一 什么是通信
就是进程间的数据交换,进程间由于具有独立性,需要操作系统提供能让进程间交换信息,也就是数据的方法。
二 如何做到
让不同进程看到同一份资源(这不是很简单的事吗),我在父进程定义一个变量,子进程不就能看到吗,这不就看到同一份资源了吗,可是进程间具有独立性,如果你后面想修改这个变量的值,会发生写时拷贝,子进程就看不到父进程修改了,什么?你说为什么要有独立性,因为免得进程间相互影响,假如没有独立性,父进程把数据全改了,然后子进程啥也没做,数据就全被改了,这合理吗?所以父子进程间数据都是独立(父子进程数据独立不表示数据各自一份,而是用写时拷贝和缺页中断来实现父子进程的互不影响(这个我在博客曾详细提过进程地址空间-CSDN博客),毫不相关的进程更要独立。
噢,原来这么难啊,所以这份资源就不应该属于进程,(不过都是操作系统申请的,咋有些属于系统,有些属于进程,我想系统是会区分的),而是应该由操作系统提供一份资源,然后你们往这块空间写数据和读数据就行了,这个空间就是匿名管道。
既然涉及到了操作系统,显然要用系统调用访问啦,而系统中有多个进程都要通信,系统中就会有多个匿名管道,这些匿名管道一定都要被系统管理起来,怎么管理呢?也就是用一个结构体先描述匿名管道,再将所有结构体用数据结构组织起来,这样对匿名管道的管理就变成了对一个数据结构的增删改查。(至于操作系统为什么要管理,为什么管理就是用一个结构体来描述它,我在从硬件结构到软件-CSDN博客曾提及,文字不少,在此不赘述)
三 那为什么要有通信呢
我好端端一个进程,为什么要通信呢,不通信不行吗,你这有进程独立性也不好通信啊,那不如进程间别通信,别交换数据了。我查资料说大的项目中一个进程是不足以支撑功能的,所以需要多个进程来协作通信,这个估计得工作后才好理解。
先前博客我小小的模拟了一下shell,当时的实现是父进程接收键盘输入的指令,然后用fork创建子进程,再用execl函数替换子进程的代码去执行例如ls,pwd等指令,这个我一开始以为是进程间通信,后来感觉有点不像是进程间通信,父进程也只是一开始能给子进程的main函数传个参,之后就没办法了,也算不上通信。
四 进程通信方式-匿名管道
接下来就正式谈匿名管道的实现,就是用文件,噢,文件好啊,磁盘的文件父进程能打开,子进程一般也能打开,因为大家的权限一般是一样的,可能都是user,那我们就可以把通信的数据就可以放到文件中,这不就实现了通信吗。好好好,我悟了,原来这么简单。
不过,这个思想是好的,但是如果真的用磁盘文件通信,那我们存放和读取都会伴随着大量和外设的IO操作,影响效率,不过你本来读取磁盘的内容就要先加载到内存,我才能读取,写也是先写给内存,再刷新到磁盘上,那不如os在内存上划分一个区域用于通信算了。这个区域其实和文件还有点关系,正是文件的系统缓冲区(注意:文件系统缓冲区一词多意,有时候是指用户缓冲区,有时候指系统缓冲区),此时我们指的是内核缓冲区。
1 具体原理
弄一个内存级文件。如下图,一个文件一般在磁盘上有自己的空间,打开后内存也会为文件创建配套的缓冲区,inode结构体,用来存属性,先前还提过一个file结构体,也是存文件属性,但是inode内部的属性更多,因为file结构体是用来管理文件的,管理文件不需要文件的所有属性。

