在拥有大量表格形式数据的组织中,数据分析师的工作是通过提取、转换和围绕数据构建故事来理解这些数据。 分析师访问数据的主要工具是 SQL。 鉴于大型语言模型 (LLM) 令人印象深刻的功能,我们很自然地想知道人工智能是否可以帮助我们将信息需求转化为格式良好的 SQL 查询。
诚然,大多数LLM可以基于自然语言输入至少输出一些 SQL 查询。 但它们可以在现实环境中处理大型多表数据库吗? 换句话说,他们能胜任数据分析师的工作吗? Deepset 的一个小团队着手回答这个问题。 在三个月的时间里,我们试图找到在真实数据集上生成 SQL 查询的最佳方法。
简而言之,他们的发现是:商业智能 (BI) 很困难,评估 BI 用例也很困难。 当前声称高精度的方法可能并不能说明全部情况,而 GPT-4 是可用于生成 SQL 查询的最佳模型之一。 如果您想更多地了解我们的发现 - 并找出我们评估的哪种方法效果最好 - 那么这篇文章适合您。
高标准的数据质量可以大大简化模糊性问题:恰当命名的列、详尽的模式描述和逻辑组织的表都有助于使表格数据库更易于人类和机器管理。
The project
我们项目的目标是找到将自然语言文本转换为有效 SQL 查询的最佳解决方案,从而为用户生成正确的结果。 生成的查询与结果一起返回,以便具有一定 SQL 知识的用户可以验证它是否正确。
现有方法
当我们开始时,我们似乎有多种方法可供选择。 在过去的几个月里,许多团队尝试使用LLM的自然语言理解(NLU)功能来生成SQL查询。
但当我们更仔细地观察他们的结果时,我们发现它们存在不足:通常,性能最佳的模型只能解决手头的一个非常具体的问题,而无法推广到其他 BI 用例。 这也意味着模型在基准测试中的表现非常不同。 我们决定创建自己的数据集和基准,因为我们想要最能反映常见的真实用例的数据点,并确保评估集包含LLM以前从未见过的数据。
数据集
对 StackOverflow 的 SQL 查询进行了逆向工程,最终得到了大约 120 个查询-答案对。
