Java之Atomic 原子类总结
Atomic 原子类介绍
Atomic 翻译成中文是原子的意思。在化学上,我们知道原子是构成一般物质的最小单位,在化学反应中是不可分割的。在我们这里 Atomic 是指一个操作是不可中断的。即使是在多个线程一起执行的时候,一个操作一旦开始,就不会被其他线程干扰。
所以,所谓原子类说简单点就是具有原子/原子操作特征的类。
并发包 java.util.concurrent 的原子类都存放在java.util.concurrent.atomic下,如下图所示。
基本类型原子类
AtomicInteger:整型原子类AtomicBoolean:布尔型原子类AtomicLong:长整型原子类
public final int get() //获取当前的值
public final int getAndSet(int newValue)//获取当前的值,并设置新的值
public final int getAndIncrement()//获取当前的值,并自增
public final int getAndDecrement() //获取当前的值,并自减
public final int getAndAdd(int delta) //获取当前的值,并加上预期的值
boolean compareAndSet(int expect, int update) //如果输入的数值等于预期值,则以原子方式将该值设置为输入值(update)
public final void lazySet(int newValue)//最终设置为newValue,使用 lazySet 设置之后可能导致其他线程在之后的一小段时间内还是可以读到旧的值。
AtomicInteger 类使用示例 :
import java.util.concurrent.atomic.AtomicInteger;public class AtomicIntegerTest {public static void main(String[] args) {int temvalue = 0;AtomicInteger i = new AtomicInteger(0);temvalue = i.getAndSet(3);System.out.println("temvalue:" + temvalue + "; i:" + i); //temvalue:0; i:3temvalue = i.getAndIncrement();System.out.println("temvalue:" + temvalue + "; i:" + i); //temvalue:3; i:4temvalue = i.getAndAdd(5);System.out.println("temvalue:" + temvalue + "; i:" + i); //temvalue:4; i:9}}