而内存级文件也就是一个文件没有对应的磁盘空间,file_operators对应的也不是硬件的读写方法,而是对缓冲区的读写方法,也不用刷新缓冲区,这种特殊的文件是可以实现的,因为它几乎和普通文件没任何区别,操作系统可以像管理普通文件一样管理它,只是刷新的时候做一下判断,这种缓冲区就不刷新。
子进程会复制父进程的files_struct结构体,而struct file结构体没必要复制,只需要对引用计数++即可,也不能复制,因为file结构体内会记录一个位置信息,这个位置信息用于读写文件时记录读写位置,所以如果file被复制了,那file内记录的位置信息就是独立的,当父进程去写的时候,子进程再去写时会覆盖,所以file不能复制,换一种理解就是file是属于os的,不属于进程,不能复制。下面为了简洁,所以给父子进程都画了一份file结构体。

父进程打开了一个内存级文件,然后fork创建子进程,父子进程就都看到了这个内存级文件,说是看到,其实也就是各自的files_struct中的数组存有file结构体的指针,这样就巧妙地利用继承实现了不同进程看到同一份资源的功能,后面总结管道特征会再说明匿名管道只适用于有血缘关系的进程A,B。
父进程如果以读方式打开,子进程也是只读,因为files_struct中数组存的指针是一样的,指向的struct file结构体是一样的,那如何通信? 解决:父进程同时以读写方式打开,子进程也可以对缓冲区读和写了,然后父关闭读端,子关闭写端,我们实现的是单向通信,因为我们是不建议父进程既可以读又可以写的。
为什么设计者不支持父子进程可以对一个管道既可以读又可以写呢,为了简化file实现,假设我们设计让父子进程可以对一个文件缓冲区同时能读能写,此时父进程往缓冲区写了数据,然后我们又调用父进程去读,为了防止父进程读到自己刚写的数据,是不是就要想想如何区分这个数据是父进程写的还是子进程写的,有点复杂,设计者为了简化,就没有实现让父子进程可以同时读写的方法,而是让我们父进程只能读或者写。
如果当前管道是父写子读,我还想实现父读子写呢,多设一个管道就可以了。
2 创建管道文件
用系统调用pipe函数,既然是系统调用,当然是在man手册中的二号手册中。

参数是个数组,显然这是个输出型参数,pipe函数里面要对数组元素进行修改,然后我们在外界就可以直接获取到了,这两个数组存的其实就是管道的文件描述符,其中pripefd[0]就是以读方式打开的文件描述符,而pipefd[1]则是以写方式打开的文件描述符。注意:一个文件可以被相同方式,或者不相同的方式打开多次,反正open一次就会创建一个file对象,如下,可以验证open一次创建一个file对象,写了两次显示最后一句话,说明有两个file对象,内部的位置信息独立,所以没有接着写,而是直接覆盖写。突然想到了,就提一下,我们创建匿名管道不是直接用的open。

下图又没有覆盖写,说明父子进程共用一个file对象,所以内部记录的位置信息是一样的。

这个对象的指针要存到file_struct数组中,所以一个文件可以有多个文件描述符。
当所有准备工作做好后,我们就可以开始实现通信了,除去创建管道的部分,其余都是非常简单的函数使用。
int main()
{int fd[2]={0};创建管道文件,此时fd内已经装了两个文件描述符pipe(fd);创建子进程int id = fork();if(id == 0){close(fd[0]);//子进程关闭读端Writer(fd[1]); 子进程调用writer函数,向管道写数据关闭文件描述符并退出close(fd[1]);exit(0);}close(fd[1]);//父进程关闭写端Reader(fd[0]); 父进程向管道读数据关闭文件描述符并退出close(fd[0]);return 0;
}
有点懵,怎么会有这么多的close,父进程close一遍,子进程还close一遍,因为进程具有独立性!下图的pcb和files_struct都是每个进程各有一份的,这也必须是各自一份,不然父子进程各自打开不同的文件,files_struct结构体内不就同时存了父子进程打开的文件描述了?此时如果父进程退出,那父进程打开的文件描述符应该都被关闭,也就是把数组上的指针清空,可是我怎么区分哪个是父进程的,哪个是子进程的文件描述符,越想越麻烦,算了,各自一份吧。

