打造新一代云原生"消息、事件、流"统一消息引擎的融合处理平台
- 云原生架构
- RocketMQ的云原生架构实现
- RocketMQ的云原生发展历程
- 互联网时期的诞生
- 无法支持云原生的能力
- 云原生阶段的升级
- 云原生升级方向
- 促进了Mesh以及多语言化发展
- 可分合化的存算分离架构
- 存储分离架构的优势
- 存储分离架构的缺点
- 弹性存储引擎
- LSM(Log-Structured Merge)原理
- 消息和流的统一
- 流式消息VS简单消息
- Serverless化
- 最后预测 — 未来的事件驱动发展
云原生架构
在技术视角下,云原生架构是由一系列针对云原生技术的设计原则和模式构成,其主要目标是在云应用中去除最大限度的非业务代码部分,从而将这些非功能性特性(比如弹性、韧性、安全性、可观察性、灰度等)交由云基础设施来管理。这不仅消除了非功能性业务中断的问题,而且为业务赋予了轻量化、灵活性以及高度自动化的特质。

云原生架构可以理解为是云计算中天生的设计模式,它的“生命力”源自云计算技术,没有云计算,谈论云原生架构就如同空谈理论。
RocketMQ的云原生架构实现
在过去的数年中,RocketMQ基于大规模云计算环境的实践经验(例如,阿里(双十一、双十二)、携程(过年高峰期)),辅助了成千上万的企业完成数字化转型,从而实现了从互联网消息中间件到云原生消息中间件的发展变革。RocketMQ与其他消息中间件的一大区别就在于,它采用的是经过实践检验的云原生架构。接下来,我们要探讨RocketMQ在云原生架构领域的关键技术进步。
RocketMQ的云原生发展历程
随着消息队列行业的发展,Apache RocketMQ经历了12年的发展历程,可以被划分为两个阶段:互联网时期的诞生和云计算时期的成长。
互联网时期的诞生
RocketMQ是2011年诞生于淘宝核心电商系统,一开始是定位于服务集团业务,面向单一超大规模互联网企业设计,当时的架构存在一些痛点,无法很好地满足云计算场景的需求。其中包括以下问题:
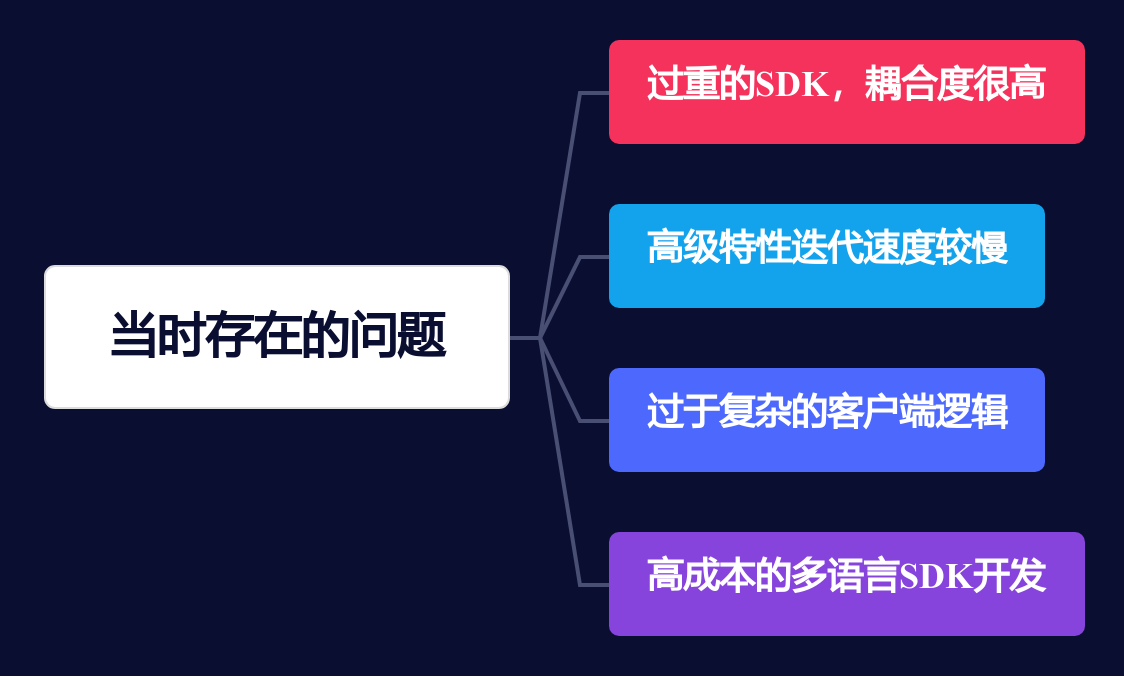
无法支持云原生的能力
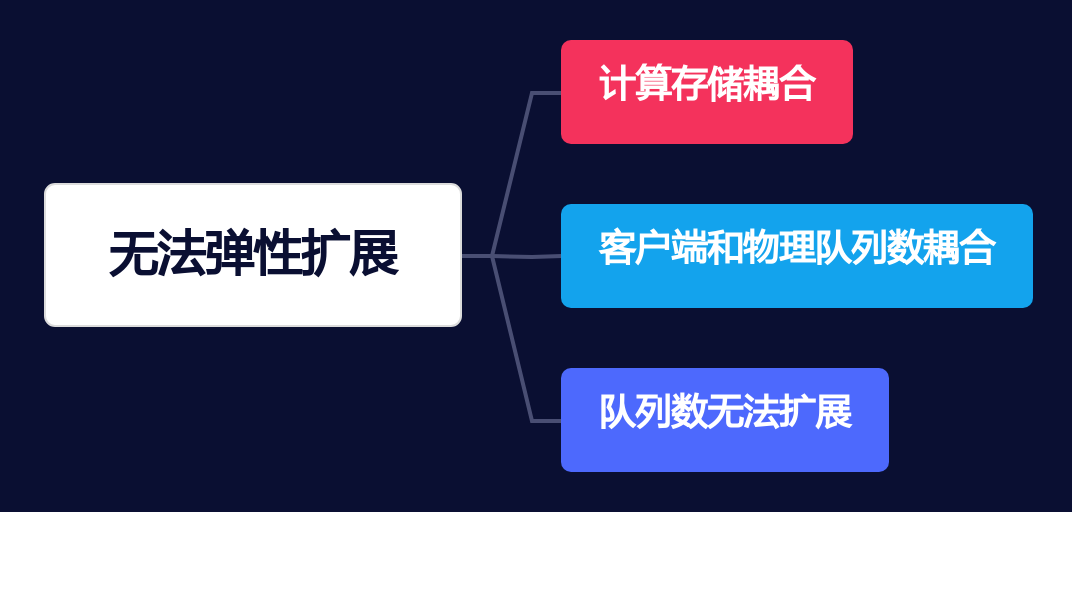
在弹性能力方面,目前存在一些问题,当然其他主流的开源消息项目也没有进行云原生架构转型,比如RabbitMQ无法水平扩展单队列能力、Kafka扩容需要大量数据拷贝和均衡。这些现有解决方案都不适用于为大规模客户提供弹性服务的公共云环境。
经过不断的努力和发展,在2016年,Apache RocketMQ开始向云端发展,成为了全球首个推出公有云SaaS版本的开源消息队列服务。同年,RocketMQ被阿里巴巴赠予Apache基金会,于2017年成为首个中国互联网中间件获得TLP(Top-Level Projects,顶级项目)身份。