基本数据类型原子类的优势
通过一个简单例子带大家看一下基本数据类型原子类的优势
1、多线程环境不使用原子类保证线程安全(基本数据类型)
class Test {private volatile int count = 0;//若要线程安全执行执行count++,需要加锁public synchronized void increment() {count++;}public int getCount() {return count;}
}
2、多线程环境使用原子类保证线程安全(基本数据类型)
class Test2 {private AtomicInteger count = new AtomicInteger();public void increment() {count.incrementAndGet();}//使用AtomicInteger之后,不需要加锁,也可以实现线程安全。public int getCount() {return count.get();}
}
AtomicInteger 线程安全原理简单分析
AtomicInteger 类的部分源码:
// setup to use Unsafe.compareAndSwapInt for updates(更新操作时提供“比较并替换”的作用)private static final Unsafe unsafe = Unsafe.getUnsafe();private static final long valueOffset;static {try {valueOffset = unsafe.objectFieldOffset(AtomicInteger.class.getDeclaredField("value"));} catch (Exception ex) { throw new Error(ex); }}private volatile int value;
AtomicInteger 类主要利用 CAS (compare and swap) + volatile 和 native 方法来保证原子操作,从而避免 synchronized 的高开销,执行效率大为提升。
CAS 的原理是拿期望的值和原本的一个值作比较,如果相同则更新成新的值。UnSafe 类的 objectFieldOffset() 方法是一个本地方法,这个方法是用来拿到“原来的值”的内存地址。另外 value 是一个 volatile 变量,在内存中可见,因此 JVM 可以保证任何时刻任何线程总能拿到该变量的最新值。
数组类型原子类
使用原子的方式更新数组里的某个元素
AtomicIntegerArray:整形数组原子类AtomicLongArray:长整形数组原子类AtomicReferenceArray:引用类型数组原子类
上面三个类提供的方法几乎相同,所以我们这里以 AtomicIntegerArray 为例子来介绍。
AtomicIntegerArray 类常用方法
public final int get(int i) //获取 index=i 位置元素的值
public final int getAndSet(int i, int newValue)//返回 index=i 位置的当前的值,并将其设置为新值:newValue
public final int getAndIncrement(int i)//获取 index=i 位置元素的值,并让该位置的元素自增
public final int getAndDecrement(int i) //获取 index=i 位置元素的值,并让该位置的元素自减
public final int getAndAdd(int i, int delta) //获取 index=i 位置元素的值,并加上预期的值
boolean compareAndSet(int i, int expect, int update) //如果输入的数值等于预期值,则以原子方式将 index=i 位置的元素值设置为输入值(update)
public final void lazySet(int i, int newValue)//最终 将index=i 位置的元素设置为newValue,使用 lazySet 设置之后可能导致其他线程在之后的一小段时间内还是可以读到旧的值。
引用类型原子类
基本类型原子类只能更新一个变量,如果需要原子更新多个变量,需要使用 引用类型原子类。
AtomicReference:引用类型原子类AtomicStampedReference:原子更新带有版本号的引用类型。该类将整数值与引用关联起来,可用于解决原子的更新数据和数据的版本号,可以解决使用 CAS 进行原子更新时可能出现的 ABA 问题。-
- 解决修改过几次
AtomicMarkableReference:原子更新带有标记的引用类型。该类将 boolean 标记与引用关联起来-
- 解决是否修改过,它的定义就是将标记戳简化为true/false,类似于一次性筷子
