k8s-自动横向伸缩pod 与节点
简述
我们可以通过调高ReplicationController、 ReplicaSet、 Deployment等可伸缩资源的rep让cas字段, 来手动实现pod中应用的横向扩容。 我们也可以通过增加pod容器的资源请求和限制来纵向扩容pod (尽管目前该操作只能在pod创建时, 而非运行时进行)。 虽然如果你能预先知道负载何时会飘升, 或者如果负载的变化是较长时间内逐渐发生的, 手动扩容也是可以接受的, 但指望靠人工干预来处理突发而不可预测的流量增长, 仍然不够理想。
Kubemetes可以监控你的pod, 并在检测到CPU使用率或其他度量增长时自动对它们扩容。 如果Kubemetes运行在云端基础架构之上, 它甚至能在现有节点无法承载更多pod之时自动新建更多节点。
pod的横向自动伸缩
横向pod自动伸缩是指由控制器管理 的pod副本数量的自动伸 缩。 它由Horizontal控制器执行, 我们通过创建 一个HorizontalpodAutoscaler C HPA)资源来启用和配置Horizontal控制器。 该控制器周期性检查pod度量, 计算满足HPA资源所配置的目标数值所需的副本数量, 进而调整目标资源(如Deployment、ReplicaSet、 ReplicationController、StatefulSet等)的replicas字段。
自动伸缩过程
自动伸缩的过程可以分为三个步骤:
• 获取被伸缩资源对象所管理的所有pod度量。
• 计算使度量数值到达(或接近)所指定目标数值所需的pod数量。
• 更新被伸缩资源的replicas字段。
下面我们就来看看这三个步骤。
获取pod度量
Autoscaler本身并不负责采集pod度量数据 , 而是从另外的来源获取。 正如之前提到的, pod与节点度量数据是由运行在每个节点的kubelet之上, 名为cAdvisor的agent采集的;这些数据将由 集群级的组件Heapster聚合。 HPA控制器向Heapster 发起REST调用来获取 所有pod度量数据。
计算所需的 pod 数量
一 旦Autoscaler获得了它所调整的资源(Deployment、 ReplicaSet、ReplicationController或State伈!Set)所辖pod的全部度量, 它便可以利用这些度量计算出所需的副本数量。 它需要计算出一个合适的副本数量, 以使所有副本上度量的平均值尽量接近配置的目标值。 该计算的输入是一组pod度量(每个pod可能有多个), 输出则是一个整数(pod副本数量)。
当Autoscaler配置为只考虑单个度量时, 计算所需 副本数很简单。 只要将所有pod的度量求和后除以HPA资源上配置的目标值, 再向上取整即可。 实际的计算稍微复杂一些; Autoscaler还保证了度量数值不稳定、 迅速抖动时不会导致系统抖动(thrash)。
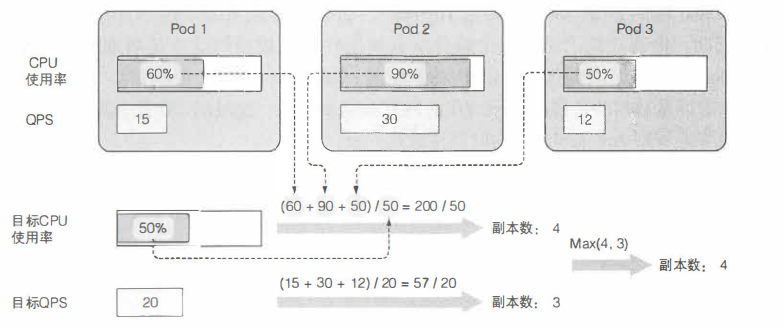
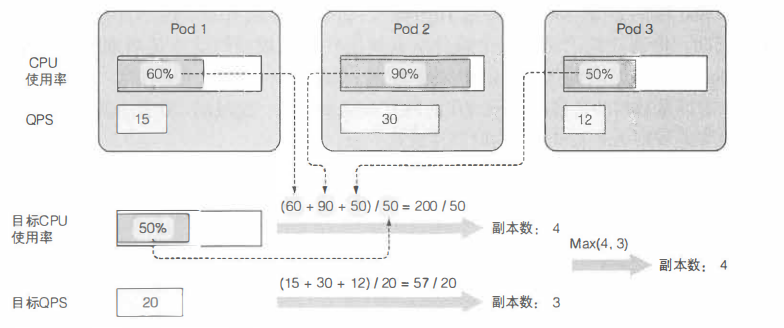
基于多个pod度量的自动伸缩(例如: CPU使用率和每秒查询率[QPS])的计算也并不复杂。 Autoscaler单独计算每个度量的副本数, 然后取最大值(例如:如果需要4个pod达到目标CPU使用率, 以及需要3个pod来达到目标QPS, 那么Autoscaler 将扩展到4个pod)。 下图展示了这个示例。
更新被伸缩资源的副本数
自动伸缩操作的最后 一 步是更新被伸缩资源对象(比如ReplicaSet)上的副本数字段 然后让ReplicaSet控制器负责启动更多pod或者删除多余的pod。Autoscaler控制器通过scale子资源来修改被伸缩资源的rep巨cas字段。 这样Autoscaler不必了解它所管理资源的细节,而只需要通过Scale子资源暴露的界面,就可以完成它的工作了,如下图

