本文主要介绍分布式定时任务框架Quartz集成SpringBoot持久化数据到Mysql数据库的操作,上一篇文章使用Quartz创建定时任务都是保存在内存中,如果服务重启定时任务就会失效,所以Quartz官方也提供将定时任务等信息持久化到Mysql数据库的功能,本文主要实现这种Quartz的这种使用方式。
[TOC]
一、概述
Quartz提供两种基本作业存储类型,包括将任务数据保存在内存中的RAMJobStore模式和保存在数据库中的JDBC作业存储模式,上篇说明了RAMJobStore 模式,本篇说明JDBC作业存储。
- RAMJobStore :RAM也就是内存,默认情况下Quartz会将任务调度存在内存中,这种方式性能是最好的,因为内存的速度是最快的。不好的地方就是数据缺乏持久性,但程序崩溃或者重新发布的时候,所有运行信息都会丢失
- JDBC作业存储:存到数据库之后,可以做单点也可以做集群,当任务多了之后,可以统一进行管理。关闭或者重启服务器,运行的信息都不会丢失。缺点就是运行速度快慢取决于连接数据库的快慢。
二、功能说明
实现功能:
- 实现将Quartz的任务持久化到Mysql中,当服务重启后也能重写执行之前的任务;
- 实现通过restful API能够增删改查Quartz中执行的任务;
主要依赖:
- springboot
- quartz
- mybatis:ORM组件
- Druid:数据库连接池
- mysql 8.0:数据库
三、实现步骤
1.配置POM文件
配置需要引入的依赖项,涉及Quartz的是:quartz-jobs、spring-boot-starter-quartz
<modelVersion>4.0.0</modelVersion>
<parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.6.2</version><relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.example</groupId>
<artifactId>QuartzDemo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>QuartzDemo</name>
<description>Demo project for Spring Boot</description>
<properties><java.version>1.8</java.version>
</properties><dependencies><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.4</version></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!--jdbc--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-jdbc</artifactId></dependency><!--mybatis--><dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter</artifactId><version>2.2.1</version></dependency><!--lombok--><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><!--mysql--><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><scope>runtime</scope></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><!--quartz依赖--><dependency><groupId>org.quartz-scheduler</groupId><artifactId>quartz-jobs</artifactId><version>2.2.1</version></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-quartz</artifactId></dependency><!--druid连接池依赖--><dependency><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-starter</artifactId><version>1.1.10</version></dependency>
</dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><configuration><excludes><exclude><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></exclude></excludes></configuration></plugin><!--mybatis generator start--><plugin><groupId>org.mybatis.generator</groupId><artifactId>mybatis-generator-maven-plugin</artifactId><version>1.3.2</version><configuration><!-- <configurationFile>/src/main/resources/generatorConfig.xml</configurationFile>--><configurationFile>/Users/yangnk/IdeaProjects/SpringBoot-Learning/QuartzDemo/src/main/resources/generatorConfig.xml</configurationFile><overwrite>true</overwrite></configuration><dependencies><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.12</version></dependency></dependencies></plugin><!--mybatis generator end--></plugins>
</build>2.配置application.yml文件
选用Druid做数据库连接池,需要对连接池进行配置。
server:port: 9000#数据库连接池druid配置
