论文题目
High-throughput cryo-ET structural pattern mining by unsupervised deep iterative subtomogram clustering
摘要
- 现有的结构排序算法的吞吐量低,或者由于依赖于可用模板和手动标签而固有地受到限制。
- 本文提出了一种高吞吐量的、无需模板和标签的深度学习方法,即 deep iterative subtomogram clustering approach (DISCA)。通过学习和建模三维结构特征及其分布,自动检测同质结构的子集。
- 在五个实验数据集上的评估表明,基于无监督深度学习的方法能够检测具有广泛分子大小范围的多样结构。
简介
DISCA通过学习由CNN提取的3D结构特征,并统计建模特征分布,自动在大规模冷冻电子断层扫描数据集中检测结构同质的颗粒子集。
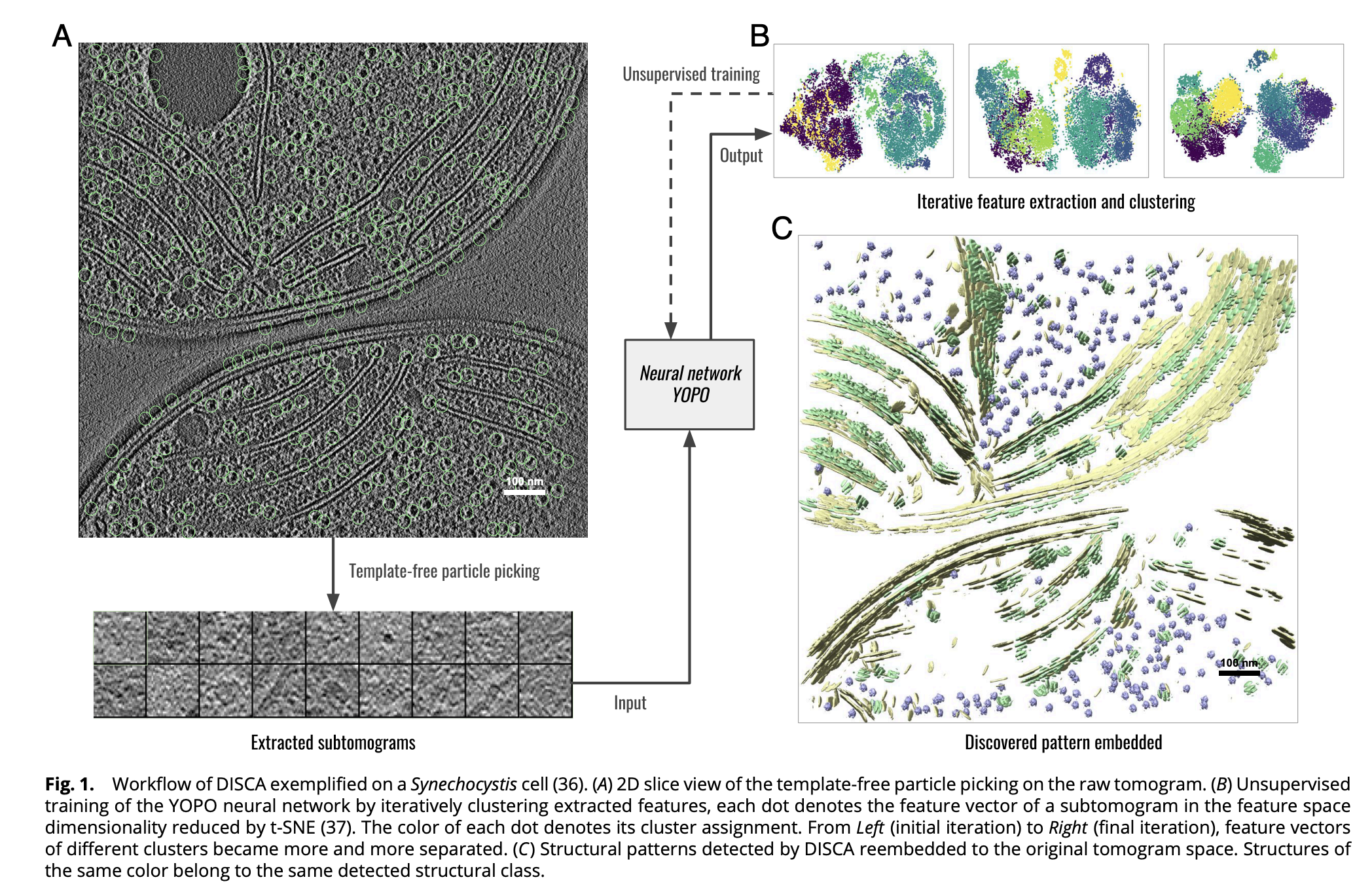
给定一个重建的3D断层扫描数据集,在预处理步骤首先使用无模板颗粒拾取方法来检测潜在的结构并提取它们作为子体积。该预处理步骤是自动完成的,不需要手动标记,提取的子体积包含异质结构。
