随着人工智能技术的迅猛发展,问答机器人在多个领域中展示了广泛的应用潜力。在这个信息爆炸的时代,许多领域都面临着海量的知识和信息,人们往往需要耗费大量的时间和精力来搜索和获取他们所需的信息。
在这种情况下,垂直领域的 AI 问答机器人应运而生。OpenAI 的 GPT3.5 和 GPT4 无疑是目前最好的 LLM(大语言模型),借助 OpenAI 的 GPT 确实可以快速地打造出一个高质量的 AI 问答机器人,但是 GPT 在实际应用上存在着不少限制。比如 ChatGPT 的知识库是通用领域的,对于垂直领域的知识理解有限,而且对于不熟悉的知识还会存在幻觉的问题。
另外 GPT 的训练语料大部分是英文的,对于中文的理解也存在一定的问题,这对于国内公司来说是一个很大的问题。
本文将介绍如何使用中文 LLM—— ChatGLM2 结合 LangChain 来打造一个垂直领域的知识库问答系统,并在云 GPU 服务上部署运行。

GPU 服务器选择
如果想要在机器上跑自己部署的 LLM,那么你至少需要一台配置不错的 GPU 服务器,否则推理的速度会很慢。想要拥有 GPU 服务器,你可以选择购买或者租用。如果你有足够的资金,那么可以选择购买一台 GPU 服务器,如果你的资金有限,那么可以选择租用云 GPU 服务器。本文主要以租用云 GPU 服务器为例来讲解内容。
随着 AI 的火热,国内出现各种云 GPU 服务厂商,老牌的国内各大云厂商也都纷纷支持 GPU 服务器,经过笔者的试用,发现 AutoDL 和阿里云的 GPU 服务器性价比最高,而且系统也比较稳定且无需绑定额外的开发框架,所以笔者比较推荐这两个云服务器厂商。
技术交流
建了大模型技术交流群!想要学习、技术交流、获取如下原版资料的同学,可以直接加微信号:mlc2060。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
方式①、微信搜索公众号:机器学习社区,后台回复:加群
方式②、添加微信号:mlc2060,备注:来自CSDN + 技术交流

阿里云
先说说为什么推荐阿里云的 GPU 服务器,这是因为他们推出了一个免费试用计划[1],可以让开发者免费试用 5000CU*H 的 GPU,试用时间为 3 个月,支持 A10/V100/G6 3 种显卡机型。

不免费的话阿里云的 GPU 服务器还是比较贵的,V100 16G 的服务器一个小时要大约 30 块钱,还不包括存储的费用。免费的额度使用完后,建议找其他的云服务器厂商。
AutoDL
AutoDL[2]是一款新晋的云 GPU 深度学习环境出租平台,相比阿里云的 GPU 服务器价格,AutoDL 的价格可谓相当亲民。
以 V100 服务器为例,阿里云的 V100 16G 的服务器收费大概是 30 元每小时且不包存储,而 AutoDL 的 V100 32G 服务器仅需 2.4 元每小时,还送 50GB 的存储,价格是阿里云的十分之一不到,配置还更高。
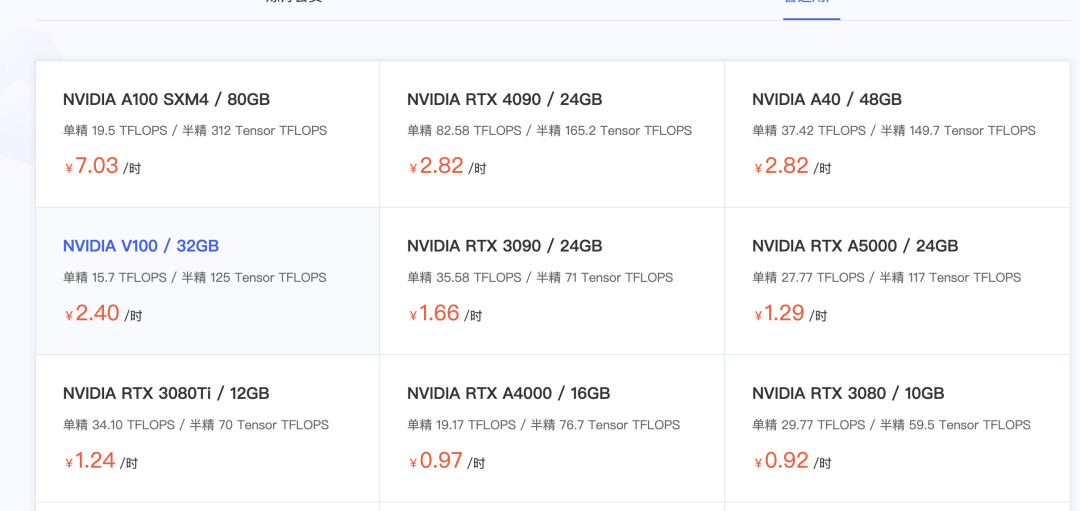
所以我建议的云 GPU 服务器使用策略是:先免费试用阿里云三个月的 GPU 服务器,然后再使用 AutoDL 的 GPU 服务器。如果你有更加划算的 GPU 服务器推荐,欢迎在评论区留言。
创建实例
无论你是使用阿里云还是 AutoDL,都需要先创建一个服务器实例,创建实例按照官方说明文档即可,需要注意的是实例的镜像选择,笔者选择的是 PyTorch 1.1x + Ubuntu 20.04 的镜像,这个镜像已经安装了 PyTorch 和 CUDA ,使用起来也比较稳定,其他的镜像部署过程中可能会出现各种问题。
另外建议选择显存至少为 16GB 的显卡,因为 ChatGLM2-6B 的推理需要至少 12GB 的显存,再加上 LangChain 其他模型的显存消耗,所以至少要保证 16GB 的显存才能进行后面的部署工作。
部署 ChatGLM2
我们先部署 ChatGLM2,ChatGLM2 是开源中英双语对话模型的第二代,对中文的处理能力要优于其他大模型,比第一代有了更强大的性能,更长的上下文,更高效的推理,更开放的协议。
克隆仓库
开始克隆仓库并安装依赖,在阿里云和 AutoDL 上安装 python 依赖包时,系统默认的是使用阿里的源,安装速度会比较慢,这里我推荐用百度的源,速度快非常多。
git clone https://github.com/THUDM/ChatGLM2-6B.git
