目录标题
- 基本概念与原理
- 爬虫与搜索系统的关系
- 爬虫运行原理
- 爬虫步骤
- DNS域名解析
- 爬虫开发本质
- 网络爬虫的分类
- 通用网络爬虫
- 聚集网络爬虫
- 增量式网络爬虫
- Deep Web爬虫
- 参考文献
基本概念与原理
爬虫又叫网络蜘蛛,一种运行在互联网上用来获取数据的自动程序。
- 互联网的数据,有很多,一般都是根据业务需求来的。
- 网页(文字、图片、视频)
- 商品数据
- 怎么获取数据?
- HTTP协议
- 人的操作是通过浏览器的,程序是利用网络请求的相关协议获取数据。
- 自动化,尽可能减少人工的干预。
- 爬虫开发的技术,没有限制的。
- python做网络爬虫是非常流行的。
- Java 编写爬虫框架。
- 爬虫开发的技术,没有限制的。
说明:网络爬虫作为一项技术,更应该服务于社会。在使用该技术的过程中,应遵守Robots 协议(互联网行业数据抓取的道德协议)。同时,需要注意对数据所涉及的知识产权和隐私信息进行保护。
爬虫与搜索系统的关系
搜索系统的数据是爬虫爬取过来?不一定。
搜索系统可以简单的分为两类,通用搜索,站内搜索。
通用搜索:像百度,谷歌会爬取互联网上所有的数据 站内搜索:只需要业务系统的数据。 垂直搜索:行业数据和自己的数据。
总结:搜索一定会包含爬虫(除站内搜索外),爬虫爬取的数据不一定是为搜索服务。除了搜索功能以外,爬虫爬取的数据主要用来做数据分析。
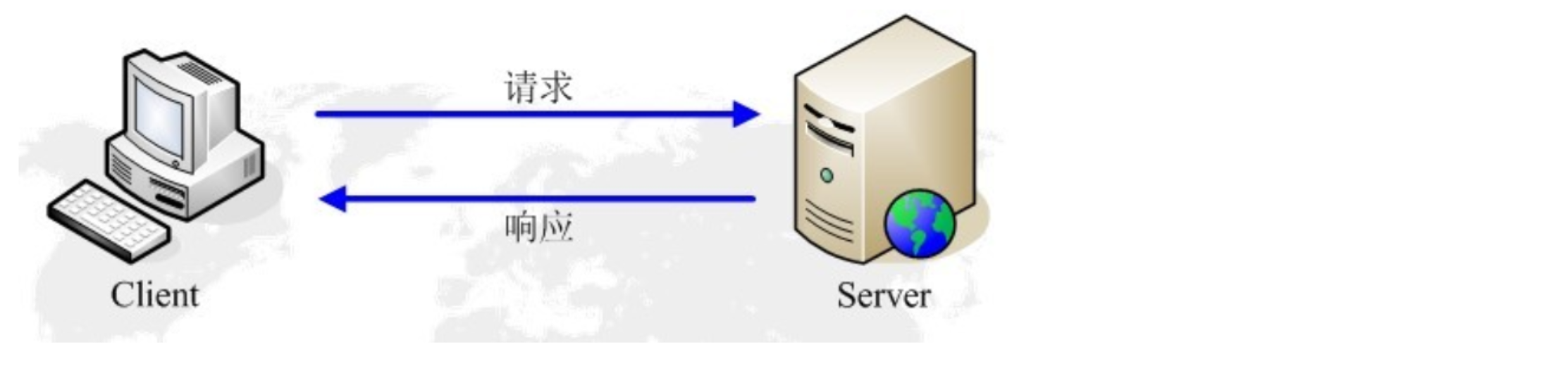
爬虫运行原理
模拟浏览器进行网络请求 模拟浏览器渲染(解析)html文档
爬虫步骤
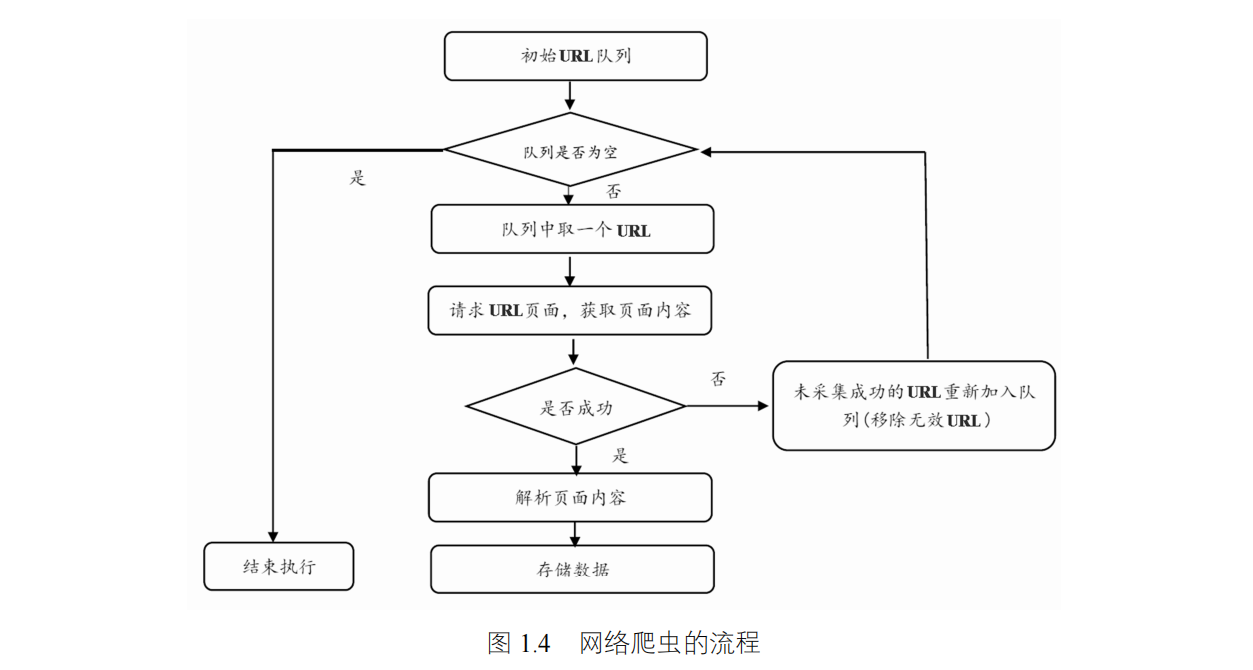
- 指定一个种子url放入到队列中
- 从队列中获取某个URL
- 使用HTTP协议发起网络请求
- 在发起网络请求的过程中,需要将域名转化成IP地址,也就是域名解析
- 得到服务器的响应,此时是二进制的输入流
- 将二进制的输入流转换成HTML文档,并解析内容(我们要抓取的内容,比如标题)。
- 将解除出来的内容保持到数据库
- 记录当前URL,并标记为已爬取,避免下次重复爬取。
- 从当前的HTML文档中,解析出页面中包含的其它URL,以供下次爬取
- 判断解析出来的URL是否已经爬取过了,如果已经爬取就丢弃掉
- 将还没爬取过的URL,存放到等待爬取的URL队列中。
- 重复以上的步骤,指导等待爬取的URL队列中没有数据
DNS域名解析
DNS(Domain Name System,域名系统),因特网上作为域名和IP地址相互映射的一个分布式数据库,能够使用户更方便的访问互联网,而不用去记住能够被机器直接读取的IP数串。
通过主机名,最终得到该主机名对应的IP地址的过程叫做域名解析(或主机名解析)。 DNS协议运行在UDP协议之上,使用端口号53
爬虫开发本质
本质是HTTP请求(计算机网络相关知识,可参考小林图解网络讲解)
使用HTTP GET协议获取数据,使用HTTP POST协议提交数据。
