【前言】 由于v5Lite仓库遗漏了不少历史问题,最大的问题是毕业后卷起来了,找不到时间更新。
上面是这篇博客的背景,那么先说下结论,使用 v5lite-e 模型,在 树莓派4B(4G内存) 上,有三种过程得到的三种结果:
- 静态图推理,可达15帧(实际14.5帧),帧率的统计共包括【图解码,前处理,向前推理,后处理,图保存】这五个过程;
- 调用摄像头实时推理,不使用窗口显示结果,可达15帧(满15),帧率的统计包括【取帧,帧解码,前处理,向前推理,后处理】这五个过程;
- 调用摄像头实时推理,使用窗口显示结果,可达13帧,帧率的统计包括【取帧,帧解码,前处理,向前推理,后处理,窗口显示】这六个过程;以上结果均为树莓派预热3分钟后的测试结果。
那么接下来怎么做?Follow me
一、树莓派64位系统
这个是老生常谈的问题了,在很早之前就已经提示过网友这个细节:
http://downloads.raspberrypi.org/raspios_arm64/images/raspios_arm64-2020-08-24/
https://link.zhihu.com/?target=https%3A//shumeipai.nxez.com/download%23os
上一为老版,下一为新版,链接共包含64位 AArch64 架构、相关 A64 指令集的ARMv8-A架构集成的64位系统,求稳请使用老版,追求性能请使用新版,本文默认使用老版64位系统。
至于怎么刷系统,网上教程太多了,这里不展开篇幅。
二、MNN框架编译
没错,这篇博客使用的推理框架是阿里的MNN(本文使用2.7.0版本),正常编译的话,网上已经有非常多的教程了,但是好巧不巧,今天我们的主角是树莓派,只能好好折腾一下。
由于在博主的树莓派只有4G的运行内存,资源比较紧张,如果追求快,板上就肯定上不了fp32的模型,因此只能使用fp16或者bf16进行推理,这时候我们翻找源码中的CMakeLists,有这么两个参数,叫做MNN_SUPPORT_BF16及MNN_ARM82,这两个构建选项很关键,众所周知树莓派4B是基于ARMv8的架构,为了发挥其计算优势,博主刷上了aarch64的系统,这个时候使用bf16的半精度推理方式,无疑有极大的加成。
事不宜迟,我们开始编译推理需要的几个库,使用下面命令:
$ cmake .. -DMNN_BUILD_CONVERTER=ON -DMNN_BUILD_TOOL=ON -DMNN_BUILD_QUANTOOLS=ON -DMNN_EVALUATION=ON -DMNN_SUPPORT_BF16=ON -DMNN_ARM82=ON
$ make -j
这个时候会报一个错,如下:
[ 15%] Building ASM object CMakeFiles/MNNARM64.dir/source/backend/cpu/arm/arm64/bf16/ARMV86_MNNPackedMatMulRemain_BF16.S.o
/root/mnn/MNN/source/backend/cpu/arm/arm64/bf16/ARMV86_MNNPackedMatMulRemain_BF16.S: Assembler messages:
/root/mnn/MNN/source/backend/cpu/arm/arm64/bf16/ARMV86_MNNPackedMatMulRemain_BF16.S:158: Fatal error: macros nested too deeply
make[2]: *** [CMakeFiles/MNNARM64.dir/build.make:383: CMakeFiles/MNNARM64.dir/source/backend/cpu/arm/arm64/bf16/ARMV86_MNNPackedMatMulRemain_BF16.S.o] Error 1
make[1]: *** [CMakeFiles/Makefile2:430: CMakeFiles/MNNARM64.dir/all] Error 2
make[1]: *** Waiting for unfinished jobs....
这是因为启动bf16进行构建时,源码的汇编指令嵌套过深,会导致编译时定义的宏无法展开,这个时候我们需要将指令集中所有关于FMAX和FMIN两个变量的嵌套调用展开,按照以下这种形式修改:

那么编译结束后,我们会使用到后面这三个动态库,一个是包含半精度运行方式的 libMNN.so,一个是进行图像处理的libMNNOpenCV.so,另一个是libMNNExpress.so.
三、导出模式更改
这个时候,博主提供新的三种导出方式,具体哪种请根据自己的情况选择。
首先是第一种,自带ancher和grid匹配的方式,这是因为在群里经常被问到为什么检测框密密麻麻,有很大概率是后处理出了问题,为了规避这种情况,直接把anchor那些乱七八糟的东西给导出来,省去不必要的麻烦,如下:
def mnnd_forward(self, x):z = [] # inference outputfor i in range(self.nl):x[i] = self.m[i](x[i]) bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()if self.grid[i].shape[2:4] != x[i].shape[2:4]:self.grid[i] = self._make_grid(nx, ny).to(x[i].device)y = x[i].sigmoid()xy = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xywh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i].view(1, self.na, 1, 1, 2) # why = torch.cat((xy, wh, y[..., 4:]), -1)z.append(y.view(bs, -1, self.no))return torch.cat(z, 1)
接着是第二种,一种伪造end2end的导出模式,但实际上这种还是和end2end有一定区别,mnn暂未提供类似torchvison.nms处理张量后返回索引id的算子(官方有nms_,和本文想要的又有点不同),因为在这里只能精简下大家常用的end2end方式,将输出头的shape锁死,这样就可以正常导出mnn模型,如下:
def mnne_forward(self, x):z = [] # inference outputfor i in range(self.nl):x[i] = self.m[i](x[i]) bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()if self.grid[i].shape[2:4] != x[i].shape[2:4]:self.grid[i] = self._make_grid(nx, ny).to(x[i].device)y = x[i].sigmoid()xy = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xywh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i].view(1, self.na, 1, 1, 2) # why = torch.cat((xy, wh, y[..., 4:]), -1)z.append(y.view(bs, -1, self.no))prediction = torch.cat(z, 1)min_wh, max_wh = 2, 4096 output = [torch.zeros((0, 6), device=prediction.device)] * prediction.shape[0]for index, pre in enumerate(prediction): obj_conf = pre[:,4:5]cls_conf = pre[:,5:]cls_conf = obj_conf * cls_conf box = xywh2xyxy(pre[:, :4])conf, j = cls_conf.max(1, keepdim=True)pre = torch.cat((box, conf, j.float()), 1)output[index] = pre.view(-1, 6)return output
最后是第三种,这种就是大家常用的end2end方式了,非常简单,网上也有一堆可以抄的代码,但这种目前支持的三方推理库较少,支持比较好的为onnxruntime,如下:
def end2end_forward(self, x):import torchvisionz = [] conf_thres = 0.25iou_thres = 0.50# inference outputfor i in range(self.nl):x[i] = self.m[i](x[i]) bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()if self.grid[i].shape[2:4] != x[i].shape[2:4]:self.grid[i] = self._make_grid(nx, ny).to(x[i].device)y = x[i].sigmoid()xy = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xywh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i].view(1, self.na, 1, 1, 2) # why = torch.cat((xy, wh, y[..., 4:]), -1)z.append(y.view(bs, -1, self.no))prediction = torch.cat(z, 1)min_wh, max_wh = 2, 4096 xc = prediction[..., 4] > conf_thres # candidatesoutput = [torch.zeros((0, 6), device=prediction.device)] * prediction.shape[0]for index, pre in enumerate(prediction): pre = pre[xc[index]] # confidenceobj_conf = pre[:,4:5]cls_conf = pre[:,5:]cls_conf = obj_conf * cls_conf box = xywh2xyxy(pre[:, :4])conf, j = cls_conf.max(1, keepdim=True)pre = torch.cat((box, conf, j.float()), 1)[conf.view(-1) > conf_thres]boxes = pre[:, :4]scores = pre[:, 4]i = torchvision.ops.nms(boxes, scores, iou_thres) # NMSoutput[index] = pre[i]return output
如果喜欢使用mnn推理,又是新手,建议使用第二种方式,但本文默认使用第一种。
四、模型导出和精度排查
这个真的要好好说一说,模型转化为onnx后又不验证下onnx是否能正常使用,精度和原模型对齐没,等使用三方推理框架部署上去后发现有问题,又觉得三方框架转化的模型无误,容易让一些新人陷入自我怀疑的死胡同~
以第一种方式为例,转化onnx的指令如下:
$ python export.py --mnnd --weight weights/v5lite-e.pt
得到.onnx文件后用onnxsim刷一遍,抖掉胶水:
$ python -m onnxsim weights/v5lite-e-mnnd.onnx weights/v5lite-e-mnnd_sim.onnx

