
下述所有数据可在下方二维码公众号回复: 数据大礼包 获得!!!

Fashion-MNIST图像数据集(200.4MB)
每个训练和测试样本都按照以下类别进行了标注:
| 标注编号 | 描述 |
|---|---|
| 0 | T-shirt/top(T恤) |
| 1 | Trouser(裤子) |
| 2 | Pullover(套衫) |
| 3 | Dress(裙子) |
| 4 | Coat(外套) |
| 5 | Sandal(凉鞋) |
| 6 | Shirt(汗衫) |
| 7 | Sneaker(运动鞋) |
| 8 | Bag(包) |
| 9 | Ankle boot(踝靴) |
CIFAR100数据集(161.3MB)
车辆数据集(车辆识别与分类)(62.5MB)
垃圾分类数据集
该数据集是图片数据,分为训练集85%(Train)和测试集15%(Test)。其中O代表Organic(有机垃圾),R代表Recycle(可回收)。
另一个垃圾分类数据集(40.9MB)
CIFAR10数据集(148MB)
GTSRB-德国交通标志识别图像数据(253.3MB)
手势识别数据库(1.1GB)
提出了手势识别数据库,该数据库由Leap Motion传感器获取的一组近红外图像组成。
该数据库由10个不同的手势(如上所示)组成,这些手势由10个不同的对象(5位男性和5位女性)执行。
情绪的面部表情(170MB+)
它是一个包含9名BPD(边缘型人格障碍)患者的数据库。
并非所有患者都接受了12次治疗采访。
所有患者都是女性。
治疗干预的持续时间因访谈而异。
数据说明
我们根据Paul Ekman和David Matsumoto的理论分析了7种情绪(Happy,Sad,Angry,Surprised,Scared,Disgusted,Contempt)的面部表情。
从每位患者的每次治疗访谈的视频记录中分析这些表达,每0.04秒分析一次,即每秒进行25次测量。
并非所有患者都能覆盖所有12个访谈,但会议的年表按照对治疗的帮助顺序出现。
因此,我们希望看到的是这些患者的适应力或情绪调节。
中性对Contemp的情绪在0到1的强度中被评估。
情绪效价从0到1被评估为正面情绪,0到-1是负面情绪。唤醒评估从0到1。
枪支目标检测(2.4MB)
一共有333张图像,对于每张图像,都标注了其中枪支的所在位置。图像不是单一尺寸的,它们有不同的长宽大小。值得注意的是,一张图像里面可能有不止一把枪支!
数据收集基于来自flickr,google图像和yandex图像的抓取数据。
人脸图像数据(294.1MB)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4k5GGey7-1603543383804)(https://cdn.kesci.com/upload/image/pzgl9tukkd.png)]
RMFD口罩遮挡人脸数据集(610.3MB)
中国交警手势数据集(1.8GB)
数据已划分为训练集和测试集,每个文件夹包含多个视频和csv文件;
视频里展示了中国交警的各种手势动作,同一序号名称的csv文件则对应了每帧视频交警的动作标签
场景分类数据集(105.9MB)
87种宝石图片数据(50.9MB)
验证码数据集(13.5MB)
硬币图像数据集(326.7MB)
LabelMe图像语义分割数据集(102.6MB)
数据集包含945张图片,图片已经注释了天空,建筑物,道路,人行道,植被,窗户,门和汽车等的标签信息,用于语义图像分割任务。
车牌识别数据集(62.8MB)
Biwi头姿势数据库(449.7MB)
数据集包含945张图片,图片已经注释了天空,建筑物,道路,人行道,植被,窗户,门和汽车等的标签信息,用于语义图像分割任务。
动物
Butterfly-200细粒度图像分类数据集(828MB)
数据集包含25,279张蝴蝶🦋图像,涵盖200个物种,116属,23个亚科和5个科的四个不同级别,用于细粒度图像分类研究
宠物图像数据集(783.5MB)
狗狗种类图像数据集(919.5MB)
黑猩猩图片数据集(604.4MB)
植物:
水稻叶子疾病图片集(36.7MB)
水稻叶子的三种疾病,即Bacterial leaf blight, Brown spot, and Leaf smut。
植物幼苗图片数据集
花卉识别数据集(224.9MB)
花卉图像分类
可食用野外植物数据集
叶片计数图像数据集(882.3MB)
气象:
飓风损害的卫星图像数据集(63MB)
从卫星图像理解云层数据集(42MB)
字符识别:
TibetanMNIST藏文手写数字数据集(53.2MB)
MNIST手写识别数据集(9.5MB)
Chars74K字符识别数据集(188.3MB)
信用卡卡面图像及标注数据(42.9MB)
卡片是信用卡的重要载体,我们希望能够通过拍照卡片来识别卡片上的信息。
本次竞赛希望参赛者独立设计模型,在拍照的卡面上识别卡面信息, 具体包括如下几点:
- 判断是否是招行信用卡
- 识别卡类别
- 识别卡片编号
- 识别卡片有效期
手写数学表达式识别(29MB)
CROHME,一个在线手写数学表达识别竞赛。本数据集提供了来自CROHME 2011、2012和2013竞赛的训练和测试数据
图片与单词匹配数据集(31.1MB)
密集不规则文本行数据集(353MB)
视觉文字识别数据集
HASY手写符号图片数据集(127.2MB)
麻将图片数据集(7.5MB)
医疗:
犬球虫病寄生虫图片集(18.1MB)
包含犬球虫病寄生虫的近350张图片,识别他们!
头部CT图像数据(24.4MB)
该数据集包含100个正常头部CT切片和100个头部其他出血的CT切片
肺部CT图像数据(529.0MB)
LUNA和2017年Kaggle数据科学碗等竞赛涉及处理并试图找到肺部CT图像中的病变。
为了很好地发现这些图像中的疾病,首先要很好地找到肺部是很重要的。
该数据集是具有手动分割的肺的2D和3D图像的集合。
心血管疾病预测(2.7MB)
深圳医院胸片检查掩膜图片数据集(19.8MB)
该数据集包含人工分割的肺部图像掩膜,在我们最近的论文中使用该肺部图像掩膜来描述肺分割技术,结合无损和有损数据增强功能,使我们能够在如此小的数据集(<1000张图像)上获得统计上可靠的预测。
肺部CT图像数据(529MB)
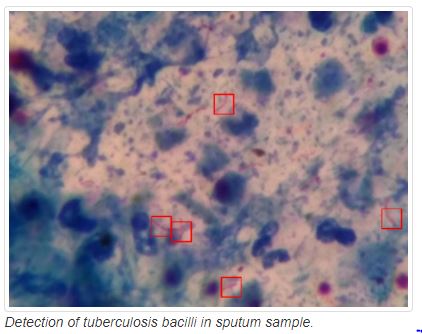
结核病图像数据集(456.8MB)
该数据集全部与结核有关,取自痰液样本。
它包含928个痰液图像以及3734个细菌的边界框。XML文件包含图像的边界框详细信息。参见示例图片:
行人识别:
行人检测数据集ETHZ(146MB)
行人重识别数据集Market-1501(145.7MB)
该数据集包括了1501个行人,751个行人用于训练,有750个人用于测试,共有3368个图像。 测试集中有19732张图像,训练集中有12936张图像。
行人重识别数据集RAiD(140.1MB)
行人重识别数据集prid_2011(1015.3MB)
汽车后视摄像头视角行人数据集(799.7MB)
数据集包含15个拍摄时段,每个拍摄时段在不同的日子以不同的场景进行。每个会话包含多个剪辑,持续时间从几秒钟到几分钟不等。数据集总共包含250个剪辑,总时长为76分钟,并带有超过20万个带注释的行人边界框。
两种类型的session。分阶段进行的场景主要包括行人以可控的方式在摄像机前的不同位置和方向行走,跨越后方警报或制动汽车功能的不同用例。在其余的时段中,车辆在公共道路或停车场中行驶,并捕获了偶然的行人。不同的位置包括:室内停车场,室外铺砌/沙地停车场,城市道路和私人车道。我们在不同的天气和光照条件下拍摄白天和黑夜的场景。有
——语音大类——
Mozilla语音数据集-中文(358.2MB)
2000个英语读数字的录音(8.9MB)
上述所有数据可在下方二维码公众号回复: 数据大礼包获得!!!
所有的数据,在下面二维码扫码关注就能免费领取~
一 [NLP] 50万闲聊语料
公众号回复:闲聊
二 密集人群检测
公众号回复:密集人群检测
三疲劳驾驶数据集
公众号回复:pilao
四 文本生成与文本分类数据集
公众号回复:文本生成
五 实体命名识别
公众号回复:实体命名识别
六 人脸识别
公众号回复:人脸识别
七 车牌数据集
公众号回复:车牌
八 自动驾驶数据集
公众号回复:自动驾驶
九 异常行为数据集
公众号回复:异常行为
十 人脸关键点检测
公众号回复:人脸关键点检测
十一 高空车辆数据集
公众号回复:高空车辆
十二 安全帽+头盔+算法
公众号回复:头盔
十三 吸烟手势
公众号回复:吸烟手势
十四 香烟数据+算法
公众号回复:香烟
十五 10万烟雾数火灾数据
公众号回复:烟雾
十六 十万口罩数据集
公众号回复:口罩
十七 车道线数据
公众号回复:车道线
十八 车辆识别数据+模型
公众号回复:车辆识别
十九 车辆检测数据集
公众号回复:车辆检测
二十 无人机检测
公众号回复:无人机
二十一 X光安检
公众号回复:安检
二十二 【语音识别】婴儿啼哭
公众号回复:婴儿啼哭
二十三 老鼠检测
公众号回复:老鼠检测
二十四 工业缺陷检测
包含:纺织布缺陷检测;
金属钢板缺陷检测;
混凝土缺陷检测;
PCB板缺陷检测;
太阳能板缺陷检测;
等等
公众号回复:工业缺陷检测
二十五 交通卡口 车辆计数
公众号回复:车辆计数
二十六 电动车
公众号回复:电动车
二十七 医疗ct
公众号回复医疗ct
二十八 YOLOv3 口罩检测
公众号回复:v3口罩
二十九 漂流物检测
公众号回复:漂流物
三十 昆虫检测
公众号回复:昆虫
**三十一 点赞关注转发~
你不知道的数据集合)
![[PyQt5]点击主窗口弹出另一个窗口](http://pic.xiahunao.cn/[PyQt5]点击主窗口弹出另一个窗口)


深入理解BIO、NIO、AIO)
)


反射和动态代理(JDK Proxy和Cglib))
)





Java虚拟机组成详解)