然后,使用DISCA将这些子体积分拣到相对同质的结构子集中。具体来说,作者提出了一个广义的期望最大化(EM)框架,根据提取的CNN特征迭代地对子体积进行聚类,并通过无监督训练优化CNN。最后作为框架之外的后处理步骤,已排序的子集被对齐、平均和重新嵌入到原始断层扫描空间,以可视化恢复的结构及其空间分布。
结果
DISCA 计算框架
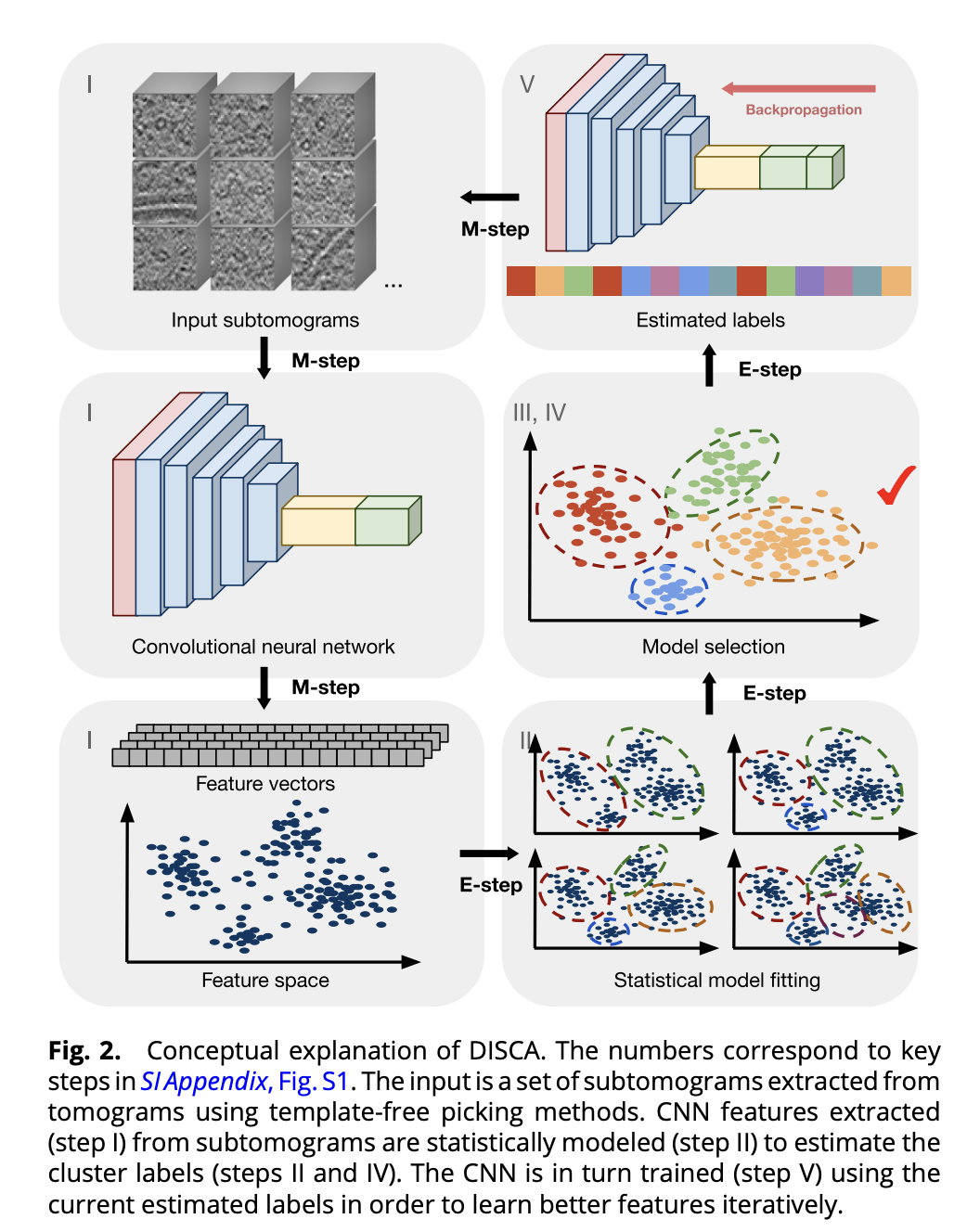
DISCA主要受到计算机视觉领域最近提出的无监督图像聚类方法的启发。这些方法将深度神经网络与特征聚类算法和自监督策略相结合,从大规模二维图像数据集中学习图像的判别特征表示,而不需要预先指定的图像标签。同样,我们将特征聚类算法和自监督融入到DISCA中。此外,考虑到cryoET数据的特定属性,例如低信噪比和未知的簇的数量,我们设计了神经网络架构和训练策略来提高cryoET数据的结构排序性能。由于本文方法是无监督训练,因此设计了一种策略来迭代估计结构同质子集的数量和输入自断层图的结构类标签。提出的迭代动态标记策略通过广义期望最大化算法以交替方式更新两个模型。图2说明了用于特征提取的YOPO模型和用于特征空间中结构同质子集统计建模的高斯分布。
在E步骤中,根据当前学习的特征估计结构同质子集的数量和标签。