spring:datasource:#1.JDBCtype: com.alibaba.druid.pool.DruidDataSourcedriver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://x.x.x.x:3306/quartz?serverTimezone=UTC&useSSL=false&allowPublicKeyRetrieval=trueusername: rootpassword: xxxxxxdruid:#2.连接池配置#初始化连接池的连接数量 大小,最小,最大initial-size: 5min-idle: 5max-active: 20#配置获取连接等待超时的时间max-wait: 60000#配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒time-between-eviction-runs-millis: 60000# 配置一个连接在池中最小生存的时间,单位是毫秒min-evictable-idle-time-millis: 30000validation-query: SELECT 1 FROM DUALtest-while-idle: truetest-on-borrow: truetest-on-return: false# 是否缓存preparedStatement,也就是PSCache 官方建议MySQL下建议关闭 个人建议如果想用SQL防火墙 建议打开pool-prepared-statements: truemax-pool-prepared-statement-per-connection-size: 20# 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙filter:stat:merge-sql: trueslow-sql-millis: 5000#3.基础监控配置web-stat-filter:enabled: trueurl-pattern: /*#设置不统计哪些URLexclusions: "*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*"session-stat-enable: truesession-stat-max-count: 100stat-view-servlet:enabled: trueurl-pattern: /druid/*reset-enable: true#设置监控页面的登录名和密码login-username: adminlogin-password: adminallow: 127.0.0.1mybatis:mapper-locations: classpath*:mapper/*.xmltype-aliases-package: com.example.quartzdemo.modellogging:level:com.example.quartzdemo.mapper : debug3.配置quartz.properties配置
其中org.quartz.dataSource.qzDS.connectionProvider.class配置项是Druid连接池的Quartz扩展类,该扩展类是需要implements ConnectionProvider,这样在Quartz中才能使用Druid连接池。
其中org.quartz.jobStore.isClustered参数是配置是否开启集群模式,如果开启则配置:ture,如果未开启则配置:false,我们用单机实现所以配置:false。
#============================================================================
# Configure Main Scheduler Properties \u8C03\u5EA6\u5668\u5C5E\u6027
#============================================================================
org.quartz.scheduler.instanceName: DefaultQuartzScheduler
org.quartz.scheduler.instanceId = AUTO
org.quartz.scheduler.rmi.export: false
org.quartz.scheduler.rmi.proxy: false
org.quartz.scheduler.wrapJobExecutionInUserTransaction: false
org.quartz.threadPool.class: org.quartz.simpl.SimpleThreadPool
org.quartz.threadPool.threadCount= 10
org.quartz.threadPool.threadPriority: 5
org.quartz.threadPool.threadsInheritContextClassLoaderOfInitializingThread: true
org.quartz.jobStore.misfireThreshold: 60000
#============================================================================
# Configure JobStore
#============================================================================
#\u5B58\u50A8\u65B9\u5F0F\u4F7F\u7528JobStoreTX\uFF0C\u4E5F\u5C31\u662F\u6570\u636E\u5E93
org.quartz.jobStore.class: org.quartz.impl.jdbcjobstore.JobStoreTX
org.quartz.jobStore.driverDelegateClass:org.quartz.impl.jdbcjobstore.StdJDBCDelegate
#\u4F7F\u7528\u81EA\u5DF1\u7684\u914D\u7F6E\u6587\u4EF6
org.quartz.jobStore.useProperties:true
#\u6570\u636E\u5E93\u4E2Dquartz\u8868\u7684\u8868\u540D\u524D\u7F00
org.quartz.jobStore.tablePrefix:qrtz_
org.quartz.jobStore.dataSource:qzDS
#\u662F\u5426\u4F7F\u7528\u96C6\u7FA4\uFF08\u5982\u679C\u9879\u76EE\u53EA\u90E8\u7F72\u5230 \u4E00\u53F0\u670D\u52A1\u5668\uFF0C\u5C31\u4E0D\u7528\u4E86\uFF09
org.quartz.jobStore.isClustered = false
#============================================================================
# Configure Datasources
#============================================================================
#\u914D\u7F6E\u6570\u636E\u5E93\u6E90
org.quartz.dataSource.qzDS.connectionProvider.class: com.example.quartzdemo.demo.DruidConnectionProvider
org.quartz.dataSource.qzDS.driver: com.mysql.cj.jdbc.Driver
org.quartz.dataSource.qzDS.URL: jdbc:mysql://x.x.x.x:3306/quartz?serverTimezone=UTC&useSSL=false&allowPublicKeyRetrieval=true
