T1、【初级】线程和进程有什么区别?
(1)线程是CPU调度的最小单位,进程是计算分配资源的最小单位。
(2)一个进程至少要有一个线程。
(3)进程之间的内存是隔离的,而同一个进程中的线程之间是共享内存的。
T2、【初级】线程的创建有哪几种方式?
(1)继承Thread类,重写run方法。
(2)实现Runnable接口,重写run方法。
(3)实现Callable接口,重写call方法,结合Future创建线程。
(4)通过线程池创建。
T3、【初级】创建线程池的几种方式?
(1)使用Executors工具类创建线程池
(2)直接使用底层线程池构造函数创建线程:new ThreadPoolExecuto()
T4、【中级】线程池的参数有哪些?
// 五参创建public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue) {this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,Executors.defaultThreadFactory(), defaultHandler);}// 七参创建public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory,RejectedExecutionHandler handler) {//---}
(1)corePoolSize 核心线程数
(2)maximumPoolSize 最大线程数
(3)keepAliveTime 空闲线程存活时间
(4)unit 空闲线程存活时间单位
(5)workQueue 工作队列
- ArrayBlockingQueue
- LinkedBlockingQuene
- SynchronousQuene
- PriorityBlockingQueue
(6)threadFactory 线程工厂
(7)handler 拒绝策略
- 第一种拒绝策略是 AbortPolicy,这种拒绝策略在拒绝任务时,会直接抛出异常 RejectedExecutionException (属于RuntimeException),让你感知到任务被拒绝了,于是你便可以根据业务逻辑选择重试或者放弃提交等策略。
- 第二种拒绝策略是 DiscardPolicy,这种拒绝策略正如它的名字所描述的一样,当新任务被提交后直接被丢弃掉,也不会给你任何的通知,相对而言存在一定的风险,因为我们提交的时候根本不知道这个任务会被丢弃,可能造成数据丢失。
- 第三种拒绝策略是 DiscardOldestPolicy,如果线程池没被关闭且没有能力执行,则会丢弃任务队列中的头结点,通常是存活时间最长的任务,这种策略与第二种不同之处在于它丢弃的不是最新提交的,而是队列中存活时间最长的,这样就可以腾出空间给新提交的任务,但同理它也存在一定的数据丢失风险。
- 第四种拒绝策略是 CallerRunsPolicy,相对而言它就比较完善了,当有新任务提交后,如果线程池没被关闭且没有能力执行,则把这个任务交于提交任务的线程执行,也就是谁提交任务,谁就负责执行任务。这样做主要有两点好处。
- 第一点新提交的任务不会被丢弃,这样也就不会造成业务损失。
- 第二点好处是,由于谁提交任务谁就要负责执行任务,这样提交任务的线程就得负责执行任务,而执行任务又是比较耗时的,在这段期间,提交任务的线程被占用,也就不会再提交新的任务,减缓了任务提交的速度,相当于是一个负反馈。在此期间,线程池中的线程也可以充分利用这段时间来执行掉一部分任务,腾出一定的空间,相当于是给了线程池一定的缓冲期。
理解思路
- 队列已满,并且超过最大线程数,直接报异常
- 队列已满,并且超过最大线程数,抛弃新添加的任务
- 队列已满,并且超过最大线程数,抛弃最老的任务
- 队列已满,并且超过最大线程数,交给提交任务的线程来执行
T5、【中级】多线程中常用的工具类有哪些?
(1)CountDownLaunch:让某一条线程等待其他线程执行完毕后再执行
(2)CycleBarrier:希望多条线程准备就绪之后,一起开始执行
(3)Condition:当希望指定唤醒某条线程时使用
T6、【中级】线程池都有哪些类型?
(1)缓存型线程池:
ExecutorService executorService = Executors.newCachedThreadPool();
(2)固定长度线程池
ExecutorService executorService = Executors.newFixedThreadPool(10);
(3)可定时执行的线程池
ScheduledExecutorService executorService = Executors.newScheduledThreadPool(10);
(4)单线程化线程池
ExecutorService executorService = Executors.newSingleThreadExecutor();
理解思路
- 定长线程池
- 变长线程池
- 单线程池
- 定时线程池
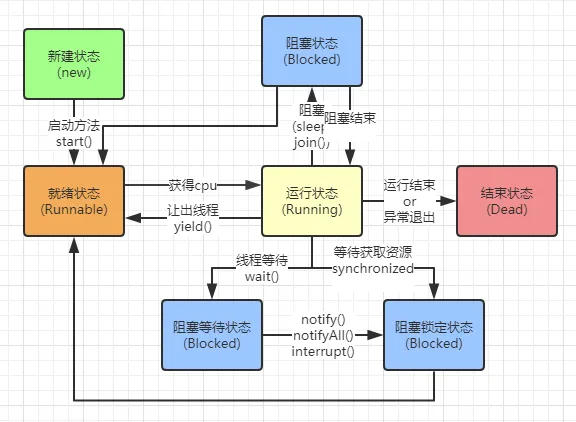
T7、【中级】线程的状态都有哪些?