在M步骤中,YOPO参数通过反向传播训练进行更新,以最小化计算从E步估计的标签的损失函数。
具体来说,YOPO被随机初始化来从输入的子断层图中提取特征向量。
然后,通过一组K个候选结构同质子集的混合多元高斯分布在特征空间中拟合特征向量。只保留具有最低贝叶斯信息准则的混合分布。通过继承前一次迭代的参数来稳定统计模型拟合的优化过程。在第一个迭代之后的每次迭代中,高斯混合模型的参数先验,包括每个聚类的先验权重、均值和每个聚类的协方差矩阵,都由前一次迭代的聚类解初始化。
因为在使用前一次迭代结果初始化统计模型拟合时可能会积累误差,为了避免陷入局部最优,每轮迭代还会进行随机初始化参数的全新模型拟合。如果这个模型提高了统计模型的似然函数,这个参数就会被采用。这一设计的基本思想类似于强化学习中的Epsilon-Greedy算法。其中以一定概率选择用新解替换前一次观察的最佳解。
然后,子体积的当前估计标签由与具有最高概率的分量多元高斯分布相对应的硬聚类分配给出。在下一次迭代中,当前估计的标签用于通过最小化分类铰链损失函数训练YOPO,以学习更好的特征表示。经过YOPO训练后,混合分布将根据新提取的特征向量进行更新。这个过程迭代进行,直到满足停止标准——标签的一致性或最大迭代次数。
