如何获取SPSS自带的案例数据文件?
首先找到SPSS的安装目录,然后找到Samples文件夹
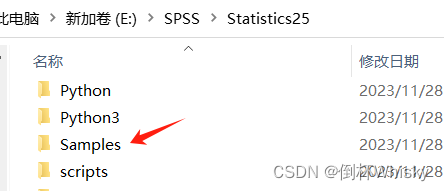
可以看到有不同语言版本,选择简体中文
就能看到很多.sav文件
数据文件的整理
个案排序
单值排序
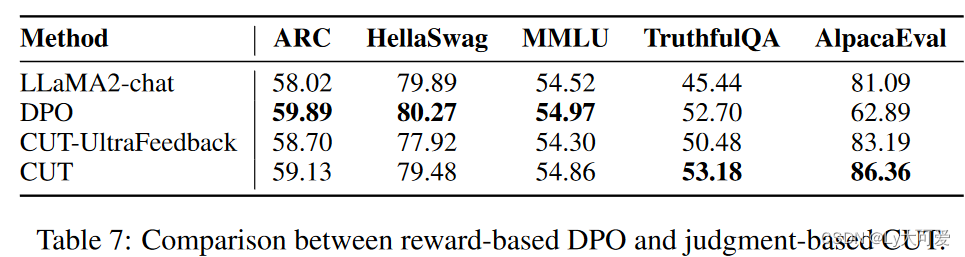
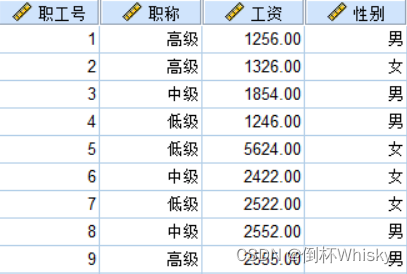
例:对于下面的数据集,将工资按照降序排序
菜单:数据-个案排序
排序依据选择工资,顺序选择降序
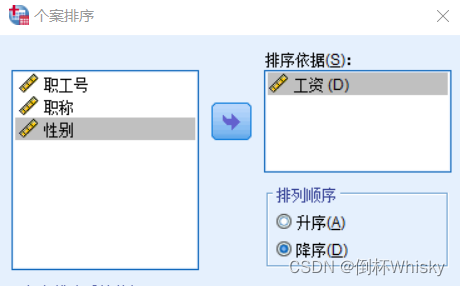
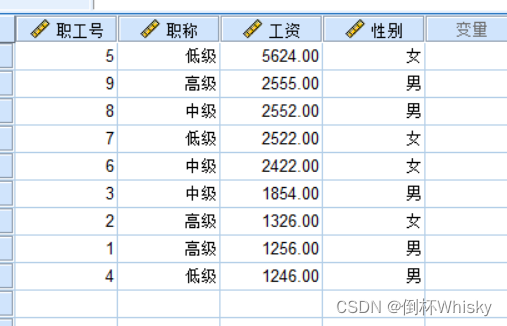
排序结果:
多重排序
当排序变量有多个时,第一排序为职称升序,第二排序为工资降序
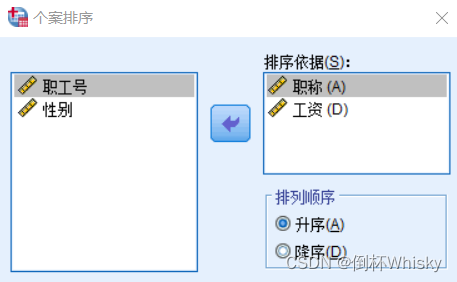
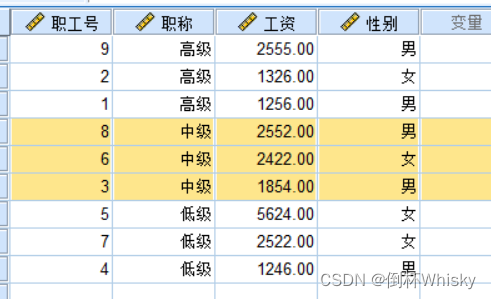
排序结果:
个案选取