云原生阶段的升级
在开源发展和云计算的推动下,RocketMQ不仅在阿里巴巴内部实现大规模应用,还助推了各行各业的数字转型。至2022年,随着5.0版本的发布,Apache RocketMQ正式进入了云原生的新阶段。
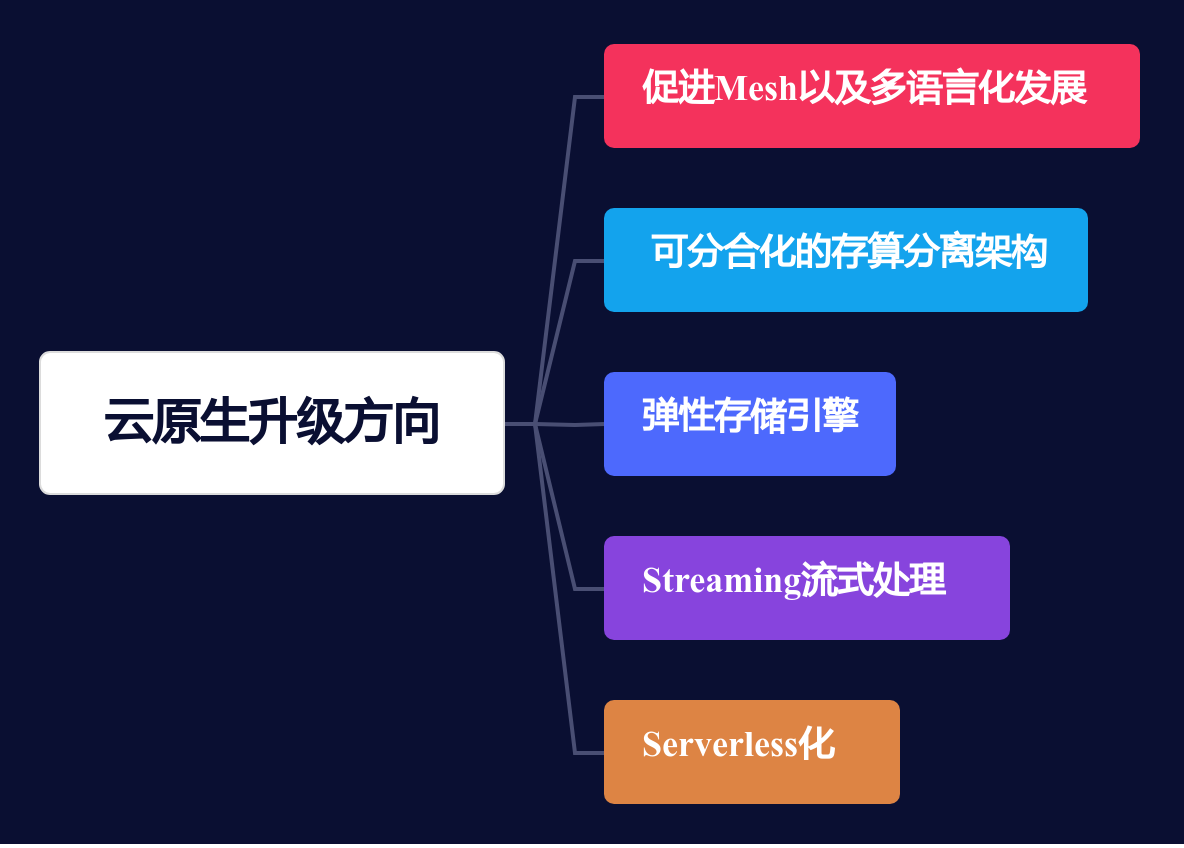
RocketMQ5.0 面向云计算的场景进行重新设计,期望从架构层面解决根本性问题,对客户端、Broker到存储引擎全面升级,如下图所示:
云原生升级方向
下一步,我们将对RocketMQ5.0版本在技术层面的更新进行评估和深度探讨。我们将按照以下几个主题进行讨论和解析。
促进了Mesh以及多语言化发展
在RocketMQ 5.0中,大量的逻辑被下沉到服务端,使得SDK的代码行数减少了60%。这种下沉的设计使得开发和维护多语言SDK的成本大幅度降低。同时,这也使得RocketMQ的SDK变得更加轻量化,更容易被Service Mesh、Dapr等云原生代表技术集成。通过将逻辑下沉到服务端,RocketMQ能够提供更简洁且高效的SDK,为开发人员带来更好的开发和集成体验。
可分合化的存算分离架构
用户根据不同的场景诉求,既可以同一进程启动存储和计算的功能,也可以将两者分开部署。