为了利用CNN的卓越性能,本文设计了一个专门用于子体积数据的CNN,命名为YOPO(SI 附录,图 S2),考虑了子体积数据的独特特点:
1)结构细节对于确定包含在亚体积中的大分子的类别至关重要;
2)包含的大分子具有随机的方向和位移;
3)信噪比(SNR)极低。
由于其强大的架构设计,YOPO具有结构细节保留、变换不变性和对噪声的鲁棒性等特性。这些也是在传统子体积分类方法中的理想特性。
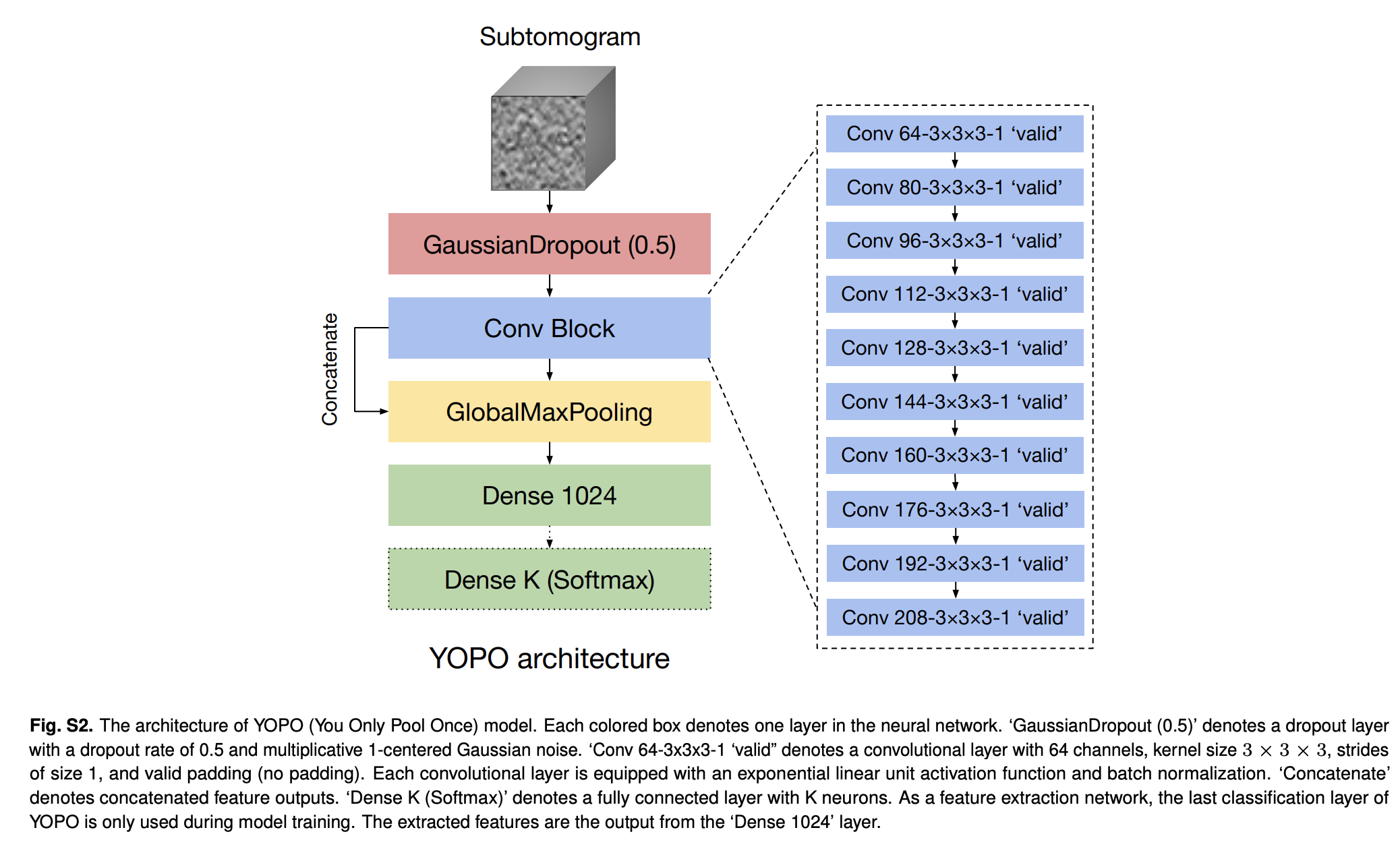
作为一个特征提取模型,YOPO保留了详细的结构信息,并从子体积数据中提取旋转(通过自监督训练)和平移不变(通过架构设计)的特征。YOPO的平移不变性与输入数据或网络权重无关。这种平移不变性通常无法通过标准的CNN架构设计实现。
在SHREC2020比赛里YOPO的准确度是第三名,超过了模板匹配。重要的是,YOPO只需要目标大分子的位置坐标用来训练,其他有竞争力的算法需要体素级别的分割label。
在DISCA中YOPO的训练完全是无监督的,并且进一步自动化,不受所有外部领域知识的影响,包括现有的结构模板、手动标记或手动选择断层图中的密度。
Validation of the Feature Learning and Modeling Ability.
