1. 引言
CLIP代表语言图像对比预训练模型,是OpenAI于2021年开发的一个深度学习模型。CLIP模型中图像和文本嵌入共享相同的潜在特征空间,从而能够在两种模式之间直接进行对比学习。这是通过训练模型使相关的图像和文本更紧密地结合在一起,同时将不相关的图像在特征空间距离分开来实现的。
闲话少说,我们直接开始吧!
2. 相关应用
关于CLIP模型的一些应用总结如下:
-
图像分类和检索:
CLIP可以通过将图像与自然语言文本描述关联起来进而可用于图像分类任务。它允许更通用和灵活的图像检索系统,用户可以使用文本查询来在数据库里搜索图像。 -
内容调节:CLIP可用于通过分析图像和附带文本来识别和过滤不适当或有害的内容,从而调节在线平台上的展示内容。
3. 核心思想
CLIP模型旨在预测一个batch中N×N个潜在(img,text)配对具体哪些是实际匹配的。为了实现这一点,CLIP通过图像编码器和文本编码器的联合训练建立了一个多模态嵌入空间。CLIP的损失函数旨在最大化批处理中N个真实配对的图像和文本嵌入之间的余弦相似性,同时最小化N²−N个错误配对的余弦相似度。以下是伪代码(取自原始论文),概述了CLIP的核心实现。

接着我们将伪代码中每一行的逐步描述,将其转化为使用PyTorch来实现。
4. 网络结构
在进行代码实现之前,我们先来简单回顾下clip模型具体的网络结构:

ClIP模型使用两种独立的网络结构来作为图像编码和文本编码的主干,其中:
image_encoder:负责编码图像的神经网络主干(eg,ResNet或Vision Transformer等)。text_encoder:表示负责编码文本信息的神经网络架构(eg,CBOW或BERT等)。
原始CLIP模型是从零开始训练的,而没有使用预训练的权重来初始化图像编码器和文本编码器,因为它们用于训练其CLIP模型的数据集体量很大(4亿个图像-文本对)。在这篇博客文章的例子中,我们将采取一些不同的做法。我们将从resnet(用于图像)和distilbert(用于文本)模型的预训练权重开始初始化这些部分。
5. 数据输入
该模型每个批次以n个图像和文本对作为输入,其中:
I[n,h,w,c]:表示对齐的图像的小批次输入,其中n是batch大小,h是图像高度,w是图像宽度,c是通道数。T[n,l]:表示对齐文本的小批次输入,其中n是batch大小,l是文本序列的长度。
我们的实现中,我们默认batch的大小为128,如下所示:

6. 特征提取
关于文本和图像的特征提取,这里使用resnet34和distilbert来分别提取图像和文本的特征,如下:
I_f = image_encoder(I): 从图像编码器中获取的图像特征表示I_f。I_f的大小为[n,d_I],其中d_I是图像特征的维度。T_f=text_encoder(T):从文本编码器中获取的文本特征表示T_f。T_f的大小为[n,d_T],其中d_T是文本特征的维度。
在本文实现中,相应的代码如下:
# for encoding images
I_f = models.resnet34(pretrained=True)
# for encoding captions
T_f= AutoModel.from_pretrained("distilbert-base-multilingual-cased")
7. 特征映射
接着,我们将相应的文本和图像特征,映射到同一嵌入特征空间,如下:
W_i[d_i,d_e]:表示用于将图像特征i_f映射到嵌入特征空间i_e的投影矩阵。W_i的形状大小是[d_i,d_e],其中d_e表示的是联合嵌入特征空间的维度。W_t[d_t,d_e]:表示用于将文本特征t_f映射到相同嵌入空间t_e的投影矩阵。W_t的形状大小是[d_t,d_e]。
投影操作可以使用具有两个线性层的神经网络进行编码,其权重是学习的投影矩阵。在大多数情况下,投影权重是唯一可以在新数据集上需要训练的权重。此外,投影层在对齐图像和文本嵌入的尺寸方面发挥着至关重要的作用,确保它们具有相同的维度。
相应的代码实现如下:

