像。它可以根据用户的指定权重来引导图像生成过程。当添加条件图像时,可以选择将其同时应用到图像的多个部分或只应用到特定部分。这样可以根据条件图像的特征来调整生成图像的细节。 为了实现CFG分辨率加权,我们首先将条件图像添加到一部分特定的区域。然后,在稳定扩散和条件图像之间的每个连接处,按照每个区域的大小给予权重。通过降低CFG的引导强度,可以在生成图像时更灵活地控制条件图像的影响。这样可以得到更加清晰和逼真的图像效果。
此外,还可以使用多个调节图像,例如Canny边缘和姿态,来进一步改进生成的图像。通过将不同调节图像的输出直接添加到生成模型中,而无需进行额外的加权或线性插值,可以有效地组合多个控制因素,使生成的图像更加细致和准确。
四、Experiments
1.Ablative Study

消融实验:
(a) ControlNet的原始结构
(b) 用高斯权值初始化的标准卷积层替换零卷积层
(c) 用单个卷积层替换每个块的可训练副本,称之为ControlNet-lite。
主要实验了四种测试:无提示、不充分的提示、具有语义冲突的提示、完美的提示。
结果:轻量级ControlNet-lite(图8 c)不足以解释调节图像,并且在不充分和无提示条件下失败。当零卷积被替换时,ControlNet的性能下降到与ControlNet-lite大致相同,这表明可训练副本的预训练骨干在微调期间被破坏(图8b)。

在ADE20K数据集上进行实验分析,指标是Intersection over Union (IoU),用于评估语义分割标签重建的准确性。

基于语义分割的图像生成评价。FID、CLIP文本图像评分和CLIP美学评分,用于我们的方法和其他基线。
FID 是用于衡量生成图像与参考模型生成图像之间的差距的指标,FID值越低表示生成图像与真实图像的分布越接近。
CLIP-score是使用CLIP模型计算的文本和图像之间的相似度得分,它衡量了生成图像与输入文本之间的语义一致性。
CLIP-aesthetic是使用CLIP模型计算的生成图像的美学评分,它衡量了生成图像的质量和视觉吸引力。
下面是与其他方法所做的比较:


参考:不得不读 | 深入浅出ControlNet,一种基于生成扩散模型Stable Diffusion、可控生成的AIGC绘画生成算法! - 知乎 (zhihu.com)














)
-1)