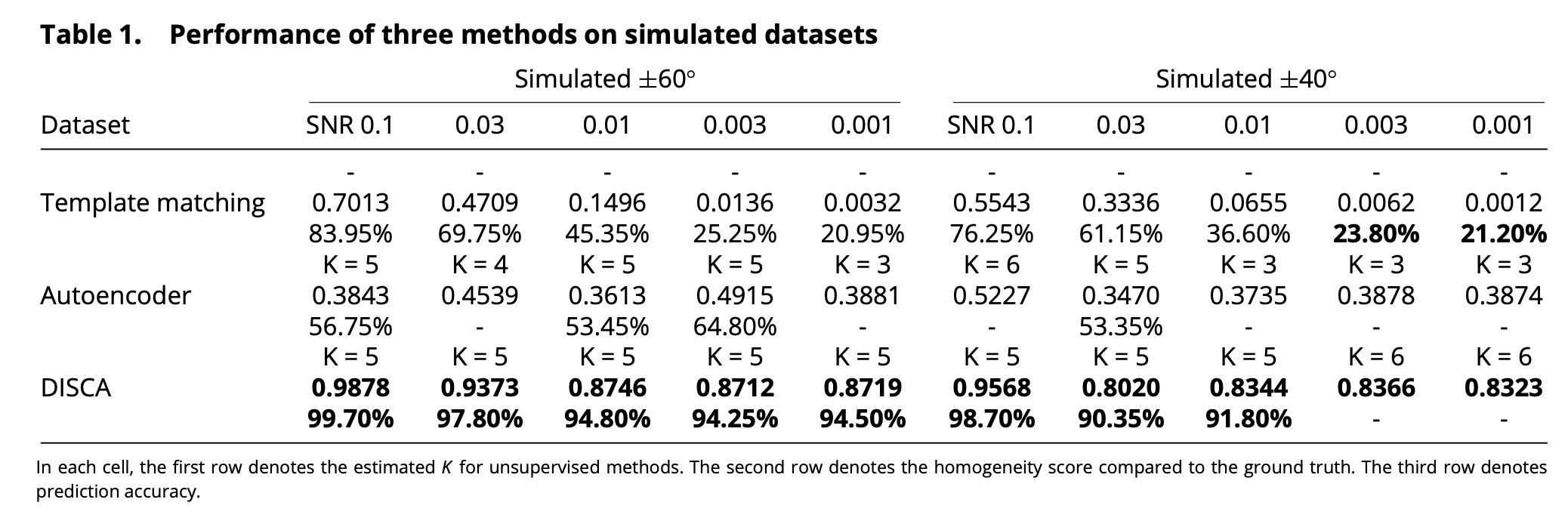
DISCA的设计能够实现变换不变性(transformation-invariant)的特征提取,自动估计聚类数量,并随着更大的样本量逐步提高性能。为了验证DISCA的这些能力,作者对各种成像参数的真实模拟数据集进行了多次实验。这些模拟数据集具有预先指定的真实标签,可以定量评估DISCA和现有方法的性能。
通过三个标准评估结果:
(1)估计的K (K范围2-20)
(2)同质性得分:根据真实标签衡量每个簇的同质程度。同质性得分不需要和真实值相同数量的聚类。
(3)预测准确度:测量正确标记的子断层图的百分比。只有K估计正确才能计算预测精度。
结果表明,随着信噪比降低和倾斜角度范围变小,同质性得分逐渐下降。所有设置下同质性得分都高于0.8,结果良好,意味着生成的簇通常是同质的。
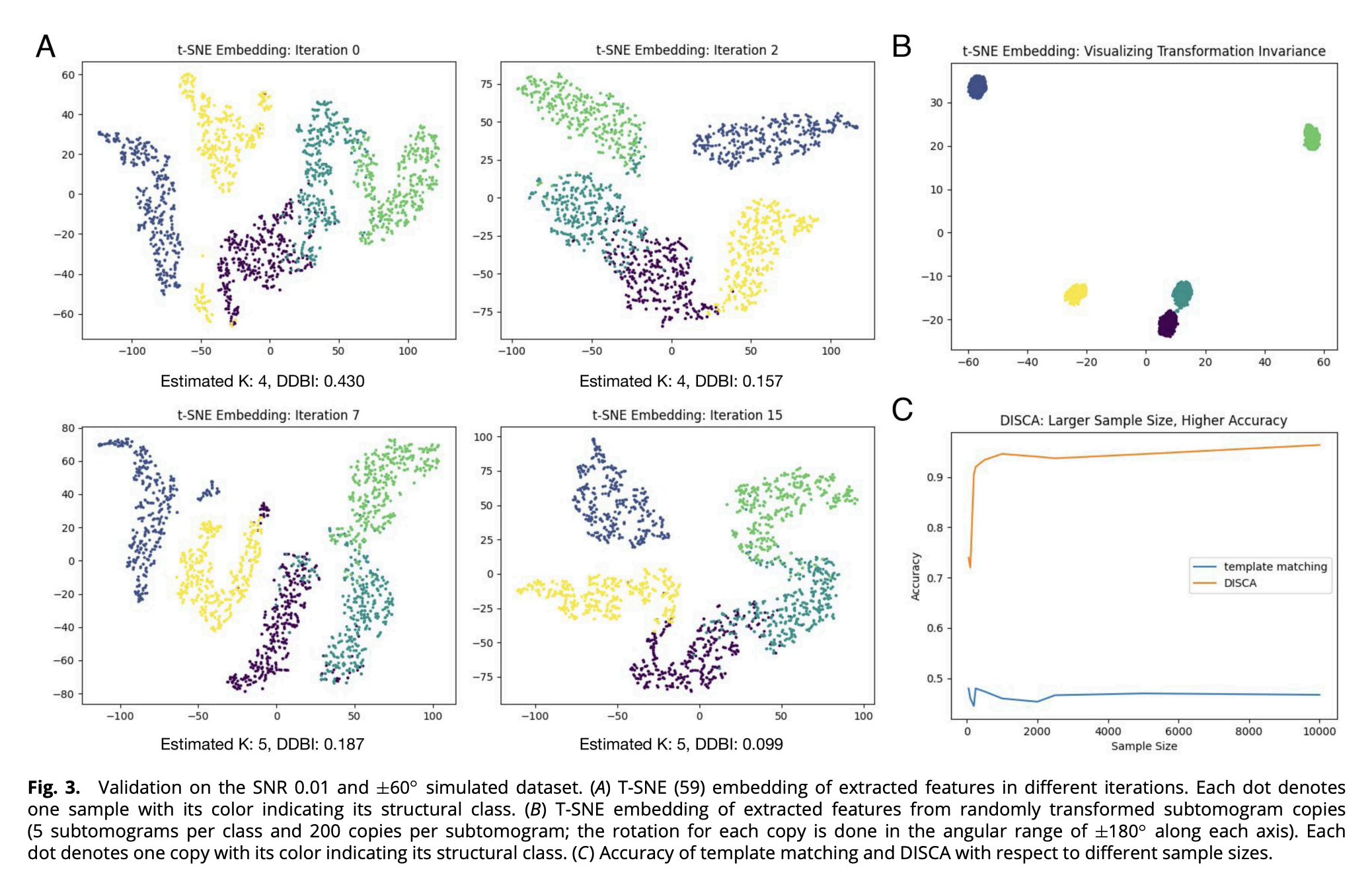
无监督结构模式挖掘
目前有许多流形的子断层图平均软件,将平均值细化到高分辨率。但这些工具需要结构相对均匀的颗粒输入。DISCA的主要目的是有效地将代表性结构分类为大规模数据集中结构相对同质的子集,以补充这些工具。因此DISCA的目标是以高通量的方式识别代表性结构,而不是提高子断层平均分辨率。作者在来自不用细胞类型的五个实验冷冻电子断层扫描数据集上进行了测试。由于ground truth未知,有两种主流的方法来验证检测结果:1. 