T8、【中级】synchronized和static synchronized区别?
(1)synchronized是对象锁
(2)static synchronized是类锁
T9、【中级】synchronized与Lock有啥区别?
(1)实现方式不同:synchronized是Java语言内置的关键字,而Lock是一个Java API。
(2)粒度不同:synchronized锁的是整个方法或代码块,而Lock可以只锁定代码的一部分,可以灵活地控制加锁和解锁操作。
(3)可中断性不同:synchronized在获取锁失败时会等待,直到获取锁成功,而Lock可以通过tryLock()方法尝试获取锁,如果获取失败则可以终止等待。
(4)条件变量不同:Lock提供了Condition接口来实现线程之间的协调,而synchronized没有类似的概念。
(5)释放方式不同:synchronized可重入,即同一线程可以重复获取锁并解锁synchronized是自动释放锁。而Lock也可重入,但需要手动管理锁的计数器,Lock需要手动释放锁。
理解记忆
- synchronized是java内置关键字,自动释放锁,可重入,非公平
- Lock是接口,手动释放锁,可重入,可公平也可以不公平,默认是不公平
-
synchronized的底层原理是使用了操作系统的互斥对象(mutex)来实现的。
T10、【中级】start()和run()有啥区别?
(1)start()方法来启动线程,真正实现了多线程运行。这时无需等待 run 方法体代码执行完毕,可以直接继续执行下面的代码。
(2)通过调用 Thread 类的 start()方法来启动一个线程, 这时此线程是处于就绪状态, 并没有运行。
(3)方法 run()称为线程体,它包含了要执行的这个线程的内容,线程就进入了运行状态,开始运行 run 函数当中的代码。 Run 方法运行结束, 此线程终止。然后 CPU 再调度其它线程。
T11、【初级】wait()和sleep()有啥区别?
(1)调用方式不同:wait()是Object类的方法,可以调用任何对象的wait()方法;而sleep()是Thread类的静态方法,只能调用当前执行线程的sleep()方法。
(2)执行的对象不同:wait()会释放对象锁,线程执行完wait()方法后进入等待池中,只能被其他线程调用notify()或notifyAll()方法唤醒;而sleep()不会释放对象锁,线程暂停一段时间后,会重新进入就绪状态,由操作系统进行调度。
(3)使用方式不同:wait()、notify()和notifyAll()通常用于相互协调的线程之间进行协作,如线程A等待线程B的信号来进行操作;而sleep()通常用于程序中对时间的控制,如在执行某个操作时需要暂停一段时间后再继续执行。
(4)异常处理不同:wait()和sleep()都可以抛出InterruptedException异常,但是InterruptedException异常的含义不同。wait()方法在等待过程中如果线程被中断,则会抛出InterruptedException异常;而sleep()方法在睡眠过程中如果线程被中断,则会清除中断标志位,不会抛出InterruptedException异常。
理解记忆
- sleep()是静态方法,释放cpu但不释放锁,阻塞到时间了就继续执行
- wait()是object对象的方法,释放锁,通过notify()唤醒
T12、【初级】notify()和notifyAll()有啥区别?
(1)notify()随机唤醒一条线程;
(2)notifyAll()唤醒全部的线程。
T13、悲观锁和乐观锁有啥区别?