cd ChatGLM2-6B
pip install -r requirements.txt -i https://mirror.baidu.com/pypi/simple # 用百度的源
模型下载
接着是下载模型,这里我使用的是 ChatGLM2-6B 的模型,模型文件是存放在 HuggingFace 上面,最近国内连接 HuggingFace 经常会不通,不清楚是不是被墙了,所以如果下载过程中遇到问题,可以尝试使用科学上网进行代理。下面介绍两种下载方法。
自动下载
第一种是直接运行web_demo.py,这样程序在执行时会先检查本地是否有模型,没有的话就会自动下载模型,下载完成后再开始执行程序,下载下来的模型存放在这个目录:~/.cache/huggingface/hub/models--THUDM--chatglm2-6b/blobs,模型大小大概有 10G 左右。
手动下载
第二种是使用git clone下载模型,因为模型比较大,所以要先确认 git 的大文件下载功能是否已开启,执行命令git lfs install,如果显示Git LFS initialized.则说明已开启,否则需要先安装Git LFS,可以在这个网站[3]查看如何安装。
然后执行git clone命令下载模型。
git clone https://huggingface.co/THUDM/chatglm2-6b
手动下载模型需要修改web_demo.py文件中的模型路径,将from_pretrained中的模型路径修改为下载后的模型路径。
-tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True)
-model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True, device='cuda')
+tokenizer = AutoTokenizer.from_pretrained("/mnt/workspace/chatglm2-6b", trust_remote_code=True)
+model = AutoModel.from_pretrained("/mnt/workspace/chatglm2-6b", trust_remote_code=True).quantize(4).cuda()
部署验证
最后我们希望将 ChatGLM2 运行起来,看安装是否成功,ChatGLM2 提供了一个 web 程序,启动这个程序后我们可以在浏览器中访问它的功能,web 程序的访问端口是 7860,但我们的服务器不一定会开放这个端口对外提供访问,因此我们还需要再改下web_demo.py的代码,来让它可以提供外部访问的地址。
-demo.queue().launch(share=False, inbrowser=True)
+demo.queue().launch(share=True, inbrowser=True)
将share设置为 True,这样程序启动后会生成一个对外访问地址,我们在本地浏览器直接访问这个地址就可以了。执行命令python web_demo.py启动 web 程序。
/mnt/workspace/ChatGLM2-6B> python web_demo.py
[2023-07-13 11:20:33,304] [INFO] [real_accelerator.py:110:get_accelerator] Setting ds_accelerator to cuda (auto detect)
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████| 7/7 [01:25<00:00, 12.25s/it]
Running on local URL: http://127.0.0.1:7860
Running on public URL: https://46841e4217313f9dbb.gradio.live This share link expires in 72 hours. For free permanent hosting and GPU upgrades (NEW!), check out Spaces: https://huggingface.co/spaces
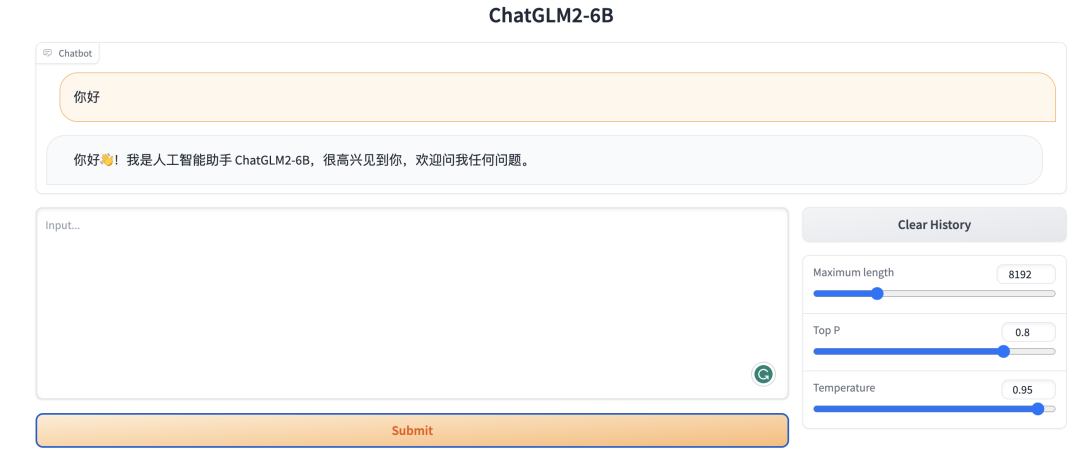
