写在前面的话:本文内容有对应50分钟视频讲解,有兴趣可以访问PG与开发者共舞。
很多数据库的对比的活动都是基于数据库本身的一些的底层的功能以及纯数据库方面的对比,等等。更多方面数据库是要为应用来服务的,而生产应用的大部分都是与程序员有关的,怎么服务于程序员,提高程序员的舒适感,也是一个重要的话题,提高了程序员的工作效率,减少代码量,将逻辑下移,减少程序中的BUG,这是一个数据库可以做到的,不是每个企业都是互联网企业,不是每个业务都是高并发的业务,我们有大量复杂业务,如果将业务逻辑全部都在程序端实现,势必会增加程序员的劳动力,开发周期延长,后续的程序的灵活性也会受到部分限制。

所以这次的课,主要是面对程序员,服务于程序员,有一部分老板也可能对降低成本,尤其是开发的成本很感兴趣,另外可能也有部分纯软件开发企业会对后续软件的维护,尤其是数据库的维护,感兴趣,因为复杂的数据库高可用结构,尤其分库分表,限制了纯开发企业的开发软件的方式和后期与签约企业的运维维护方面的难度。
那么下面我们就从几点来阐述,PG到底和开发者是一个什么关系,到底开发者在使用PG 能不能得到好处的问题。

以下单纯以服务于开发人员和客户的观点进行本次课程的阐述,并且会辅以一些例子来说明。

我相信在看到上面的图上的文字,有一部分非互联网的开发人员,已经坐不住的,但实际上是这样的,互联网企业使用的数据库的要求很多,当然这也是由于数据库的原理造成的问题,但需要开发人员来买单。
在软件开发中,最让开发人员头疼的问题之一,就是字段的预留的大小的问题,某些大型的软件开发企业和互联网企业,在使用开源数据库中大多都会遇到这个问题,因为某些开源数据库的字段大小,与字段扩展和系统的性能是有"绑定“的关系, 有的时候都要进行一番“辩论”。所以每次开发和DBA之间的冲突就因为某些问题开始产生矛盾。互相都不理解,软件开发不理解对方为什么要严格的去扣一个字段的大小,254和512有差吗,如果以后扩展,还要麻烦,我为什么不能使用更大的字段,并且后续的开发中某些系统的对接表还要记住之间的字段大小匹配,我太难了,DBA方也有自己的理由,明明如果你使用了特别大的字段后,系统的性能会明显下降,为了系统性能我要求难道不对吗,后续你要扩展,我还要冒着风险给你加字段扩展字段,我容易吗?
所以矛盾就产生了,并且来来回回的审核和修改,让开发人员浪费时,DBA的时间也就这样浪费了,互相的成本都很大。
PostgreSQL 在这方面和其他的开源数据库不太一样,甚至和商业数据库也不大一样,他的宽容度和包容度都比较大,在设计和开发软件的时候,不需要那么用力,我们以 postgresql 11 作为我们的例子,这是PG11版本中tip,由于原理的原因,在PG 中text 和 varchar之间是没有什么性能的差别的。(当然如果你往一个字段里面放置几十MB ,上百MB的情况,另当别论),所以在字段大小设计方面的问题的矛盾点就被化解了。

我们下面看一下一个建表的语句,

下面是从pg_admin中导出的语句

其实也是听到一个声音,就是PG在某些方面不如别的数据库在语句的写法上宽泛,实际上第一张图是手写的,如果不和你说明估计也不大能分的很清楚与某些其他数据库建表语句的明显区别,PG对语句的兼容性并不低,下图是从PG_ADMIN导出的语句,最终实际的PG标准的语句是这样的,这也明显的看出, PG的包容性。
说完PG的包容性,下面就的继续说PG的多态性,这个问题其实要从PG支持的数据类型来开始,PG支持的数据类型是相当的多。其中必然要谈的是一个种特殊的PG的数据类型 hstore

insert into hstore_test (id,name,history) values (1,'postgresql','from => "IBM_Research",origination => "inges",time => "1970"')
可以看到与JSON 格式对比,hstore 在处理比较随意的数据上。
SELECT name, history->'from' as history FROM hstore_test WHERE history->'origination' = 'inges';