HPA只对Scale子资源进行更改 。
这意味着只要API服务器为某个可伸缩资源暴露了Scale子资源, Autoscaler即可操作该资源。 目前暴露了Scale子资源的资源有:

View Code
了解整个自动伸缩过程
从pod指向 cAdvisor, 再经过Heapster , 而最终到达HPA的箭头代表度量数据的流向。 值得注意的是, 每个组件从其他组件拉取数据的动作是周期性的 (即cAdvisor用 一个无限循环从pod中采集数据; Heapster与HPA控制器亦是如此)。这意味着度量数据的传播与相应动作的触发都需要相当一段时间, 不是立即发生的。接下来实地观察Autoscaler行为时要注意这一点。
基于CPU使用率进行自动伸缩
可能你最想用以指导自动伸缩的度量就是pod中进程的CPU使用率了。 假设你用几个pod来提供服务, 如果它们的CPU使用率达到了100%, 显然它们已经扛不住压力了, 要么进行纵向扩容(scale up), 增加它们可用的CPU时间, 要么进行横向扩容(scale out), 增加pod 数量 。 因为本章谈论的是HPA, 我们仅仅关注横向扩容。
这么一来, 平均CPU使用率就应该下降了。因为CPU使用通常是不稳定的, 比较靠谱的做法是在CPU被压垮之前就横向扩容一—可能平均负载达到或超过80%的时候就进行扩容。 但这里有个问题, 到底是谁的80%呢。
就 Autoscaler而言, 只有pod的保证CPU用量(CPU请求)才与确认pod的CPU使用有关。 Autoscaler对比pod的实际CPU使用与它的请求, 这意味着你需要给被伸缩的pod设置CPU请求,不管是直接设置还是通过LimitRange对象间接设置,这样Autoscaler才能确定CPU使用率。
基于CPU使用率创建HPA


创建deployment 资源 apiVersion: extensions/vlbetal kind: Deployment metadata:name: kubia spec: replicas: 3 #手动设置(初始)想要的副本数为3template: metadata:name: kubia labels: app: kubia spec: containers: - image: luksa/kubia:vl name: nodejs resources: requests: cpu: 100m #每个pod请求100毫核的CPU创建了Deployment之后, 为了给它的pod 启用横向自动伸缩 , 需要创建一个 HorizontalpodAutoscaler (HPA)对象, 并把它指向该Deployment。$ kubectl autoscale deploymen七kubia --cpu-percent=30 --min=l --max=5这会帮你创建 HPA对象,并将叫作kubia的Deployment设置为伸缩目标。你还设置了pod的目标 CPU使用率为30%, 指定了副本的最小和最大数量。Autoscaler会持续调整副本的数量 以使CPU使用率接近30%, 但它永远不会调整到少于1个或者多于5个。提示:一定要确保自动伸缩的目标是Deployinent 而不是底层的 ReplicaSet。 这样才能确保预期的副本数量在应用更新后继续保持(记着 Deployment 会给每个应用版本创建一个 新的 ReplicaSet)。 手动伸缩也是同样的道理。

修改一个已有 HPA 对象的目标度量值
可能你 开始设置的目标值30 有点太低了,我们把它提高到 你将使用 kubectl edit 命令来完成这项工作。文本编辑器打开之后,把 targetAverageUtilization 字段改为 60,
正如大多数其他资源 样,在你修改资源之后, Autosca er 控制器会检测到这一变更,并执行相应动作 也可以先删除 HPA 资源再用新的值创建一个,因为删除HPA 资源只会禁用目标资源的自动伸缩(本例中为 Deployment ,而它的伸缩规模会保持在删除资源的时刻 在你为 Deployment 创建一个新的 HPA 资源之后,自动伸缩过程就会继续进行
伸缩操作的最大速率
因为 Autosca 在单次扩容操作中可增加的副本数受到限制。如果当前副本数大于 2,Autoscaler 单次操作至多使副本数翻倍;如果副本数只有 2, Autoscaler 最多扩容到4个副
另外 Autoscaler 两次扩容操作之间的时间间隔是有限制。目前,只有当3钟内没有任何伸缩操作时才会触发扩容,缩容操作频率更低一- 5分钟 记住这点,这样你再看到度量数据很明显应该触发伸缩却没有触发的时候,就不会感到奇怪了。
基于内存使用进行自动伸缩
基于内存的自动伸缩比基于CPU 困难很多, 主要原因在于,扩容之后原有的pod 需要有办法释放内存。这只能由应用完成,系统无法代劳,系统所能做的只有杀死并重启应用,希望它能比之前少占用 些内存;但如果应用使用了跟之前多的内存 Autoscaler 就会扩容、扩容 再扩容到达到HPA资源上配置的最大pod 数量,显然没有人想要这种行为。基于内存使用的自动伸缩在 Kubernetes 1.8 中得到支持,配置方法与基于 CPU 的自动伸缩完全相同 。
基于其他自定义度量进行自动伸缩


