Publisher: ICCV 2023
MOTIVATION OF READING: 自监督学习、稀疏事件 = NILM
link: https://arxiv.org/pdf/2301.01928.pdf
Code: GitHub - Yan98/Event-Camera-Data-Pre-training
1. Overview

Contributions are summarized as follows:
1. A self-supervised framework for event camera data pre-training. The pre-trained model can be transferred to diverse downstream tasks;
2. A family of event data augmentations, generating meaningful event images;
3. A conditional masking strategy, sampling informative event patches for network training;
4. An embedding projection loss, using paired RGB embeddings to regularize event embeddings to avoid model collapse;
5. A probability distribution alignment loss for aligning embeddings from the paired event and RGB images.
6. We achieve state-of-the-art performance in standard event benchmark datasets.
2. Related work
The SSL frameworks can be generally divided into two categories: contrastive learning and masked modeling.
2.1 Contrastive learning
This approach generally assumes augmentation invariance of images. one notable drawback
of contrastive learning is suffering from model collapse and training instability.
2.2 Masked modeling
Reconstructing masked inputs from the (i. e., unmasked) visible ones is a popular selfsupervised
learning objective motivated by the idea of autoencoding. (Bert, GPT)
3. Methodology

For pre-training, our method takes event data E and its paired natural RGB image I as inputs, and outputs a pre-trained network fe.
Firstly, consecutively perform data augmentations, event image generation, and conditional masking to obtain two patch sets (xq, xk).
Secondly, fe extracts features from event patch set xq, and he_img and he_evt separately project features from fe to latent embeddings q_img and q_evt.
fm and hm_evt are the momentum of fe and he_evt, and are updated by the exponential moving average (EMA). (momentum的含义可以参考MOCO论文)
The momentum network takes patch set xk as input and generates an embedding k_evt.
At the same time, the natural RGB image I is embeded into y = f1(h1(I)).
Finally, we perform event discrimination, and event and natural RGB image discrimination to train our model. 这里不用INFONCE直接对q_evt和k_evt进行相似度计算是因为这么做会导致embedding collapse使得embedding过于相似。原因是事件图像是稀疏离散。因此使用RGB图像的映射。
L_evt is an event embedding projection loss aiming to pull together paired event embeddings qevt and kevt, for event discrimination.
L_RGB aims to pull together paired event and RGB embeddings q_evt and y, for event and natural RGB image discrimination.
L_k1 aims to drive fe learning discriminative event embeddings, towards well-structured embedding space of natural RGB images.
InfoNCE loss Contrastive learning aims to pull together embeddings q and k+, and pushes away embeddings q and {k−}.
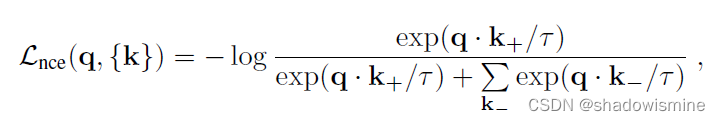
Event embedding projection loss

ζ(v1, v2) is the projection function.
Event and RGB image discrimination
Considering the sparsity of the event image, a single event image is less informative than an RGB image, possessing difficulty for self-supervised event network training.
We pull together embeddings of paired event and RGB images, xq and I.
![]()
we first compute the pairwise embedding similarity and then fit an exponential kernel to the similarities to compute probability scores. The probability score of the (i, j)-th pair is given by,
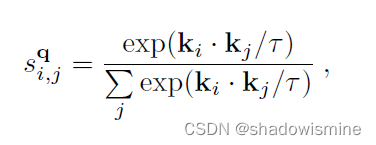
Our probability distribution alignment loss is given by,

Total Loss
![]()
where λ1 is a hyper-parameter for balancing the losses.
4. Experiment
We evaluate our method on three downstream tasks: object recognition, optical flow estimation, and semantic segmentation.




】单行道汽车通行时间(模拟题—JavaPythonC++JS实现))




)
)

、小波变换(WT)、同步压缩变换(SST)、瞬态提取变换(TET)进行时频分析)