这样的数据的处理方式,在实际的应用中是很有意义的,例如项目不稳定,客户经常没有准主意,一会一变,等等这样的情况,开发人员都可以用这样的模式来设计初期的项目中的数据存储,并且这样的的数据也可以保证系统的性能和查询的。不会对开发人员有过高的要求和特殊的规定。
其实这样的设计是一个数据库包容能力和多态性的一种体现,完全为项目和应用以及程序员的便利性去考虑,这也是一个数据库中适应结构化和半结构化数据,完全面向应用,降低开发的难度和成本做出的最大的诚意。
除此以外,PG对于程序员在模糊查询中的诚意也是满满的,我们都知道在开发一些系统中,用户的挑剔和项目经理以及需求经理对于开发人员来说,奇葩的需求,天天有,例如客户对一个系统中用户的留言点评,想进行一个查询,每天都要有,根据几个关键词来进行查找客户是否有不满意,或者意见的情况,当然这些词也是变化的,模糊查询中最让人讨厌的就是两边都是
%% 百分号。而PG 对于这样的情况是可以走索引进行查询的。那我们将这一块的内容和下边的索引的内容进行一个合并,通过两个例子来讲一讲。

结合上面的查询,开发人员对于索引的支持也是关心的,因可能由于某些逻辑或前期设计的问题,造成我们的数据表必须要有大量的索引来解决部分查询性能问题,例如某些表中的数据的一列只有几种类型,或者我们的表的数据量比较大,最后造成索引和表都特别大的情况,本身就带来性能问题
PG 本身在设计上,就考虑了这点,索引的类型很多, B-tree, Hash, GiST, SP-GiST, GIN and BRIN, 这里大部分数据库除了b-tree索引类型以外,其他的类型的索引是不支持,或许这里面的 GIST GIN Brin 等索引的类型大部分没有用过PG的人也是第一次听说。
那我们就来挑两个索引来说说 GIN 和 BRIN 索引,这两种索引都是有针对性的
1 模糊查询
我们先建立一个函数用来生成随机的数据
create or replace function gen_hanzi(int) returns text as $$ declare res text; begin if $1 >=1 then select string_agg(chr(19968+(random()*20901)::int), '') into res from generate_series(1,$1); return res; end if; return null; end; $$ language plpgsql strict;
insert into text_search (address) select gen_hanzi(10) from generate_series(1,1000000);

插入200万条数据,随机产生汉字。
create index CONCURRENTLY idx_ts_address on text_search using gin (address gin_trgm_ops);
创建相关GIN 索引来应用trgm 函数


通过上面的操作,我想大家已经对于PG的 GIN 索引在模糊查询中的实力有所了解,这也是四大数据库中,其他的数据库都不能快速简便解决的问题,所以开发人员如果遇到这样的需求,在头痛的时候,可以问自己一句,为什么没有用PG,浪费本应该节省下的时间和成本。因为其他的数据库要做这样的事情,是需要其他的附加的其他的数据库来完成,例如ES, 这样的情况为了一个字段,一个奇葩需求而要付出的代价就被PG 轻松的化解了。
当然这还不是最神奇的,我们还有一些应用,表的数据量很大,同时也要建立索引,而索引随着表的变大,就会变得越来越大,这就是b+tree的问题,而PG中的BRIN索引就是为了解决这样的问题而来的,怎么能更减小索引,并且与btree 的性能相近,与范围查询配合效果是很不错的.
我们用一个例子来证明一下
CREATE TABLE testtab (id int NOT NULL PRIMARY KEY,date TIMESTAMP NOT NULL, level INTEGER, msg TEXT)
INSERT INTO testtab (id, date, level, msg) SELECT g, CURRENT_TIMESTAMP + ( g || 'minute' ) :: interval, random() * 6, md5(g::text)
FROM generate_series(1,8000000) as g;

create index CONCURRENTLY idx_tss_brin on testtab using brin (date);
create index CONCURRENTLY idx_tss_btree on testtab (date);