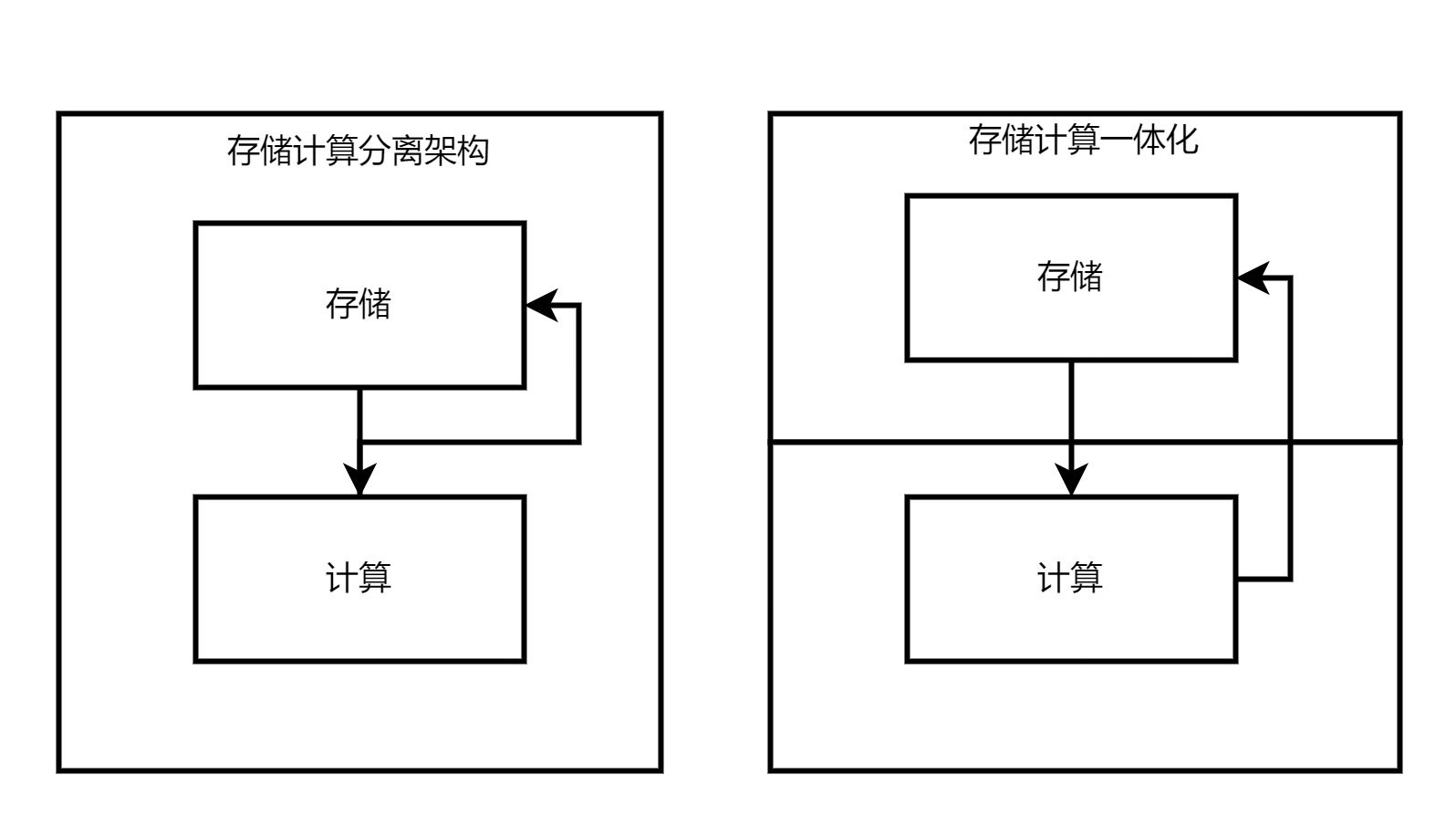
分开部署后的计算节点可以实现"无状态",这意味着一个接入点可以代理所有的流量。通过在云平台上结合新的硬件内核旁路技术,可以减少分离部署所带来的性能和延迟问题。另一方面,选择"存储计算一体化"架构则具备"就近计算"的优势,即计算节点与存储节点在物理上更接近。这种架构能够提供更佳的性能,因为计算可以直接在存储节点上进行,无需跨越网络进行数据传输。综合而言,通过分离部署和存储计算一体化,可以在云平台上获得更高的性能和更低的延迟。
存储分离架构的优势
在云上多租户、多VPC(虚拟私有云)复杂网络、多协议接入的场景中,采用存储计算分离的模式可以避免直接将后端存储服务暴露给客户端。这样做有助于实现对流量的控制、隔离、调度、权限管理以及协议转换等功能。通过将存储和计算分离,可以更好地管理和保护后端存储服务,并提供一种更灵活、高效、安全的数据处理方式。这种模式适用于复杂的云上环境,可确保安全性和可扩展性,并提供更好的管理和控制能力。
存储分离架构的缺点
有利必有弊,存算分离也同时带来了链路变长、延迟增大、机器成本上升等问题,运维也没得到简化,除了要运维有状态存储节点外,还要多运维无状态计算节点。在大数据传输场景下,存算一体能够极大降低机器及流量成本,这个从Kafka的架构演进也可以得到印证。
