在SREWorks社区聚集了很多进行运维数仓建设的同学,大家都会遇到类似的挑战和问题:
- 数仓中存储大量数据消耗成本,但很多存储的数据却并没有消费。
- 进数仓的ETL学习成本高、管理成本高,相关同学配合度低,以及上游结构改动后ETL却迟迟无人调整。
- 数仓中数据的时效性、准确性问题,导致很多场景无法完全依赖数仓展开。
上面的种种让推广数仓的同学很犯难:明明花了大力气构建了统一数仓,但却又受限于各种问题,无法让其价值得到完全的落地。本文旨在阐述一种基于LLM的数仓构建方案,从架构层面解决上述的三个问题。
一、方案设计
从需求出发,再次思考一下我们进行运维数仓构建的初衷:用一句SQL可以查询或统计到所有我们关注的运维对象的情况。虽然有很多方案能做,但总结一下,就是这样两种抽象模型:Push 或 Pull。
- Push的方式是我们去主动管理数据的ETL链路,比如使用Flink、MaxCompute等大数据方案将数据进行加工放到数仓中。在需要查询的时候,直接SELECT数仓就能出结果。这类方案的问题在于:1. ETL管理维护成本高。2. 数据准确性较数据源有所下降。
- Pull的方式是我们不去主动拉所有的数据,在执行时候再去各个数据源找数据,比较具有代表性的就是Presto。这种方案的优点就是不用进行ETL管理以及数据准确性较好,毕竟是实时拉的。但问题就在于这种方案把复杂性都后置到了查询那一刻,查询速度过慢就成了问题。
那么是否有一种方案能将这两种模型结合起来,取其中的优点呢?经过这段时间对于大模型熟悉,我认为这个方案是可行的,于是尝试设计了一下流程图:
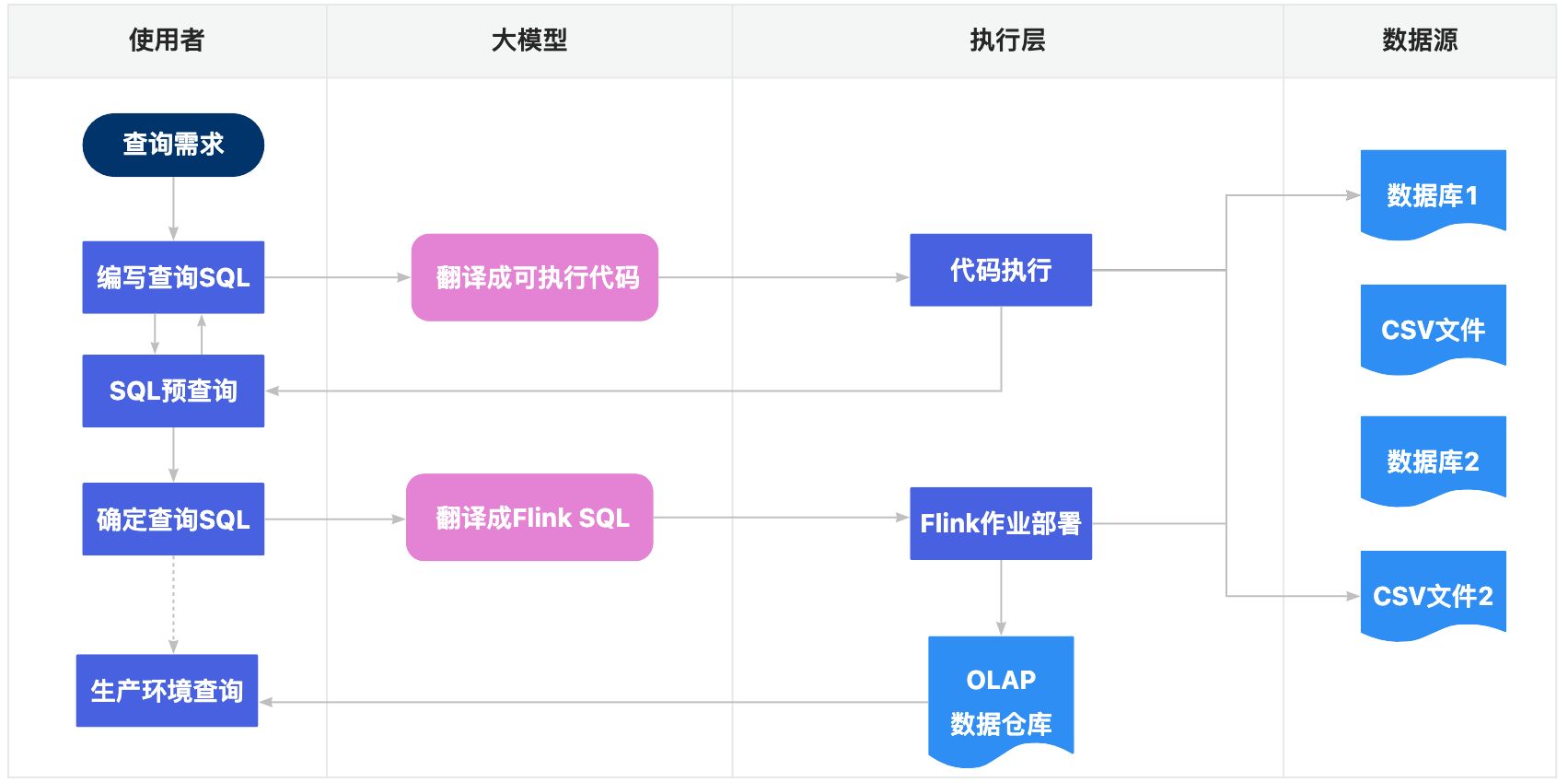
二、基于LLM的SQL预查询
相信大家在使用了类似Presto的联邦查询(Federated Query),都会对此印象深刻,原本要好多个for循环的代码,放到里面只要一个select-join就能解决。但Presto本身的定位就是为分析型的负载设计,我们无法把它置于一些高频查询的关键链路上。
联邦查询的SQL和for循环的代码,看起来似乎只隔了一层纱,现在大模型的出现就直接把这层纱给捅破了。我们的思路也非常简单:既然大模型可以非常方便地把用户需求转换成SQL,那么把用户SQL转换成代码似乎也不是一件难事。
import os
import sys
from openai import OpenAI
import traceback
from io import StringIO
from contextlib import redirect_stdout, redirect_stderrclient = OpenAI()def get_script(content):return content.split("```python")[1].split("```")[0]def execute_python(code_str: str):stdout = StringIO()stderr = StringIO()return_head = 1000context = {}try:# 重定向stdout和stderr,执行代码with redirect_stdout(stdout), redirect_stderr(stderr):exec(code_str, context)except Exception:stderr.write(traceback.format_exc())# 获取执行后的stdout, stderr和contextstdout_value = stdout.getvalue()[0:return_head]stderr_value = stderr.getvalue()[0:return_head]return {"stdout": stdout_value.strip(), "stderr": stderr_value.strip()}prompt = """
你是一个数据库专家,我会给你一段SQL,请你转换成可执行的Python代码。
当前有2个数据库的连接信息,分别是:1. 数据库名称 processes 连接串 mysql://root@test-db1.com:3306/processes
下面是这个数据库的表结构
```
CREATE TABLE `process_table` (`process_name` varchar(100) DEFAULT NULL,`start_time` datetime DEFAULT NULL,`end_time` datetime DEFAULT NULL,`server_name` varchar(100) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
```2. 数据库名称 servers 连接串 mysql://root@test-db2.com:3306/servers