public class AtomicMarkableReferenceDemo {static AtomicMarkableReference markableReference = new AtomicMarkableReference(100, false);public static void main(String[] args) {new Thread(() -> {boolean marked = markableReference.isMarked();System.out.println(Thread.currentThread().getName() + "\t" + "默认标识: " + marked);//t1 默认标识: falsetry {TimeUnit.SECONDS.sleep(1);} catch (InterruptedException e) {e.printStackTrace();}markableReference.compareAndSet(100, 1000, marked, !marked);//t2 默认标识: false}, "t1").start();new Thread(() -> {boolean marked = markableReference.isMarked();System.out.println(Thread.currentThread().getName() + "\t" + "默认标识: " + marked);//t2 t2线程CASResult:falsetry {TimeUnit.SECONDS.sleep(2);} catch (InterruptedException e) {e.printStackTrace();}boolean b = markableReference.compareAndSet(100, 2000, marked, !marked);System.out.println(Thread.currentThread().getName() + "\t" + "t2线程CASResult:" + b);System.out.println(Thread.currentThread().getName() + "\t" + markableReference.isMarked());//t2 trueSystem.out.println(Thread.currentThread().getName() + "\t" + markableReference.getReference());//t2 1000}, "t2").start();}
}
对象的属性修改类型原子类
如果需要原子更新某个类里的某个字段时,需要用到对象的属性修改类型原子类。
AtomicIntegerFieldUpdater:原子更新整形字段的更新器AtomicLongFieldUpdater:原子更新长整形字段的更新器AtomicReferenceFieldUpdater:原子更新引用类型里的字段的更新器
要想原子地更新对象的属性需要两步。第一步,因为对象的属性修改类型原子类都是抽象类,所以每次使用都必须使用静态方法 newUpdater()创建一个更新器,并且需要设置想要更新的类和属性。第二步,更新的对象属性必须使用 public volatile 修饰符。
上面三个类提供的方法几乎相同,所以我们这里以 AtomicIntegerFieldUpdater为例子来介绍。
AtomicIntegerFieldUpdater 类使用示例 :
import java.util.concurrent.atomic.AtomicIntegerFieldUpdater;public class AtomicIntegerFieldUpdaterTest {public static void main(String[] args) {AtomicIntegerFieldUpdater<User> a = AtomicIntegerFieldUpdater.newUpdater(User.class, "age");User user = new User("Java", 22);System.out.println(a.getAndIncrement(user));// 22System.out.println(a.get(user));// 23}
}class User {private String name;public volatile int age;public User(String name, int age) {super();this.name = name;this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}}输出结果:
22
23原子操作增强类原理深度解析
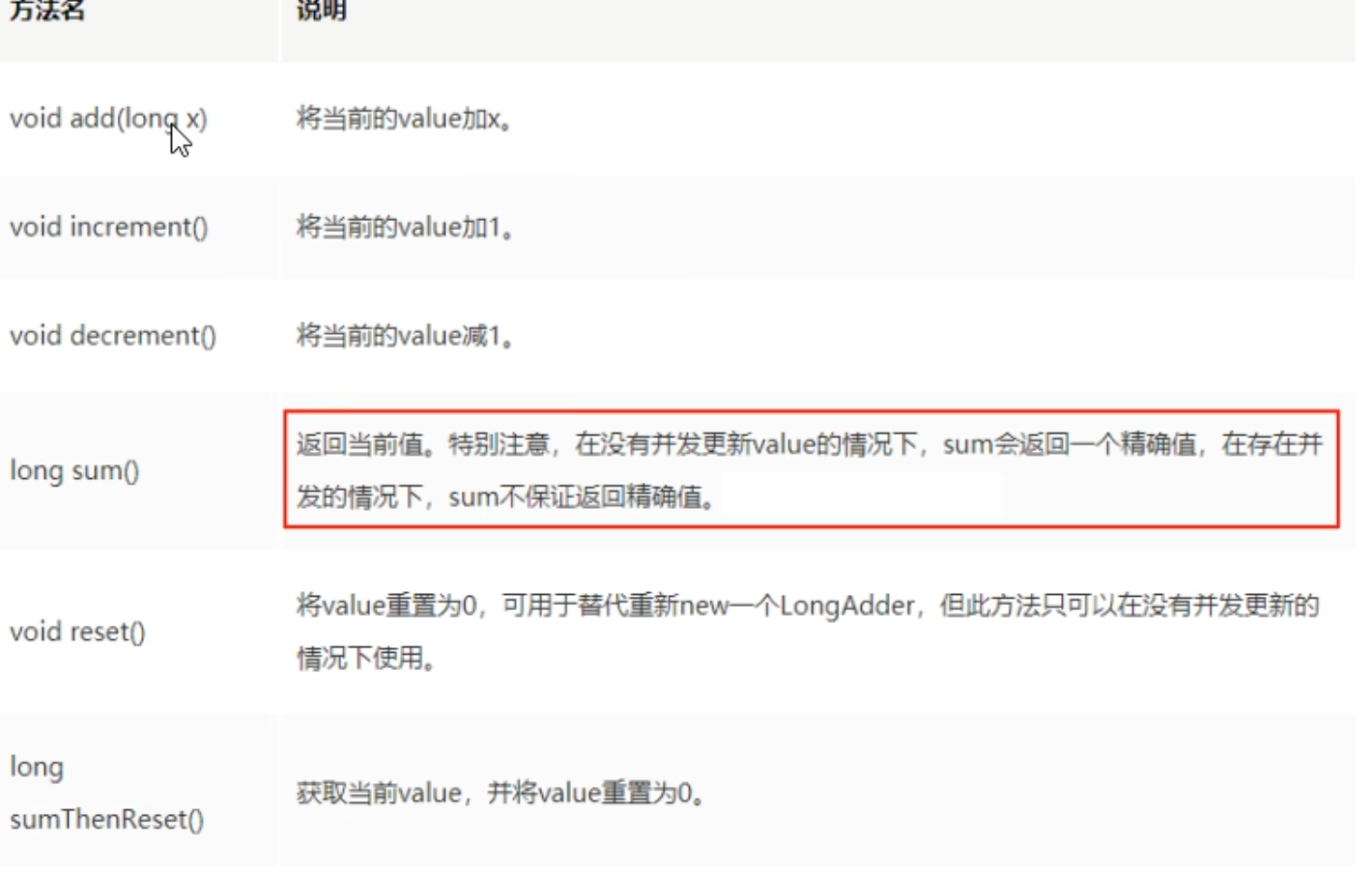
DoubleAccumulator:一个或多个变量,它们一起保持运行double使用所提供的功能更新值DoubleAdder:一个或多个变量一起保持初始为零double总和LongAccumulator:一个或多个变量,一起保持使用提供的功能更新运行的值long ,提供了自定义的函数操作LongAdder:一个或多个变量一起维持初始为零long总和(重点),只能用来计算加法,且从0开始计算