接下来就是看看父进程是如何读的以及子进程如何写的了。
#include<stdio.h>
#include<iostream>
#include<unistd.h>
#include<iostream>
#include<string.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <stdlib.h>
using namespace std;上面是使用对应函数需要的头文件,老实说自从在vim写代码,感觉要包含的头文件都变多了#define NUM 1024
void Writer(int wfd)
{char buf[NUM]={0};int cnt = 0;while(true){先将数据写到buf数组中snprintf(buf,sizeof(buf),"I am child id : %d",getpid());系统调用write直接写,向管道文件写和向普通文件是一样的write(wfd,buf,strlen(buf));sleep(1);cnt++;if(cnt > 5)break;}
}snprintf函数:和printf类似,printf("I am child id : %d",getpid()),printf是输出到显示器,而snprintf则是最后输出到数组中去,size应该是告诉snprintf最多读多少个字节,当然读到\0也要停止,\0不会被读取。

细节:Reader代码处我没写sleep,但是我们会发现子进程写一次,然后sleep ,父进程读完后也会陷入休眠,很像是父子进程在协同一样,我写一句,你就读一句,原因管道特征中解释。
void Reader(int rfd)
{char buf[1024]={0};int num = 0;while(true){int n =read(rfd,buf,sizeof(buf));cout<<"这是父进程: 读取结果: ";buf[n] = '\0';if(n > 0){ cout<<buf<<endl;}else if(n == 0){cout<<"child process exit father exit too"<<endl;break;}}
}
在文件时,我们就了解过,write是往文件缓冲区写的,那上述的通信过程中是会有多次拷贝的,不考虑snprintf写到buf数组,只考虑和系统缓冲区打交道的次数,子进程write:buf到系统缓冲区,1次,父进程read:系统缓冲区到buf,共两次。
4 管道特征
1 只能在有血缘关系的进程间通信
2 单向的
3 会协同
4 面向字节流(也就是读端会按照指定的字节数读取,不考虑分隔符,全部都认为是字符)
5 管道的生命周期随进程,当没有文件描述符指向它了,就要删除了
特征1解释 从匿名管道使用我们就知道,这个管道文件无名字,我们无法通过open打开来获取文件描述符,只能用pipe函数往pipefd[2]存的文件描述符,而这个数据是可以被子进程继承的,也就是说只有子进程是最容易拿到这个文件描述符。
为什么我不让操作系统帮忙将这个文件描述符给其它没有血缘关系的进程呢,反正都在系统的管理之下,拿点数据给其它进程怎么了,好,此时我们就是系统的设计者,我们设计了一个接口能将数据传给其它进程,此时我们要实现一种新的通信方式,让两个不相关的进程能够通信,可是我们现在不就在实现通信吗,我们为了能让两个进程能用匿名管道的方式通信,居然要先让他们用其它的方式通信,而且我们上面每句话都说让操作系统帮我处理,操作系统是追求效率的,你这种麻烦低效的通信方式第一个就被枪毙了。
我最后举个例子帮助大家理解,为什么说匿名管道用于有血缘关系的进程,而不是父子进程,例子:假如父进程1调用了pipe函数,然后又创建了两个子进程,这两个子进程都继承了pipefd里面的文件描述符,这两个子进程间可以实现通信,由此我们可以发散思维,不仅父子间可以用这种通信,只要两个进程间具有血缘关系,是亲戚就可以实现通信。
特征2解释,我在写代码的时候都是只让一个进程负责读,另一个进程负责写,不会说一个进程可以又读又写,前面具体原理部分说过了为了简化设计者就建议我们单向通信。
5 管道的四种情况

情况1 读完管道内的数据后,写端未关闭,读端阻塞。
这恰恰印证了管道的特征3,读写端是会协同的,读端要等写端没在写的时候,例如先前代码中写了一句话然后让写端sleep休眠,不能我在写的时候你就上来说你要读,当read读完管道内的数据,此时变成了管道情况1。