org.quartz.dataSource.qzDS.user: root
org.quartz.dataSource.qzDS.password: xxxxxx
org.quartz.dataSource.qzDS.maxConnection: 10Druid连接池的Quartz扩展类
import com.alibaba.druid.pool.DruidDataSource;
import org.quartz.SchedulerException;
import org.quartz.utils.ConnectionProvider;
import java.sql.Connection;
import java.sql.SQLException;/*** Druid连接池的Quartz扩展类*/
public class DruidConnectionProvider implements ConnectionProvider {/** 常量配置,与quartz.properties文件的key保持一致(去掉前缀),同时提供set方法,Quartz框架自动注入值。*///JDBC驱动public String driver;//JDBC连接串public String URL;//数据库用户名public String user;//数据库用户密码public String password;//数据库最大连接数public int maxConnection;//数据库SQL查询每次连接返回执行到连接池,以确保它仍然是有效的。public String validationQuery;private boolean validateOnCheckout;private int idleConnectionValidationSeconds;public String maxCachedStatementsPerConnection;private String discardIdleConnectionsSeconds;public static final int DEFAULT_DB_MAX_CONNECTIONS = 10;public static final int DEFAULT_DB_MAX_CACHED_STATEMENTS_PER_CONNECTION = 120;//Druid连接池private DruidDataSource datasource;/** ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~** 接口实现** ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~*/@Overridepublic Connection getConnection() throws SQLException {return datasource.getConnection();}@Overridepublic void shutdown() throws SQLException {datasource.close();}@Overridepublic void initialize() throws SQLException{if (this.URL == null) {throw new SQLException("DBPool could not be created: DB URL cannot be null");}if (this.driver == null) {throw new SQLException("DBPool driver could not be created: DB driver class name cannot be null!");}if (this.maxConnection < 0) {throw new SQLException("DBPool maxConnectins could not be created: Max connections must be greater than zero!");}datasource = new DruidDataSource();try{datasource.setDriverClassName(this.driver);} catch (Exception e) {try {throw new SchedulerException("Problem setting driver class name on datasource: " + e.getMessage(), e);} catch (SchedulerException e1) {}}datasource.setUrl(this.URL);datasource.setUsername(this.user);datasource.setPassword(this.password);datasource.setMaxActive(this.maxConnection);datasource.setMinIdle(1);datasource.setMaxWait(0);datasource.setMaxPoolPreparedStatementPerConnectionSize(this.DEFAULT_DB_MAX_CACHED_STATEMENTS_PER_CONNECTION);if (this.validationQuery != null) {datasource.setValidationQuery(this.validationQuery);if(!this.validateOnCheckout)datasource.setTestOnReturn(true);elsedatasource.setTestOnBorrow(true);datasource.setValidationQueryTimeout(this.idleConnectionValidationSeconds);}}/** ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~** 提供get set方法** ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~*/public String getDriver() {return driver;}public void setDriver(String driver) {this.driver = driver;}public String getURL() {return URL;}public void setURL(String URL) {this.URL = URL;}public String getUser() {return user;}public void setUser(String user) {this.user = user;}public String getPassword() {return password;}public void setPassword(String password) {this.password = password;}public int getMaxConnection() {return maxConnection;}public void setMaxConnection(int maxConnection) {this.maxConnection = maxConnection;}public String getValidationQuery() {return