前言
今日头条文章收益是没有任何门槛,只要是你发布文章,每篇文章的阅读量超过1000就能有收益,阅读量越多收益越高。于是乎我就有了个大胆的想法。何不利用Python爬虫,爬取热门文章,然后完成自动化发布文章呢?这不就完成了我多年以来躺着赚钱的愿望了嘛。说干就干,于是乎就有了下面的操作。我的思路是这样的,因为娱乐版块的文章更容易上热门,于是我就以娱乐版块为突破口。

1. 获取今日头条文章列表接口
找到了获取文章列表的接口,今日头条的接口做了反爬虫处理,每次请求接口时都需要带上一组加密字符,否则接口报错,于是我通过百度,发现今日头条的加密字符串生成来自于acrawler.js文件,我将js文件下载到本地按照网友的方法发现代码跑起来了加密字符串生成了,然后我加成功拼接url成功获取到了文章列表。


将acrawler.js下载到本地,引入到自己的html文件中,并执行代码
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><meta http-equiv="X-UA-Compatible" content="IE=edge"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>getSig</title><script src="./acrawler.js"></script>
</head>
<body><p id="sigUrl"></p>
</body>
<script>var channel = "3189398972" // 娱乐// var channel = "3189398999" // 科技function getSSSS(){var time = new Date();var str = "https://www.toutiao.com/api/pc/list/feed?channel_id="+channel+"&max_behot_time="+time.getTime()+"&offset=0&category=pc_profile_channel&client_extra_params=%7B%22short_video_item%22:%22filter%22%7D&aid=24&app_name=toutiao_web"var sig = window.byted_acrawler.sign({url:str})var url = str+"&_signature="+sig;document.getElementById("sigUrl").innerText = urlconsole.log(url);}getSSSS();setInterval(function(){getSSSS();},30000)</script>
</html>html文件运行结果:

2. 使用selenium获取js脚本生成的url
Selenium是一个用于Web应用程序自动化测试工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作浏览器一样。
因为js运行依靠window浏览器对象,所以Python无法直接运行js代码获取加密之后的url,这里我使用selenium运行浏览器,打开生成url的html文件,获取加密处理后的url
pip安装selenium
pip install selenium主要代码:
# 浏览器自动化工具
from selenium import webdriver
from selenium.webdriver.common.by import By# 创建一个浏览器实例
browser = webdriver.Firefox()# 获取请求地址
browser.get("file:///E:/studyproject/python/toutiao/getSig.html")# 自动化获取js代码计算的sig数据值
sigTag = browser.find_element(By.ID,"sigUrl")
url = sigTag.text