对每个检测到的结构子集进行对齐平均以恢复结构,并将其与现有的已知结构进行比较。2. 是与结构生物学家的手动注释进行比较。对五个数据集,作者进行了子断层图平均并计算了金标准傅里叶桥相关分辨率。其中三个实验数据集有专家标注,一个数据集由之前的粗表示学习方法自动标注。结果表明,DISCA检测到了多种代表性结构模式。子断层图对齐平均得到分辨率范围为14-38埃,证明了无模板和标记的方法适合原位结构分析。
讨论
局限性:
- DISCA的一个主要限制来自于对选定的子断层图的操作。理想情况下应该分析每个体素的子断层图,但是计算复杂度太高。尽管颗粒挑选步骤引入了一些false positives和negatives,但在和效率之间的trade-off是可接受的。
- 每个体素的绝大多数颗粒都包含背景噪声或结构,它们在断层图里难以识别。包含这些在内会导致排序过程将使模型偏向于区分结构和背景,而不是结构之间的差异。由于不同的大分子结构尺寸不同,在实验中使用了固定的子断层图尺寸,可以包围大多数大分子结构,为了避免结构被剪切,可以提供更大的子断层图,或者对DISCA使用相同的子断层图大小并提取更大尺寸的子断层图进行后处理平均。
- 另一个限制是分析大型连续结构,例如膜。子断层图平均的嵌入将显示为小块。可以通过对子断层图执行膜分割而不是进行平均来解决。从而产生逼真的连续膜结构标注。