(1)并发控制策略不同:悲观锁采用独占锁(排他锁)的方式,在读写数据之前先获得锁,以保证操作的原子性;而乐观锁采用版本号或时间戳等方式实现数据版本控制,在更新数据之前先检查版本号或时间戳是否一致,以确保在多线程环境下对数据的并发访问正确。
(2)加锁开销不同:悲观锁需要频繁的加锁和解锁,造成了较大的加锁开销和系统资源浪费;而乐观锁只需要在更新操作时进行版本号或时间戳的比较,不需要进行加锁和解锁操作,因此开销较小。
(3)适用场景不同:悲观锁适用于多写少读的情况,例如数据库的更新操作;而乐观锁适用于多读少写的情况,例如缓存中数据的更新。
(4)冲突处理方式不同:悲观锁在获取锁失败时会进入等待队列等待锁的释放,从而避免了数据的冲突问题;而乐观锁在检查版本或时间戳失败时需要回滚事务或重新执行操作,从而处理数据的冲突问题。。
理解记忆
- 悲观锁,是重锁,是真正使用了锁
- 乐观锁,是轻量级锁,实际上没有使用锁,而是通过CAS实现的
T14、join和CountDownLatch区别
(1)join:join()是线程对象的成员方法,功能是等待调用join()的线程对象执行完毕,才执行其它的逻辑
(2)CountDownLatch是一种灵活的闭锁实现,它维护了一个计数器,通过计数器控制一个或多个线程等待另一组事件发生,具体控制方法是:CountDownLatch调用countDown方法来递减计数器,表示有一个事件发生了,调用await在计数器为0之前保持阻塞。
(3)区别:
- join()的阻塞原理是不停检查join()所属的线程对象是否存活(也就是线程完全执行完毕),如果存活则让调用join()的线程保持阻塞。
- CountDownLatch的阻塞原理是仅仅关注计数器是否为0,若不为0才保持阻塞,它并不关注持有计数器的其它线程是否完全执行完毕。
显然join()能控制阻塞的范围比CountDownLatch小,且没有CountDownLatch那么灵活。
理解记忆
- join是线程执行完了,才唤醒
- CountDownLatch是一个计数器,为0时才唤醒
T15、多线程有哪些特性?
(1)原子性
(2)可见性:保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,这新值对其他线程来说是立即可见的。
(3)有序性:通过synchronized和lock来保证有序性
T16、什么是锁?
锁就是在多线程环境下为保证共享资源健康、线程安全的一种手段。
线程操作某个共享资源之前,先对资源加一层锁,保证操作期间没有其他线程访问资源,当操作完成后,再释放锁。
T17、什么是死锁?
死锁是指两个或两个以上的进程在执行过程中,由于竞争资源或者由于彼此通信而造成的一种阻塞的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程。
T18、怎么避免死锁?
1、避免一个线程同时获取多个锁,如果必须使用多个锁,必须使用相同的加锁顺序。
2、降低锁的使用粒度,尽量保证一个锁只占用一个资源
3、尽可能使用定时锁,例如使用lock.tryLock(timeout)来替代使用内部锁机制
T19、分布式锁实有哪些实现方案?
1、基于数据库(唯一索引)
2、基于缓存(Redis,memcached,tair)
3、基于Zookeeper
T20、你都了解哪些锁?
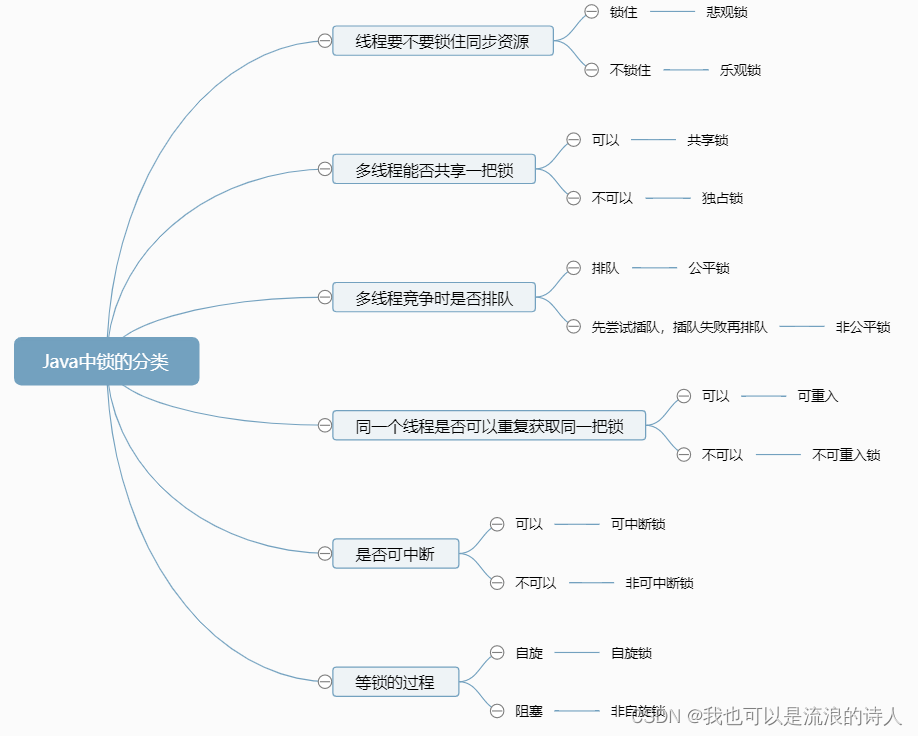










 解决方案)



山脊图)