通过上面代码获取到请求的url了
3. 使用requests根据列表url获取文章列表数据
Requests是Python的一个第三方库,用于发送HTTP请求。Requests库可用于爬取数据、与API交互、测试Web服务等。Requests库的作用主要是向Web服务器发送请求,并获取响应结果。发送的请求可以是GET、POST、PUT、DELETE、HEAD、OPTIONS等HTTP方法,同时还可以设置请求参数、请求头、请求体、代理、超时时间等。获取的响应结果包含HTTP状态码、HTTP响应头、HTTP响应内容等信息,同时支持自动解析JSON格式的响应内容。
使用pip安装requests,请求刚才获取的url列表地址,设置请求头的cookie,否则每次请求连接返回的数据都是相同的
pip安装requests工具包
pip install requests主要代码:
# 网络请求工具
import requestsheaders = {# 设置User-Agent,模拟浏览器发送请求'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36',# 设置Cookie,用于身份验证或其他需要的信息'Cookie': '__ac_signature=_02B4Z6wo00f01Lz3yHgAAIDB3.0IExdN.9i818zAAEpR33;tt_webid=7309719685489198604;ttcid=fb73866ceb7a44cdb848344abfc11b6364;s_v_web_id=verify_lpur8vrr_aKDsfWBn_AThk_4UlU_8RpK_Ci9lGCzIBKbb; _ga=GA1.1.1051493470.1701926754; local_city_cache=%E4%B8%B4%E6%B2%82; csrftoken=4561fa578aa7c7bc7d3ac8f87ac7fad1; __feed_out_channel_key=entertainment; passport_csrf_token=a296ea89de4f632e00534cd16812d593; passport_csrf_token_default=a296ea89de4f632e00534cd16812d593; msToken=Lhx7DAYTtQJiiCVIVmYNqtpQkUVKq8RzEzhUZAslgKw_w5gJ_vSlmCJKsQoQUyXXoJzHhluRQFpfceUoT2n2IoACypVJ-aD7RCuXC7iI; tt_scid=0lfkb7lPohYDsWmjDuFAe7L3oLDo0KsbKzlhKzl1CQ2im2TQypCzPCKr.jkBHxexd641; ttwid=1%7CVPO9aK7JwsvyYUFWA3MR5i_pw1b4nic0TD5-jp-zjVc%7C1702450449%7C067c9bd8be4c0a21dc4e60bc225ee29072184eeb24503d5d6cc26b9554d20d26; _ga_QEHZPBE5HH=GS1.1.1702455638.13.0.1702455638.0.0.0.0.0'}# 请求接口获取json数据
res = requests.get(url,headers=headers)上述代码中User-Agent和Cookit直接在浏览器请求接口中获取就行。
4. 使用json工具包,解析文章列数据
python可以通过json库,解析字符串或文件中的内容转为json字符串或python的字典或列表
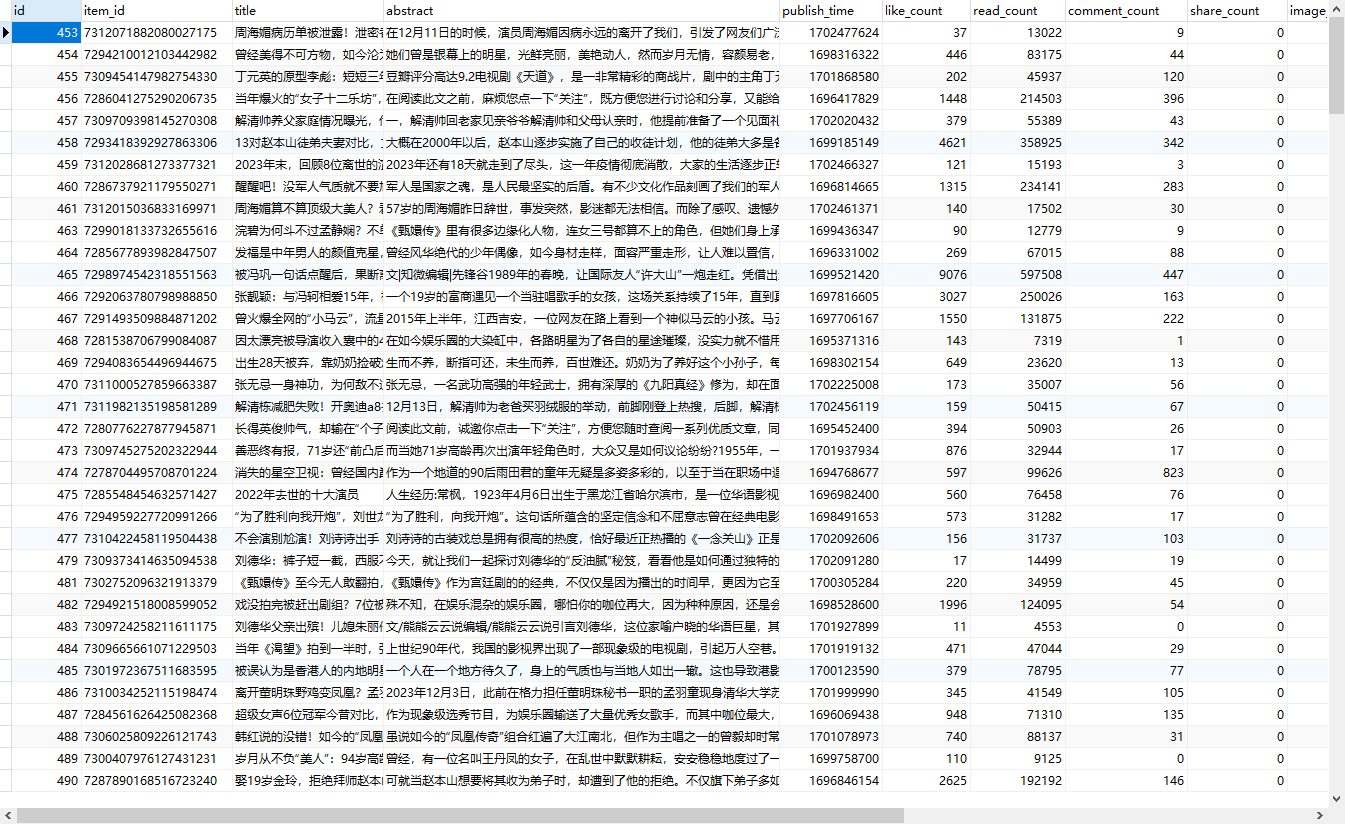
获取返回的json数据,解析json数据,保留阅读量、点赞量等较高的文章信息。
# JSON解析工具
import json# 请求接口获取json数据
res = requests.get(url,headers=headers)
json_obj = json.loads(res.text)# 通过遍历每条数据,过滤热门文章