... spec: maxReplicas: 5 metrics: - type: Resourceresource: name: cputargetAverageUtilization:30 ...
如上所示, metrics 字段允许你定义多个度量供使用。在代码清单中使用了单个度量。每个条目都指定相应度量的类型一一本例中为一个 Resource 度量。可以在HPA 对象中使用三种度量:
定义 metric 类型
使用情况会被监控的资源
资源的 目标使用量
Resurce 量类型
Resource 类型使 autoscaler 基于一个资源度量做出自动伸缩决策,在容器的资源请求中指定的那些度量即为一例 。这一类型的使用方式我们己经看过了,所以重点关注另外两种类型。
pods 度量类型
Pods 类型用来引用任何其他种类的(包括自定义的)与 pod 直接相关的度量。每秒查询次数 CQPS ),或者消息队列中的消息数量(当消息队列服务运行在 pod 之中 )都属于这种度量。要配置autoscaler 使用 pod QPS 度量, HPA 对象的 metrics 字段中就需要包含以下代码清单所示的条目。


... spec: metrics: - type: Podsresource: metricName: qpstargetAverageValue:100 ...

代码清单中的示例配置 Autoscaler ,使该 HPA 控制的 ReplicaSet (或其他)控制器下所辖 pod 的平均 QPS 维持 100 的水平。
Object 度量类型
Object 类型被用来让 Autoscaler 基于并非直接与 pod 关联的度量来进行伸缩,比方说,你可能希望基于另一集群对象 ,比如 Ingress 对象来伸缩你的 pod。 这度量可能是代码清单 15.8 中的 QPS ,也可能是平均请求延迟,或者完全是不相干的其他东西。与此前的例子不同,使用 object 度量类型时, Autoscaler 只会从这单个对象中获取单个度量数据;在此前的例子中, Autoscaler 需要从所有下属 pod 中获取度量,并使用它们的平均值。你需要在HPA对象的定义中指定目标对象与目标值。如下所示:

View Code
该例中 HPA 被配置为使用 Ingress 对象 frontend 的 latencyMillis 度量,目标值为 20 。HPA 会监控该 Ingress 度量,如果该度量超过了目标值太多autoscaler 便会对 kubia Deployment 资源进行扩容了。
确定哪些度量适合用于自动伸缩
不是所有度量都适合作为自动伸缩的基础。正如之前提到的, pod 中容器的内存占用并不是自动伸缩的一个好度量。如果增加副本数不能导致被观测度量平均值的线性(或者至少接近线性)下降 ,那么 autoscaler 就不能正常工作比方说,如果你只有 pod 实例,度量数值为 X,这时 autoscaler 扩容到了2个副本,度量数值就需要落在接近 X/2 位置 每秒查询次数 QPS )就是这么一种自定义度量,对 we 应用而 即为应用每秒接收的请求数。增大副本数总会导致QPS 成比例下降,因为同样多的请求数现在被更多数量的 pod 处理了。在你决定基于应用自有的自定义度量来伸缩它之前,一定要思考 pod 数量增加或减少时,它的值会如何变化。
缩容到0个副本
HPA 目前不允许设置 minReplicas 字段为0 ,所以 autoscaler 永远不会缩容到0个副本,即便 pod 什么都没做也不会。允许 pod 数量缩容到0可以大幅提升硬件利用率:如果你运行的服几个小时甚至几天才会收到1次请求,就没有道理留着它们一直运行,占用本来可以给其他服务利用的资源:然而一旦客户端请求进来了,你仍然还想让这些服务马上可用。
这叫空载( idling )与解除空载 (un-idling ),即允许提供特定服务的 pod 被缩容量到0 副本。在新的请求到来时,请求会先被阻塞,直到 pod 被启动,从而请求被转发到新的 pod 为止。Kubernetes 目前暂时没有提供这个特性,但在未来会实现。可 以检查 Kubernetes 文档来看看空载特性有没有被实现。
pod 的纵向自动伸缩
横向伸缩很棒,但并不是所有应用都能被横向伸缩,对这些应用而言,唯一选项是纵向伸缩一-给它们更多 CPU 和(或)内存。因为每个节点所拥有的资源通常都比单个 pod 请求的要多 ,我们应该几乎总能纵向扩容 pod ,因为 pod 的资源请求是通过 pod manifest 的字段配置的,纵向伸缩 pod 将会通过改变这些字段来实现。笔者这里说的是“将会”,因为目前还不可能改变己有 pod的资源请求和限制, 在笔者动笔之前(已经是一年多之前了),请参考Kubemetes文档来检查纵向pod自动伸缩实现了没有。
集群节点的横向伸缩
HPA在需要的时候会创建更多的pod实例。 但万一所有的节点都满了, 放不下更多pod了, 怎么办?显然这个问题并不局限于Autoscaler创建新pod实例的场景。即便是手动创建pod, 也可能碰到因为资源被已有pod使用殆尽, 以至于没有节点能接收新pod的清况。
Kubernetes支持在需要时立即自动从云服务提供者请求更多节点。 该特性由 Cluster Autoscaler执行。
Cluster Autoscaler介绍
Cluster Autoscaler负责在由于节点资源不足, 而无法调度某pod到已有节点时,自动部署新节点。它也会在 节点长时间使用率低下的情况下下线节点。
从云端基础架构请求新节点
如果在 一个pod被创建之后,Scheduler无法将其调度到任何一个已有 节点,一个新节点就会被创建。ClusterAutoscaler会注意此类pod, 并请求云服务提供者启动 一个新节点。但在这么做之前,它会检查新节点有没有可能容纳这个(些) pod,毕竟如果 新节点本来就不可能容纳它们,就没必要启动这么一个节点了。
云服务提供者通常把相同规格(或者有相同特性)的节点聚合成组。因此Cluster Autoscaler不能单纯地说 “给我多一个节点”,它还需要指明节点类型。Cluster Autoscaler 通过检查可用的节点分组来确定是否有至少一种节点类型能容纳未被调度的pod。如果只存在唯一一个此种节点分组,ClusterAutoscaler就可以增加节点分组的大小,让云服务提供商给分组中增加一个节点。但如果存在多个满足条件的节点分组,ClusterAutoscaler就必须挑一个最合适的。这里 “ 最合适” 的精确含义显然必须是可配置的。在 最坏的情况下,它会随机挑选一个。
新节点启动后,其上运行的Kubelet会联系API服务器,创建一个Node资源以注册该节点。从这一刻起,该节点即成为Kubernetes集群的一部分,可 以调度pod于其上了。
归还节点
当节点利用率不足时, Cluster Autoscaler 也需要能够减少节点的数目。 Cluster Autoscaler 通过监控所有节点上请求的CPU 与内存来实现这一点。 如果某个节点上
所有pod请求的CPU、 内存都不 到 50%, 该节点即被认定 为不再需要。这并不是决定是否要归还某 一 节点的唯一因素。 Cluster Autoscaler 也会检查是否有系统 pod (仅仅)运行在该节点上(这并不包括每个节点上都运行的服务, 比如 DaemonSet所部署的服务)。 如果节点上有系统 pod 在运行,该节点就不会被归还。
对非托管 pod, 以及有本地存储的pod 也是如此, 否则就会造成这些 pod 提供的服务中断。 换句话说, 只有当 Cluster Autoscaler 知道节点上运行的pod 能够重新调度到其他节点, 该节点才会被 归还。
当一个节点被选中下线, 它首先会被标记为不可调度, 随后运行其上的pod 将被疏散至其他节点。 因为所有这些 pod 都属于 ReplicaSet 或者其他控制器, 它们的替代 pod会被创建并调度到其他剩下的节点(这就是为何正被下线的节点要先标记为不可调度的原因)。
手动标记节点为不可调度、 排空节点


节点也可以手动被标记为不可调度并排空。 不涉及细节, 这些工作可用以下 kubectl 命令完成:• kubectl cordon <node> 标记节点为不可调度(但对其上的 pod不做任何事)。 • kubectl drain <node> 标记节点为不可调度, 随后疏散其上所有pod。两种情形下, 在你用 kubectl uncordon <node> 解除节点的不可调度状态之前, 不会有新 pod被调度到该节点。

限制集群缩容时的服务干扰
如果 一个节点发生非预期故障, 你不可能阻止其上的pod变为不可用;但如果一个节点被Cluster Autoscaler或者人类操作员主动下线,可以用一个新特性来确保下线操作不会干扰到这个节点上pod所提供的服务。一些服务要求至少保持一定数量的pod持续运行 , 对基于quorum的集群应用而言尤其如此。 为此, Kubemetes可以指定 下线等操作时需要保待的最少 pod数量,我们通过创建一个podDisruptionBudget资源的方式来利用这一特性。尽管这个资源的名称听起来挺复杂的, 实际上 它是最简单的Kubemetes资源
之一 。 它只包含 一个pod 标签选择器和 一个数字, 指定 最少需要维持运行的podYAML文件。
如果想确保你的kubiapod总有3个实例在运行(它们有 app=kubia这个标签), 像这样创建PodDisruptionBudget资源 :

$ kubectl create pdb kubia-pdb --selector=app=kubia --min-available=3 poddisruptionbudget "kubia-pdb" created
现在获取这个pod 的YAML文件, 如以下代码清单所示。