根据不同的需要,从个案中筛选出符合条件的个案,有以下几种选取方式
- 选择符合给定条件表达式的个案
- 随机选取个案
- 精确选取
- 近似选取
- 选取某一区域的个案
- 使用过滤变量选取个案
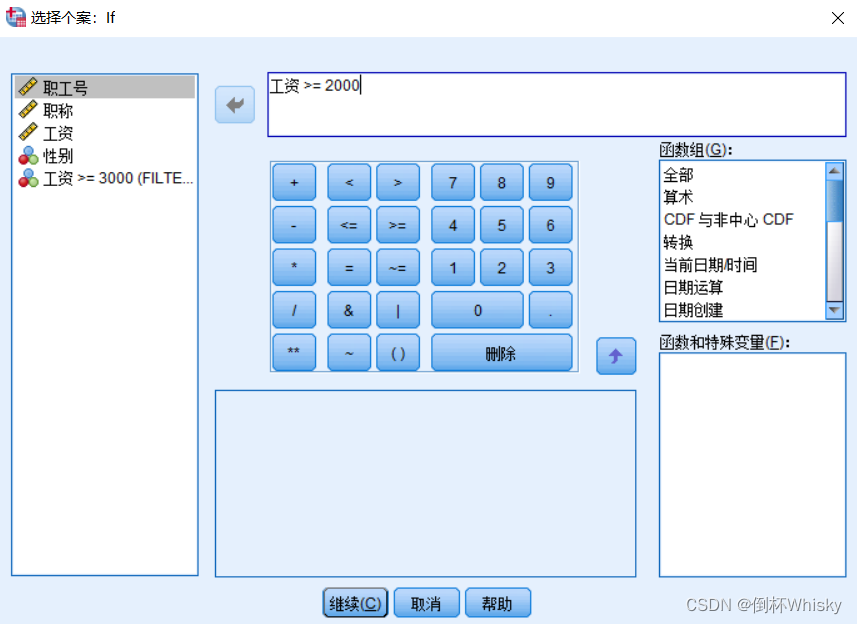
还是用上面那个数据集,筛选出工资大于等于2000的
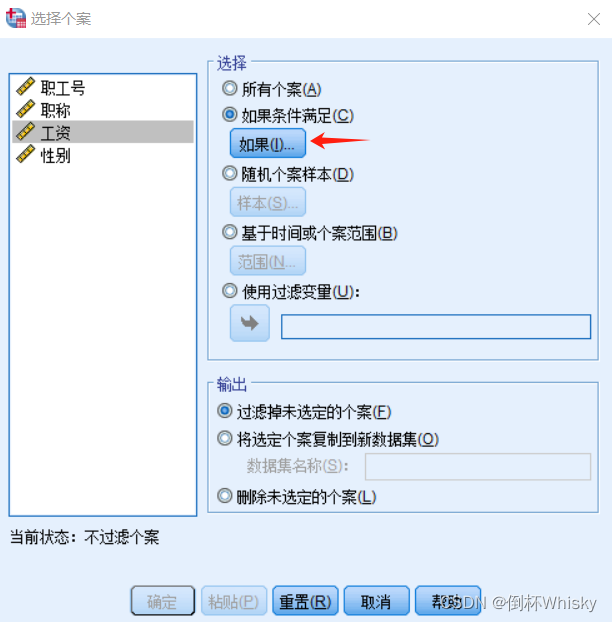
菜单:数据-选择个案

选择满足某个表达式的个案
过滤的结果: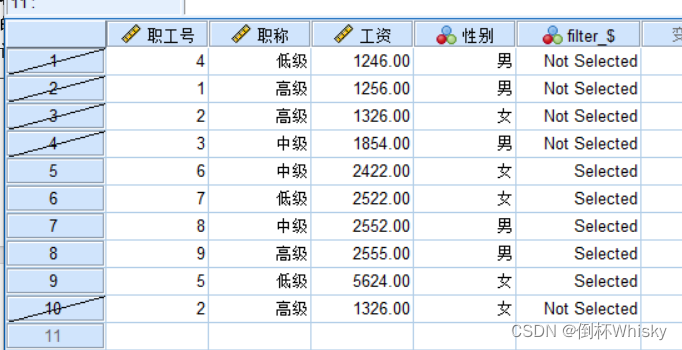
SPSS会在数据编辑窗口中自动生成一个filter_$的新变量,取值为选中或未被选中
数据文件的合并
在数据量比较大的时候需要将一份大的数据拆分成几个小部分由几个人去录入,因此,将这若干个小数据文件合并成一个大的数据文件是对大数据库分析的前提
纵向合并
将当前窗口的数据与另一个新的文件数据进行首尾对接,即:将一个SPSS数据文件追加到当前数据编辑窗口的后面
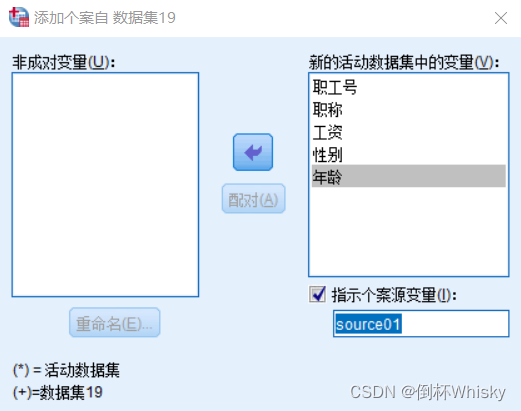
