在线体验 ,点击识别语音需要等待一会,文件太大缓存会报错
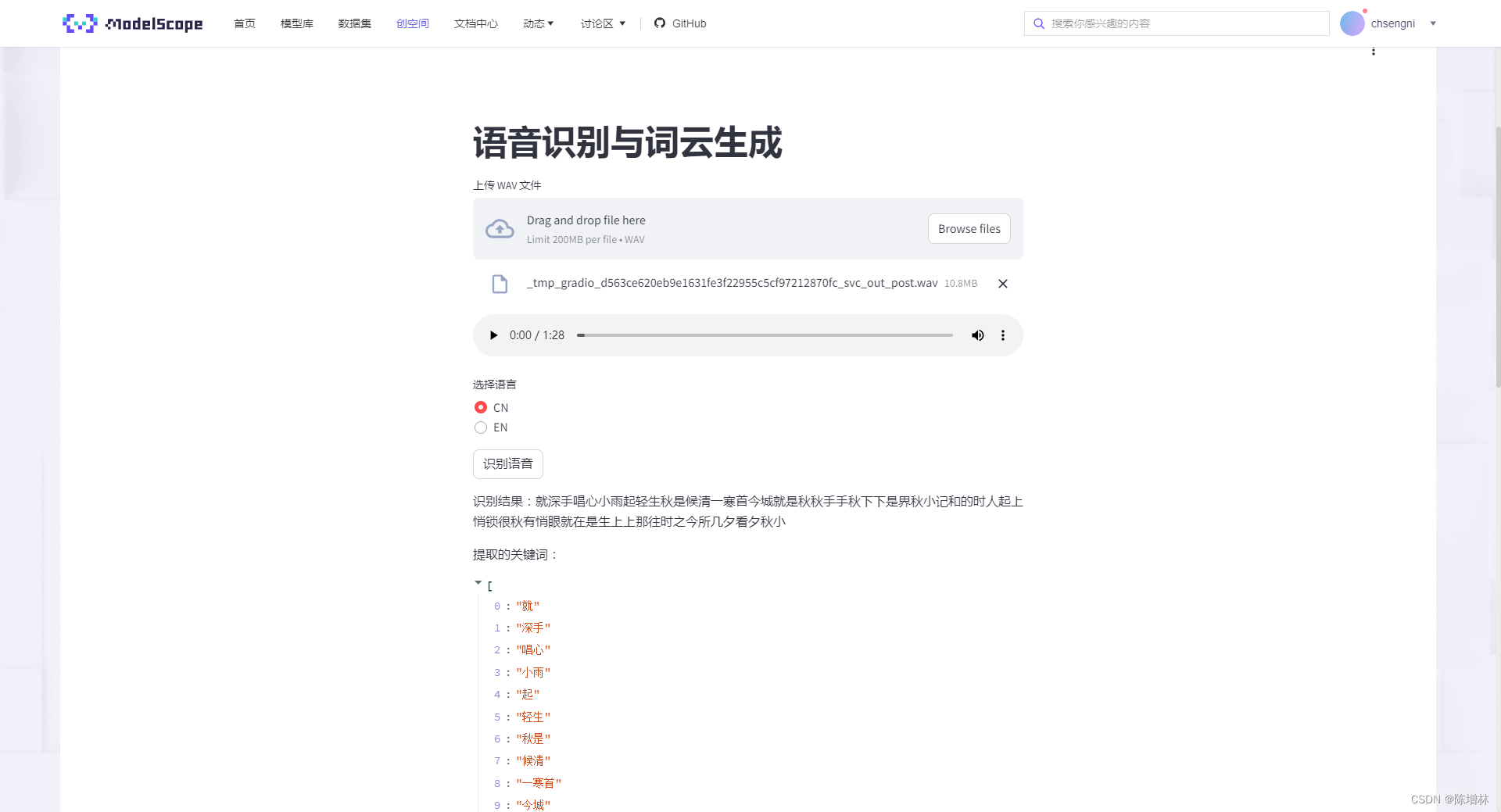
介绍
本篇博客将介绍如何使用 Streamlit、jieba、wenet 和其他 Python 库,结合语音识别(WeNet)和词云生成,构建一个功能丰富的应用程序。我们将深入了解代码示例中的不同部分,并解释其如何实现音频处理、语音识别和文本可视化等功能。
代码概览
首先,让我们来看一下这个应用的主要功能和组成部分:
-
导入必要的库和模型加载
import streamlit as st import jieba from wordcloud import WordCloud import matplotlib.pyplot as plt from pydub import AudioSegment from noisereduce import reduce_noise import wenet import base64 import os在这一部分,我们导入了必要的 Python 库,包括 Streamlit、jieba(用于中文分词)、WordCloud(用于生成词云)、matplotlib(用于图表绘制)、pydub(用于音频处理)等。同时,我们还加载了 wenet 库,该库包含用于中英文语音识别的预训练模型。
-
语音识别的函数定义
def recognition(audio, lang='CN'):# 识别语音内容并返回文本# ...这个函数利用 wenet 库中的预训练模型,根据上传的音频文件进行语音识别。根据用户选择的语言(中文或英文),函数返回识别出的文本。
-
音频处理函数定义
def reduce_noise_and_export(input_file, output_file):# 降噪并导出处理后的音频文件# ...这个函数对上传的音频文件进行降噪处理,并导出处理后的音频文件,以提高语音识别的准确性。
-
关键词提取函数定义
def extract_keywords(result):# 提取识别文本中的关键词# ...此函数使用 jieba 库对识别出的文本进行分词,并返回关键词列表。
-
Base64 编码和下载链接函数定义
def save_base64(uploaded_file):# 将上传文件转换为 Base64 编码# ...def get_base64_link(file_path, link_text):# 生成下载处理后音频的 Base64 链接# ...这两个函数分别用于将上传的音频文件转换为 Base64 编码,并生成可下载处理后音频的链接。
-
主函数
main()def main():# Streamlit 应用的主要部分# ...主函数包含了 Streamlit 应用程序的主要逻辑,包括文件上传、语言选择、按钮触发的操作等。
-
运行主函数
if __name__ == "__main__":main()此部分代码确保主函数在运行时被调用。
应用程序功能
通过上述功能模块的组合,这个应用程序可以完成以下任务:
- 用户上传 WAV 格式的音频文件。
- 选择要进行的语言识别类型(中文或英文)。
- 降噪并处理上传的音频文件,以提高识别准确性。
- 对处理后的音频进行语音识别,返回识别结果。
- 从识别结果中提取关键词,并将其显示为词云图。
- 提供处理后音频的下载链接,方便用户获取处理后的音频文件。
希望这篇博客能够帮助你理解代码示例的每个部分,并激发你探索更多有趣应用的灵感!
streamlit应用程序
import streamlit as st
import jieba
from wordcloud import WordCloud
import matplotlib.pyplot as plt
from pydub import AudioSegment
from noisereduce import reduce_noise
import wenet
import base64
import os
# 载入模型
chs_model = wenet.load_model('chinese')
en_model = wenet.load_model('english')# 执行语音识别的函数
def recognition(audio, lang='CN'):if audio is None:return "输入错误!请上传音频文件!"if lang == 'CN':ans = chs_model.transcribe(audio)elif lang == 'EN':ans = en_model.transcribe(audio)else:return "错误!请选择语言!"if ans is None:return "错误!没有文本输出!请重试!"txt = ans['text']return txt# 降噪并导出处理后的音频的函数
def reduce_noise_and_export(input_file, output_file):try:audio = AudioSegment.from_wav(input_file)audio_array = audio.get_array_of_samples()reduced_noise = reduce_noise(audio_array, audio.frame_rate)reduced_audio = AudioSegment(reduced_noise.tobytes(),frame_rate=audio.frame_rate,sample_width=audio.sample_width,channels=audio.channels)reduced_audio.export(output_file, format="wav")return output_fileexcept Exception as e:return f"发生错误:{str(e)}"def extract_keywords(result):word_list = jieba.lcut(result)return word_listdef save_base64(uploaded_file):with open(uploaded_file, "rb") as file:audio_content = file.read()encoded = base64.b64encode(audio_content).decode('utf-8')return encodeddef main():st.title("语音识别与词云生成")uploaded_file = st.file_uploader("上传 WAV 文件", type="wav")if uploaded_file:st.audio(uploaded_file, format='audio/wav')language_choice = st.radio("选择语言", ('CN', 'EN'))bu=st.button("识别语音")if bu:if uploaded_file:output_audio_path = os.path.basename(uploaded_file.name)processed_audio_path = reduce_noise_and_export(uploaded_file, output_audio_path)if not processed_audio_path.startswith("发生错误"):result = recognition(processed_audio_path, language_choice)st.write("识别结果:" + result)keywords = extract_keywords(result)st.write("提取的关键词:", keywords)text = " ".join(keywords)wc = WordCloud(font_path="SimSun.ttf",collocations=False, width=800, height=400, margin=2, background_color='white').generate(text.lower())st.image(wc.to_array(), caption='词云')# 提供处理后音频的下载链接st.markdown(get_base64_link(processed_audio_path, '下载降噪音频'), unsafe_allow_html=True) else:st.warning("请上传文件")
def get_base64_link(file_path, link_text):with open(file_path, "rb") as file:audio_content = file.read()encoded = base64.b64encode(audio_content).decode('utf-8')href = f'<a href="data:audio/wav;base64,{encoded}" download="processed_audio.wav">{link_text}</a>'return hrefif __name__ == "__main__":main()
requirements.txt
wenet @ git+https://github.com/wenet-e2e/wenet
streamlit
wordcloud
pydub
jieba
noisereduce

体验链接: 长音频切换识别
import streamlit as st
import jieba
from wordcloud import WordCloud
import matplotlib.pyplot as plt
from pydub import AudioSegment
from noisereduce import reduce_noise
import wenet
import base64
import os
import numpy as np# 载入模型
chs_model = wenet.load_model('chinese')
en_model = wenet.load_model('english')# 执行语音识别的函数
def recognition(audio, lang='CN'):if audio is None:return "输入错误!请上传音频文件!"if lang == 'CN':ans = chs_model.transcribe(audio)elif lang == 'EN':ans = en_model.transcribe(audio)else:return "错误!请选择语言!"if ans is None:return "错误!没有文本输出!请重试!"txt = ans['text']return txtdef reduce_noise_segmented(input_file,chunk_duration_ms,frame_rate):try:audio = AudioSegment.from_file(input_file,format="wav")# 将双声道音频转换为单声道audio = audio.set_channels(1)# 压缩音频的帧率为 16000audio = audio.set_frame_rate(frame_rate)duration = len(audio)# 分段处理音频chunked_audio = []start = 0while start < duration:end = min(start + chunk_duration_ms, duration)chunk = audio[start:end]chunked_audio.append(chunk)start = endreturn chunked_audioexcept Exception as