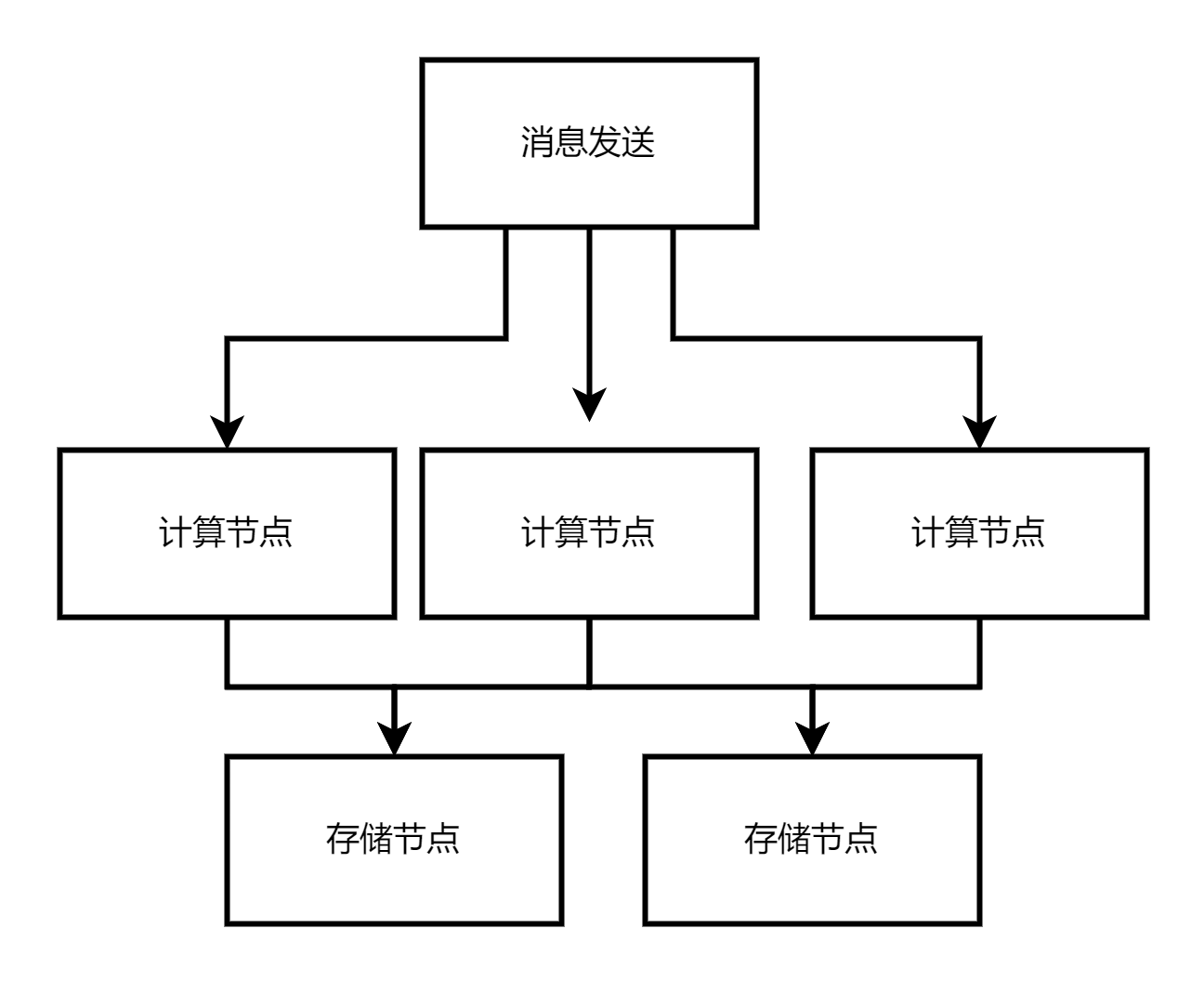
在大多数简单的消息收发场景中,数据链路通常只涉及写入日志和读取日志,没有复杂的计算逻辑(相对于数据库来说,计算逻辑非常简单)。在这种情况下,选择存储计算一体化架构是最佳选择,因为它简单易用、性能高、延迟低,并且足以满足需求。这种架构能够提供高效的数据处理,适用于需要快速、高效的消息收发的场景。

弹性存储引擎
为了适应面向物联网海量设备和云上大规模小客户的场景,RocketMQ引入了LSM(Log-Structured Merge)的KV(Key-Value)索引,实现了单机处理海量队列的能力。队列数量可以无限扩展,以进一步释放云存储的潜力。
LSM(Log-Structured Merge)原理
RocketMQ引入了LSM(Log-Structured Merge)的KV(Key-Value)索引时,它改变了消息队列的存储方式和索引结构。
- 传统的消息队列:通常使用的是基于B+树的索引结构,这种结构在插入和删除操作时存在频繁的磁盘IO,限制了消息队列的吞吐量和性能。
- 升级的消息队列:LSM索引采用了一种更高效的存储方式。它将消息按顺序记录到磁盘上的多个日志文件(Log File)中,称为写日志(Write Log),同时,还维护一个内存中的索引(MemTable),用于加速消息的查找操作。
