今天一朋友反馈他们的一个数据库hang住了,通过ssh也不能登录系统,他们没有办法重启系统解决问题,现在想让我帮忙找出问题原因
分析awr得出
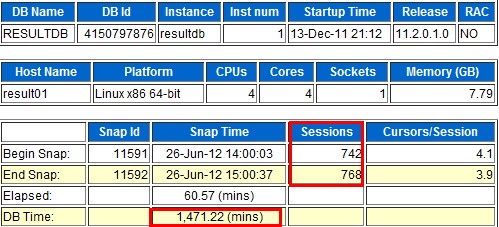
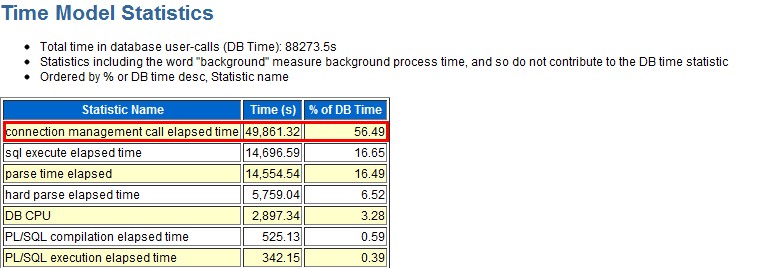
询问朋友,他们的库一般session保持在200个左右,这次突然飙升到750以上,属于异常情况
分析监听日志
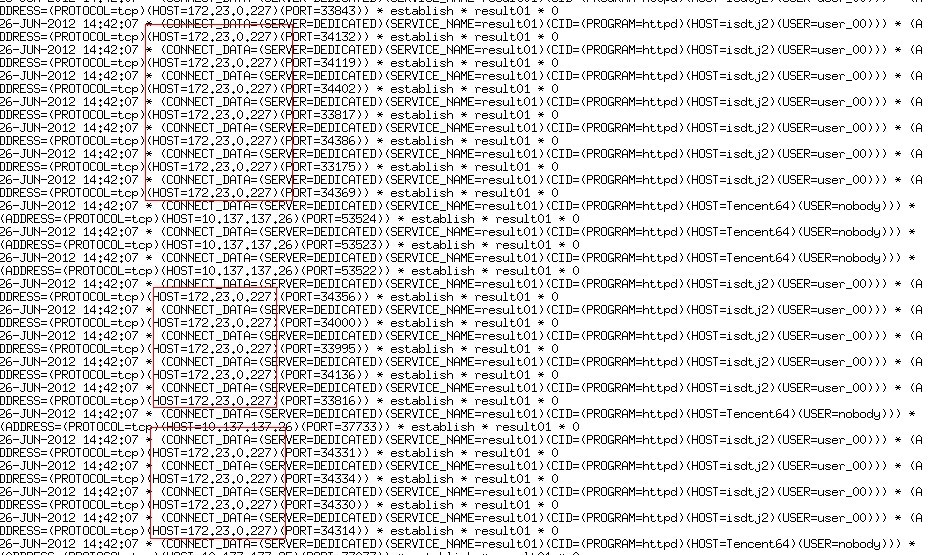
看到在截图的时间内,整体访问较频繁,某个ip访问异常频繁,通过这些信息,初步怀疑是用户的数据库内存使用完,导致系统数据库hang住.
查看系统日志
Jun 26 14:35:55 result01 kernel: [5613531.566617] Free swap = 0kB
Jun 26 14:35:55 result01 kernel: [5613531.566618] Total swap = 2104504kB
Jun 26 14:35:55 result01 kernel: [5613531.566620] Free swap: 0kB
Jun 26 14:35:55 result01 kernel: [5613531.591073] 2359296 pages of RAM
Jun 26 14:35:55 result01 kernel: [5613531.591074] 318236 reserved pages
Jun 26 14:35:55 result01 kernel: [5613531.591075] 73353 pages shared
Jun 26 14:35:56 result01 kernel: [5613531.591076] 529 pages swap cached
Jun 26 14:35:56 result01 kernel: [5613531.591079] Out of Memory: Kill process 8904 (oracle) score 891 and children.
Jun 26 14:35:56 result01 kernel: [5613531.591201] Out of memory: Killed process 8904 (oracle).
Jun 26 14:35:56 result01 kernel: [5613531.592280] oracle invoked oom-killer: gfp_mask=0x201d2, order=0, oomkilladj=0
通过这个日志看出系统内存和交换分区都使用完,因为内存不够,系统开始kill掉部分oracle进程.通过这些确定是系统内存使用完导致hang住可以理解.
分析hang住原因
为什么session意外的从200添增到750的时候,系统内存被使用完
cat /proc/meminfo
MemTotal: 8164240 kB
SwapTotal: 2104504 kB
PageTables: 69732 kB
HugePages_Total: 0
HugePages_Free: 0
HugePages_Rsvd: 0
Hugepagesize: 2048 kB
sga_target=3674210304
pga_aggregate_target=1732247552
从这里得出几个信息:
1.数据库总内存8g,swap配置2g
2.数据库未使用Hugepage
3.数据库设置sga和pga信息
内存参数估算
数据库总计占用内存为:(3674210304+1732247552)/1024/1024=5156M(pga可能未使用完,也可能超过)
结合实际sga_target=3674210304,会话数.
保守估计下Oracle进程占用的系统内存3674210304/(4*1024)*1.5*750/1024/1024=960M
估算如果使用Hugepage Oracle进程占用系统内存为:3674210304/(2*1024*1024)*1.5*750/1024/1024=1.9M
通过这里分析Oracle总占用内存为:5156+960=6116M
通过保守计算留给系统的内存大概为:1.8G左右
因为系统的其他操作,最终导致该系统内存耗完,系统和数据库hang住
总结说明
这是一个实实在在因为linux中因为未配置Hugepage,因为用户突增,导致系统内存消耗光,从而使得系统和数据库hang住的例子.
这个库因为sga不是非常大,所以Oracle占用系统内存不是高到离谱,如果sga配置为32g,1000个session,那就会占用12g的系统内存
通过这些可以看出在linux中配置Hugepage的优点:Hugepage不光是为了减轻cpu的负担,还可以减少系统内存的消耗;在没有极端的情况下,建议linux的数据库系统配置Hugepage.





![java正则表达式 分词_[Java]使用正则表达式实现分词](https://img-blog.csdnimg.cn/img_convert/48304ba5e6f9fe08f3fa1abda7d326ab.png)





![linux下sqlmap安装教程,(转)Sqlmap官网下载与安装教程[windows/linux版本]](https://img-blog.csdnimg.cn/img_convert/a4c26d1e5885305701be709a3d33442f.png)