常用API
源码、原理分析
- 架构
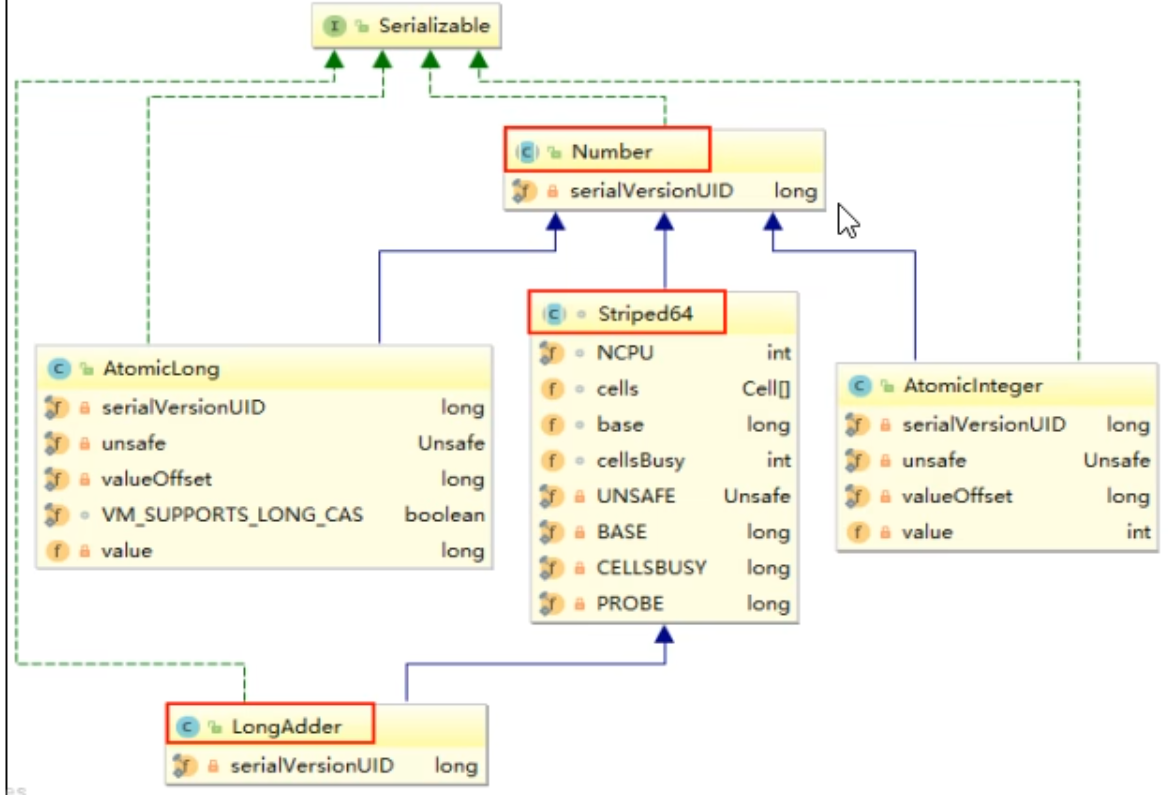
- 原理(LongAdder为什么这么快)
-
- 如果是JDK8,推荐使用LongAdder对象,比AtomicLong性能更好(减少乐观锁的重试次数)
- LongAdder是Striped64的子类
- Striped64的基本结构
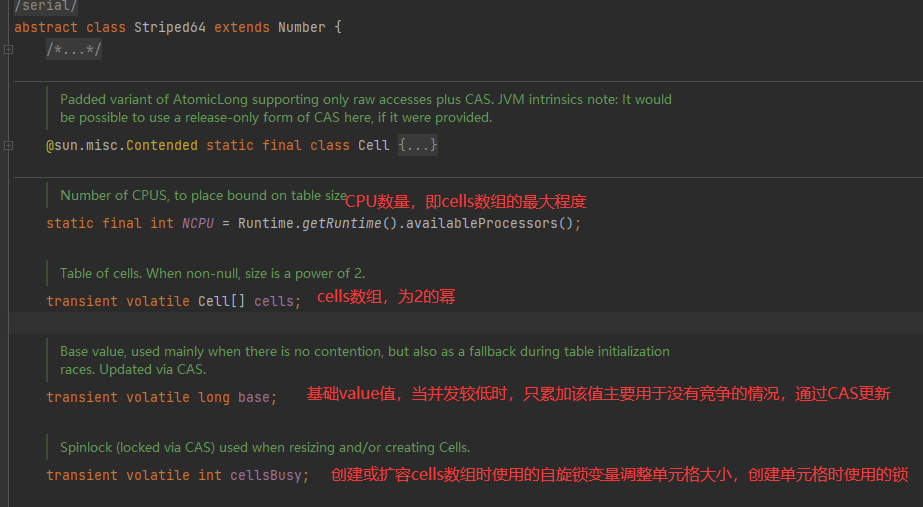

-
- cell:是java.util.concurrent.atomic下Striped64的一个内部类
- LongAdder为什么这么快
-
-
- LongAdder的基本思路就是分散热点,将value值分散到一个Cell数组中,不同线程会命中到数组的不同槽中,各个线程只对自己槽中的那个值进行CAS操作,这样热点就被分散了,冲突的概率就小很多,如果要获取真正的long值,只要将各个槽中的变量值累加返回
- sum()会将所有的Cell数组中的value和base累加作为返回值,核心的思想就是将之前AtomicLong一个value的更新压力分散到多个value中去,从而降级更新热点。
- 内部有一个base变量,一个Cell[]数组
-
-
-
-
- base变量:低并发,直接累加到该变量上
- Cell[]数组:高并发,累加进各个线程自己的槽Cell[i]中
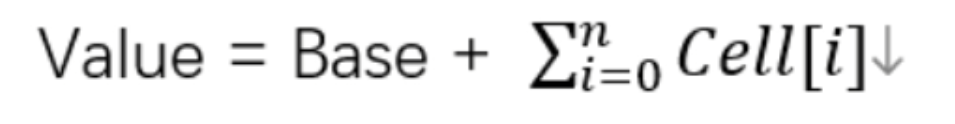
-
-
-
源码解读深度分析
-
- LongAdder在无竞争的情况下,跟AtomicLong一样,对同一个base进行操作,当出现竞争关系时则是采用化整为零分散热点的做法,用空间换时间,用一个数组cells,将一个value值拆分进这个数组cells。多个线程需要同时对value进行操作的时候,可以对线程id进行hash得到hash值,再根据hash值映射到这个数组cells的某个下标,再对该下标所对应的值进行自增操作。当所有线程操作完毕,将数组cells的所有值和base都加起来作为最终结果
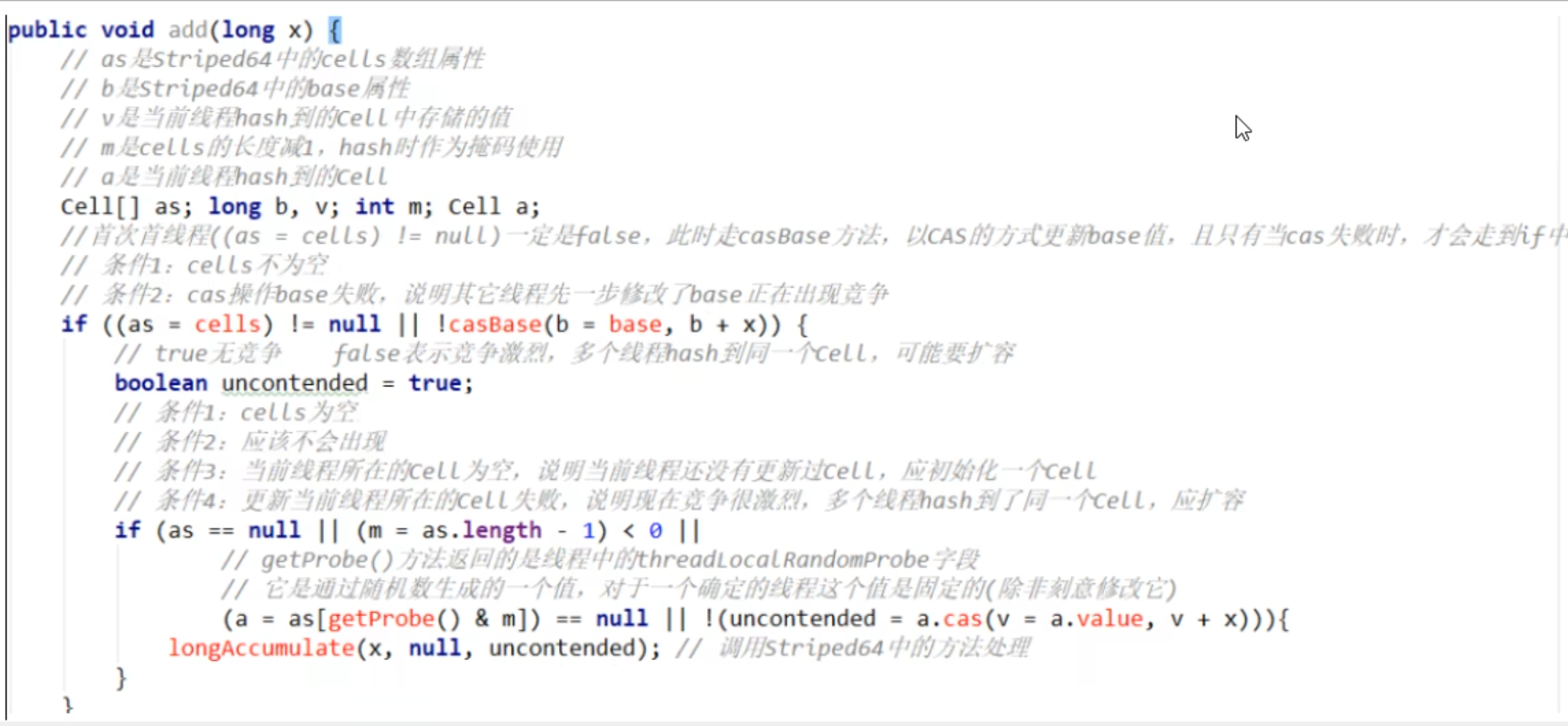
- add(1L)
-
-
- 1 如果Cells表为空,尝试用CAS更新base字段,成功则退出
- 2 如果Cells表为空,CAS更新base字段失败,出现竞争,uncontended为true,调用longAccumulate(新建数组)