同理,其他模型也是这么操作,mnnd方式导出的模型检测头如下:

mnne方式带出的模型检测头如下:


得到转化后的onnx模型,我们验证下导出来的精度对齐没,使用验证脚本直接 python check.py
得到的对比结果如下:

左为原pt模型,右为导出的onnx模型,这时候就可以保证onnx确实没有问题。
五、三方模型转化和量化
三方库转化需要使用到 MNNConvert 工具,只要前面处理好了,这里基本都是一步过,在此之前我们先验证下onnx有没有官方不支持的算子:
$ python ./tools/script/testMNNFromOnnx.py YOLOv5-Lite/v5Lite-e-mnnd_sim.onnx

如果没报错,那就下一步,开始转化:
./build/MNNConvert -f ONNX --modelFile YOLOv5-Lite/mnnd/v5lite-e-mnnd_sim.onnx --MNNModel YOLOv5-Lite/mnnd/v5lite-e-mnnd.mnn --optimizeLevel 1 --optimizePrefer 2 --bizCode MNN --saveStaticModel --testdir val_test

讲几个比较重要的参数:
- –optimizeLevel arg 图优化级别,默认为1:
- 0: 不执行图优化,仅针对原始模型是MNN的情况;
- 1: 保证优化后针对任何输入正确;
- 2: 保证优化后对于常见输入正确,部分输入可能出错;
- –optimizePrefer arg 图优化选项,默认为0:
- 0:正常优化
- 1:优化后模型尽可能小;
- 2:优化后模型尽可能快;
转fp16模型,只需要在后面加上 –fp16 标识符
转化后的mnn模型检测头如下:

转成int8量化模型的话,稍微要久一些,如下:
$ root@ubuntu:/home/xx/MNN# ./build/quantized.out YOLOv5-Lite/mnnd/v5lite-e.mnn YOLOv5-Lite/mnnd/v5lite-e-i8.mnn YOLOv5-Lite/v5Lite-e.json
该过程大约需要10分钟,如果转成功了,会输出以下结果:
[04:46:39] /home/xx/MNN/tools/quantization/quantized.cpp:23: >>> modelFile: YOLOv5-Lite/v5lite-e-mnnd.mnn
[04:46:39] /home/xx/MNN/tools/quantization/quantized.cpp:24: >>> preTreatConfig: YOLOv5-Lite/v5Lite-e-mnnd.json
[04:46:39] /home/xx/MNN/tools/quantization/quantized.cpp:25: >>> dstFile: YOLOv5-Lite/v5lite-e-mnnd-i8.mnn
[04:46:39] /home/xx/MNN/tools/quantization/quantized.cpp:53: Calibrate the feature and quantize model...
[04:46:39] /home/xx/MNN/tools/quantization/calibration.cpp:158: Use feature quantization method: KL
[04:46:39] /home/xx/MNN/tools/quantization/calibration.cpp:159: Use weight quantization method: MAX_ABS
[04:46:39] /home/xx/MNN/tools/quantization/calibration.cpp:179: feature_clamp_value: 127
[04:46:39] /home/xx/MNN/tools/quantization/calibration.cpp:180: weight_clamp_value: 127
[04:46:39] /home/xx/MNN/tools/quantization/calibration.cpp:193: skip quant op name:
The device support i8sdot:1, support fp16:1, support i8mm: 1
[04:46:39] /home/xx/MNN/tools/quantization/Helper.cpp:111: used image num: 5000
[04:46:39] /home/xx/MNN/tools/quantization/calibration.cpp:665: fake quant weights done.
ComputeFeatureRange: 100.00 %
CollectFeatureDistribution: 100.00 %
computeDistance: 100.00 %Debug info:191 input_tensor_0: cos distance: 0.999921, overflow ratio: 0.000082
191 output_tensor_0: cos distance: 0.997810, overflow ratio: 0.000652
192 output_tensor_0: cos distance: 0.998180, overflow ratio: 0.000004
194 output_tensor_0: cos distance: 0.998478, overflow ratio: 0.000049
196 output_tensor_0: cos distance: 0.993538, overflow ratio: 0.000316
197 output_tensor_0: cos distance: 0.997754, overflow ratio: 0.000001
219 input_tensor_0: cos distance: 0.998476, overflow ratio: 0.000000
219 output_tensor_0: cos distance: 0.997667, overflow ratio: 0.000007
221 output_tensor_0: cos distance: 0.987334, overflow ratio: 0.000064
222 output_tensor_0: cos distance: 0.995765, overflow ratio: 0.000005
244 input_tensor_0: cos distance: 0.995262, overflow ratio: 0.000000
244 output_tensor_0: cos distance: 0.994176, overflow ratio: 0.000011
246 output_tensor_0: cos distance: 0.980969, overflow ratio: 0.000172
247 output_tensor_0: cos distance: 0.991131, overflow ratio: 0.000001
269 input_tensor_0: cos distance: 0.993674, overflow ratio: 0.000000
269 output_tensor_0: cos distance: 0.995367, overflow ratio: 0.000009
271 output_tensor_0: cos distance: 0.981729, overflow ratio: 0.000007
272 output_tensor_0: cos distance: 0.994556, overflow ratio: 0.000001
280 input_tensor_0: cos distance: 0.995445, overflow ratio: 0.000001
280 output_tensor_0: cos distance: 0.988656, overflow ratio: 0.000009
281 output_tensor_0: cos distance: 0.994097, overflow ratio: 0.000001
283 output_tensor_0: cos distance: 0.986572, overflow ratio: 0.000001
285 output_tensor_0: cos distance: 0.984723, overflow ratio: 0.000215
286 output_tensor_0: cos distance: 0.995883, overflow ratio: 0.000002
308 input_tensor_0: cos distance: 0.991681, overflow ratio: 0.000002
308 output_tensor_0: cos distance: 0.994107, overflow ratio: 0.000003
310 output_tensor_0: cos distance: 0.983974, overflow ratio: 0.000366
311 output_tensor_0: cos distance: 0.993694, overflow ratio: 0.000000
333 input_tensor_0: cos distance: 0.993330, overflow ratio: 0.000001
333 output_tensor_0: cos distance: 0.992975, overflow ratio: 0.000003
335 output_tensor_0: cos distance: 0.985026, overflow ratio: 0.000022
336 output_tensor_0: cos distance: 0.994901, overflow ratio: 0.000003
358 input_tensor_0: cos distance: 0.993783, overflow ratio: 0.000000
358 output_tensor_0: cos distance: 0.993021, overflow ratio: 0.000002
360 output_tensor_0: cos distance: 0.984969, overflow ratio: 0.000094
361 output_tensor_0: cos distance: 0.993611, overflow ratio: 0.000006
383 input_tensor_0: cos distance: 0.994139, overflow ratio: 0.000007
383 output_tensor_0: cos distance: 0.992251, overflow ratio: 0.000001
385 output_tensor_0: cos distance: 0.984115, overflow ratio: 0.000020
386 output_tensor_0: cos distance: 0.993809, overflow ratio: 0.000006
408 input_tensor_0: cos distance: 0.995448, overflow ratio: 0.000005
408 output_tensor_0: cos distance: 0.992664, overflow ratio: 0.000002
410 output_tensor_0: cos distance: 0.984901, overflow ratio: 0.000113
411 output_tensor_0: cos distance: 0.994208, overflow ratio: 0.000005
433 input_tensor_0: cos distance: 0.994892, overflow ratio: 0.000001
433 output_tensor_0: cos distance: 0.993541, overflow ratio: 0.000002
435 output_tensor_0: cos distance: 0.985944, overflow ratio: 0.000043
436 output_tensor_0: cos distance: 0.995184, overflow ratio: 0.000004
458 input_tensor_0: cos distance: 0.995215, overflow ratio: 0.000003
458 output_tensor_0: cos distance: 0.993813, overflow ratio: 0.000001
460 output_tensor_0: cos distance: 0.985733, overflow ratio: 0.000841
461 output_tensor_0: cos distance: 0.993928, overflow ratio: 0.000001
469 input_tensor_0: cos distance: 0.996452, overflow ratio: 0.000002
469 output_tensor_0: cos distance: 0.988663, overflow ratio: 0.000096
470 output_tensor_0: cos distance: 0.992134, overflow ratio: 0.000001
472 output_tensor_0: cos distance: 0.989637, overflow ratio: 0.000000
474 output_tensor_0: cos distance: 0.968360, overflow ratio: 0.001480
475 output_tensor_0: cos distance: 0.975570, overflow ratio: 0.000000
497 input_tensor_0: cos distance: 0.987168, overflow ratio: 0.000000