也可以用 一个百分比而非绝对数值来写minAvailable字段。 比方说,可以指定60%带app=kubia标签的pod应当时刻保持运行。注意从Kubemetes 1. 7开始podDismptionBudget资源也支持maxUnavailable。如果当很多pod不可用而想要阻止pod被剔除时,就可以用maxUnavailable字段而不是minAvailable。
关于这个资源, 没有更多要讲的了。 只 要它存在 ,Cluster Autoscaler与 kubectl drain 命令都会遵守它;如果疏散一个带有app=kubia标签的pod会导致它们的总数小于3, 那这个操作就永远不会被执行。比方说,如果总共有4个pod, minAvailable像例子中 一 样被设为3, pod 疏散过程就会挨个进行,待ReplicaSet控制器把被疏散的pod换成新的,才继续下一个。
简述
我们可以通过调高ReplicationController、 ReplicaSet、 Deployment等可伸缩资源的rep让cas字段, 来手动实现pod中应用的横向扩容。 我们也可以通过增加pod容器的资源请求和限制来纵向扩容pod (尽管目前该操作只能在pod创建时, 而非运行时进行)。 虽然如果你能预先知道负载何时会飘升, 或者如果负载的变化是较长时间内逐渐发生的, 手动扩容也是可以接受的, 但指望靠人工干预来处理突发而不可预测的流量增长, 仍然不够理想。
Kubemetes可以监控你的pod, 并在检测到CPU使用率或其他度量增长时自动对它们扩容。 如果Kubemetes运行在云端基础架构之上, 它甚至能在现有节点无法承载更多pod之时自动新建更多节点。
pod的横向自动伸缩
横向pod自动伸缩是指由控制器管理 的pod副本数量的自动伸 缩。 它由Horizontal控制器执行, 我们通过创建 一个HorizontalpodAutoscaler C HPA)资源来启用和配置Horizontal控制器。 该控制器周期性检查pod度量, 计算满足HPA资源所配置的目标数值所需的副本数量, 进而调整目标资源(如Deployment、ReplicaSet、 ReplicationController、StatefulSet等)的replicas字段。
自动伸缩过程
自动伸缩的过程可以分为三个步骤:
• 获取被伸缩资源对象所管理的所有pod度量。
• 计算使度量数值到达(或接近)所指定目标数值所需的pod数量。
• 更新被伸缩资源的replicas字段。
下面我们就来看看这三个步骤。
获取pod度量
Autoscaler本身并不负责采集pod度量数据 , 而是从另外的来源获取。 正如之前提到的, pod与节点度量数据是由运行在每个节点的kubelet之上, 名为cAdvisor的agent采集的;这些数据将由 集群级的组件Heapster聚合。 HPA控制器向Heapster 发起REST调用来获取 所有pod度量数据。
计算所需的 pod 数量
一 旦Autoscaler获得了它所调整的资源(Deployment、 ReplicaSet、ReplicationController或State伈!Set)所辖pod的全部度量, 它便可以利用这些度量计算出所需的副本数量。 它需要计算出一个合适的副本数量, 以使所有副本上度量的平均值尽量接近配置的目标值。 该计算的输入是一组pod度量(每个pod可能有多个), 输出则是一个整数(pod副本数量)。
当Autoscaler配置为只考虑单个度量时, 计算所需 副本数很简单。 只要将所有pod的度量求和后除以HPA资源上配置的目标值, 再向上取整即可。 实际的计算稍微复杂一些; Autoscaler还保证了度量数值不稳定、 迅速抖动时不会导致系统抖动(thrash)。
基于多个pod度量的自动伸缩(例如: CPU使用率和每秒查询率[QPS])的计算也并不复杂。 Autoscaler单独计算每个度量的副本数, 然后取最大值(例如:如果需要4个pod达到目标CPU使用率, 以及需要3个pod来达到目标QPS, 那么Autoscaler 将扩展到4个pod)。 下图展示了这个示例。
更新被伸缩资源的副本数
自动伸缩操作的最后 一 步是更新被伸缩资源对象(比如ReplicaSet)上的副本数字段 然后让ReplicaSet控制器负责启动更多pod或者删除多余的pod。Autoscaler控制器通过scale子资源来修改被伸缩资源的rep巨cas字段。 这样Autoscaler不必了解它所管理资源的细节,而只需要通过Scale子资源暴露的界面,就可以完成它的工作了,如下图

HPA只对Scale子资源进行更改 。
这意味着只要API服务器为某个可伸缩资源暴露了Scale子资源, Autoscaler即可操作该资源。 目前暴露了Scale子资源的资源有:

View Code
了解整个自动伸缩过程
从pod指向 cAdvisor, 再经过Heapster , 而最终到达HPA的箭头代表度量数据的流向。 值得注意的是, 每个组件从其他组件拉取数据的动作是周期性的 (即cAdvisor用 一个无限循环从pod中采集数据; Heapster与HPA控制器亦是如此)。这意味着度量数据的传播与相应动作的触发都需要相当一段时间, 不是立即发生的。接下来实地观察Autoscaler行为时要注意这一点。
基于CPU使用率进行自动伸缩
可能你最想用以指导自动伸缩的度量就是pod中进程的CPU使用率了。 假设你用几个pod来提供服务, 如果它们的CPU使用率达到了100%, 显然它们已经扛不住压力了, 要么进行纵向扩容(scale up), 增加它们可用的CPU时间, 要么进行横向扩容(scale out), 增加pod 数量 。 因为本章谈论的是HPA, 我们仅仅关注横向扩容。
这么一来, 平均CPU使用率就应该下降了。因为CPU使用通常是不稳定的, 比较靠谱的做法是在CPU被压垮之前就横向扩容一—可能平均负载达到或超过80%的时候就进行扩容。 但这里有个问题, 到底是谁的80%呢。
就 Autoscaler而言, 只有pod的保证CPU用量(CPU请求)才与确认pod的CPU使用有关。 Autoscaler对比pod的实际CPU使用与它的请求, 这意味着你需要给被伸缩的pod设置CPU请求,不管是直接设置还是通过LimitRange对象间接设置,这样Autoscaler才能确定CPU使用率。
基于CPU使用率创建HPA


创建deployment 资源 apiVersion: extensions/vlbetal kind: Deployment metadata:name: kubia spec: replicas: 3 #手动设置(初始)想要的副本数为3template: metadata:name: kubia labels: app: kubia spec: containers: - image: luksa/kubia:vl name: nodejs resources: requests: cpu: 100m #每个pod请求100毫核的CPU创建了Deployment之后, 为了给它的pod 启用横向自动伸缩 , 需要创建一个 HorizontalpodAutoscaler (HPA)对象, 并把它指向该Deployment。$ kubectl autoscale deploymen七kubia --cpu-percent=30 --min=l --max=5这会帮你创建 HPA对象,并将叫作kubia的Deployment设置为伸缩目标。你还设置了pod的目标 CPU使用率为30%, 指定了副本的最小和最大数量。Autoscaler会持续调整副本的数量 以使CPU使用率接近30%, 但它永远不会调整到少于1个或者多于5个。提示:一定要确保自动伸缩的目标是Deployinent 而不是底层的 ReplicaSet。 这样才能确保预期的副本数量在应用更新后继续保持(记着 Deployment 会给每个应用版本创建一个 新的 ReplicaSet)。 手动伸缩也是同样的道理。

修改一个已有 HPA 对象的目标度量值
可能你 开始设置的目标值30 有点太低了,我们把它提高到 你将使用 kubectl edit 命令来完成这项工作。文本编辑器打开之后,把 targetAverageUtilization 字段改为 60,
正如大多数其他资源 样,在你修改资源之后, Autosca er 控制器会检测到这一变更,并执行相应动作 也可以先删除 HPA 资源再用新的值创建一个,因为删除HPA 资源只会禁用目标资源的自动伸缩(本例中为 Deployment ,而它的伸缩规模会保持在删除资源的时刻 在你为 Deployment 创建一个新的 HPA 资源之后,自动伸缩过程就会继续进行
伸缩操作的最大速率
因为 Autosca 在单次扩容操作中可增加的副本数受到限制。如果当前副本数大于 2,Autoscaler 单次操作至多使副本数翻倍;如果副本数只有 2, Autoscaler 最多扩容到4个副
另外 Autoscaler 两次扩容操作之间的时间间隔是有限制。目前,只有当3钟内没有任何伸缩操作时才会触发扩容,缩容操作频率更低一- 5分钟 记住这点,这样你再看到度量数据很明显应该触发伸缩却没有触发的时候,就不会感到奇怪了。
基于内存使用进行自动伸缩
基于内存的自动伸缩比基于CPU 困难很多, 主要原因在于,扩容之后原有的pod 需要有办法释放内存。这只能由应用完成,系统无法代劳,系统所能做的只有杀死并重启应用,希望它能比之前少占用 些内存;但如果应用使用了跟之前多的内存 Autoscaler 就会扩容、扩容 再扩容到达到HPA资源上配置的最大pod 数量,显然没有人想要这种行为。基于内存使用的自动伸缩在 Kubernetes 1.8 中得到支持,配置方法与基于 CPU 的自动伸缩完全相同 。
基于其他自定义度量进行自动伸缩


... spec: maxReplicas: 5 metrics: - type: Resourceresource: name: cputargetAverageUtilization:30 ...