- 3 如果Cells表非空,但当前线程映射的槽为空,uncontended为true,调用longAccumulate(初始化)
- 4 如果Cells表非空,且当前线程映射的槽非空,CAS更新Cell的值,成功则返回,否则,uncontended设为false,调用longAccumulate(扩容)
-
-
-
longAccumulate
-
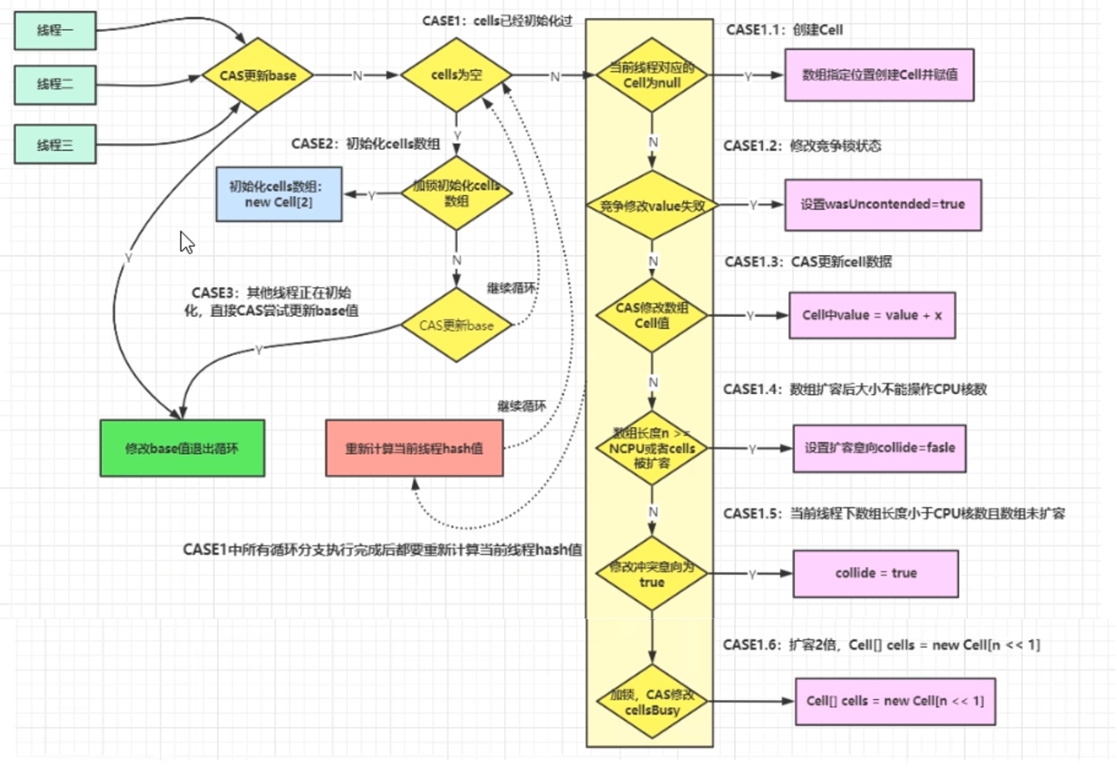
-
sum
-
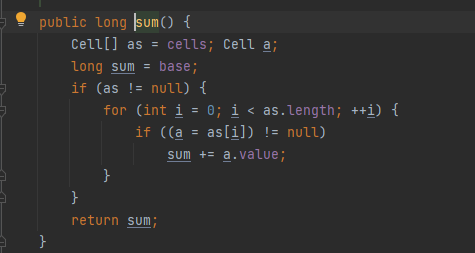
■ sum()会将所有Cell数组中的value和base累加作为返回值。核心思想就是将之前AtomicLong一个value的更新压力分散到多个value中去,从而降级更新热点。
■ sum执行时,并没有限制对base和cells的更新,所以LongAdder不是强一致性的,它是最终一致性的,对cell的读取无法保证是最后一次写入的值,所以在没有并发的场景下,可以获得正确的结果。
-
使用总结
-
-
-
- AtomicLong线程安全,可允许一些性能损耗,要求高精度时可使用,保证精度,多个线程对单个热点值value进行了原子操作-----保证精度,性能代码
- LongAdder当需要在高并发场景下有较好的性能表现,且对值得精确度要求不高时,可以使用,LongAdder时每个线程拥有自己得槽,各个线程一般只对自己槽中得那个值进行CAS操作—保证性能,精度代价
-
-
总结
-
- AtomicLong
-
-
- 原理:CAS+自旋
- 场景:低并发下的全局计算,AtomicLong能保证并发情况下计数的准确性,其内部通过CAS来解决并发安全性问题
- 缺陷:高并发后性能急剧下降----AtomicLong的自旋会成为瓶颈(N个线程CAS操作修改线程的值,每次只有一个成功过,其他N-1失败,失败的不停自旋直至成功,这样大量失败自旋的情况,一下子cpu就打高了)
-
-
- LongAdder
-
-
- 原理:CAS+Base+Cell数组分散-----空间换时间并分散了热点数据
- 场景:高并发下的全局计算
- 缺陷:sum求和后还有计算线程修改结果的话,最后结果不够准确
-


















)
![[EFI]Dell Latitude-7400电脑 Hackintosh 黑苹果efi引导文件](http://pic.xiahunao.cn/[EFI]Dell Latitude-7400电脑 Hackintosh 黑苹果efi引导文件)