当内存中的索引(MemTable)达到一定大小时,它会被转化为一个只读的磁盘上的索引文件(SSTable,Sorted String Table)。并且,多个SSTable可以合并成更大的文件,以减少读操作时的磁盘IO次数。这个过程被称为合并(Merge)。
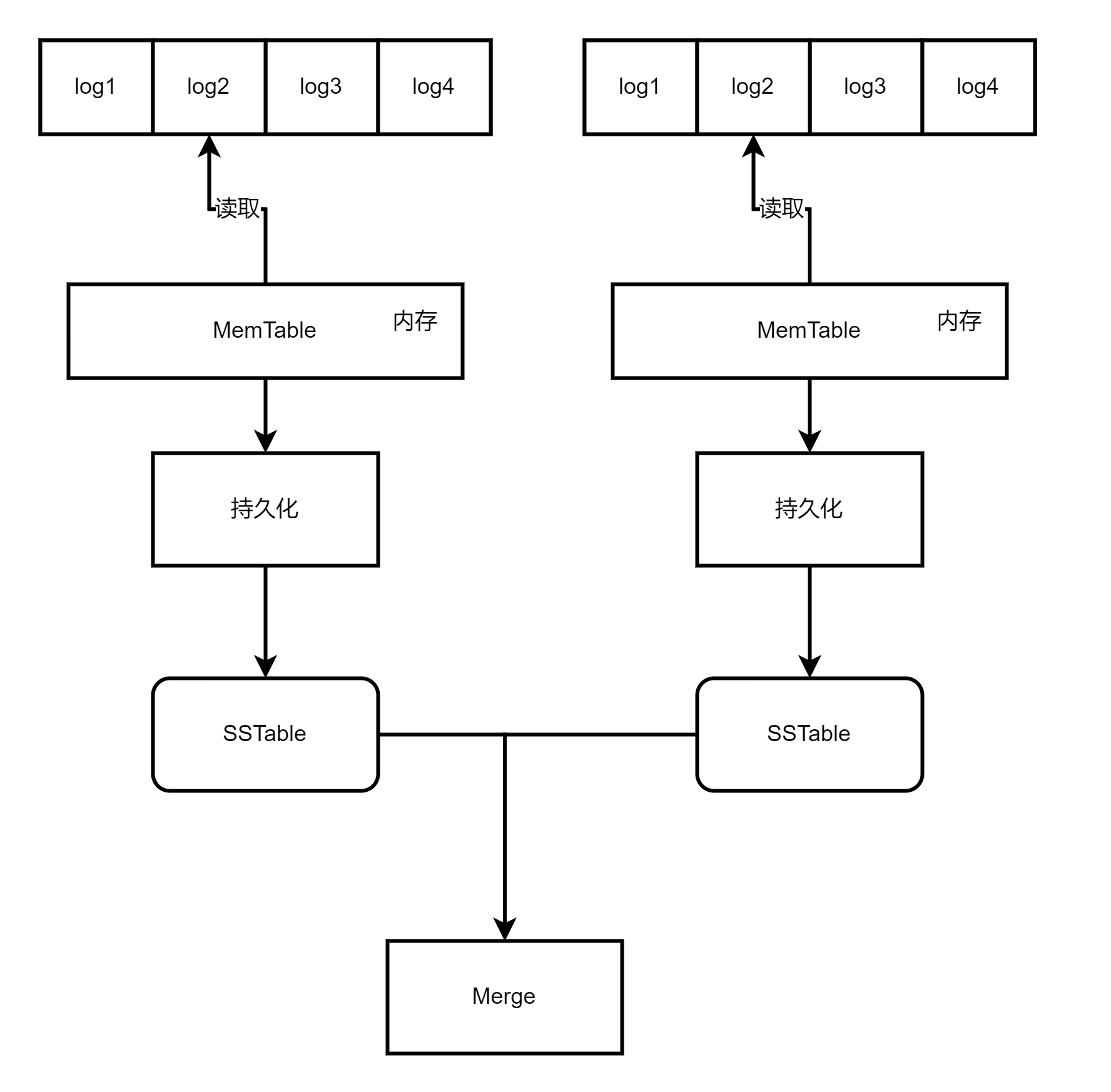
- 文件合并:通过这种LSM索引的设计,RocketMQ实现了快速的写入和顺序读取,并且能够支持海量的队列数量和高吞吐量的消息处理。同时,由于合并操作的特性,也使得RocketMQ具备了优化存储空间和提高读取性能的能力。
- 分级存储,RocketMQ将消息的存储时长从原来的3天提高到月份或年份级别,并且存储空间可以无限扩展。
- 冷热存储,RocketMQ还将冷热数据进行了分离,将冷数据的存储成本降低了80%。这些改进措施使得RocketMQ能够更好地满足大规模部署、高容量存储以及成本效益的需求。
RocketMQ引入LSM的KV索引通过将消息顺序写入磁盘日志,利用内存中的索引及合并操作,实现了高效的写入、读取和存储管理,从而提高了整体性能和可扩展性。
消息和流的统一
Streaming/顺序消息的场景,客户端需要指定Topic下的某个队列(也称分区)进行消息顺序收发,在流场景里面,还有一个很重要的变化,就是数据类型的变化。