validationQuery;}public void setValidationQuery(String validationQuery) {this.validationQuery = validationQuery;}public boolean isValidateOnCheckout() {return validateOnCheckout;}public void setValidateOnCheckout(boolean validateOnCheckout) {this.validateOnCheckout = validateOnCheckout;}public int getIdleConnectionValidationSeconds() {return idleConnectionValidationSeconds;}public void setIdleConnectionValidationSeconds(int idleConnectionValidationSeconds) {this.idleConnectionValidationSeconds = idleConnectionValidationSeconds;}public DruidDataSource getDatasource() {return datasource;}public void setDatasource(DruidDataSource datasource) {this.datasource = datasource;}
}4.在数据库中创建quartz相关的表
进入quartz的官网Quartz Enterprise Job Scheduler,点击Downloads,也可以直接去文章末尾直接下载官方提供的Quartz相关表。
也可以自定义业务表,我们定义了t_schedule_trigger、t_schedule_trigger_param,具体表功能可以参考总结部分。
5.自定义MyJobFactory
自定义MyJobFactory的作用主要是为了解决在Spring中需要注入Quartz的bean实例,由于是将任务bean的全限定名信息保存在数据库中,Job对象的实例化过程是在Quartz中进行的,需要注入的实体类是在Spring容器当中的,所以在job中无法注入Srping容器的实体类。
Job的创建都是通过JobFactory创建的。JobFactory 有2个实现类:AdaptableJobFactory 和 SimpleJobFactory,可以通过AdaptableJobFactory类来解决:
- 自定义的工厂类 JobFactory 继承 AdaptableJobFactory 。
- 通过调用父类 AdaptableJobFactory 的方法createJobInstance来实现对Job的实例化。
- 在Job实例化完以后,再调用自身方法为创建好的Job实例进行属性自动装配并将其纳入到Spring容器的管理之中。(通过AutowireCapableBeanFactory纳入)。
import org.quartz.spi.TriggerFiredBundle;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.config.AutowireCapableBeanFactory;
import org.springframework.scheduling.quartz.AdaptableJobFactory;
import org.springframework.stereotype.Component;/*** @description:自定义MyJobFactory,解决spring不能在quartz中注入bean的问题*/
@Component
public class MyJobFactory extends AdaptableJobFactory {/*** @description:这个对象Spring会帮我们自动注入进来*/@Autowiredprivate AutowireCapableBeanFactory autowireCapableBeanFactory;@Overrideprotected Object createJobInstance(TriggerFiredBundle bundle) throws Exception {Object jobInstance = super.createJobInstance(bundle);//通过以下方式,解决Job任务无法使用Spring中的Bean问题autowireCapableBeanFactory.autowireBean(jobInstance);return jobInstance;}创建调度器schedule
在配置类中创建schedule。
import org.quartz.Scheduler;
import org.springframework.beans.factory.config.PropertiesFactoryBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.ClassPathResource;
import org.springframework.scheduling.quartz.SchedulerFactoryBean;import javax.annotation.Resource;
import java.io.IOException;
import java.util.Properties;/*** @description:quartz配置类,将调度器交给spring管理*/
@Configuration
public class QuartzConfigration {@Resourceprivate MyJobFactory myJobFactory;@Beanpublic Scheduler scheduler(){return this.getSchedulerFactoryBean().getScheduler();}@Beanpublic SchedulerFactoryBean getSchedulerFactoryBean(){//1.创建SchedulerFactoryBeanSchedulerFactoryBean sc = new SchedulerFactoryBean();//2.加载自定义的quartz.propertiessc.setQuartzProperties(this.getProperties());//3.设置自定义的MyJobFactorysc.setJobFactory(myJobFactory);return sc;}/*** @description:读取自定义的properties文件* @author: jie* @time: 2022/1/15 18:24*/public Properties getProperties(){try {PropertiesFactoryBean propertiesFactoryBean = new PropertiesFactoryBean();//设置自定义配置文件的位置propertiesFactoryBean.setLocation(new ClassPathResource("/quartz.properties"));//读取配置文件propertiesFactoryBean.afterPropertiesSet();return propertiesFactoryBean.getObject();} catch (IOException e) {e.printStackTrace();throw new RuntimeException(e);}}