为了使数据库更像真实的生产环境,我们规范了数据库模式。 例如,我们将列同时允许多个值的表拆分为单独的相关表。 每个数据点由自然语言查询和相应的标签(查询的 SQL 等效项)组成。
评估Text 2 SQL的难题
在深入研究现有方法时,我们还发现,即使它们报告了高精度结果,它们也往往基于有问题的评估方法。 由于自然语言的模糊性,文本到 SQL 的评估仍然是一个未解决的问题,没有标准化的方法。 我们认为,它总是至少需要一个手动组件。 这是一个令人不安的事实,但研究团队经常掩盖这一事实——也许是因为他们不想谈论这样一个事实:他们只使用了一个很小的评估数据集来弥补手动评估结果的耗时做法。
在尝试了多种方法之后,我们决定采用半自动评估程序。 我们的评估脚本对 LLM 的输出进行了预处理,将每个结果分类为正确(如果它与我们的评估数据集中的基本事实完全匹配)、不正确(如果结果为“无”)或需要手动评估。 然后,我们手动处理最后一组结果,以验证结果确实不正确,或者模型只是选择了仍产生相同结果的不同 SQL 查询。
方法总结
我们尝试了多种不同的方法,使我们能够利用法学硕士探索全方位的 NLP 流程:代理、检索增强、微调等等。 在这里,我们总结了我们的结果。 在本节的最后,我们概述了所有方法及其性能。
模式感知提示词(Schema-aware prompting)
方法:在我们的基线方法中,我们在 LLM 的提示词中包含了数据库的Schema。 该Schema描述了数据库的布局:表名称和描述以及列名称。 这种方法为LLM提供了很多背景信息。
我们还尝试在提示词中包含数据库中的行,以帮助模型更好地解析不明确的列名,并为其提供更多有关给定单元格的期望信息。 例如,在下面的示例中,我们可以看到 HTML/CSS 在语言表中被计为一种语言。 这样,模型就知道两者始终结合在一起,并可以相应地调整其对数据库的查询。
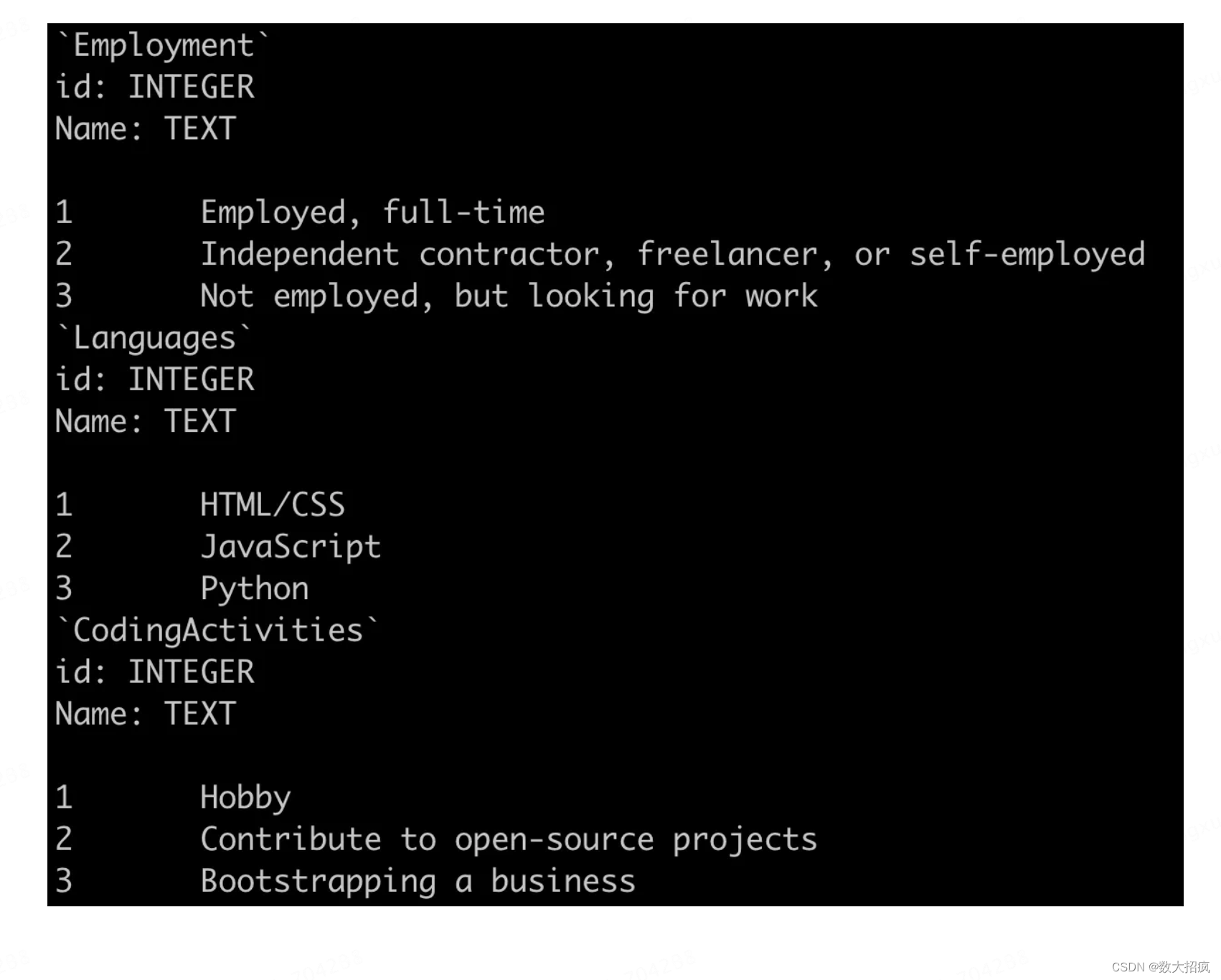