菜单:数据-合并文件-添加个案

选择需要追加的文件
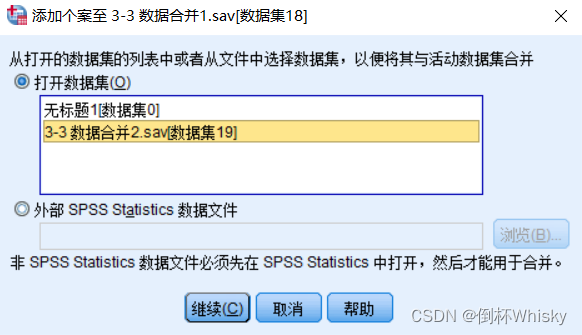
两个待合并的数据文件会被自动对应匹配,并出现在右边的框中,SPSS默认两个文件的变量名具有相同的数据含义,此外,选择指示个案原变量可以在合并之后看到那些个案来自哪个文件
合并结果:
横向合并
横向合并应遵循的三个条件:
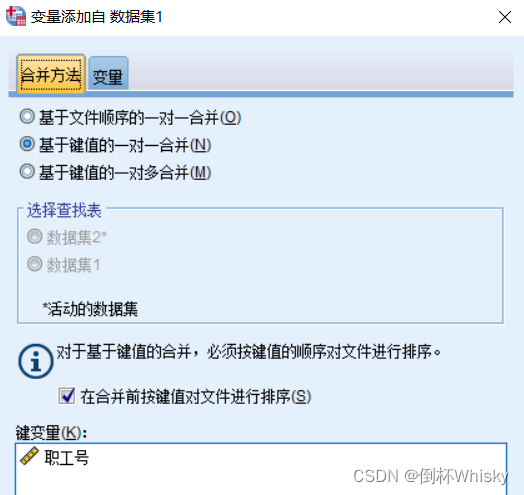
第一,两个数据文件必须至少有一个变量名相同的公共变量;
第二,两个数据文件都必须事先按关键变量进行升序排序或多重升序排序;
第三,为方便SPSS数据文件的合并,在不同数据文件中,数据含义不相同的列,变量名不应取相同的名称;
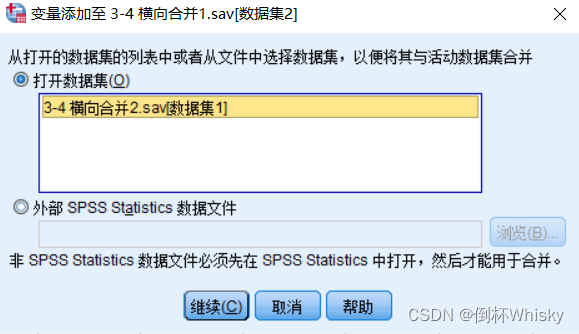
菜单:数据-合并文件-添加变量

选择数据集
选择基于键值的一对一合并
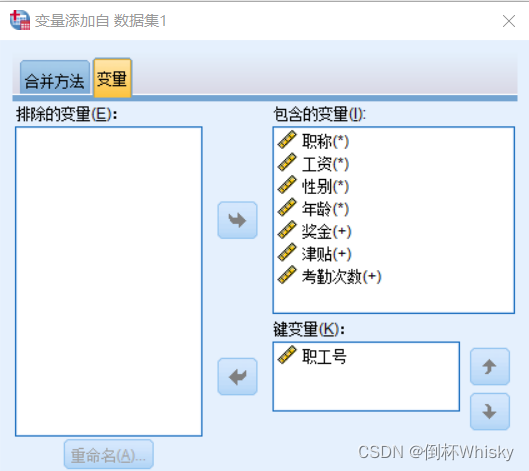
文件1:
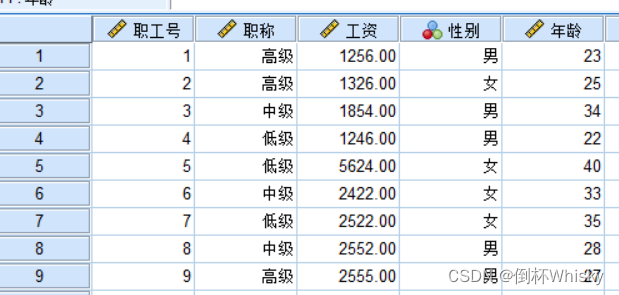