所以就出现了写端写一次,然后sleep休眠,此时读端读完,明明代码里没有sleep,也要进入休眠,其实就是管道的设计者让读端休眠了,显然并非是写端的sleep影响了读端休眠,而是管道特征导致的,如果读端读完sleep一下,写端是不会sleep休眠,但写端会一直写,直到写满管道才会休眠,这就是特征2了。
下图我让子进程先休眠10s再写,此时读端一点反应都没有,就是因为在read的时候阻塞了。

情况3 读端正常,写端关闭,读端的read会返回0,若写端没关闭会一直在等数据,就像scanf一样。
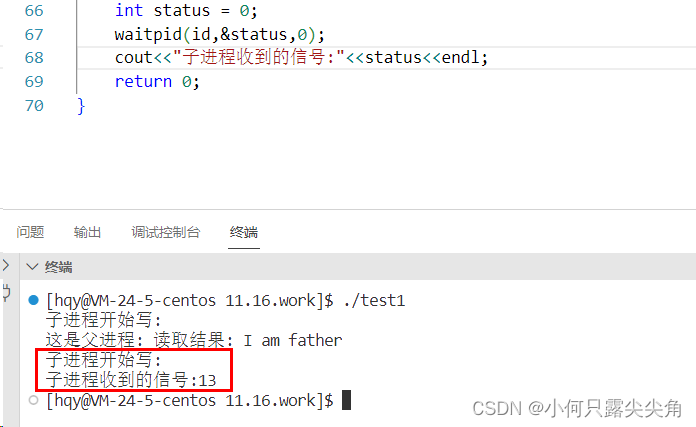
4 读端关闭,写端正常,此时写端进程会被kill。这就是为什么前面设计子写父读的原因,就是为了方便拿到子进程收到的信号值。

子进程写一次,然后父进程读完后就break退出函数了,但是卡在waitpid等子进程退出,然后子进程再写的时候我们就发现子进程退出了,就是因为它收到了13号信号-管道破裂。
五 应用场景 进程池
先前只是简单实现了两个进程的通信,接下来应用进程间通信来实现进程池。
什么是进程池?和内存池原理类似,我们知道shell是bash接收任务,然后创建子进程去执行,如果bash是接收一个任务才创建一个子进程,这样会非常影响bash处理需求的速度,所以为了提高效率,在无任务的时候bash就会创建出一批的子进程,任务来了指派某个子进程执行即可。
执行过程如下函数,接下来就一步步了解这些函数的具体实现。
int main()
{//加载任务Load(&tasks);std::vector<channel> channels;//1 初始化channelsinitchannle(channels);//2 控制子进程crlprocess(channels);//清理回收QuitCtrl(channels); return 0;
}1 加载任务
父进程既然要派发任务给子进程执行,那我们首先得模拟一下有任务来的情况,
typedef void(*task_t)();
void task1()
{std::cout<<"任务1: 打印日志"<<std::endl;
}
void task2()
{std::cout<<"任务2: 检查版本更新"<<std::endl;
}
void task3()
{std::cout<<"任务3: 刷新boss"<<std::endl;
}
void task4()
{std::cout<<"任务4: 发送活动通知"<<std::endl;
}
void Load(std::vector<task_t>* tasks)在main函数定义了一个vector,内部存的是一个个函数指针main函数调用Load()函数来加载任务
{tasks->push_back(task1);tasks->push_back(task2);tasks->push_back(task3);tasks->push_back(task4);
}2 创建子进程
创建的子进程和管道太多,那势必要将管道和子进程管理起来,那保存创建好的子进程pid是有必要的,但是仅仅是保存pid是不够的,因为当父进程挑选出一个子进程的pid的时候,此时想用write发送消息,怎么发,文件fd参数都没有,那好吧,看来得把子进程的pid和对应管道的写端fd保存在一起。如下结构体。