497 output_tensor_0: cos distance: 0.980892, overflow ratio: 0.000000
499 output_tensor_0: cos distance: 0.971500, overflow ratio: 0.000056
500 output_tensor_0: cos distance: 0.973503, overflow ratio: 0.000002
508 input_tensor_0: cos distance: 0.972393, overflow ratio: 0.000000
508 output_tensor_0: cos distance: 0.991235, overflow ratio: 0.000002
510 output_tensor_0: cos distance: 0.993184, overflow ratio: 0.000170
523 output_tensor_0: cos distance: 0.996924, overflow ratio: 0.000000
525 output_tensor_0: cos distance: 0.996898, overflow ratio: 0.000100
544 output_tensor_0: cos distance: 0.994193, overflow ratio: 0.000002
557 output_tensor_0: cos distance: 0.989506, overflow ratio: 0.000000
564 output_tensor_0: cos distance: 0.998756, overflow ratio: 0.000002
617 input_tensor_0: cos distance: 0.997003, overflow ratio: 0.000001
617 input_tensor_1: cos distance: 1.000000, overflow ratio: 1.000000
617 output_tensor_0: cos distance: 0.997003, overflow ratio: 0.000001
619 input_tensor_1: cos distance: 1.000000, overflow ratio: 1.000000
619 output_tensor_0: cos distance: 0.989684, overflow ratio: 0.000001
620 input_tensor_1: cos distance: 0.970060, overflow ratio: 0.500000
620 output_tensor_0: cos distance: 0.970980, overflow ratio: 0.000000
622 input_tensor_1: cos distance: 1.000000, overflow ratio: 1.000000
622 output_tensor_0: cos distance: 0.970980, overflow ratio: 0.000000
629 input_tensor_0: cos distance: 0.997438, overflow ratio: 0.000004
629 output_tensor_0: cos distance: 0.997438, overflow ratio: 0.000004
631 output_tensor_0: cos distance: 0.989391, overflow ratio: 0.000004
633 input_tensor_1: cos distance: 0.999999, overflow ratio: 0.166672
633 output_tensor_0: cos distance: 0.989400, overflow ratio: 0.000009
647 output_tensor_0: cos distance: 0.998979, overflow ratio: 0.000001
700 input_tensor_0: cos distance: 0.997080, overflow ratio: 0.000001
700 output_tensor_0: cos distance: 0.997080, overflow ratio: 0.000001
702 output_tensor_0: cos distance: 0.990428, overflow ratio: 0.000000
703 input_tensor_1: cos distance: 0.966962, overflow ratio: 0.550027
703 output_tensor_0: cos distance: 0.968651, overflow ratio: 0.000000
705 input_tensor_1: cos distance: 1.000000, overflow ratio: 1.000000
705 output_tensor_0: cos distance: 0.968651, overflow ratio: 0.000000
712 input_tensor_0: cos distance: 0.997000, overflow ratio: 0.000045
712 output_tensor_0: cos distance: 0.997000, overflow ratio: 0.000045
714 output_tensor_0: cos distance: 0.987340, overflow ratio: 0.000045
716 input_tensor_1: cos distance: 0.953653, overflow ratio: 0.333344
716 output_tensor_0: cos distance: 0.961789, overflow ratio: 0.000000
730 output_tensor_0: cos distance: 0.999155, overflow ratio: 0.000003
783 input_tensor_0: cos distance: 0.996334, overflow ratio: 0.000000
783 output_tensor_0: cos distance: 0.996334, overflow ratio: 0.000000
785 output_tensor_0: cos distance: 0.988708, overflow ratio: 0.000000
786 input_tensor_1: cos distance: 0.918444, overflow ratio: 0.699968
786 output_tensor_0: cos distance: 0.909960, overflow ratio: 0.000000
788 input_tensor_1: cos distance: 1.000000, overflow ratio: 1.000000
788 output_tensor_0: cos distance: 0.909960, overflow ratio: 0.000000
795 input_tensor_0: cos distance: 0.998407, overflow ratio: 0.000055
795 output_tensor_0: cos distance: 0.998407, overflow ratio: 0.000055
797 output_tensor_0: cos distance: 0.993247, overflow ratio: 0.000055
799 input_tensor_1: cos distance: 1.000000, overflow ratio: 0.166672
799 output_tensor_0: cos distance: 0.995202, overflow ratio: 0.000004
814 input_tensor_0: cos distance: 1.000004, overflow ratio: 0.005462
814 output_tensor_0: cos distance: 0.999964, overflow ratio: 0.000023
817 input_tensor_0: cos distance: 0.995616, overflow ratio: 0.000054
817 output_tensor_0: cos distance: 0.990109, overflow ratio: 0.000026
820 output_tensor_0: cos distance: 0.990457, overflow ratio: 0.000000
823 input_tensor_0: cos distance: 0.996000, overflow ratio: 0.000011
823 output_tensor_0: cos distance: 0.991474, overflow ratio: 0.000004
826 output_tensor_0: cos distance: 0.981345, overflow ratio: 0.000002
829 output_tensor_0: cos distance: 0.994768, overflow ratio: 0.003006
832 output_tensor_0: cos distance: 0.988064, overflow ratio: 0.000000
835 output_tensor_0: cos distance: 0.992485, overflow ratio: 0.000000
838 output_tensor_0: cos distance: 0.983760, overflow ratio: 0.000004
841 output_tensor_0: cos distance: 0.997717, overflow ratio: 0.000567
844 output_tensor_0: cos distance: 0.987962, overflow ratio: 0.000000
847 output_tensor_0: cos distance: 0.992817, overflow ratio: 0.000002
850 output_tensor_0: cos distance: 0.984299, overflow ratio: 0.000002
Geometry_UnaryOp39 output_tensor_0: cos distance: 0.998984, overflow ratio: 0.000020
Geometry_UnaryOp41 output_tensor_0: cos distance: 0.999521, overflow ratio: 0.000100
Geometry_UnaryOp44 input_tensor_0: cos distance: 0.998648, overflow ratio: 0.000010
Geometry_UnaryOp44 output_tensor_0: cos distance: 0.999641, overflow ratio: 0.003844
Geometry_UnaryOp50 input_tensor_0: cos distance: 0.998955, overflow ratio: 0.000024
Geometry_UnaryOp50 output_tensor_0: cos distance: 0.999617, overflow ratio: 0.002672
Geometry_UnaryOp56 input_tensor_0: cos distance: 0.999096, overflow ratio: 0.000000
Geometry_UnaryOp56 output_tensor_0: cos distance: 0.999682, overflow ratio: 0.001699
[04:57:36] /home/xx/MNN/tools/quantization/quantized.cpp:58: Quantize model done!
总体而言,int8量化的结果还是很不错的,每层网络fp32和int8的余弦距离基本都在99%左右。
转化结束后,所有模型大小如下:

如果对模型体积有精神洁癖,又不在乎那几个点的损失,强烈推荐使用int8模型,才900多k,在armv8上推理也比fp16的模型快17%左右。
六、推理及结果
这里真没啥好讲的,友友们看我提供在仓库里面的代码即可,这里简单挑两个细节说说就行,一个是mnnd的nms方式,是不用进行anchor配齐和grid匹配等操作,因为导出就已经处理掉了。
另一个是mnne的nms方式,这个更狠,每行张量的最后一个元素就是我们需要的class_id,很适合那些刚入门又不太想花时间去折腾C++的友友们。
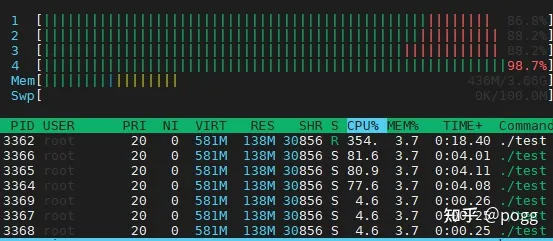
展示下mnnd的推理耗时和结果,首先是静态图的方式:


咦… 等等,貌似有点不太对劲,精度不对啊,咋回事?
这个时候我们又要排查一圈,好在我们已经确定onnx模型是正确的,那问题出在哪?
找了几分钟,原来出在了 backendConfig.precision 这个参数上,我们重新翻回官方的指导手册,看到如下解释:

如果我们要使用回正常的精度,这时候就需要更改这个参数:
backendConfig.precision = MNN::BackendConfig::Precision_Normal; // 全精度
backendConfig.precision = MNN::BackendConfig::Precision_Low_BF16; // 半精度
实测使用全精度后,在树莓派推理静态图片只有12帧,但使用半精度后,基本每个obj的score都降低了2-6个百分点,那如果我们又想快,又想保证精度,咋办?
这时候我们可以在box.score这里做一些骚操作:
box[i].score += 0.04
此时得到一系列的对比如下:

为啥是这样?别问,照做就行了,你个小憨憨…

以上帧率计算包括了【图解码,前处理,向前推理,后处理,图保存】这五个过程,而并不是简单的向前推理。
接着是调用摄像头,带窗口显示的推理方式:

可以看到还是能勉强满足实时性的要求,帧率计算包括了【取帧,帧解码,前处理,向前推理,后处理,窗口显示】这六个过程。
以上测试数据均为预热三分钟后的结果!
七、优化
- 是否还能更快?
友友们按照官方提供的教程和文档,理论上还可以再加速10%-20%,但需要使用到量化后的模型,此处不提供教程,想留个悬念给各位,也非常欢迎你们能PR这个idea。
官方手册:常见问题与解答 - MNN-Doc 2.1.1 documentatio
- 我还想更快,怎么搞?
具体问题具体分析,举个例子,去年毕设中遇到这么一个业务场景,需要检测电梯中的电动车,那既然是电梯内,一般都属于大尺度目标,近距离场景的检测,这样我们可以把小尺度目标的feature进行cell skip,如下:

也就是对于小尺度的feature,我不需要每个cell都去预测,毕竟目标这么大,总有一些不长眼的cell采坑,为了降低计算量,每隔一个cell我才预测一次,但是这样的加速方法就是在赌你的枪有没有子弹,燕大侠看了都摇头,对于小尺度和遮挡严重的场景不适用,因此没有放入仓库中,伪代码如下:
// 对提取出来的三个图层进行 decode,函数如下
decode_infer(MNN::Tensor & data, int stride, const yolocv::YoloSize &frame_size, int net_size, int num_classes,const std::vector<yolocv::YoloSize> &anchors, float threshold, int skip)
{std::vector<BoxInfo> result;int batchs, channels, height, width, pred_item ;batchs = data.shape()[0];channels = data.shape()[1];height = data.shape()[2];width = data.shape()[3];pred_item = data.shape()[4];auto data_ptr = data.host<float>();for(int bi=0; bi<batchs; bi++){auto batch_ptr = data_ptr + bi*(channels*height*width*pred_item);for(int ci=0; ci<channels; ci++){auto channel_ptr = batch_ptr + ci*(height*width*pred_item);for(int hi=0; hi<height; hi+=2){auto height_ptr = channel_ptr + hi*(width * pred_item);for(int wi=0; wi<width; wi+=2){auto width_ptr = height_ptr + wi*pred_item;auto cls_ptr = width_ptr + 5;auto confidence = sigmoid(width_ptr[4]);for(int cls_id=0; cls_id<num_classes; cls_id++){float score = sigmoid(cls_ptr[cls_id]) * confidence;if(score > threshold){float cx = (sigmoid(width_ptr[0]) * 2.f - 0.5f + wi) * (float) stride;float cy = (sigmoid(width_ptr[1]) * 2.f - 0.5f + hi) * (float) stride;float w = pow(sigmoid(width_ptr[2]) * 2.f, 2) * anchors[ci].width;float h = pow(sigmoid(width_ptr[3]) * 2.f, 2) * anchors[ci].height;BoxInfo box;box.x1 = std::max(0, std::min(frame_size.width, int((cx - w / 2.f) )));box.y1 = std::max(0, std::min(frame_size.height, int((cy - h / 2.f) )));box.x2 = std::max(0, std::min(frame_size.width, int((cx + w / 2.f) )));box.y2 = std::max(0, std::min(frame_size.height, int((cy + h / 2.f) )));box.score = score;box.label = cls_id;result.push_back(box);}}}}}}return result;
}// 大尺度图层 skip 设置为 1,保留原始精度
boxes = decode_infer(tensor_scores_host, layers[2].stride, yolosize, net_size, num_classes, layers[2].anchors, threshold, 1);
result.insert(result.begin(), boxes.begin(), boxes.end());// 中尺度图层 skip 设置为 1,保留原始精度
boxes = decode_infer(tensor_boxes_host, layers[1].stride, yolosize, net_size, num_classes, layers[1].anchors, threshold, 1);
result.insert(result.begin(), boxes.begin(), boxes.end());// 小尺度图层 skip 设置为 2,实现网格跳跃
boxes = decode_infer(tensor_anchors_host, layers[0].stride, yolosize, net_size, num_classes, layers[0].anchors, threshold, 2);
result.insert(result.begin(), boxes.begin(), boxes.end());
- 还想再快,还有招吗?
这个只能借用其他第三方并行库做一些加速了,仓库中使用到了OpenMP做一些并行加速,只要计算量稍大的地方都可以试一试,博主凭经验只试了三处地方,树莓派的核就快满了,至于其他芯片,建议多试试~
FAQ环节:
- 为啥我测静态图的时候跑不到14帧?
这个和开发板的新旧程度,磨损程度,以及处理细节有关,比如博主用的静态图尺寸在【480-720】之间,如果使用更大的尺寸做测试,resize的耗时会随着图片尺寸而增加。
- 怎么启动程序后,每隔一段时间帧率就下跌一点?
正常情况,性能和功耗有很大关系,建议多做做散热方面的相关措施。
- 一定要超频才能发挥树莓派更好的性能?
正常情况下是,本文中博主使用的树莓派一直是在超频状态下运行,具体为1.8GHZ,但如果你们开发板性能足够了,最好使用官方推荐的频率在定频下使用。
- 为啥量化后的模型比fp32还慢?
老生常谈的问题,看架构,看指令,看厂家支持,看过大内密探零零发的应该知道,不是后宫三千就一定幸福,这是看质还是看量的问题。
假设买的开发板只有四颗核,那永远无法达到四颗都100%,如果达到了,程序会跳出,利用率能无限接近99%,已经是非常逆天了。
结尾:
如果你还有疑问,那就请加 模型部署&轻量化 交流群:993965802,入群 Password:量化
交流群提倡言论自由,当出现不良广告,不善言论,踢出本群!
交流群友好的话题:模型轻量化&部署和编程技术,模型训练,深度学习前沿知识;MNN、NCNN、TNN、ONNXRUNTIME、OPENVINO、RKNN、QNN、SPNE、TENSORRT等三方推理框架采坑心得;瑞芯微,地平线,爱芯,君正,嘉楠,英伟达,德州仪器等国内外芯片部署经验交流,其他领域的知识,各种技术博客和干货等!
参考:
https://link.zhihu.com/?target=https%3A//github.com/ppogg/YOLOv5-Lite
https://link.zhihu.com/?target=https%3A//github.com/techshoww/mnn-yolov5
https://link.zhihu.com/?target=https%3A//github.com/DefTruth/lite.ai.toolkit
https://github.com/hpc203/yolov5-v6.1-opencv-onnxrun
https://zhuanlan.zhihu.com/p/400545131
https://zhuanlan.zhihu.com/p/478630138
https://openbenchmarking.org/result/2202058-NE-RASPBERRY79&sgm=1
https://github.com/alibaba/MNN/issues/2231
https://github.com/WongKinYiu/yolov7/blob/main/tools/YOLOv7onnx.ipynb
https://mnn-docs.readthedocs.io/en/latest/tools/convert.html
https://mnn-docs.readthedocs.io/en/latest/intro/releases.html?highlight=Precision_Low_BF16#id31






)
:常用内置方法轻松掌握)



,图的存储方式,一些细节(auto,pair用法,结构体指针))