如上所示, metrics 字段允许你定义多个度量供使用。在代码清单中使用了单个度量。每个条目都指定相应度量的类型一一本例中为一个 Resource 度量。可以在HPA 对象中使用三种度量:
定义 metric 类型
使用情况会被监控的资源
资源的 目标使用量
Resurce 量类型
Resource 类型使 autoscaler 基于一个资源度量做出自动伸缩决策,在容器的资源请求中指定的那些度量即为一例 。这一类型的使用方式我们己经看过了,所以重点关注另外两种类型。
pods 度量类型
Pods 类型用来引用任何其他种类的(包括自定义的)与 pod 直接相关的度量。每秒查询次数 CQPS ),或者消息队列中的消息数量(当消息队列服务运行在 pod 之中 )都属于这种度量。要配置autoscaler 使用 pod QPS 度量, HPA 对象的 metrics 字段中就需要包含以下代码清单所示的条目。


... spec: metrics: - type: Podsresource: metricName: qpstargetAverageValue:100 ...

代码清单中的示例配置 Autoscaler ,使该 HPA 控制的 ReplicaSet (或其他)控制器下所辖 pod 的平均 QPS 维持 100 的水平。
Object 度量类型
Object 类型被用来让 Autoscaler 基于并非直接与 pod 关联的度量来进行伸缩,比方说,你可能希望基于另一集群对象 ,比如 Ingress 对象来伸缩你的 pod。 这度量可能是代码清单 15.8 中的 QPS ,也可能是平均请求延迟,或者完全是不相干的其他东西。与此前的例子不同,使用 object 度量类型时, Autoscaler 只会从这单个对象中获取单个度量数据;在此前的例子中, Autoscaler 需要从所有下属 pod 中获取度量,并使用它们的平均值。你需要在HPA对象的定义中指定目标对象与目标值。如下所示:

View Code
该例中 HPA 被配置为使用 Ingress 对象 frontend 的 latencyMillis 度量,目标值为 20 。HPA 会监控该 Ingress 度量,如果该度量超过了目标值太多autoscaler 便会对 kubia Deployment 资源进行扩容了。
确定哪些度量适合用于自动伸缩
不是所有度量都适合作为自动伸缩的基础。正如之前提到的, pod 中容器的内存占用并不是自动伸缩的一个好度量。如果增加副本数不能导致被观测度量平均值的线性(或者至少接近线性)下降 ,那么 autoscaler 就不能正常工作比方说,如果你只有 pod 实例,度量数值为 X,这时 autoscaler 扩容到了2个副本,度量数值就需要落在接近 X/2 位置 每秒查询次数 QPS )就是这么一种自定义度量,对 we 应用而 即为应用每秒接收的请求数。增大副本数总会导致QPS 成比例下降,因为同样多的请求数现在被更多数量的 pod 处理了。在你决定基于应用自有的自定义度量来伸缩它之前,一定要思考 pod 数量增加或减少时,它的值会如何变化。
缩容到0个副本
HPA 目前不允许设置 minReplicas 字段为0 ,所以 autoscaler 永远不会缩容到0个副本,即便 pod 什么都没做也不会。允许 pod 数量缩容到0可以大幅提升硬件利用率:如果你运行的服几个小时甚至几天才会收到1次请求,就没有道理留着它们一直运行,占用本来可以给其他服务利用的资源:然而一旦客户端请求进来了,你仍然还想让这些服务马上可用。
这叫空载( idling )与解除空载 (un-idling ),即允许提供特定服务的 pod 被缩容量到0 副本。在新的请求到来时,请求会先被阻塞,直到 pod 被启动,从而请求被转发到新的 pod 为止。Kubernetes 目前暂时没有提供这个特性,但在未来会实现。可 以检查 Kubernetes 文档来看看空载特性有没有被实现。
pod 的纵向自动伸缩
横向伸缩很棒,但并不是所有应用都能被横向伸缩,对这些应用而言,唯一选项是纵向伸缩一-给它们更多 CPU 和(或)内存。因为每个节点所拥有的资源通常都比单个 pod 请求的要多 ,我们应该几乎总能纵向扩容 pod ,因为 pod 的资源请求是通过 pod manifest 的字段配置的,纵向伸缩 pod 将会通过改变这些字段来实现。笔者这里说的是“将会”,因为目前还不可能改变己有 pod的资源请求和限制, 在笔者动笔之前(已经是一年多之前了),请参考Kubemetes文档来检查纵向pod自动伸缩实现了没有。
集群节点的横向伸缩
HPA在需要的时候会创建更多的pod实例。 但万一所有的节点都满了, 放不下更多pod了, 怎么办?显然这个问题并不局限于Autoscaler创建新pod实例的场景。即便是手动创建pod, 也可能碰到因为资源被已有pod使用殆尽, 以至于没有节点能接收新pod的清况。
Kubernetes支持在需要时立即自动从云服务提供者请求更多节点。 该特性由 Cluster Autoscaler执行。
Cluster Autoscaler介绍
Cluster Autoscaler负责在由于节点资源不足, 而无法调度某pod到已有节点时,自动部署新节点。它也会在 节点长时间使用率低下的情况下下线节点。
从云端基础架构请求新节点
如果在 一个pod被创建之后,Scheduler无法将其调度到任何一个已有 节点,一个新节点就会被创建。ClusterAutoscaler会注意此类pod, 并请求云服务提供者启动 一个新节点。但在这么做之前,它会检查新节点有没有可能容纳这个(些) pod,毕竟如果 新节点本来就不可能容纳它们,就没必要启动这么一个节点了。
云服务提供者通常把相同规格(或者有相同特性)的节点聚合成组。因此Cluster Autoscaler不能单纯地说 “给我多一个节点”,它还需要指明节点类型。Cluster Autoscaler 通过检查可用的节点分组来确定是否有至少一种节点类型能容纳未被调度的pod。如果只存在唯一一个此种节点分组,ClusterAutoscaler就可以增加节点分组的大小,让云服务提供商给分组中增加一个节点。但如果存在多个满足条件的节点分组,ClusterAutoscaler就必须挑一个最合适的。这里 “ 最合适” 的精确含义显然必须是可配置的。在 最坏的情况下,它会随机挑选一个。
新节点启动后,其上运行的Kubelet会联系API服务器,创建一个Node资源以注册该节点。从这一刻起,该节点即成为Kubernetes集群的一部分,可 以调度pod于其上了。
归还节点
当节点利用率不足时, Cluster Autoscaler 也需要能够减少节点的数目。 Cluster Autoscaler 通过监控所有节点上请求的CPU 与内存来实现这一点。 如果某个节点上
所有pod请求的CPU、 内存都不 到 50%, 该节点即被认定 为不再需要。这并不是决定是否要归还某 一 节点的唯一因素。 Cluster Autoscaler 也会检查是否有系统 pod (仅仅)运行在该节点上(这并不包括每个节点上都运行的服务, 比如 DaemonSet所部署的服务)。 如果节点上有系统 pod 在运行,该节点就不会被归还。
对非托管 pod, 以及有本地存储的pod 也是如此, 否则就会造成这些 pod 提供的服务中断。 换句话说, 只有当 Cluster Autoscaler 知道节点上运行的pod 能够重新调度到其他节点, 该节点才会被 归还。
当一个节点被选中下线, 它首先会被标记为不可调度, 随后运行其上的pod 将被疏散至其他节点。 因为所有这些 pod 都属于 ReplicaSet 或者其他控制器, 它们的替代 pod会被创建并调度到其他剩下的节点(这就是为何正被下线的节点要先标记为不可调度的原因)。
手动标记节点为不可调度、 排空节点