循环创建子进程和管道,用来初始化channels。
#define PRONUM 3class channel 描述子进程和管道
{
public:channel(int cfd, int fd, std::string name):_cfd(cfd), _fd(fd), _pname(name){;}int _cfd; 管道的写端int _fd; 子进程pidstd::string _pname; 进程名
};void initchannle(std::vector<channel>& channels)
{循环创建子进程和匿名管道for (int i = 0; i < PRONUM; i++){int fd[2] = { 0 };int ret = pipe(fd);先创建管道,再创建子进程int id = fork();if (ret == -1)perror("pipe");if (id == 0)//子进程读{close(fd[1]);dup2(fd[0], 0);//输入重定向执行任务slaver();这个函数实现下面会提及关闭读端并退出close(fd[0]);exit(0);}//父进程写close(fd[0]);std::string name = "process->" + to_string(i);channels.push_back(channel(fd[1], id, name));}
}总结一下上面代码,先pipe创建读写端,再创建子进程1,此时子进程1继承读写端,随后父子分别关闭读写端,此时它们的file_struct内的数组如下图。此时是父写子读。

然后我们再pipe一下,然后再创建子进程2,再关闭读写端,最终的file_struct内的数组如下图。

此时我们发现子进程2多继承了一个文件描述符4,这个4是第一次pipe的写端,因为父进程一直没关闭,所以下次创建子进程时,之前的写端都会被继承下来,这个bug在清理回收时会再提及。
而且由于父进程每次关闭了pipe[0],这样后面创建的时候我们发现读端都是3号文件描述符,而写端则是4,5,6....,显然文件描述符的分配是找第一个空位。
3 派发执行任务
管道读端的fd就不用保存了。

因为我们可以通过传参给slaver函数,让子进程拿到fd,或者用输入重定向,再次说明写端要保存的,因为父进程会有多个写端文件描述符,子进程只需要拿到自己的读端描述符就可以接收指令了。
#define PRONUM 3
std::vector<task_t> tasks;
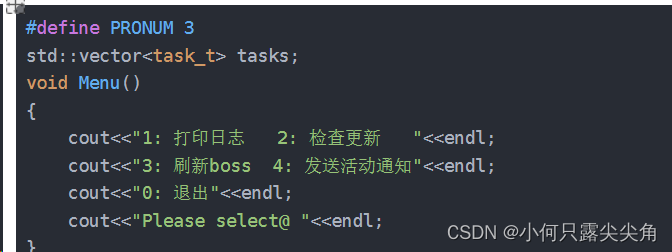
void Menu()
{cout<<"1: 打印日志 2: 检查更新 "<<endl;cout<<"3: 刷新boss 4: 发送活动通知"<<endl;cout<<"0: 退出"<<endl;cout<<"Please select@ "<<endl;
}
void slaver()
{while (true){sleep(1);int codenum = 0;int n = read(0, &codenum, sizeof(int));if (n == sizeof(codenum)){ std::cout << "我是子进程 : " << getpid() << " 收到的任务为" << "codenum: " << codenum << endl;tasks[codenum]();}if (n == 0){std::cout << "退出" << endl;break;}}
}
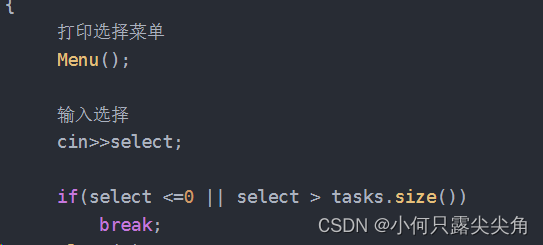
void crlprocess(const std::vector<channel>& channels)
{int cnt = 0;int which = 0;int select = 0;while (true){打印选择菜单Menu();输入选择cin>>select;if(select <=0 || select > tasks.size())break;sleep(1);1 选择任务int tasknum = select - 1;cout<<"父进程第"<<which<<"次给子进程: "<<channels[which]._fd<<" " <<channels[which]._pname<<" 发送任务码: "<<tasknum<<endl;2 选择子进程,并发送任务码write(channels[which]._cfd, &tasknum, sizeof(tasknum));sleep(1);which++;which %= channels.size();采用轮询选择子进程}
}
4 代码异常
异常1
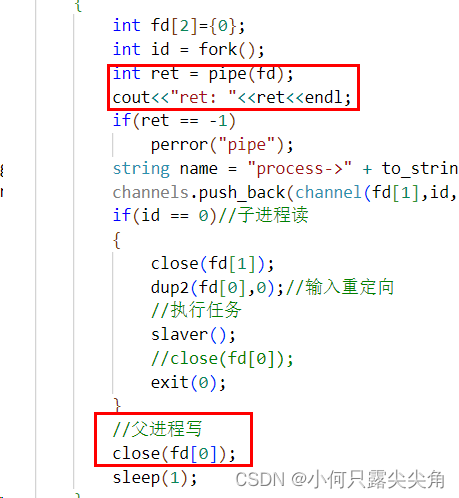
此时父进程会把自己的管道读端关闭,而由于先fork,再创建管道,此时父子进程的管道独立,父进程读端关闭,之后父进程要控制子进程时会往管道写入,此时会发生管道破裂,被系统杀死。
5 清理回收
我们选择0。
然后按照main函数逻辑,此时进入QuitCtrl函数。首先父进程关闭所有的写端。
void QuitCtrl(const std::vector<channel>& channels)
{for(auto& e :channels)close(e._cfd);for(auto& e :channels)//等待回收子进程{waitpid(e._fd,NULL,0);sleep(1);}
}然后父进程一个一个回收子进程,当然我写的代码中存子进程pid并非是必须的,但是如果我是指定了多个子进程执行任务,都执行完了,我要选择性地回收某个子进程看执行结果,此时子进程pid还是有用的。由于waitpid是阻塞等待,所以此时会调用子进程,那我们的子进程到哪了呢?显然,会在slaver()函数中因为read返回0,而退出函数。

