Python基础
1. Hello World!

Python命令行
假设你已经安装好了Python, 那么在命令提示符输入:
python
将直接进入python。然后在命令行提示符>>>后面输入:
>>>print('Hello World!')
可以看到,随后在屏幕上输出:
![]()
print是一个常用函数,其功能就是输出括号中得字符串。
(在Python 2.x中,print还可以是一个关键字,可写成print 'Hello World!',但这在3.x中行不通 )
由于篇幅有限,今天分享之前先说下这个,,如果大家喜欢的话我会再更新,专注学习Python技术的小伙伴可以进群(五八八零九零九四二)一起交流学习,群里还有大量学习资料可供大家自行下载参看,欢迎大家一起来交流讨论。
另一个使用Python的方法,是写一个Python程序。用文本编辑器写一个.py结尾的文件,比如说hello.py
在hello.py中写入如下,并保存:
print('Hello World!')
退出文本编辑器,然后在命令行输入:
$python hello.py
来运行hello.py。可以看到Python随后输出
Hello World!
Python基础02 基本数据类型
变量不需要声明
Python的变量不需要声明,你可以直接输入:
那么你的内存里就有了一个变量a, 它的值是10,它的类型是integer (整数)。 在此之前你不需要做什么特别的声明,而数据类型是Python自动决定的。
>>>print(a)
>>>print(type(a))
那么会有如下输出:
10
这里,我们学到一个内置函数type(), 用以查询变量的类型。
回收变量名
如果你想让a存储不同的数据,你不需要删除原有变量就可以直接赋值。
>>>a = 1.3
>>>print(a,type(a))
会有如下输出
1.3
我们看到print的另一个用法,也就是print后跟多个输出,以逗号分隔。

基本数据类型
a=10 # int 整数
a=1.3 # float 浮点数
a=True # 真值 (True/False)
a='Hello!' # 字符串。字符串也可以用双引号。
以上是最常用的数据类型。此外还有分数,字符,复数等其他类型,有兴趣的可以学习一下。
变量不需要声明,不需要删除,可以直接回收适用。
type(): 查询数据类型
整数,浮点数,真值,字符串
Python基础03 序列
sequence 序列
sequence(序列)是一组有顺序的元素的集合
(严格的说,是对象的集合,但鉴于我们还没有引入“对象”概念,暂时说元素)
序列可以包含一个或多个元素,也可以没有任何元素。
我们之前所说的基本数据类型,都可以作为序列的元素。元素还可以是另一个序列,以及我们以后要介绍的其他对象。
序列有两种:tuple(定值表; 也有翻译为元组) 和 list (表)
>>>s1 = (2, 1.3, 'love', 5.6, 9, 12, False) # s1是一个tuple
>>>s2 = [True, 5, 'smile'] # s2是一个list
>>>print(s1,type(s1))
>>>print(s2,type(s2))
tuple和list的主要区别在于,一旦建立,tuple的各个元素不可再变更,而list的各个元素可以再变更。
一个序列作为另一个序列的元素
>>>s3 = [1,[3,4,5]]
空序列
>>>s4 = []
元素的引用
序列元素的下标从0开始:
>>>print(s1[0])
>>>print(s2[2])
>>>print(s3[1][2])
由于list的元素可变更,你可以对list的某个元素赋值:
>>>s2[1] = 3.0
>>>print(s2)
如果你对tuple做这样的操作,会得到错误提示。
所以,可以看到,序列的引用通过s[]实现, int为下标
其他引用方式
范围引用: 基本样式[下限:上限:步长]
>>>print(s1[:5]) # 从开始到下标4 (下标5的元素 不包括在内)
>>>print(s1[2:]) # 从下标2到最后
>>>print(s1[0:5:2]) # 从下标0到下标4 (下标5不包括在内),每隔2取一个元素 (下标为0,2,4的元素)
>>>print(s1[2:0:-1]) # 从下标2到下标1
从上面可以看到,在范围引用的时候,如果写明上限,那么这个上限本身不包括在内。
尾部元素引用
>>>print(s1[-1]) # 序列最后一个元素
>>>print(s1[-3]) # 序列倒数第三个元素
同样,如果s1[0:-1], 那么最后一个元素不会被引用 (再一次,不包括上限元素本身)

