我们已经知道通过 L1 正则化和 SBS 算法可以用来做特征选择。
我们还可以通过随机森林从数据集中选择相关的特征。随机森林里面包含了多棵决策树,我们可以通过计算特征在每棵决策树决策过程中所产生的的信息增益平均值来衡量该特征的重要性。
你可能需要参考:《机器学习系列06:决策树》
这种方法无需对特征做归一化或者标准化预处理,也不假设数据集是否线性可分。
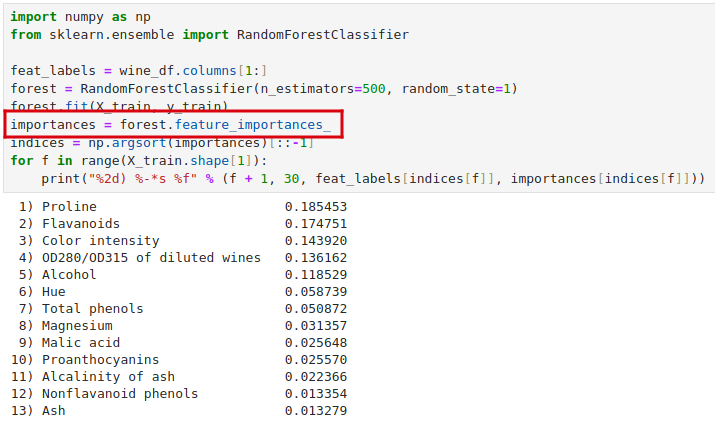
以红酒数据集为例。我们可以直接通过 feature_importances_ 属性获取每个特征的重要性,所有特征重要性之和为 1.0。
我们可以更直观地可视化观察一下。
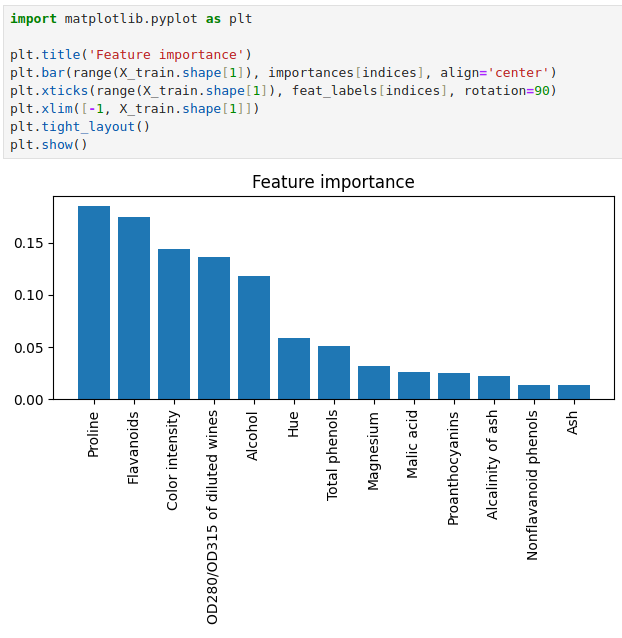
可以看到上面随机森林选出的前 3 个特征最重要的特征中有 2 也出现在了之前在
《机器学习系列12:减少过拟合——降维(特征选择)》中使用 SFS 算法选择的 3 个最重要的特征中。

我们可以通过 scikit-learn 提供的 SelectFromModel 来通过 threshold 参数设定一个阈值 ,选择满足这个贡献度阈值的特征出来。
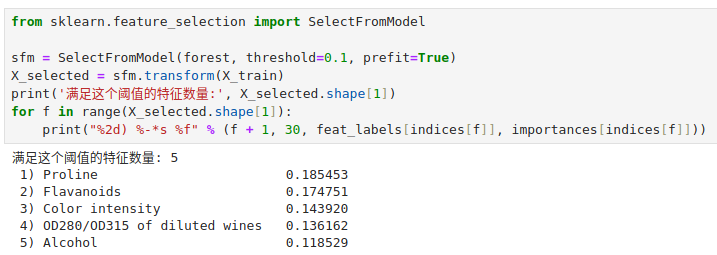
可以看到选择了 5 个特征,现在我们就用这 5 个特征拟合一下 kNN 算法。

可以对比一下在用 SFS 算法选择的 3 个特征拟合的 kNN 算法。
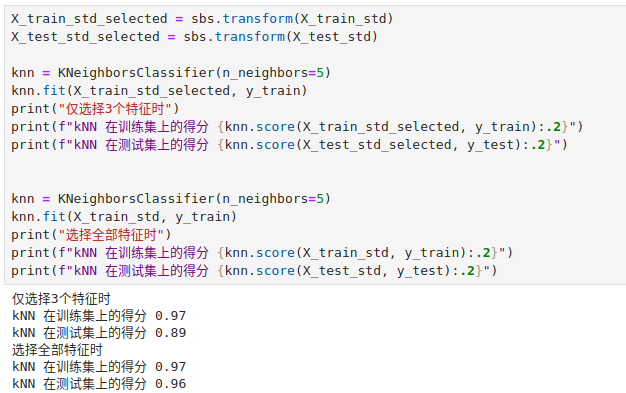
选择 5 个特征时,模型在训练集和测试集上的表现和选择全部特征的表现相当!



 详细讲解动态规划的思路)



(第40~42集))









报错parameter group不匹配的问题的原因)

 + Nacos(v2.3.0) + Mysql(5.7))