无监督方法的一个主要关注点是训练稳定性。DISCA的训练通常是稳定的,这归功于所使用的初始化器:作者为YOPO使用了正交核初始化器和零偏置初始化器。训练的稳定性确保了DISCA的可重复性。在实际应用中,为了获得最佳的排序性能,用户可以运行DISCA多次并保留具有最低DDBI度量的结果,或者保留在现有数据集上成功预训练的DISCA模型,并在新数据集上进行微调。
在方法论的简约性方面,DISCA不需要手动干预或选择现有的结构模板进行匹配,这个特性提供了最大的自动化和客观性。总之,性能表明当缺乏数据集的手动注释或先验知识时,DISCA是冷冻电子断层扫描结构发现的一个合理替代方法,同时也是验证基于模板的结果的强大工具。通过快速检测冷冻电子断层扫描数据集中的代表性同质结构子集,DISCA还可以作为标准模板匹配和子体积平均流程的预处理步骤的补充。虽然DISCA能够自动检测丰富和具有代表性的冷冻电子断层扫描颗粒,但研究人员有时对稀有的大分子或特定类型的目标蛋白质感兴趣。DISCA在检测相对稀有结构方面的能力在表3的TRiC和蛋白酶体结构上已经得到了定量证明。
此外,用户可以
1)结合DISCA和模板匹配来搜索特定的目标蛋白质;
2)将DISCA扩展到多个阶段,首先检测并排除丰富的颗粒,然后再次应用DISCA对剩余的颗粒进行排序。
总之,DISCA展示了用于系统地发现丰富和具有代表性结构的高吞吐量冷冻电子断层扫描结构模式挖掘的潜力。
A u t h o r : C h i e r Author: Chier Author:Chier


———链式语句中table用法)
)









)
总结Ⅰ)
)

函数详解)