字符串是元组
字符串是一种特殊的元组,因此可以执行元组的相关操作。
>>>str = 'abcdef'
>>>print(str[2:4])
tuple元素不可变,list元素可变
序列的引用 s[2], s[1:8:2]
字符串是一种tuple
Python基础04 运算
数学运算
>>>print 1+9 # 加法
>>>print 1.3-4 # 减法
>>>print 3*5 # 乘法
>>>print 4.5/1.5 # 除法
>>>print 3**2 # 乘方
>>>print 10%3 # 求余数
判断
判断是真还是假,返回True/False
>>>print 5==6 # =, 相等
>>>print 8.0!=8.0 # !=, 不等
>>>print 3
>>>print 4>5, 4>=0 # >, 大于; >=, 大于等于
>>>print 5 in [1,3,5] # 5是list [1,3,5]的一个元素
(还有is, is not等, 暂时不深入)
逻辑运算
True/False之间的运算
>>>print True and True, True and False # and, “与”运算, 两者都为真才是真
>>>print True or False # or, "或"运算, 其中之一为真即为真
>>>print not True # not, “非”运算, 取反
可以和上一部分结合做一些练习,比如:
>>>print 5==6 or 3>=3
数学 +, -, *, /, **, %
, >=,
逻辑 and, or, not
Python基础05 缩进和选择
缩进
Python最具特色的是用缩进来标明成块的代码。我下面以if选择结构来举例。if后面跟随条件,如果条件成立,则执行归属于if的一个代码块。
先看C语言的表达方式(注意,这是C,不是Python!)

如果i > 0的话,我们将进行括号中所包括的两个赋值操作。括号中包含的就是块操作,它隶属于if。
在Python中,同样的目的,这段话是这样的

在Python中, 去掉了i > 0周围的括号,去除了每个语句句尾的分号,表示块的花括号也消失了。
多出来了if ...之后的:(冒号), 还有就是x = 1 和 y =2前面有四个空格的缩进。通过缩进,Python识别出这两个语句是隶属于if。
Python这样设计的理由纯粹是为了程序好看。
if语句
写一个完整的程序,命名为ifDemo.py。这个程序用于实现if结构。

$python ifDemo.py # 运行
程序运行到if的时候,条件为True,因此执行x = x+1,。
print x语句没有缩进,那么就是if之外。
如果将第一句改成i = -1,那么if遇到假值 (False), x = x+1隶属于if, 这一句跳过。 print x没有缩进,是if之外,不跳过,继续执行。
这种以四个空格的缩进来表示隶属关系的书写方式,以后还会看到。强制缩进增强了程序的可读性。
复杂一些的if选择:

这里有三个块,分别属于if, elif, else引领。
Python检测条件,如果发现if的条件为假,那么跳过后面紧跟的块,检测下一个elif的条件; 如果还是假,那么执行else块。
通过上面的结构将程序分出三个分支。程序根据条件,只执行三个分支中的一个。
整个if可以放在另一个if语句中,也就是if结构的嵌套使用:

if i > 2 后面的块相对于该if缩进了四个空格,以表明其隶属于该if,而不是外层的if。
if语句之后的冒号
以四个空格的缩进来表示隶属关系, Python中不能随意缩进
if :
statement
elif :
statement
elif :
statement
else:
statement
Python基础07 函数
函数最重要的目的是方便我们重复使用相同的一段程序。
将一些操作隶属于一个函数,以后你想实现相同的操作的时候,只用调用函数名就可以,而不需要重复敲所有的语句。
函数的定义
首先,我们要定义一个函数, 以说明这个函数的功能。
def square_sum(a,b): c = a**2 + b**2 return c
这个函数的功能是求两个数的平方和。
首先,def,这个关键字通知python:我在定义一个函数。square_sum是函数名。
括号中的a, b是函数的参数,是对函数的输入。参数可以有多个,也可以完全没有(但括号要保留)。
我们已经在循环和选择中见过冒号和缩进来表示的隶属关系。
c = a**2 + b**2 # 这一句是函数内部进行的运算
return c # 返回c的值,也就是输出的功能。Python的函数允许不返回值,也就是不用return。
return可以返回多个值,以逗号分隔。相当于返回一个tuple(定值表)。
return a,b,c # 相当于 return (a,b,c)

