小样本学习介绍
本文首先介绍了什么是小样本学习,其次介绍了为什么小样本学习的很多文章都采用元学习的方法。目的是通过通俗的解释更加清楚的介绍小样本学习是什么,适合初学者的入门。当然,以下更多的是自己的思考,欢迎交流。
什么是小样本学习?
当我开始接触“小样本”这个术语的时候,给我的第一感觉就是他的数据集很小(这也是我入坑小样本学习最开始的原因,以为炼丹不需要太久),相信很多人有个同样的感觉,但是事实上并不是这样的,在我将小样本学习这一方向介绍给自己的同门或者其他同学的过程中,我发现很多人也都对小样本有着同样的误解。实际上,小样本的“小”并不是体现在数据集上。相反,小样本的数据集是很大的,比如常用的mini-imagenet有6万张图片,更大的tiered-ImageNet有779165张图片,所以说数据集并不小。
那么小样本的这个“小”体现在哪里呢?
这个小其实是针对小样本学习的特定任务而言的,比如我在下图例举的five-way one-shot的任务,way代表类别的数量,shot代表每个类别有几张图片,five-way one-shot指的就是有五个类别,每个类别有一张图片,five-way one-shot任务中定义了两个集合,分别是支持集和查询集,小样本学习的任务的目标就是判断查询集的图片是属于支持集中哪一个类别的。讲到这里大家可能就明白了小样本学习的“小”并不是体现在数据量小。而是体现在小样本学习这一特殊任务设定,即每个类别(n-way)只有少量的标记图片(k-shot),也就是我们的支持集,要求我们的模型能根据这几张少量的图片,判断查询集图片的类别。

为什么元学习能应用到小样本学习?
首先简单的介绍一下什么是元学习:元学习 (Meta-Learning) 是一种机器学习方法,其目标是使计算机系统能够学习如何学习。简单来说,它是关于如何构建和设计机器学习系统的更高层次的学习方法。元学习的一个重要目标是提高机器学习系统的泛化能力,泛化能力是指一个机器学习系统能够从已知的数据中推广到未知的数据。通过元学习,我们可以训练模型具有更好的泛化能力,从而可以更准确地预测未来的数据。
单从元学习的定义来说,我们很难将元学习和小样本学习联系到一起。所以很快就能提出疑问:
为什么大多数的小样本学习的方法大多数都采用元学习的训练策略呢?
在上一节我们提到,小样本学习的任务的目标就是判断查询集的图片是属于支持集中哪一个类别。也就是说我们的目标是判断查询集的图片是属于支持集中哪一个类别(如下图所示,小样本学习的测试方式与传统的训练模型的方式是不同的,其本质上是一种匹配任务(将查询集中的图片匹配到对应的支持集))。既然小样本学习的任务目标是如此,那么,我们在小样本学习任务的训练过程中,为什么不模拟这一测试的过程(n-way k-shot)呢?于是,我们在小样本学习训练的过程中,采用元学习的训练策略,即将训练集划分为支持集和查询集,模拟测试时的小样本场景,相当于划分成一个又一个的小样本学习任务(也叫episode),每一个任务都是一个测试场景下的few-shot task,通过这种方式,就能更好的训练小样本模型(论文实验证明效果确实好)。
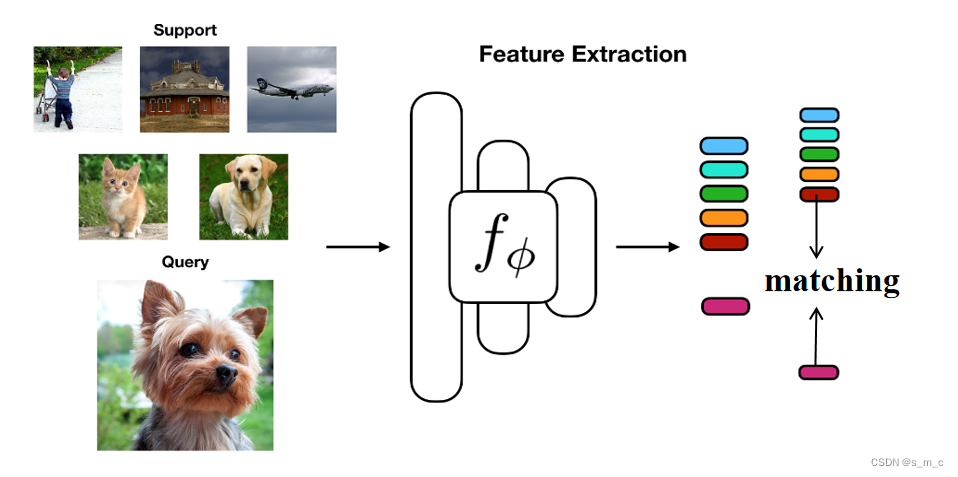
讲到这里,相信大家都清楚了为什呢我们要在训练的时候将小样本学习的训练集划分成支持集和查询集进行训练,如上图所示。同时也从根本上了解了为什么小样本学习的训练策略(元学习的训练策略)与一般的深度学习模型的训练策略的不同。更进一步来说,拿mini-imagenet数据集来举例。mini-imagenet本身有100个类,我们通常将前64个类划分为训练集,16个类划分为验证集,20个类划分为测试集。同时,我们对训练集、验证集和测试集进行进一步的划分,拿5-way 1-shot任务而言,我们首先会随机选取5个类,并在每个类中选取一张图片(也就是5way-1shot),然后再分别从选取的5个类中每个类别选取15张图片,得到了75张图片作为查询集(15*5=75)。在训练的过程中通过不断判断查询集图片的类别,进行有监督的loss的方向传播,更新我们的模型(当然这里并不一定每个类别抽取15张图片,也可以是其他的数量的图片,不过大多数论文都使用15这个数量,目的是更多的query能带来更多的loss的更新,但是query图片太多也不好,会导致support图片的数量变少,总体的episode的数量变少。所以说二者之间需要有一个权衡)。我本人也做过一些尝试性的实验,query图片数量在15上下得到的结果是最优的。
以上就是对小样本学习的一个总体介绍,后续我会不断的更新小样本学习相关的系列工作,其中也会穿插自己的拙见,就此落笔。

)


)

】开发项目经验积累(处理问题))



同时替换多个字符)


)
![[设计模式 Go实现] 行为型~迭代器模式](http://pic.xiahunao.cn/[设计模式 Go实现] 行为型~迭代器模式)

![# [NOIP2015 普及组] 扫雷游戏#洛谷](http://pic.xiahunao.cn/# [NOIP2015 普及组] 扫雷游戏#洛谷)