}6.创建自定义任务
Quartz中自定义任务需要implements Job。
import lombok.extern.slf4j.Slf4j;
import org.quartz.Job;
import org.quartz.JobDataMap;
import org.quartz.JobExecutionContext;
import org.quartz.JobExecutionException;
import org.springframework.stereotype.Component;
import java.util.Date;@Component
@Slf4j
public class MyJob1 implements Job {@Overridepublic void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {//在日志中打印以下语句log.info("job1 ="+new Date().toLocaleString());JobDataMap jobDataMap = jobExecutionContext.getJobDetail().getJobDataMap();for (String s : jobDataMap.keySet()) {System.out.println(s);}}
}7.生成数据库访问相关文件
通过mybatis-generator-maven-plugin插件生成XML文件、Mapper文件、Model文件。
8.增加quartz中的任务Service层方法
主要实现两部分功能,一部分是通过 @Scheduled设置定时任务,定时同步数据库中的任务信息,如果有新增的任务则加入到调度器中,如果有删除的任务则从调度器中删除。
另一部分是提供新增和删除任务的逻辑,通过restful API的形式可以动态的向数据库中新增和删除任务。
public interface IScheduleService {/*** 定时更新任务*/public void refresh();/*** 创建新任务* @param triggerVo*/public void addTrigger(TriggerVo triggerVo);/*** 停止任务** @param jobName* @param jobGroup*/public void deleteTrigger(String jobName, String jobGroup);}import com.example.quartzdemo.mapper.TScheduleTriggerMapper;
import com.example.quartzdemo.mapper.TScheduleTriggerParamMapper;
import com.example.quartzdemo.model.TScheduleTrigger;
import com.example.quartzdemo.model.TScheduleTriggerParam;
import lombok.extern.slf4j.Slf4j;
import org.quartz.*;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
import java.util.HashMap;
import java.util.List;
import java.util.Map;@Service
@Slf4j
public class ScheduleServiceImpl implements IScheduleService {/*** @description:* @author: 调度器* @time: 2022/1/15 19:15*/@Resourceprivate Scheduler scheduler;@Resourceprivate TScheduleTriggerMapper scheduleTriggerMapper;@Resourceprivate TScheduleTriggerParamMapper scheduleTriggerParamMapper;public void deleteTrigger(String jobName, String jobGroup) {try {scheduleTriggerMapper.deleteByJobName(jobName);scheduler.deleteJob(new JobKey(jobName));} catch (SchedulerException e) {e.printStackTrace();}}public void addTrigger(TriggerVo triggerVo) {int id = (int) (System.currentTimeMillis() % Integer.MAX_VALUE);TScheduleTrigger trigger = new TScheduleTrigger();trigger.setCron(triggerVo.getCron());trigger.setJobGroup(triggerVo.getJobGroup());trigger.setJobName(triggerVo.getJobName());trigger.setId(id);trigger.setStatus("1");scheduleTriggerMapper.insert(trigger);HashMap<String, String> allMap = triggerVo.getMap();JobDataMap jobDataMap = new JobDataMap();for (Map.Entry<String, String> entry : allMap.entrySet()) {TScheduleTriggerParam tScheduleTriggerParam = new TScheduleTriggerParam();tScheduleTriggerParam.setScheduleTriggerId(id);tScheduleTriggerParam.setName(entry.getKey());tScheduleTriggerParam.setValue(entry.getValue());scheduleTriggerParamMapper.insert(tScheduleTriggerParam);jobDataMap.put(entry.getKey(),entry.getValue());}try {//设置TriggerKeyString jobName = triggerVo.getJobName();String jobGroup = triggerVo.getJobGroup();String cron = triggerVo.getCron();//创建触发器CronTrigger cronTrigger1 = TriggerBuilder.newTrigger().withIdentity(jobName, jobGroup).withSchedule(CronScheduleBuilder.cronSchedule(cron)).build();//创建工作详情实例JobDetail jobDetail = JobBuilder.newJob((Class<? extends Job>) Class.forName(jobName)).withIdentity(jobName, jobGroup).setJobData(jobDataMap).build();scheduler.scheduleJob(jobDetail, cronTrigger1);} catch (SchedulerException | ClassNotFoundException e) {e.printStackTrace();}}@Scheduled(cron = "*/10 * * * * ?")