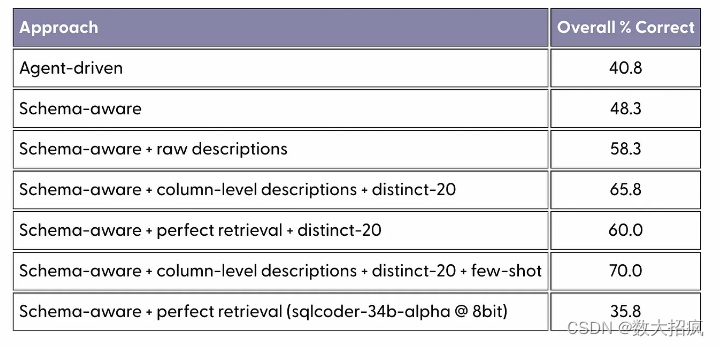
观察:模式感知提示会产生很长的提示。 我们的数据库中有 66 个表,包含每个表的详细信息会产生包含大约 3000 个标记的提示。 这不仅成本高昂,还意味着模型必须立即处理更多信息,这可能对其输出产生负面影响。 模式感知提示和 GPT-4 的简单组合使我们达到了约 48% 的准确率。 模型错误的范围从与实际Schema不匹配的无效 SQL 查询到 SQL 查询返回的结果不是问题的正确答案的更微妙的错误。 在提示中包含示例行肯定会提高性能。
Agent-driven navigation of the database
方法:代理是可以在给定一组工具的情况下自主行动的LLM。 例如,它可以在将另一个 LLM 的输出返回给用户之前对其进行迭代。 在我们的方法中,我们指示模型使用日益复杂的 SQL 查询来浏览数据库。 这意味着我们不必自己提供数据库模式,而是可以让模型在需要知道的基础上找出它。 事实上,我们要求代理通过检索数据库中所有表的信息来开始探索。 从那时起,它必须自己找出战略的其余部分。
观察结果:代理方法使我们能够让LLM修复无效的查询。 好处之一是查询始终是最终有效的 SQL。 以下是代理驱动方法的实际应用示例(屏幕截图后有各个步骤的细分):
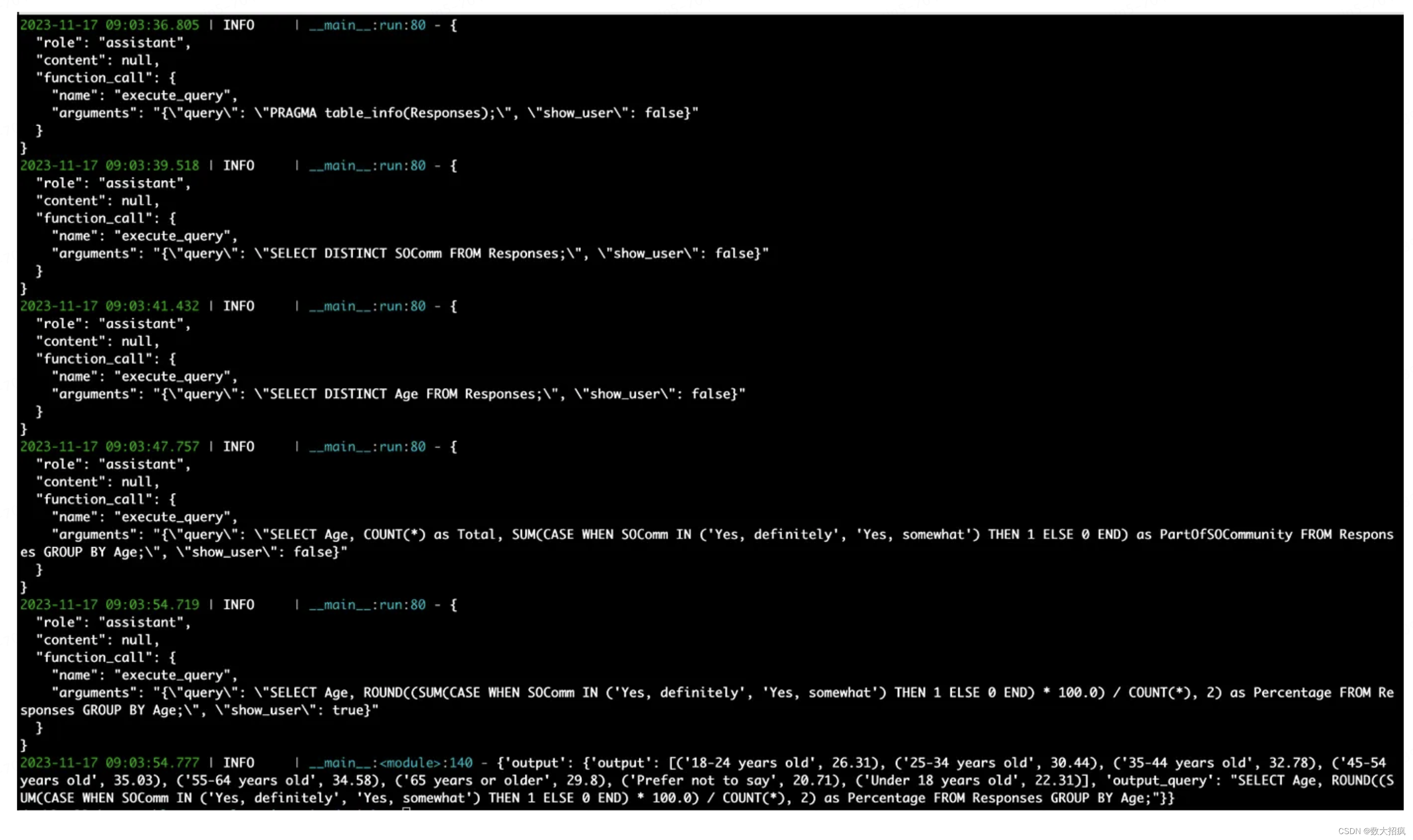
# Question: How many respondents consider themselves to be “definitely” or “somewhat” a part of the Stack Overflow community by age in %?{“query”: “PRAGMA table_info(Responses);”, “show_user”: false}# First up the agent gets the info for the Responses table.{“query”: “SELECT DISTINCT SOComm FROM Responses;”, “show_user”: false}# It figures out that it needs to look at the SOComm column, specifically the distinct values.{“query”: “SELECT DISTINCT Age FROM Responses;”, “show_user”: false}# It also checks the Age column.{“query”: “SELECT Age, COUNT(*) as Total, SUM(CASE WHEN SOComm IN (‘Yes, definitely’, ‘Yes, somewhat’) THEN 1 ELSE 0 END) as PartOfSOCommunity FROM Responses GROUP BY Age;”, “show_user”: false}# Performs the necessary operation but still has show_user: false.{“query”: “SELECT Age, ROUND((SUM(CASE WHEN SOComm IN (‘Yes, definitely’, ‘Yes, somewhat’) THEN 1 ELSE 0 END) * 100.0) / COUNT(*), 2) as Percentage FROM Responses GROUP BY Age;”, “show_user”: true}# Rounds out the percentage answer and sets show_user: true to end the generation.