在创建表和索引后,我们对比同样的功能,两个索引的大小相比,BTREE 是171MB 而 BRIN 索引只有 64kb.
这时估计很多人都会想,那效果一定大打折扣。那我们来看看,到底查询的性能会不会因为不同的索引而造成查询的性能特别大的差距。
explain analyze select * from public.testtab where date between '2020-03-23 06:15:01.41099' and '2020-03-23 06:19:01.41099';


通过上面两个查询的对比,实际上差距并不是很大,相对于他们的索引的大小来说。所以如果一个表中有很多范围类型的查询,就可以采取brin方式的索引,来降低大表对索引的空间的占用。
Brin索引,BRIN代表Block Range Index,BRIN是为处理非常大的表而设计,用一种块的概念,块范围是表中物理上相邻的一组页,对于每个块范围,索引将存储一些摘要信息。
BRIN索引可以通过常规的位图索引扫描来满足查询,索引所存储的摘要信息与查询条件一致,则返回每个范围内所有页面中的所有元组。查询执行程序负责重新检查这些元组,并丢弃那些不匹配查询条件的元组——换句话说,这些索引是有损的。由于BRIN索引非常小,与顺序扫描相比,扫描索引只增加了很少的开销,但是可以避免扫描已知不包含匹配元组的表的大部分数据。
说完索引,我们在来说说PG中的继承表,继承表这个概念我个人没有再ORACLE , SQL SERVER ,MYSQL ,或者其他类似 MONGODB 中听说过,当然也可能是我比较孤陋寡闻。PG的继承表是一种在开发中很有用的技术,举例,我们的开发中已经有一张很大的数量表,其中已经有一些信息,但这些信息是主营业务的,同时随着业务的发展,我们又有了一些其他的业务,虽然是其他的业务,但这些业务大部分是主营业务的扩展,需求方要求开发,那你要在这个业务中继续开发,如果有这样的要求,就一定会要你进行原表的信息添加,也就是加字段,这就要产生一个问题,字段添加在原表,这并不是每个开发愿意做的事情,尤其是高级的开发,一张表本身在设计初期其实已经根据当时的情况作了规划,怎么能在不影响原有的规划,并且又能继承原表的字段,产生一张新表,并在此基础上进行字段的添加修改,或者随着业务的变化,很可能会将这段抹去,这都是继承表能给开发者的恩赐。

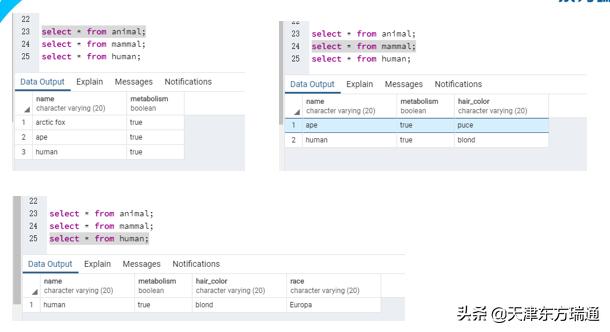
通过上图来看,实际上继承表的设计是很有意思的,如果在发散性的思维,可能会创造出更多的用法.
最后不同的程序员在以前使用不同的数据库,例如ORACLE MYSQL 或者SQL SERVER ,尤其某些程序员在使用完ORACLE 后,在使用其他的数据库时会产生一些疑问,别的数据库是instance 下有数据库,而ORACLE 是instance 下都是表,通过schema(用户)来对表进行访问的控制。
而PG 则是两种习惯都适应,你可以在PG数据库里面使用类似ORACLE 的schema 的经验来访问表,规划表,同时更可以使用MYSQL 熟悉的方式,将不同的表放置不同的数据库来进行分割。所以对于大部分程序要都是友好的。最后要阐述的是没有一种数据库在当今可以霸占一个企业,一个企业使用 N种数据库是很平常的事情。所以运维人员也需要有包容的心态来面对越来越多的曾经不熟悉的数据库的加入,增加企业的竞争力,降低成本。
本文对应视频讲解,点击浏览
以上内容由东方瑞通资深讲师 Austin原创,13年专业DBA经验,曾任互联网金融公司Senior DBA、500强制药企业Senior DBA,精通Mysql、PostgreSQL、Mongo DB、SQLServer。

)

