e:st.error(f"发生错误:{str(e)}")return Nonedef extract_keywords(result):word_list = jieba.lcut(result)return word_listdef get_base64_link(file_path, link_text):with open(file_path, "rb") as file:audio_content = file.read()encoded = base64.b64encode(audio_content).decode('utf-8')href = f'<a href="data:audio/wav;base64,{encoded}" download="processed_audio.wav">{link_text}</a>'return hrefdef main():st.title("语音识别与词云生成")uploaded_file = st.file_uploader("上传音乐文件", type="wav")if uploaded_file:st.audio(uploaded_file, format='audio/wav')segment_duration = st.slider("分段处理时长(毫秒)", min_value=1000, max_value=10000, value=5000, step=1000)frame_rate = st.slider("压缩帧率", min_value=8000, max_value=48000, value=16000, step=1000)language_choice = st.selectbox("选择语言", ('中文', '英文'))bu=st.button("识别语音")if bu:if uploaded_file:st.success("正在识别中,请稍等...")output_audio_path = os.path.basename(uploaded_file.name)chunked_audio = reduce_noise_segmented(uploaded_file, segment_duration, frame_rate)# 计算总的音频段数total_chunks = len(chunked_audio)if total_chunks>0:# 创建进度条progress_bar = st.progress(0)# 对每个音频段进行降噪并合并reduced_noise_chunks = []result_array = []for i, chunk in enumerate(chunked_audio):audio_array = chunk.get_array_of_samples()reduced_noise = reduce_noise(np.array(audio_array), chunk.frame_rate)reduced_chunk = AudioSegment(reduced_noise.tobytes(),frame_rate=chunk.frame_rate,sample_width=chunk.sample_width,channels=chunk.channels)reduced_noise_chunks.append(reduced_chunk)language=""if language_choice=='中文':language="CN"else:language="EN"path="第"+str(i+1)+"段音频.wav"reduced_chunk.export(path,format="wav")while os.path.exists(path):result = recognition(path, language)if result:st.write(f"第{i+1}段音频识别结果:" + result)result_array.append(result)break# 更新进度条的值progress = int((i + 1) / total_chunks * 100)progress_bar.progress(progress)st.write("识别的结果为:","".join(result_array))keywords = extract_keywords("".join(result_array))st.write("提取的关键词:", keywords)text=" ".join(keywords)wc = WordCloud(font_path="SimSun.ttf",collocations=False, width=800, height=400, margin=2, background_color='white').generate(text.lower())st.image(wc.to_array(), caption='词云')# 合并降噪后的音频段reduced_audio = reduced_noise_chunks[0]for i in range(1, len(reduced_noise_chunks)):reduced_audio += reduced_noise_chunks[i]# 导出处理后的音频文件reduced_audio.export(output_audio_path,format="wav")while os.path.exists(output_audio_path):# 提供处理后音频的下载链接st.markdown(get_base64_link(output_audio_path, '下载降噪音频'), unsafe_allow_html=True) breakelse:st.warning("请上传文件")if __name__ == "__main__":main()


(三))












 -- 确认应答 和 超时重传)


进行多选对话常识推理)