有意思的是这个退出顺序,每次都是后创建的进程先退出,按道理说子进程调度顺序是未知的,为什么每次都是最后创建的进程先read返回0,先退出呢。

就是因为这里埋了个小雷,我们先前在创建子进程章节内说了一些子进程内还存着写端的文件描述符,而最后一个子进程对应的管道写端只有一个,父进程关了就没有下一个子进程保存写端,所以每次都是最后一个子进程先read返回0,break退出函数。所以我们选择可以倒着回收,或者用一个数组保存oldfd。
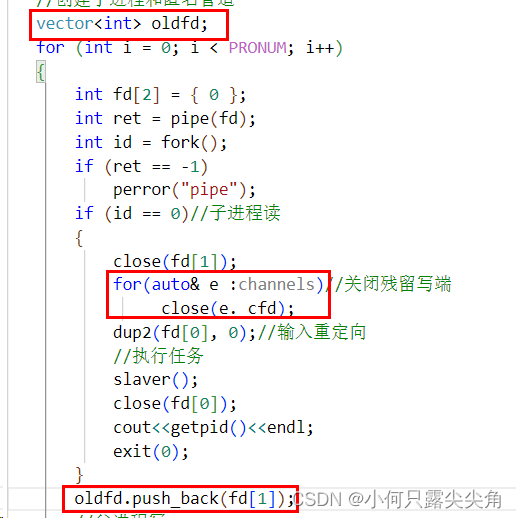
假如父进程push了很多次,然后子进程才开始回收会不会出问题呢,不会,因为会发生写时拷贝。第一个子进程继承的oldfd内啥都没有,父进程push写端的时候不会影响子进程的oldfd,这个有点细,大家可以打印看看。
))


-- filebeat的介绍与安装)

)


:深度学习的成功之源)






)



)