在Python中,当程序执行到return的时候,程序将停止执行函数内余下的语句。return并不是必须的,当没有return, 或者return后面没有返回值时,函数将自动返回None。None是Python中的一个特别的数据类型,用来表示什么都没有,相当于C中的NULL。None多用于关键字参数传递的默认值。
函数调用和参数传递
定义过函数后,就可以在后面程序中使用这一函数
print square_sum(3,4)
Python通过位置,知道3对应的是函数定义中的第一个参数a, 4对应第二个参数b,然后把参数传递给函数square_sum。
(Python有丰富的参数传递方式,还有关键字传递、表传递、字典传递等,基础教程将只涉及位置传递)
函数经过运算,返回值25, 这个25被print打印出来。
我们再看下面两个例子

第一个例子,我们将一个整数变量传递给函数,函数对它进行操作,但原整数变量a不发生变化。
第二个例子,我们将一个表传递给函数,函数进行操作,原来的表b发生变化。
对于基本数据类型的变量,变量传递给函数后,函数会在内存中复制一个新的变量,从而不影响原来的变量。(我们称此为值传递)
但是对于表来说,表传递给函数的是一个指针,指针指向序列在内存中的位置,在函数中对表的操作将在原有内存中进行,从而影响原有变量。 (我们称此为指针传递)
Python基础09 面向对象的进一步拓展
调用类的其它信息
上一讲中提到,在定义方法时,必须有self这一参数。这个参数表示某个对象。对象拥有类的所有性质,那么我们可以通过self,调用类属性。

这里有一个类属性laugh。在方法show_laugh()中,通过self.laugh,调用了该属性的值。
还可以用相同的方式调用其它方法。方法show_laugh(),在方法laugh_100th中()被调用。
通过对象可以修改类属性值。但这是危险的。类属性被所有同一类及其子类的对象共享。类属性值的改变会影响所有的对象。
__init__()方法
__init__()是一个特殊方法(special method)。Python有一些特殊方法。Python会特殊的对待它们。特殊方法的特点是名字前后有两个下划线。
如果你在类中定义了__init__()这个方法,创建对象时,Python会自动调用这个方法。这个过程也叫初始化。