for item in json_obj['data']:# 计算文章分享数量shareCount = item['share_info']['share_type']['pyq']+item['share_info']['share_type']['qq']+item['share_info']['share_type']['qzone']+item['share_info']['share_type']['wx']# 判断文章路径是否是站内文章路径if re.match(matchTemplate,item['article_url']):# 多条件判断是否是较新的热门文章if item['read_count'] >= 3000:5. 使用pymysql工具包,将爬取的数据保存到MySQL数据库
pymysql是从Python连接到MySQL数据库服务器的接口, 简单理解就是,Pymysql是python操作mysql数据库的三方模块。就是可以理解为可以在python中连接数据库写MySQL命令,实现的 MySQL 客户端操作库,支持事务、存储过程、批量执行等。
pip安装pymysql
pip install pymysql主要代码:
# 数据库链接工具
import pymysql#链接MySQL
mysqlCon = pymysql.connect(host="127.0.0.1",port=3306,user="root",password="123456",database="toutiao"
)# 通过遍历每条数据,过滤热门文章for item in json_obj['data']:# 计算文章分享数量shareCount = item['share_info']['share_type']['pyq']+item['share_info']['share_type']['qq']+item['share_info']['share_type']['qzone']+item['share_info']['share_type']['wx']imageList = ""# 判断文章路径是否是站内文章路径if re.match(matchTemplate,item['article_url']):# 多条件判断是否是较新的热门文章if item['read_count'] >= 3000:# 创建游标对象cursor = mysqlCon.cursor()# 执行 SQL 查询语句cursor.execute("select * from happy where item_id ="+item['item_id'])# 获取查询结果result = cursor.fetchall()# 判断是否已经插入if len(result) == 0:# 将热门文章保存到数据库sql = "insert into happy (id,item_id,title,abstract,publish_time,like_count,read_count,comment_count,share_count,image_list,article_url,gather_time,transport_time,source) values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)"values = (None,item['item_id'],item['title'],item['Abstract'],item['publish_time'],item['like_count'],item['read_count'],item['comment_count'],shareCount,imageList,item['article_url'],time(),0,"toutiao")cursor.execute(sql,values)mysqlCon.commit()else:print("已经存在")
6. 根据数据库爬取的热门文章列表,爬取文章文本和图片信息