下面是这个数据库的表结构
···
CREATE TABLE `server_table` (`server_name` varchar(100) DEFAULT NULL,`ip` varchar(100) DEFAULT NULL,`zone` varchar(100) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
···在编写Python代码的时候,不要把所有的数据库的信息都传入,请根据SQL的内容按需传入。
返回结果中只有Python代码,如要描述信息全部放在注释中。Python的执行结果需要是JSON格式的数据。
下面用户会给出你需要转换的SQL:
"""query_sql = "select * from processes.process_table a join servers.server_table b on a.server_name = b.server_name where b.zone = 'ZoneA';"messages = [{"role": "system", "content": prompt},{"role": "user", "content": query_sql}
]res = client.chat.completions.create(messages=messages, model="gpt-4")print(res.choices[0].message.content)exec_result = execute_python(get_script(res.choices[0].message.content))print("result:")
print(exec_result)if exec_result["stderr"] == "" and exec_result["stdout"] != "":print(exec_result["stdout"])sys.exit(0)
这个例子,确实相当简单直接,连langchain都不需要,我们基于OpenAI的接口直接实现联邦查询的能力:
- 事先将连接串和数据结构准备好,输入给LLM。
- 将SQL语句输入给LLM,确保SQL中的表名和数据结构中的表名一致,避免LLM混淆。
- 将LLM给出的代码直接执行,便获得了查询结果。
下面我们来看看运行的结果
```python
# Import required libraries
import pandas as pd
from sqlalchemy import create_engine# Create connection engines
engine1 = create_engine('mysql://root@test-db1.com:3306/processes')
engine2 = create_engine('mysql://root@test-db2.com:3306/servers')# Query data from process_table in processes database
df1 = pd.read_sql('SELECT * FROM `process_table`', engine1)# Query data from server_table in servers database
df2 = pd.read_sql('SELECT * FROM `server_table` WHERE `zone` = "ZoneA"', engine2)# Merge both dataframes on server_name
result = pd.merge(df1, df2, how='inner', on='server_name')# Convert dataframe to JSON
out_json = result.to_json(orient='records')print(out_json)
```
关于此代码:
我们首先导入了必要的库,然后使用提供的凭据创建了两个数据库连接。然后,我们分别从两个数据库中查询数据。接着,我们根据"server_name"合并这两个数据框,最后我们将结果转换为JSON格式。
result:
{'stdout': '[{"process_name":"Process1","start_time":1703259365000,"end_time":1703266565000,"server_name":"Server1","zone":"ZoneA"},{"process_name":"Process2","start_time":1703262965000,"end_time":1703270165000,"server_name":"Server2","zone":"ZoneA"}]', 'stderr': ''}