public URL就是我们要访问的地址,需要注意的是这个地址不是一成不变的,而是每次启动都会生成新的地址。下面是 web 程序的界面。
部署 LangChain-ChatGLM
接下来我们再部署 LangChain-ChatGLM,首先介绍一下 LangChain 和 LangChain-ChatGLM 这 2 个项目。
LangChain[4]是一个强大的框架,旨在帮助开发人员使用语言模型构建端到端的应用程序。它提供了一套工具、组件和接口,可简化创建由 LLM 提供支持的应用程序的过程。LangChain 可以轻松管理与语言模型的交互,将多个组件链接在一起,并集成额外的资源,例如 API 和数据库。
Langchain-ChatGLM[5] 是一种利用 Langchain 思想实现的基于本地知识库的问答应用,目标期望建立一套对中文场景与开源模型支持友好、可离线运行的知识库问答解决方案。它对中文文档分隔,问题加上下文拼接上都做了相应的优化。
Langchain-ChatGLM 开始是基于 ChatGLM 第一代来开发的,后面慢慢支持更多的模型,ChatGLM2 推出后,项目也很快集成了 ChatGLM2。
克隆仓库
和ChatGLM2一样,我们首先要下载 Langchain-ChatGLM 项目代码并安装依赖。
git clone https://github.com/imClumsyPanda/langchain-ChatGLM.git
cd langchain-ChatGLM
pip install -r requirements.txt -i https://mirror.baidu.com/pypi/simple # 用百度的源
下载 Embedding 模型
Langchain-ChatGLM 除了要用到 ChatGLM2 模型外,还需要用到一个用来 Embedding 文档和 Prompt 的模型,默认是用的text2vec-large-chinese,但这个模型推理用的显存比较大,大概要 3G 多显存,我们可以使用一个小一点的模型text2vec-base-chinese。
同样地,我们只需要用git clone下载模型。
git clone https://huggingface.co/shibing624/text2vec-base-chinese
修改配置文件
模型下载完成后修改配置文件config/model_config.py,将embedding_model_dict中的模型地址改为下载后的 Embedding 模型地址,再修改默认的 Embedding 模型名称为text2vec-base。同时修改llm_model_dict中chatglm2-6b的模型地址为我们下载的 ChatGLM2 模型地址,并且修改默认的 LLM 模型为chatglm2-6b。
embedding_model_dict = { "ernie-tiny": "nghuyong/ernie-3.0-nano-zh", "ernie-base": "nghuyong/ernie-3.0-base-zh",
- "text2vec-base": "shibing624/text2vec-base-chinese",
+ "text2vec-base": "/mnt/workspace/text2vec-base-chinese", # Embedding model name
-EMBEDDING_MODEL = "text2vec"
+EMBEDDING_MODEL = "text2vec-base" "chatglm2-6b": { "name": "chatglm2-6b",
- "pretrained_model_name": "THUDM/chatglm2-6b",
+ "pretrained_model_name": "/mnt/workspace/chatglm2-6b", # LLM 名称
-LLM_MODEL = "chatglm-6b"
+LLM_MODEL = "chatglm2-6b"
针对 ChatGLM2 的修改
因为 ChatGLM2 刚推出不久,Langchain-ChatGLM 对其适配还不太完善,需要手动再修改一些代码才能让 ChatGLM2 正常运行。修改的代码主要是/models/loader/loader.py文件中的_load_model方法,修改内容如下。
LoaderClass.from_pretrained(checkpoint, config=self.model_config, torch_dtype=torch.bfloat16 if self.bf16 else torch.float16,