今日头条对做了反爬虫处理,直接使用requests请求网页无法获取文章内容,所以只能使用selenium来模拟浏览器浏览网页内容通过上面获取的热门文章id,拼接 url地址从而获取文章内容
主要代码:
# 浏览器自动化工具
from selenium import webdriver
from selenium.webdriver.common.by import By# MySQL数据库链接工具
import pymysql
# 文件操作类
import os
# 时间类
from time import sleepfrom docx import Document
import pypandoc#链接MySQL
mysqlCon = pymysql.connect(host="127.0.0.1",port=3306,user="root",password="123456",database="toutiao"
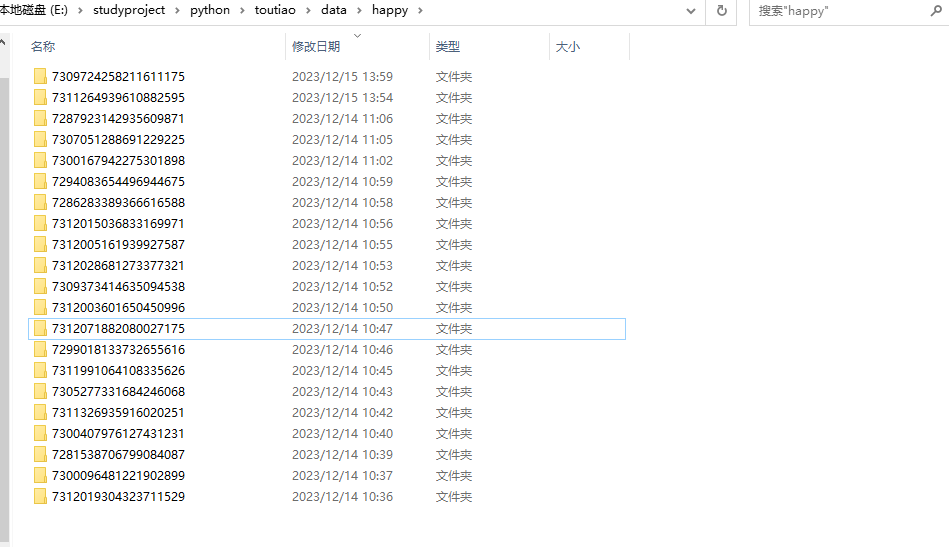
)while True:cursor = mysqlCon.cursor()# 执行 SQL 查询语句cursor.execute("select id,item_id,article_url,title from happy where state = 0 order by read_count asc limit 0,1")# 获取查询结果result = cursor.fetchall()sql = "update happy set state = 1 where id = %s"id = result[0][0]cursor.execute(sql,id)mysqlCon.commit()articleId = result[0][1]articleTitle = result[0][3]# articleId = "7279996073686123068"# 通过查询列表获取未发布的热门文章信息,根据获取的文章URL 打开URL链接地址# articleId = "7291869777788666407"# 创建一个浏览器实例browser = webdriver.Firefox()# # 获取请求地址browser.get("https://toutiao.com/group/"+articleId)sleep(30)# 根据元素名称获取元素内容textContainer = browser.find_element(By.CLASS_NAME,"syl-article-base")articleHtml = textContainer.get_attribute("innerHTML")# 根据解析的HTML内容,获取文章文本信息和图片信息,并将文本信息和图片保存到Word文档中# file = open("E:\\studyproject\\python\\toutiao\data\\"+articleId+"\\"+articleId+".html", "r",encoding='utf-8')os.mkdir("E:\\studyproject\\python\\toutiao\data\\happy\\"+articleId)output = pypandoc.convert_text(articleHtml, 'docx','html',outputfile="E:\\studyproject\\python\\toutiao\data\\happy\\"+articleId+"\\"+articleTitle+".docx")sleep(30)browser.quit()上述代码实现了,打开浏览器,获取浏览器标签和标签内内容,并将内容保存到word文档中。至此热门文章的爬取就实现了。
之后想用selenium实现自动登录,发布文章,这个时候我直接在头条平台中发布了我爬取的文章,两篇文章阅读量都在几K, 但是好景不长,文章是上午发布的,号是下午封的!!!nainai的,抄袭违规,因此只能暂时中断,下一步的计划是利用ChatGTP改写爬取的文章内容,然后再发布。






)
)

)
)





)