[{"process_name":"Process1","start_time":1703259365000,"end_time":1703266565000,"server_name":"Server1","zone":"ZoneA"},{"process_name":"Process2","start_time":1703262965000,"end_time":1703270165000,"server_name":"Server2","zone":"ZoneA"}]真实运行起来,确实LLM给的代码比较随机,一会儿使用pandas处理数据,一会儿使用pymysql处理数据,存在非常大的不确定性,但是结果是确定的。多试几次之后,我们发现这个结果还是不稳定,有时候会写一些存在瑕疵的代码,导致报错。基于我们在上一篇已经讲清楚的思维链的模型,我们可以给它加上一个报错反馈链路,让它自行修改问题代码。
for i in range(3):print("第", i + 1, "次重试")messages = [{"role": "system", "content": prompt + "\n" + query_sql},]if exec_result["stderr"] != "":messages.append({"role": "user", "content": res.choices[0].message.content + "\n\n" + exec_result["stderr"] + "\n执行报错,请根据报错修正,再次生成代码"})else:messages.append({"role": "user", "content": res.choices[0].message.content + "\n\n" + "执行没有任何返回,请再次生成代码"})res = client.chat.completions.create(messages=messages, model="gpt-4")print(res.choices[0].message.content)exec_result = execute_python(get_script(res.choices[0].message.content))print("result:")print(exec_result)if exec_result["stderr"] == "" and exec_result["stdout"] != "":print(exec_result["stdout"])sys.exit(0)print("查询失败")有了这层错误反馈之后,我们会发现这个查询就非常稳定了,虽然有些时候LLM产生的代码会出错,但是通过报错信息自行修改优化之后,能够保持产出结果稳定(不过自动修改报错的查询,时延明显会比较长一些)。
| 总计 | 一次正确 | 二次正确 | 三次正确 | 失败 | |||||
| 次数 | 20 | 7 | 35% | 9 | 45% | 0 | 0 | 4 | 20% |
| 平均耗时 | 43.0s | 13.2s | 45.3s | N/A | 91.2s | ||||
从20次的测试中,可以看出一次查询的成功率在30%左右,通过报错反馈优化,成功率就能达到80%。通过观察每个查询语句,基本可以发现使用pandas的代码编写准确率高很多,后续如果需要优化prompt,可以在再增加一些使用依赖库上的指引,编写成功率会更高。同时我们也发现,如果有些代码一开始方向就错误的话,通过报错反馈优化也救不回来,三次成功率为零就是一个很好的说明。当前测试用的LLM推理速度较慢,如果本地化部署LLM理论上推理速度还能更快不少。
当前,基于LLM的查询表现上可以和Presto已经比较近似了,但有些地方会比Presto要更强:
- 数据源扩展:presto需要进行适配器的开发才能对接其他数据源,而LLM的方案你只要教会LLM怎么查询特定数据源就行了,事实上可能都不用教,因为它有几乎所有的编程知识。
- 白盒化以及复杂查询优化:针对复杂场景如果存在一些查询准确性问题,需要去preso引擎中排查原因并不简单。但LLM的方案是按照人可阅读的代码来了,你可以要求它按照你熟悉的编程语言编写,你甚至可以要求它写的代码每行都加上注释。
当然,和Presto一样,基于LLM的查询方案,只能被放到预查询中,在生产链路中并不能每次都让LLM去生成查询代码,这太慢了。那么有没有办法让它的查询提速呢?可以的。还记得我们在文章开头提过的Push和Pull的模式吗?联邦查询是基于Pull的模式展开的,而流式ETL是基于Push模式展开的,我们如果把查询语句直接翻译成流式ETL的语句,预先将需要的数据处理到一个数据库中,那是不是就完全可以规避掉性能问题了呢?
