1.数据集划分¶
1.1 为什么要划分数据集?¶
思考:我们有以下场景:
-
将所有的数据都作为训练数据,训练出一个模型直接上线预测
-
每当得到一个新的数据,则计算新数据到训练数据的距离,预测得到新数据的类别
存在问题:
-
上线之前,如何评估模型的好坏?
-
模型使用所有数据训练,使用哪些数据来进行模型评估?
结论:不能将所有数据集全部用于训练
为了能够评估模型的泛化能力,可以通过实验测试对学习器的泛化能力进行评估,进而做出选择。因此需要使用一个 "测试集" 来测试学习器对新样本的判别能力,以测试集上的 "测试误差" 作为泛化误差的近似。
一般测试集满足:
- 能代表整个数据集
- 测试集与训练集互斥
- 测试集与训练集建议比例: 2比8、3比7 等
1.2 数据集划分的方法¶
留出法:将数据集划分成两个互斥的集合:训练集,测试集
- 训练集用于模型训练
- 测试集用于模型验证
- 也称之为简单交叉验证
交叉验证:将数据集划分为训练集,验证集,测试集
- 训练集用于模型训练
- 验证集用于参数调整
- 测试集用于模型验证
留一法:每次从训练数据中抽取一条数据作为测试集
自助法:以自助采样(可重复采样、有放回采样)为基础
- 在数据集D中随机抽取m个样本作为训练集
- 没被随机抽取到的D-m条数据作为测试集
1.3 留出法(简单交叉验证)
留出法 (hold-out) 将数据集 D 划分为两个互斥的集合,其中一个集合作为训练集 S,另一个作为测试集 T。
from sklearn.model_selection import train_test_split
from sklearn.model_selection import StratifiedShuffleSplit
from sklearn.model_selection import ShuffleSplit
from collections import Counter
from sklearn.datasets import load_irisdef test01():# 1. 加载数据集x, y = load_iris(return_X_y=True)print('原始类别比例:', Counter(y))# 2. 留出法(随机分割)x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)print('随机类别分割:', Counter(y_train), Counter(y_test))# 3. 留出法(分层分割)x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, stratify=y)print('分层类别分割:', Counter(y_train), Counter(y_test))def test02():# 1. 加载数据集x, y = load_iris(return_X_y=True)print('原始类别比例:', Counter(y))print('*' * 40)# 2. 多次划分(随机分割)spliter = ShuffleSplit(n_splits=5, test_size=0.2, random_state=0)for train, test in spliter.split(x, y):print('随机多次分割:', Counter(y[test]))print('*' * 40)# 3. 多次划分(分层分割)spliter = StratifiedShuffleSplit(n_splits=5, test_size=0.2, random_state=0)for train, test in spliter.split(x, y):print('分层多次分割:', Counter(y[test]))if __name__ == '__main__':test01()test02()1.4 交叉验证法
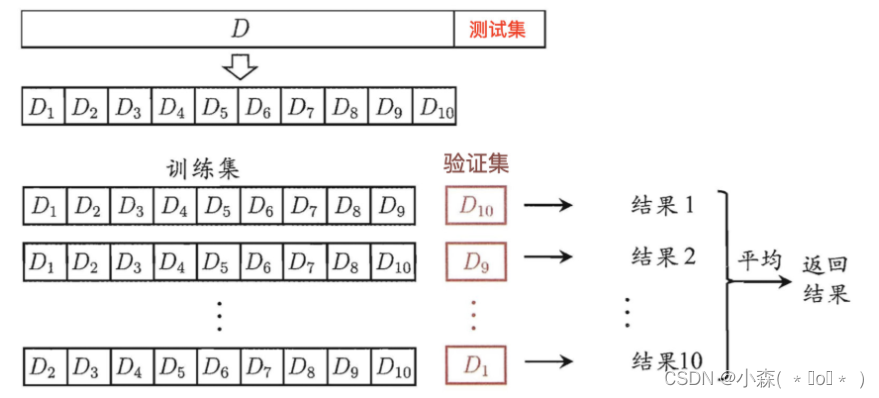
K-Fold交叉验证,将数据随机且均匀地分成k分,如上图所示(k为10),假设每份数据的标号为0-9
- 第一次使用标号为0-8的共9份数据来做训练,而使用标号为9的这一份数据来进行测试,得到一个准确率
- 第二次使用标记为1-9的共9份数据进行训练,而使用标号为0的这份数据进行测试,得到第二个准确率
- 以此类推,每次使用9份数据作为训练,而使用剩下的一份数据进行测试
- 共进行10次训练,最后模型的准确率为10次准确率的平均值
- 这样可以避免了数据划分而造成的评估不准确的问题。
from sklearn.model_selection import KFold
from sklearn.model_selection import StratifiedKFold
from collections import Counter
from sklearn.datasets import load_irisdef test():# 1. 加载数据集x, y = load_iris(return_X_y=True)print('原始类别比例:', Counter(y))print('*' * 40)# 2. 随机交叉验证spliter = KFold(n_splits=5, shuffle=True, random_state=0)for train, test in spliter.split(x, y):print('随机交叉验证:', Counter(y[test]))print('*' * 40)# 3. 分层交叉验证spliter = StratifiedKFold(n_splits=5, shuffle=True, random_state=0)for train, test in spliter.split(x, y):print('分层交叉验证:', Counter(y[test]))if __name__ == '__main__':test()1.5 留一法