8. 组合
在上一节中,我们将文本和图像特征分别统一到相同的维度,接着我们将上述相关组件进行整合:
I_e = l2_normalize(np.dot(I_f, W_i), axis=1):在联合嵌入空间I_e中嵌入并归一化图像特征T_e = l2_normalize(np.dot(T_f, W_t), axis=1):在联合嵌入空间T_e中嵌入并归一化文本特征
接着我们使用以下Pytorch代码来描述图像和文本数据的处理次序。首先,相应的数据通过基本编码器进行处理,然后通过投影层进行处理。最后,为两种模态特征进行嵌入归一化化并返回。如下:

9. 余弦相似度
接着在嵌入空间,我们来计算文本图像嵌入特征的相似度:
logits = np.dot(I_e, T_e.T) * np.exp(t):用以计算图像和文本对在联合嵌入空间的特征余弦相似度,通过可学习的参数t进行缩放。
在我们的例子中,我们考虑暂不使用参数t,代码如下:
logits = T_e @ T_e.T
10. 损失函数
CLIP使用对比损失用以将相关图像和文本在嵌入特征空间拉近,同时将不相关的图像和文本距离拉远。
labels = np.arange(n): 用以生成表示batch索引的真值标签。loss_i = cross_entropy_loss(logits, labels, axis=0):用以计算图像特征和真值标签的损失loss_t = cross_entropy_loss(logits, labels, axis=1):用以计算文本特征和真值标签的损失loss = (loss_i + loss_t)/2:计算图像和文本损失的加权平均值。
代码实现如下:

11. 构建完整模型
将所有不同的部件组合在一起,最终的自定义CLIP模型如下所示:

12. 构建数据集
我们的自定义CLIP模型将使用flickr30k数据集进行训练。该数据集包括31000多张图像,每张图像至少有5个独立的人工生成文本描述。在这个例子中,我们将为每个图像使用两个标题,总共有62000个图像和文本对用于训练。 代码实现如下:

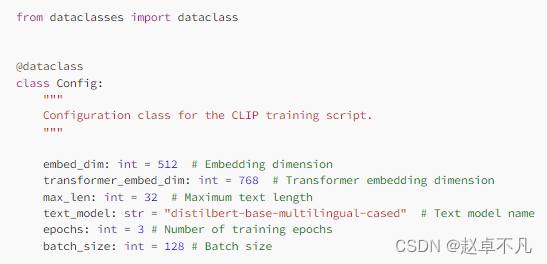
上述模型关键常数包括用于学习表示特征空间的维度embed_dim, 用于transformer特征维度的transformer_embed_dim和用于文本输入长度的max_len。所选的text_model是distilbert base multilanguage-cased。用以训练的模型的epoch为3,同时batch_size的大小为128,这些常数将用于模型构建和训练。如下所示:
13. 数据集测试用例
DataLoader是为训练期间的高效迭代而设置的,提供图像文本对的迭代访问。调用代码如下:
# Create the DataLoader
clip_dataloader = DataLoader(flickr30k_custom_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=4)
以下是数据集中一个批次中的图像文本对的示例:
import numpy as np
import matplotlib.pyplot as plt
# Create an iterator from the dataloader
data_iter = iter(clip_dataloader)# Get one batch
batch = next(data_iter)image = batch["image"][0] # get one image from the batch
caption = batch["caption"][0] # get one text from the batch# Convert the image tensor to a NumPy array and permute dimensions
image_np = np.transpose(image.numpy(), (1, 2, 0))# Display the image and caption
plt.imshow(image_np)
plt.title(f"Caption: {caption}")
plt.show()
运行结果如下:

14. 优化器选择
此外,我们还需要指定在整个训练过程中需要优化的参数。上文中我们已经固定了文本和图像编码器的特征提取层,那么只有与投影层相关的参数才会在新的数据集上进行训练。
# Create an instance of your model
model = CustomModel().to(device)# Define optimizer
optimizer = torch.optim.Adam([{'params': model.vision_encoder.parameters()},{'params': model.caption_encoder.parameters()}
], lr=model.lr)
15. 模型训练
我们使用Tesla T4的GPU机器进行3个epoch的训练,相应的训练代码如下:

执行上述训练代码,可以得到训练过程如下:

16. 总结
总之,这篇博客文章探讨了CLIP模型,揭示了其广泛应用的潜力。随着我们对CLIP应用的了解,很明显,它的影响远远超出了最初的预期,为不同领域的创新解决方案铺平了道路。
您学废了嘛?
完整代码:戳我




)
)
)



)

:Flume 聚合实战)


)

)
-Docker网络)