节点也可以手动被标记为不可调度并排空。 不涉及细节, 这些工作可用以下 kubectl 命令完成:• kubectl cordon <node> 标记节点为不可调度(但对其上的 pod不做任何事)。 • kubectl drain <node> 标记节点为不可调度, 随后疏散其上所有pod。两种情形下, 在你用 kubectl uncordon <node> 解除节点的不可调度状态之前, 不会有新 pod被调度到该节点。

限制集群缩容时的服务干扰
如果 一个节点发生非预期故障, 你不可能阻止其上的pod变为不可用;但如果一个节点被Cluster Autoscaler或者人类操作员主动下线,可以用一个新特性来确保下线操作不会干扰到这个节点上pod所提供的服务。一些服务要求至少保持一定数量的pod持续运行 , 对基于quorum的集群应用而言尤其如此。 为此, Kubemetes可以指定 下线等操作时需要保待的最少 pod数量,我们通过创建一个podDisruptionBudget资源的方式来利用这一特性。尽管这个资源的名称听起来挺复杂的, 实际上 它是最简单的Kubemetes资源
之一 。 它只包含 一个pod 标签选择器和 一个数字, 指定 最少需要维持运行的podYAML文件。
如果想确保你的kubiapod总有3个实例在运行(它们有 app=kubia这个标签), 像这样创建PodDisruptionBudget资源 :

$ kubectl create pdb kubia-pdb --selector=app=kubia --min-available=3 poddisruptionbudget "kubia-pdb" created
现在获取这个pod 的YAML文件, 如以下代码清单所示。

也可以用 一个百分比而非绝对数值来写minAvailable字段。 比方说,可以指定60%带app=kubia标签的pod应当时刻保持运行。注意从Kubemetes 1. 7开始podDismptionBudget资源也支持maxUnavailable。如果当很多pod不可用而想要阻止pod被剔除时,就可以用maxUnavailable字段而不是minAvailable。
关于这个资源, 没有更多要讲的了。 只 要它存在 ,Cluster Autoscaler与 kubectl drain 命令都会遵守它;如果疏散一个带有app=kubia标签的pod会导致它们的总数小于3, 那这个操作就永远不会被执行。比方说,如果总共有4个pod, minAvailable像例子中 一 样被设为3, pod 疏散过程就会挨个进行,待ReplicaSet控制器把被疏散的pod换成新的,才继续下一个。
任何程序错误,以及技术疑问或需要解答的,请添加









)