留一法( Leave-One-Out,简称LOO),即每次抽取一个样本做为测试集。
from sklearn.model_selection import LeaveOneOut
from sklearn.model_selection import LeavePOut
from sklearn.datasets import load_iris
from collections import Counterdef test01():# 1. 加载数据集x, y = load_iris(return_X_y=True)print('原始类别比例:', Counter(y))print('*' * 40)# 2. 留一法spliter = LeaveOneOut()for train, test in spliter.split(x, y):print('训练集:', len(train), '测试集:', len(test), test)print('*' * 40)# 3. 留P法spliter = LeavePOut(p=3)for train, test in spliter.split(x, y):print('训练集:', len(train), '测试集:', len(test), test)if __name__ == '__main__':test01()1.6 自助法
每次随机从D中抽出一个样本,将其拷贝放入D,然后再将该样本放回初始数据集D中,使得该样本在下次采样时仍有可能被抽到; 这个过程重复执行m次后,我们就得到了包含m个样本的数据集D′,这就是自助采样的结果。
import pandas as pdif __name__ == '__main__':# 1. 构造数据集data = [[90, 2, 10, 40],[60, 4, 15, 45],[75, 3, 13, 46],[78, 2, 64, 22]]data = pd.DataFrame(data)print('数据集:\n',data)print('*' * 30)# 2. 产生训练集train = data.sample(frac=1, replace=True)print('训练集:\n', train)print('*' * 30)# 3. 产生测试集test = data.loc[data.index.difference(train.index)]print('测试集:\n', test)2.分类算法的评估标准¶
2.1 分类算法的评估¶
如何评估分类算法?
-
利用训练好的模型使用测试集的特征值进行预测
-
将预测结果和测试集的目标值比较,计算预测正确的百分比
-
这个百分比就是准确率 accuracy, 准确率越高说明模型效果越好
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
#加载鸢尾花数据
X,y = datasets.load_iris(return_X_y = True)
#训练集 测试集划分
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2)
# 创建KNN分类器对象 近邻数为6
knn_clf = KNeighborsClassifier(n_neighbors=6)
#训练集训练模型
knn_clf.fit(X_train,y_train)
#使用训练好的模型进行预测
y_predict = knn_clf.predict(X_test)计算准确率:
sum(y_predict==y_test)/y_test.shape[0]
2.2 SKlearn中模型评估API介绍
sklearn封装了计算准确率的相关API:
- sklearn.metrics包中的accuracy_score方法: 传入预测结果和测试集的标签, 返回预测准去率
- 分类模型对象的 score 方法:传入测试集特征值,测试集目标值
#计算准确率
from sklearn.metrics import accuracy_score
#方式1:
accuracy_score(y_test,y_predict)
#方式2:
knn_classifier.score(X_test,y_test)3. 小结¶
- 留出法每次从数据集中选择一部分作为测试集、一部分作为训练集
- 交叉验证法将数据集等份为 N 份,其中一部分做验证集,其他做训练集
- 留一法每次选择一个样本做验证集,其他数据集做训练集
- 自助法通过有放回的抽样产生训练集、验证集
- 通过accuracy_score方法 或者分类模型对象的score方法可以计算分类模型的预测准确率用于模型评估


报错parameter group不匹配的问题的原因)

 + Nacos(v2.3.0) + Mysql(5.7))


)



复现)
)


VUEVue路由的重定向、404、编程式导航、path路径跳转传参 详细代码示例)