- trust_remote_code=True)
- .half()
- .cuda()
+ trust_remote_code=True, device='cuda')
+ # .half()
+ # .cuda()
部署运行
最后跟 ChatGLM2 一样,我们修改 Langchain-ChatGLM 的 web 程序,以便我们可以在浏览器中访问到这个 web 程序。修改webui.py文件,将share设置为 True。
- share=False,
+ share=True,
修改完后执行命令python webui.py启动 web 程序。
/mnt/workspace/langchain-ChatGLM> python webui.py
INFO 2023-07-13 14:37:52,071-1d:
loading model config
llm device: cuda
embedding device: cuda
dir: /mnt/workspace/langchain-ChatGLM
flagging username: e717a58b4ce9444e82491cefeb80bf56 [2023-07-13 14:37:58,105] [INFO] [real_accelerator.py:110:get_accelerator] Setting ds_accelerator to cuda (auto detect)
Loading /mnt/workspace/chatglm2-6b...
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████| 7/7 [01:29<00:00, 12.80s/it]
Loaded the model in 91.42 seconds.
{'answer': '你好!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。'}
Running on local URL: http://0.0.0.0:7860
Running on public URL: https://b0f2e23a9ea5b74b4a.gradio.live This share link expires in 72 hours. For free permanent hosting and GPU upgrades (NEW!), check out Spaces: https://huggingface.co/spaces
访问public URL地址就可以看到我们的 web 程序了。

系统使用介绍
添加知识库文档步骤如下:
-
先选新建知识库
-
输入知识库名字,点击“添加至知识选项”
-
上传文件,完了后点击“上传文件并加载知识库”
然后就可以基于这个知识库进行问答了,操作十分简单。
总结
本文介绍了 GPU 服务器的选型,ChatGLM2 和 Langchain-ChatGLM 的部署和使用,如果想要了解更多关于 Langchain-ChatGLM 的实现原理,可以在他们 GitHub 仓库中查看更多的信息。如果你想打造属于自身业务的问答系统,可以参考本文的方法,希望可以帮助到你。
关注我,一起学习各种人工智能和 AIGC 新技术,欢迎交流,如果你有什么想问想说的,欢迎在评论区留言。
参考:
[1]免费试用计划: https://free.aliyun.com/?searchKey=PAI&spm=5176.22772544.J_4237718650.1.14c32ea9Ojx8Dh
[2]AutoDL: https://www.autodl.com/home
[3] 这个网站: https://github.com/git-lfs/git-lfs?utm_source=gitlfs_site&utm_medium=installation_link&utm_campaign=gitlfs#installing
[4] LangChain: https://docs.langchain.com/docs/
[5] Langchain-ChatGLM: https://github.com/imClumsyPanda/langchain-ChatGLM





)



)
)