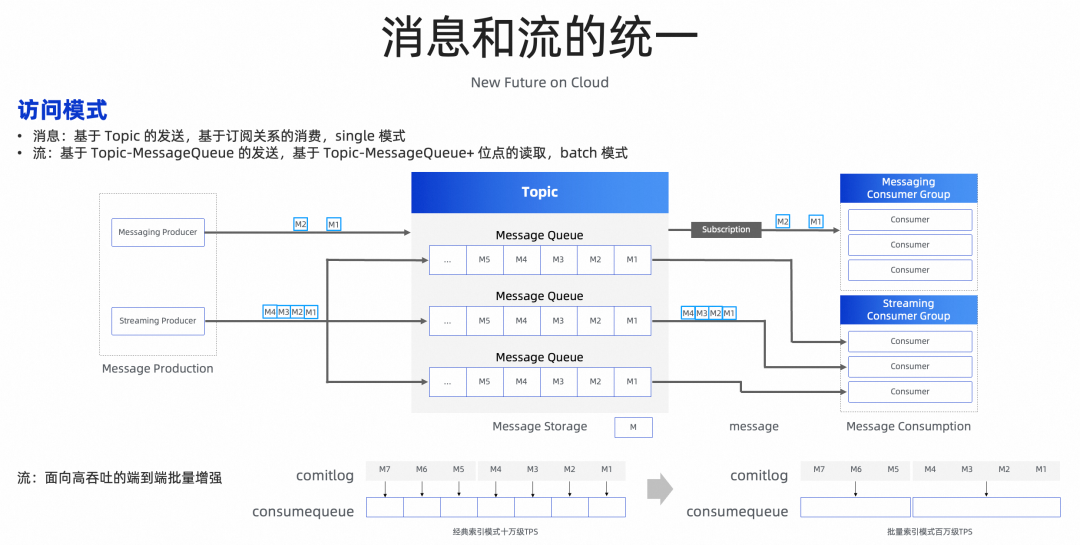
在新架构里,对客户端屏蔽物理队列,引入逻辑队列概念,一个逻辑队列通过横向分片和纵向分段,分散在不同的物理存储节点。
- 横向分片:解决了高可用问题,同一个逻辑队列的多个分片多点随机可写,基于Happen before的原理保序,秒级 Failover,无需主备切换;
- 纵向分片:解决逻辑队列的扩容问题,通过多级队列映射,实现0数据迁移的秒级扩容,逻辑资源和物理资源的弹性伸缩解耦。
流式消息VS简单消息
-
做个简单对比,业务集成场景,消息的数据承载的是业务事件,比如说订单操作、物流操作,它特点就是数据规模较小,但是它每一条数据的价值都特别高,它的访问模式是偏向于在线的,单条事务的短平快访问模式。
-
在流的场景里面呢,它更多的是一些非交易型的数据。比如说用户日志,系统的监控、IoT 的一些传感器数据、网站的点击流等等。他的特点是数据规模有数量级的提升,但单条数据的价值比较低的,然后它的访问模式偏向于离线批量传输。所以在流的场景里面,RocketMQ 存储要面向高吞吐做更多的优化。
Serverless化
面向Serverless 的趋势,RocketMQ5.0从产品形态到技术架构都做了巨大的演进。在原有的架构里面,客户感知物理队列,物理队列绑定固定存储节点,强状态。Broker、客户端、物理队列的扩缩容互相耦合,负载均衡粒度是队列级,对Serverless的技术演进很不友好。