三、基于LLM的流计算处理
和分析型的查询相比,流计算的数据同步逻辑显然简单很多,只要分析SQL,按需求字段进行同步即可。这里就不贴完整的代码了,就把相关部分的prompt贴出来。
当前有2个数据库的连接信息,分别是:1. 数据库名称 processes 连接串 mysql://root@test-db1.com:3306/processes
下面是这个数据库的表结构
```
CREATE TABLE `process_table` (`process_name` varchar(100) DEFAULT NULL,`start_time` datetime DEFAULT NULL,`end_time` datetime DEFAULT NULL,`server_name` varchar(100) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
```2. 数据库名称 servers 连接串 mysql://root@test-db2.com:3306/servers
下面是这个数据库的表结构
···
CREATE TABLE `server_table` (`server_name` varchar(100) DEFAULT NULL,`ip` varchar(100) DEFAULT NULL,`zone` varchar(100) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
···你是一个Flink专家,我会给你一段需求SQL,请你根据需求SQL,分析出哪些字段被需要,编写合适的Flink SQL预先处理到clickhouse中。
原有的表在clickhouse中依然保持原有的表名,保持一对一的映射。
Flink SQL处理的目标是使得用户能在clickhouse中在完全不改动需求SQL的情况下正确执行。
在Flink SQL中只进行数据同步,不要加数据处理逻辑。
请在结果中直接给出一份完整的Flink SQL代码,不要任何文字说明,如果有说明的地方在代码中用注释标出。下面用户会给需求SQL:
select a.process_name,b.server_name from processes.process_table a join servers.server_table b on a.server_name = b.server_name where b.zone = 'ZoneA';我们可以看到这份prompt和上一章生成查询代码的prompt几乎没有太大差别,只是对于其生成的目标做了修改,明确告诉它要生成Flink SQL。下面就是LLM生成的Flink SQL:
-- 创建Flink SQL连接到数据库processes的process_table
CREATE TABLE process_table (process_name STRING,server_name STRING
) WITH ('connector' = 'mysql-cdc', -- 使用 MySQL CDC 连接器'hostname' = 'test-db1.com', -- 源数据库主机名'port' = '3306', -- 源数据库端口'username' = 'root', -- 源数据库用户名'database-name' = 'processes', -- 源数据库名'table-name' = 'process_table' -- 源数据库表名
);-- 创建Flink SQL连接到数据库servers的server_table
CREATE TABLE server_table (server_name STRING,zone STRING
) WITH ('connector' = 'mysql-cdc', -- 使用 MySQL CDC 连接器'hostname' = 'test-db2.com', -- 源数据库主机名'port' = '3306', -- 源数据库端口'username' = 'root', -- 源数据库用户名'database-name' = 'servers', -- 源数据库名'table-name' = 'server_table' -- 源数据库表名
);-- 创建到ClickHouse的连接,保持和源数据库对应关系
CREATE TABLE clickhouse_process_table (process_name STRING,server_name STRING
) WITH ('connector' = 'clickhouse','url' = 'clickhouse://localhost:8123','table-name' = 'process_table'
);CREATE TABLE clickhouse_server_table (server_name STRING,zone STRING
) WITH ('connector' = 'clickhouse','url' = 'clickhouse://localhost:8123','table-name' = 'server_table'
);-- Flink SQL同步数据
INSERT INTO clickhouse_process_table
SELECT process_name, server_name
FROM process_table;INSERT INTO clickhouse_server_table
SELECT server_name, zone
FROM server_table;如我们所预期的,LLM给出了准确的Flink SQL语句,并且还根据查询需求的SQL,它只同步了会查到的字段,用不到的字段就没有同步(比如server中的ip字段没有用到)。在这样一条链路中,我们同样可以类似第三章使用的报错反馈自优化的方式,提高生成代码的稳定性,使得其生成的代码可以直接在生产中部署运行,在这里我们就不做过多展开了。
四、总结
一份需求查询SQL,利用LLM生成两份代码,一份用于Pull:直接查询返回结果,预查询调试用;一份用于Push:构建消费链路进实时数仓。基于LLM,实现真正意义上从需求出发的ETL生产链路构建,大概包含如下优点:
- 避免ETL过程的过度加工:按需加字段,不会加工太多用不到字段浪费计算、浪费存储。
- 降低使用者维护ETL加工过程成本:虽然Flink SQL的可维护性已经很好了,但是面向计算过程的SQL编写方式还是让很多用户不适应。如果直接用查询SQL来进行自动生成,就大大降低了维护的门槛。
- 统一数据链路:以查询为驱动的数据模型,可以使得使用者始终面向数据源表进行需求思考。ETL实时计算产生的数据会更像一个物化视图,这样在做实时数据准确性校验时也更加方便。
如果您当前还在为数仓的构建所困扰,可以尝试一下这个基于LLM的方案,欢迎大家在SREWorks数智运维社区沟通交流。







)