虽然这种方法允许我们最初输入较短的提示,但代理的迭代方法意味着历史数据会随着代理采取的每个新步骤一起传递:提示会增长。 因此,我们面临着同样的问题,即大量提示很难让模型管理,并导致 API 调用越来越昂贵。 代理方法的黑盒性质还存在一个问题,有时会导致比模式感知提示更难理解的错误。
Include raw schema descriptions
方法:在这种方法中,我们不仅提供了数据库生成的模式,还提供了 StackOverflow 对列含义的描述。 我们在提示中将这些原始描述放在任何表模式描述之前。 这些手写的描述包含有价值的信息。 因此,他们应该澄清数据库模式中的任何歧义。 例如,在下面的屏幕截图中,我们看到“YearsCode”列被定义为“包括任何教育”的编程经验年数。
观察结果:添加每列的描述会使提示变得更长(约 7k 个标记)。 准确率提高了 10 个百分点,达到 58%。
Including column-level descriptions and distinct values
方法:在这种方法中,我们试图通过将每列的描述作为架构的一部分来丰富 LLM 可用的列级信息。 我们还添加了列中最多可以包含 20 个不同的值以及描述。 这导致了约 6500 个令牌的查询。
观察结果:这进一步改善了结果,使准确率达到 65%。
Including few-shot examples and custom instructions
方法:在分析了模型遇到的一些问题后,我们尝试修改提示并添加少量示例来减轻错误。 法学硕士犯的一个常见错误是,如果人员出现在多行中,则重复计数。 相反,我们希望通过提示它向“COUNT()”函数添加一个“DISTINCT”子句,以消除相同数据的重复出现。
可以说,这超出了数据库或域的快速工程范围,并且接近于过度拟合评估集。 尽管如此,它证明了法学硕士对这些变化的响应能力。
观察结果:模型对说明和示例做出了反应,并且基本上不再犯观察到的错误。 这使得准确率达到了 70%。
Retrieval augmentation
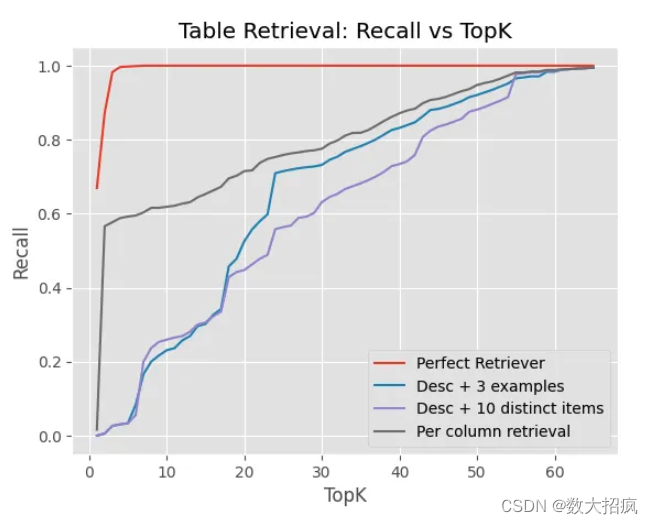
方法:模型不需要知道数据库中的所有表来回答问题。 例如,评估集中的大多数问题可以使用 66 个表格中的 5 个或更少的表格来回答。 检索模块可以检索正确的表,这将缩短提示并帮助模型仅关注相关信息。 然而,值得注意的是,没有针对将自然语言查询与表模式匹配的特定任务进行调整的检索器可用。 我们使用了 deepset/all-mpnet-base-v2,我们已经看到它在之前的表检索任务中表现良好。
观察结果:检索组件工作得不太好。 嵌入模型根本无法为每个查询选择相关表。 下图绘制了 x 轴上检索到的表格数量与 y 轴上的召回率(即正确检索到的表格的百分比)的关系。 它表明,即使增加“top_k”值,检索组件也无法识别所有相关表。 当然,这会导致 LLM 一开始就看不到生成 SQL 查询的正确上下文。
列级检索(Column-level retrieval 即,单独嵌入列并在列具有较高值时返回整个表)比表级检索性能更好。 这可能是因为将查询与各个列相匹配更容易,因为包含许多与查询无关的列的表可能会淹没单个列的信号。 其中几乎总是检索到具有大量列的特定表(“Responses”)。
我们还尝试了完美检索(Perfect Retrieval 仅传递相关表的模式)来确定基于检索的方法的上限。 令我们惊讶的是,由于LLM犯的错误数量增加,它的表现比仅仅通过所有表格还要差(60% 比 65.8%)。