为了实现极致弹性Serverless,RocketMQ 5.0 对逻辑资源和物理资源做进一步的解耦。
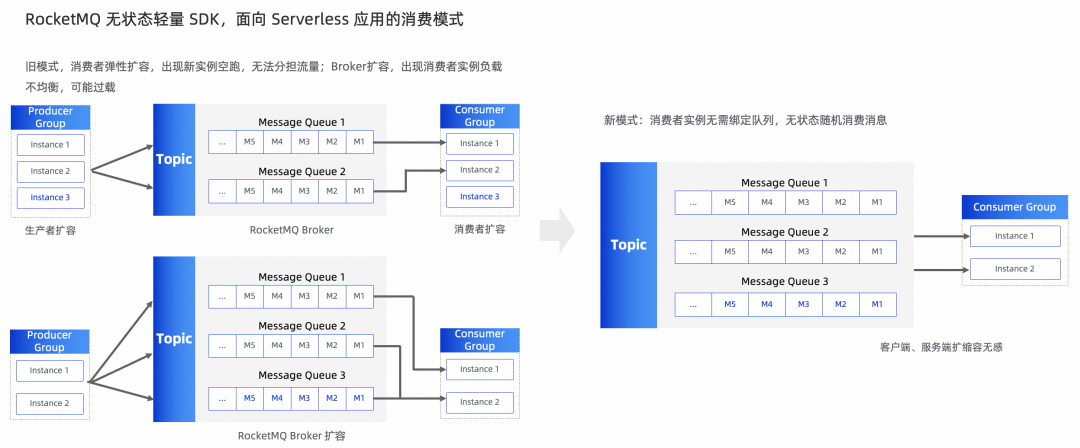
在Messaging/无序消息的场景,客户指定Topic进行消息无序收发,新架构对客户端屏蔽队列概念,只暴露逻辑资源 Topic。负载均衡粒度从队列级到消息级,实现了客户端的无状态化,客户端、服务端弹性伸缩解耦。
让我们看一下生产链路的负载均衡。生产者通过服务发现机制获取了Topic的数据分片和对应Broker的地址。其服务发现机制相对简单,通常采用默认的轮询(RoundRobin)方式将消息发送到各个Topic队列,以实现Broker集群的流量均衡。生产者是完全无状态的,因此无论是弹性伸缩还是其他变化,对其没有太多影响。
最后预测 — 未来的事件驱动发展
将有超过60%的新型数字商业解决方案会使用"事件驱动"模式。为了适应此趋势,Messaing正在演变为Eventing,诸如EventBridge(EventBroker)的产品形态便应运而生。在EventBridge中,“事件”概念成为一等公民,事件的发布者和订阅者无需依赖任何具体的消息队列SDK和实现。





(建议收藏))

:HS 鼠标绘制图形)