文件2:
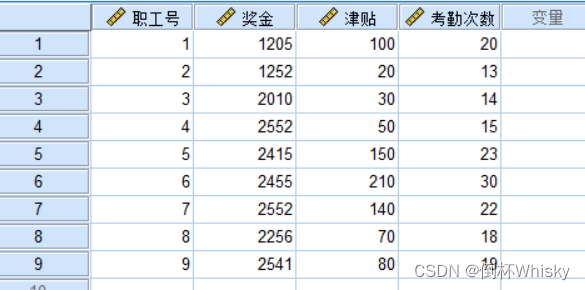
合并结果:
数据文件的转置
菜单:数据-转置

指定转置后的数据文件中保留了源文件的哪些变量,将其选入变量框中;
指定转置后数据文件中各个变量名如何取名,选择一个取值唯一的标记变量到名称变量框中,转置后的数据文件各变量的取值为:字母K开头加上该标记变量的变量值


数据加工
变量转换
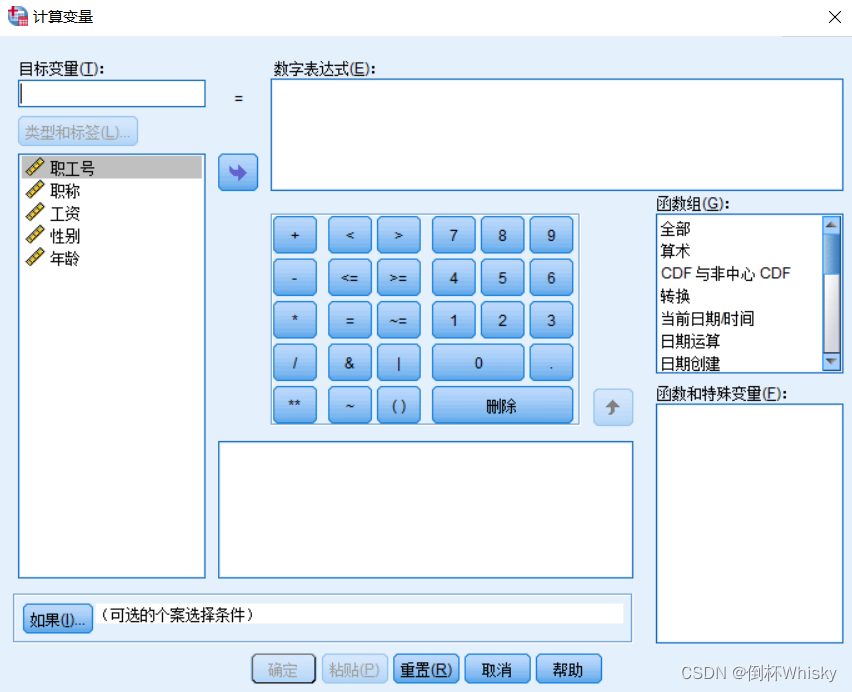
变量转换就是在原有 SPSS 数据文件的基础之上,根据用户给出的 SPSS算术表达式以及函数,对所有个案或满足 SPSS条件表达式的个案,计算产生出一系列结果,并将结果存到一个用户指定的 SPSS 变量中。这个指定的变量可以是一个新变量,也可以是一个已经存在的变量。
1.SPSS算数表达式
2.SPSS函数
有八大类,算数函数、统计函数、分布函数、逻辑函数、字符串函数、日期时间函数、缺失值函数和其他函数
SPSS常见函数
3.SPSS条件表达式
步骤
菜单:转换-计算变量