@Overridepublic void refresh() {log.info(">>>>>>>>>>Refreshing");try {//1.查询数据库中所有任务List<TScheduleTrigger> scheduleTriggers = scheduleTriggerMapper.listScheduleTrigger();log.info(">>>>>>>>>>List of scheduled is:{}", scheduleTriggers.toString());//2.遍历所有任务for (TScheduleTrigger scheduleTrigger : scheduleTriggers) {Integer id = scheduleTrigger.getId();String cron = scheduleTrigger.getCron();String status = scheduleTrigger.getStatus();String jobName = scheduleTrigger.getJobName();String jobGroup = scheduleTrigger.getJobGroup();//3.从调度器中查找该任务//3.1 设置TriggerKeyTriggerKey triggerKey = TriggerKey.triggerKey(jobName, jobGroup);//3.2 通过triggerKey从调度器中获取触发器CronTrigger cronTrigger = (CronTrigger)scheduler.getTrigger(triggerKey);//3.3 判断触发器是否为空,如果为空,表示调度器中没有该任务//如果调度器中没有该任务 ,添加任务if(null==cronTrigger){//如果状态为0,该任务禁用,跳出本次循环if("0".equals(status)){continue;}//将任务添加到调度器中(创建新的触发器和工作详情实例)//创建触发器CronTrigger cronTrigger1 = TriggerBuilder.newTrigger().withIdentity(jobName, jobGroup).withSchedule(CronScheduleBuilder.cronSchedule(cron)).build();//创建工作详情实例JobDetail jobDetail = JobBuilder.newJob((Class<? extends Job>) Class.forName(jobName)).withIdentity(jobName, jobGroup).build();//查询该任务的所有参数List<TScheduleTriggerParam> scheduleTriggerParams = scheduleTriggerParamMapper.listScheduleTriggerParam(id);//遍历参数,将参数设置到jobData中JobDataMap jobDataMap = jobDetail.getJobDataMap();for (TScheduleTriggerParam scheduleTriggerParam : scheduleTriggerParams) {jobDataMap.put(scheduleTriggerParam.getName(),scheduleTriggerParam.getValue());}scheduler.scheduleJob(jobDetail,cronTrigger1);}else{//调度器中有该任务,但是状态变成禁用if("0".equals(status)){//设置jobKeyJobKey jobKey = JobKey.jobKey(jobName, jobGroup);//移除该任务scheduler.deleteJob(jobKey);}//调度器中有该任务,但是表达式改变//获取调度器中该任务的触发器器的表达式String cronExpression = cronTrigger.getCronExpression();//表达式不一致if(!cronExpression.equals(cron)){//重新创建触发器CronTrigger cronTrigger2 = TriggerBuilder.newTrigger().withIdentity(jobName, jobGroup).withSchedule(CronScheduleBuilder.cronSchedule(cron)).build();//更新调度器中该任务的触发器scheduler.rescheduleJob(triggerKey,cronTrigger2);}}}} catch (SchedulerException | ClassNotFoundException e) {throw new RuntimeException(e);}}
}9.增加Controller增删改Quartz的方法
提供restful API接口,动态向数据库中新增和删除任务。
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;/*** @author yangnk* @desc* @date 2023/08/22 23:37**/
@RestController
public class QuartzController {@AutowiredScheduleServiceImpl scheduleService;@RequestMapping(value = "/addTrigger", method = RequestMethod.POST)public void addTrigger(@RequestBody TriggerVo triggerVoBody) {scheduleService.addTrigger(triggerVoBody);}@RequestMapping(value = "/deleteTrigger", method = RequestMethod.DELETE)public void deleteTrigger(@RequestHeader("jobName") String jobName, @RequestHeader ("jobGroup") String jobGroup) {scheduleService.deleteTrigger(jobName, jobGroup);}
}10.实现效果
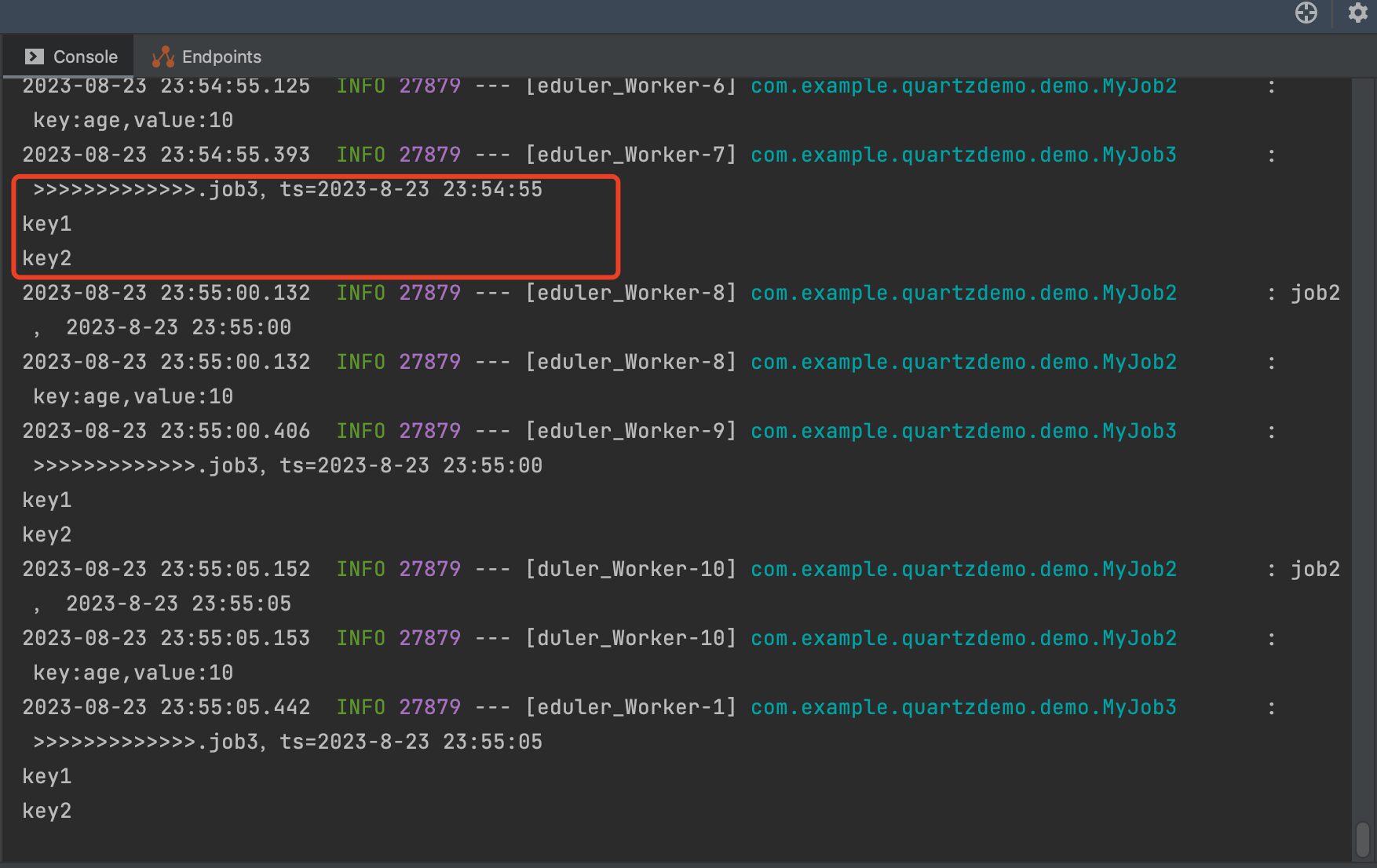
定时打印任务中参数。
四、完整代码地址
Github:https://github.com/yangnk/SpringBoot_Learning/tree/1ecdf6429fe2478487bc65a7e2742577e65ac59a/QuartzDemo
五、常见问题
- AutowireCapableBeanFactory的作用?