RAG 方法性能不佳的部分原因是数据集不平衡,其中表之间的列数差异很大。 我们可以尝试改进它(例如,通过切换到更好的检索模型或重新制定设置),但考虑到即使完美检索在此数据集上的性能也不佳,这种探索最好在不同的数据集/设置上完成。
其他模型
方法:除了GPT-4之外,我们还尝试了很多开放权重模型:Starcoderbase、New Hope、Codegen 2.5、sqlcoder模型等。
观察结果:其中,最近发布的 sqlcoder-34b-alpha(以 8 位加载)给出了最有希望的结果(35.8%),但低于 GPT-4。 我们遇到的主要问题是它经常会产生不存在的列的幻觉,例如 work_exp、response_op_sys_professional_use。
微调现有的 OSS 模型
方法:我们可以使用较小的开源 LLM 并在合适的数据集上对其进行微调。 为此,我们使用资源高效的 QLoRA 方法和 Spider 数据集的子集在 EC2 实例上微调了多个模型。 这些模型包括 Llama 2 70B,特别是当时可用的所有特定于代码的模型(例如 Starcoderbase、New Hope、Codegen 2.5)。
观察结果:不幸的是,我们所有的 OSS 方法都失败了,很可能是因为我们用于微调的数据集无法胜任任务。 Spider 数据集是面向学术的,并没有真正捕获我们感兴趣的现实世界业务用例(并且我们的评估数据集反映得相当准确)。 性能得分相应较低,约为 10%。
An improved schema + evaluation results
从我们对模型预测和错误模式的定性分析中,我们注意到许多表或列名称很难映射回原始问题。 当除了模式之外还提供了列的描述时,LLM的更好表现似乎证实了这一点。
因此,最初的任务类似于在没有任何文档或帮助的情况下为新业务分析师提供一个包含数十个表和神秘模式的错综复杂的数据库,然后期望他们为我们的问题提供正确的答案。 我们觉得我们没有给模型一个公平的机会来完成这项工作。
良好的数据卫生对于 BI 至关重要,因此我们决定坐下来更改架构,以更易于理解的方式构建表,并将列命名更改为不言自明。 例如,我们将列从“LearnCode”重命名为“LearningToCodeMethods”,这大大减少了初始列名称的歧义。
我们在本文中报告的所有评估结果都基于新模式,该模式全面显着提高了各种方法的性能。
挑战和收获
在 SQL 中创建通用的、LLM 驱动的商业智能解决方案仍然是一个很大程度上尚未解决的问题,这使得进一步探索变得更加有趣。 主要挑战与以下两个因素有关:
数据集创建和评估非常耗时
创建用于评估文本到 SQL 方法的数据集比提取问答要困难得多。 本质上,您必须为每个数据点编写一段代码(SQL 查询)。 该查询需要经过测试和调试才能进入数据集。
这不仅仅是数据集的创建,评估本身也很耗时,因为正如我们之前所描述的,它无法完全自动化。 正如我们现在所做的那样,文本到 SQL 的评估并不完全可扩展。 想要准确评估其方法的项目需要考虑
自然语言和数据库的歧义
正如我们所见,自然语言查询可能非常模糊,这使得它们很难转换为 SQL 查询。 另一方面,从数据库中提取一条信息的正确方法通常有不止一种,而我们的评估数据集可能不会考虑所有这些方法。 这让我们回到这样一个事实:每次运行后我们至少需要手动评估模型的部分结果。
这里起作用的另一个因素是数据库本身可能是不明确的——如果模式设计得不是特别好的话,情况更是如此。 这就是为什么让熟悉数据库的人参与其中会很有帮助——它将帮助您更好地评估生成的查询。 您甚至可以使用模型的输出作为对命名实践的一种检查 - 例如,如果模型不断滥用某个列,则可能表明是时候重命名它或更新其描述了。







项目一)
)

----二叉树--二叉树的层平均值)








