从今日开始,为大家开辟一个新的系列科研绘图。同一个竞赛下,大家都近乎相同的解题思路下。之所以能出现一等二等三等奖的区别很大部分都在于结果的可视化,为了能更好地帮助大家进行可视化,今后将专门推出一个可视化板块,推出各种好看实用的可视化图形。第一次给大家推荐的是山脊图,用以描述多个数据的分布方式。数模论文汇中,可以用作初始数据的可视化表达,即用这样图来解释题目给出了什么样的数据。下面是详细内容:
山脊图(Ridge Plot),也称为Joy Plot。它是一种数据可视化的方法,用于展示一个或多个组的数据分布。在山脊图中,每个组的数据分布通过平滑的密度曲线表示,这些曲线沿垂直轴堆叠排列,从而产生类似山脊的视觉效果。这种图表尤其适用于比较不同组的数据分布情况。
山脊图的制作基于核密度估计(Kernel Density Estimation, KDE),这是一种估计概率密度函数的非参数方式。与传统的条形图或直方图相比,山脊图提供了一种更平滑、更直观的方式来展示数据的分布情况。它特别适合于展示大量组的数据分布,可以帮助观察者理解不同组之间的差异和相似之处。
山脊图(Ridge Plot)是一种数据可视化工具,主要用于比较多个分布。以下是山脊图的一些优点和缺点:
优点
1. 比较能力:非常适合比较多个分布的形状和大小。它能清晰地展示不同组之间的变化和趋势。
2. 空间效率:通过在单个图中堆叠,山脊图可以有效地利用空间,显示多组数据,避免了创建多个单独的密度图。
3. 美观性:山脊图在视觉上吸引人,可以用不同的颜色和样式来区分不同的组,使得数据更加生动和直观。
4. 趋势识别:可以轻松识别多个群体数据中的共同模式和异常值。
5. 数据量:适用于展示大量数据集,而不会显得拥挤或不清晰。
缺点
1. 过度拥挤:如果组的数量过多,山脊图可能会显得拥挤,使得个别分布难以辨认。
2. 精确度:由于重叠,难以精确读取特定点的值,尤其是在分布之间的重叠区域。
3. 数值比较:虽然能够展示分布趋势,但不适合精确比较不同组之间的数值。
4. 边缘效应:在堆叠的密度图中,可能会产生误导,例如,边缘的分布可能看起来比实际更少。
本次更新主要以matlab为主,python实现代码也放于文末展示
首先是,绘制最初始的,最简单的山脊图,如下所示

% 清空环境变量和窗口
clear; close all;% 生成模拟数据
data = [];
groups = 6;
for i = 1:groups
data = [data; normrnd(i, 0.5, [200, 1])];
end% 为每组数据创建一个标签
group = repelem(1:groups, 200)';% 创建一个图形窗口
figure;% 对每组数据进行绘制
for i = 1:groups
% 选择当前组的数据
subset = data(group == i);
% 计算核密度估计
[f, xi] = ksdensity(subset);
% 绘制密度曲线,并上移相应的高度以创建堆叠效果
plot(xi, f + i, 'LineWidth', 2);
hold on;
end% 添加图例和坐标轴标签
legend('Group 1', 'Group 2', 'Group 3', 'Group 4', 'Group 5', 'Group 6');
xlabel('Value');
ylabel('Density');
title('Ridge Plot Example');% 显示图形
hold off;为了进一步美化图形,添加一些元素和调整一些参数来增强其视觉效果。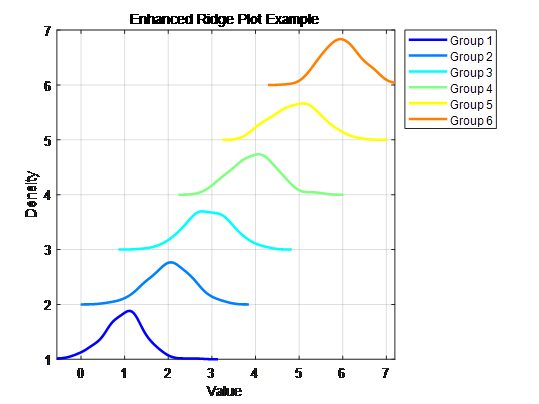
% 清空环境变量和窗口
clear; close all;% 生成模拟数据
data = [];
groups = 6;
colors = jet(groups); % 使用彩虹色系
for i = 1:groups
data = [data; normrnd(i, 0.5, [200, 1])];
end% 为每组数据创建一个标签
group = repelem(1:groups, 200)';% 创建一个图形窗口
figure;% 对每组数据进行绘制
for i = 1:groups
% 选择当前组的数据
subset = data(group == i);
% 计算核密度估计
[f, xi] = ksdensity(subset);
% 绘制密度曲线,并上移相应的高度以创建堆叠效果
plot(xi, f + i, 'LineWidth', 2, 'Color', colors(i, :));
hold on;
end% 添加图例和坐标轴标签
legend('Group 1', 'Group 2', 'Group 3', 'Group 4', 'Group 5', 'Group 6', ...
'Location', 'northeastoutside');
xlabel('Value');
ylabel('Density');
title('Enhanced Ridge Plot Example');% 设置坐标轴界限和网格
xlim([min(data), max(data)]);
ylim([1, groups + 1]);
grid on;% 设置字体大小
set(gca, 'FontSize', 10);% 显示图形
hold off;下面两个是matalb美化后的版本
下面进行python展示
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.stats import gaussian_kde# 如果您想尝试使用默认样式,可以注释掉下面这行代码
# plt.style.use('seaborn')# 生成模拟数据
groups = 6
data = pd.DataFrame({f'Group_{i}': np.random.normal(loc=i, scale=0.5, size=200) for i in range(1, groups + 1)})# 转换为“长格式”
data_long = pd.melt(data, var_name='Group', value_name='Value')# 初始化图形
fig, ax = plt.subplots(figsize=(10, 6))# 对每组数据进行绘制
for i, group in enumerate(data.columns):# 选择当前组的数据subset = data[group]# 计算核密度估计density = gaussian_kde(subset)xs = np.linspace(subset.min(), subset.max(), 200)ys = density(xs)# 绘制密度曲线,并上移相应的高度以创建堆叠效果ax.plot(xs, ys + i, lw=2)# 添加图例和坐标轴标签
ax.legend([f'Group {i + 1}' for i in range(groups)])
ax.set_xlabel('Value')
ax.set_ylabel('Density')
ax.set_title('Ridge Plot Example')# 显示图形
plt.show()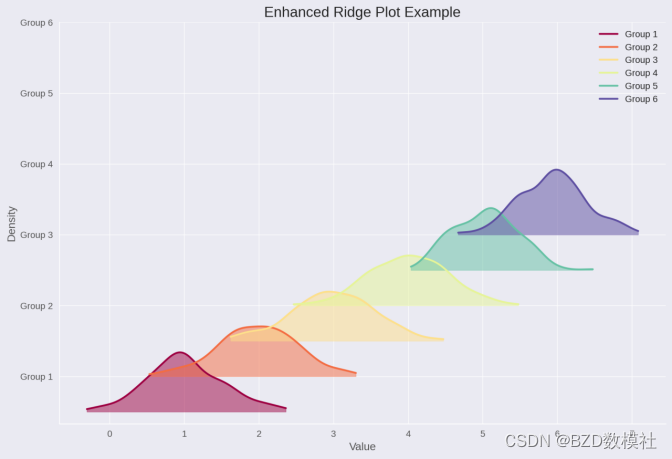










)