对于想要拥有自动装配能力,并且想把这种能力暴露给外部应用的BeanFactory类需要实现此接口。 正常情况下,不要使用此接口,应该更倾向于使用BeanFactory或者ListableBeanFactory接口。此接口主要是针对框架之外,没有向Spring托管Bean的应用。通过暴露此功能,Spring框架之外的程序,具有自动装配等Spring的功能。 需要注意的是,ApplicationContext接口并没有实现此接口,因为应用代码很少用到此功能,如果确实需要的话,可以调用ApplicationContext的getAutowireCapableBeanFactory方法,来获取此接口的实例。 如果一个类实现了此接口,那么很大程度上它还需要实现BeanFactoryAware接口。它可以在应用上下文中返回BeanFactory
- quartz中表的作用简介?
以下是quartz官方提供的表明和作用:
- QRTZ_CALENDARS: 以 Blob 类型存储 Quartz 的 Calendar 信息。
- QRTZ_CRON_TRIGGERS: 存储 Cron Trigger,包括Cron表达式和时区信息。
- QRTZ_FIRED_TRIGGERS: 存储与已触发的 Trigger 相关的状态信息,以及相联 Job的执行信息。
- QRTZ_PAUSED_TRIGGER_GRPS: 存储已暂停的 Trigger组的信息。
- QRTZ_SCHEDULER_STATE: 存储少量的有关 Scheduler 的状态信息,和别的Scheduler实例(假如是用于一个集群中) 。
- QRTZ_LOCKS: 存储程序的悲观锁的信息(假如使用了悲观锁) QRTZ_JOB_DETAILS: 存储每一个已配置的 Job 的详细信息 QRTZ_JOB_LISTENERS: 存储有关已配置的 JobListener的信息。
- QRTZ_SIMPLE_TRIGGERS:存储简单的Trigger,包括重复次数,间隔,以及已触的次数。