这里继承了Bird类,它的定义见上一讲。
屏幕上打印:
We are happy birds.Happy,Happy!
我们看到,尽管我们只是创建了summer对象,但__init__()方法被自动调用了。最后一行的语句(summer = happyBird...)先创建了对象,然后执行:
summer.__init__(more_words)
'Happy,Happy!' 被传递给了__init__()的参数more_words
对象的性质
我们讲到了许多属性,但这些属性是类的属性。所有属于该类的对象会共享这些属性。比如说,鸟都有羽毛,鸡都不会飞。
在一些情况下,我们定义对象的性质,用于记录该对象的特别信息。比如说,人这个类。性别是某个人的一个性质,不是所有的人类都是男,或者都是女。这个性质的值随着对象的不同而不同。李雷是人类的一个对象,性别是男;韩美美也是人类的一个对象,性别是女。
当定义类的方法时,必须要传递一个self的参数。这个参数指代的就是类的一个对象。我们可以通过操纵self,来修改某个对象的性质。比如用类来新建一个对象,即下面例子中的li_lei, 那么li_lei就被self表示。我们通过赋值给self.attribute,给li_lei这一对象增加一些性质,比如说性别的男女。self会传递给各个方法。在方法内部,可以通过引用self.attribute,查询或修改对象的性质。
这样,在类属性的之外,又给每个对象增添了各自特色的性质,从而能描述多样的世界。
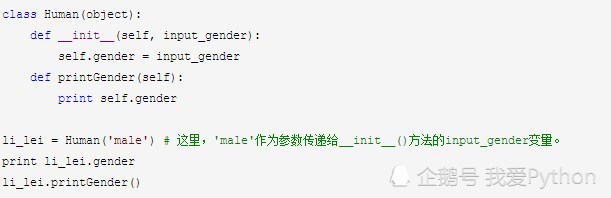
在初始化中,将参数input_gender,赋值给对象的性质,即self.gender。
li_lei拥有了对象性质gender。gender不是一个类属性。Python在建立了li_lei这一对象之后,使用li_lei.gender这一对象性质,专门储存属于对象li_lei的特有信息。
对象的性质也可以被其它方法调用,调用方法与类属性的调用相似,正如在printGender()方法中的调用。
Python基础10 反过头来看看
最初的“Hello World”,走到面向对象。该回过头来看看,教程中是否遗漏了什么。
我们之前提到一句话,"Everything is Object". 那么我们就深入体验一下这句话。
需要先要介绍两个内置函数,dir()和help()
dir()用来查询一个类或者对象所有属性。你可以尝试一下
>>>print dir(list)
help()用来查询的说明文档。你可以尝试一下
>>>print help(list)
(list是Python内置的一个类,对应于我们之前讲解过的列表)
list是一个类
在上面以及看到,表是Python已经定义好的一个类。当我们新建一个表时,比如:
>>>nl = [1,2,5,3,5]
实际上,nl是类list的一个对象。
实验一些list的方法:
>>>print nl.count(5) # 计数,看总共有多少个5
>>>print nl.index(3) # 查询 nl 的第一个3的下标
>>>nl.append(6) # 在 nl 的最后增添一个新元素6
>>>nl.sort() # 对nl的元素排序
>>>print nl.pop() # 从nl中去除最后一个元素,并将该元素返回。
>>>nl.remove(2) # 从nl中去除第一个2
>>>nl.insert(0,9) # 在下标为0的位置插入9
总之,list是一个类。每个列表都属于该类。
Python补充中有list常用方法的附录。
运算符是特殊方法
使用dir(list)的时候,能看到一个属性,是__add__()。从形式上看是特殊方法(下划线,下划线)。它特殊在哪呢?
这个方法定义了"+"运算符对于list对象的意义,两个list的对象相加时,会进行的操作。
>>>print [1,2,3] + [5,6,9]
运算符,比如+, -, >, 方法。
尝试一下
>>>print [1,2,3] - [3,4]
会有错误信息,说明该运算符“-”没有定义。现在我们继承list类,添加对"-"的定义

内置函数len()用来返回list所包含的元素的总数。内置函数__sub__()定义了“-”的操作:从第一个表中去掉第二个表中出现的元素。如果__sub__()已经在父类中定义,你又在子类中定义了,那么子类的对象会参考子类的定义,而不会载入父类的定义。任何其他的属性也是这样。
(教程最后也会给出一个特殊方法的清单)
定义运算符对于复杂的对象非常有用。举例来说,人类有多个属性,比如姓名,年龄和身高。我们可以把人类的比较(>,
下一步
希望你已经对Python有了一个基本了解。你可能跃跃欲试,要写一些程序练习一下。这会对你很有好处。
但是,Python的强大很大一部分原因在于,它提供有很多已经写好的,可以现成用的对象。我们已经看到了内置的比如说list,还有tuple等等。它们用起来很方便。在Python的标准库里,还有大量可以用于操作系统互动,Internet开发,多线程,文本处理的对象。而在所有的这些的这些的基础上,又有很多外部的库包,定义了更丰富的对象,比如numpy, tkinter, django等用于科学计算,GUI开发,web开发的库,定义了各种各样的对象。对于一般用户来说,使用这些库,要比自己去从头开始容易得多。我们要开始攀登巨人的肩膀了。
















)

 | 机器学习系统趋势研判,大咖金句汇总)