客户端向服务器发送一个请求,请求头包含请求的方法、URL、协议版本、以及包含请求修饰符、客户信息和内容的类似于MIME的消息结构。
服务器以一个状态行作为响应,响应的内容包括消息协议的版本,成功或者错误编码加上包含服务器信息、实体元信息以及可能的实体内容。
通常HTTP消息包括客户机向服务器的请求消息和服务器向客户机的响应消息。这两种类型的消息由一个起始行,一个或者多个头域,一个指示头域结束的空行和可选的消息体组成。

客户端向服务器发送一个请求,请求头包含请求的方法、URL、协议版本、以及包含请求修饰符、客户信息和内容的类似于MIME的消息结构。
服务器以一个状态行作为响应,响应的内容包括消息协议的版本,成功或者错误编码加上包含服务器信息、实体元信息以及可能的实体内容。
通常HTTP消息包括客户机向服务器的请求消息和服务器向客户机的响应消息。这两种类型的消息由一个起始行,一个或者多个头域,一个指示头域结束的空行和可选的消息体组成。
网络爬虫的分类
通用网络爬虫
通用网络爬虫又称全网爬虫(Scalable Web Crawler),爬行对象从一些种子 URL 扩充到整个 Web,主要为门户站点搜索引擎和大型 Web 服务提供商采集数据。 这类网络爬虫的爬行范围和数量巨大,对于爬行速度和存储空间要求较高,对于爬行页面的顺序要求相对较低,同时由于待刷新的页面太多,通常采用并行工作方式,但需要较长时间才能刷新一次页面。 简单的说就是互联网上抓取所有数据。
聚集网络爬虫
聚焦网络爬虫(Focused Crawler),又称主题网络爬虫(Topical Crawler),是指选择性地爬行那些与预先定义好的主题相关页面的网络爬虫。 和通用网络爬虫相比,聚焦爬虫只需要爬行与主题相关的页面,极大地节省了硬件和网络资源,保存的页面也由于数量少而更新快,还可以很好地满足一些特定人群对特定领域信息的需求 。 简单的说就是互联网上只抓取某一种数据。
增量式网络爬虫
增量式网络爬虫(Incremental Web Crawler)是指对已下载网页采取增量式更新和只爬行新产生的或者已经发生变化网页的爬虫,它能够在一定程度上保证所爬行的页面是尽可能新的页面。 和周期性爬行和刷新页面的网络爬虫相比,增量式爬虫只会在需要的时候爬行新产生或发生更新的页面 ,并不重新下载没有发生变化的页面,可有效减少数据下载量,及时更新已爬行的网页,减小时间和空间上的耗费,但是增加了爬行算法的复杂度和实现难度。 简单的说就是互联网上只抓取刚刚更新的数据。
Deep Web爬虫
Web 页面按存在方式可以分为表层网页(Surface Web)和深层网页(Deep Web,也称 Invisible Web Pages 或 Hidden Web)。 表层网页是指传统搜索引擎可以索引的页面,以超链接可以到达的静态网页为主构成的 Web 页面。 Deep Web 是那些大部分内容不能通过静态链接获取的、隐藏在搜索表单后的,只有用户提交一些关键词才能获得的 Web 页面。
参考文献
- 《网络采集技术Java网络爬虫实战》
- Java爬虫








)