- QRTZ_BLOG_TRIGGERS Trigger: 作为 Blob 类型存储(用于 Quartz 用户用JDBC创建他们自己定制的 Trigger 类型,JobStore并不知道如何存储实例的时候)。
- QRTZ_TRIGGER_LISTENERS: 存储已配置的 TriggerListener的信息。
- QRTZ_TRIGGERS: 存储已配置的 Trigger 的信息。
但是由于官方提供的表功能过于复杂,如果只是实现简单的定时任务,可以自定义业务表,在我的这个项目中,自定义了以下表:
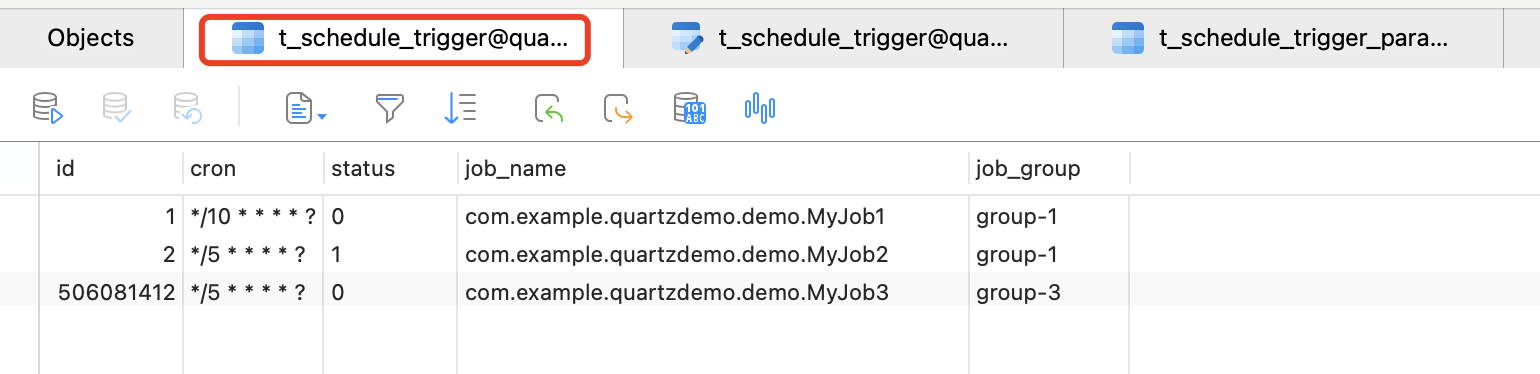
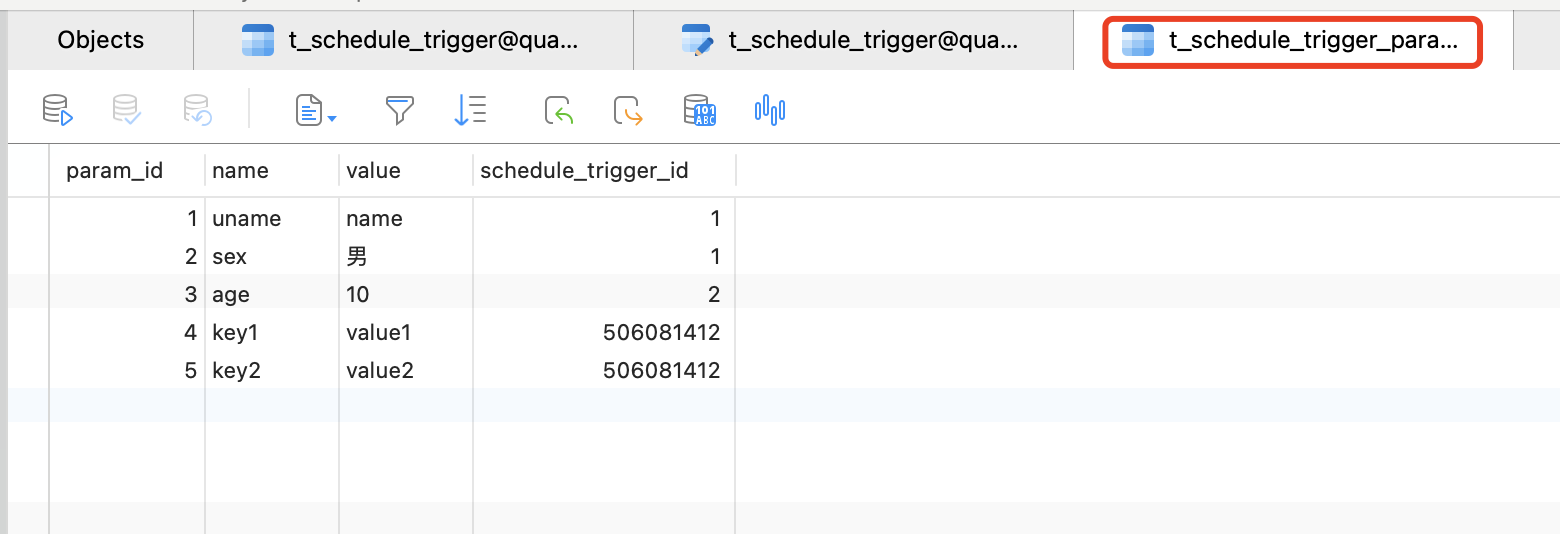
- t_schedule_trigger:任务和定时器描述信息;
- t_schedule_trigger_param:任务的具体参数;
参考资料
- SpringBoot+Quartz+数据库存储(附完整代码和数据库脚本):https://juejin.cn/post/7069609234186371108
- Springboot集成Quartz(任务存储在数据库):https://developer.aliyun.com/article/1138138 (自己实现了实例化bean的过程,不依赖Spring提供的注入方式)
- Quartz定时任务2.3版本数据库表字段说明:https://juejin.cn/post/7012961939319947300 (Quartz中表字段说明)
- SpringBoot——Quartz定时框架的使用详解和总结:https://juejin.cn/post/6946348432244080676#heading-21
本文由博客一文多发平台 OpenWrite 发布!








![[LitCTF 2023]Flag点击就送!](http://pic.xiahunao.cn/[LitCTF 2023]Flag点击就送!)


)




)


